文章目录
- 1、内容简介
- 2、CIFAR10 数据集
- 2.1、数据集概述
- 2.2、代码使用
- 2.2.1、查看数据集基本信息
- 2.2.2、数据加载器
- 2.2.3、完整代码
- 3、搭建图像分类网络🔺
- 3.1、网络结构⭐
- 3.2、代码构建网络⭐
- 4、编写训练函数
- 4.1、多分类交叉熵损失函数🔺
- 4.2、Adam🔺
- 4.3、训练函数代码
- 4.3.1、代码
- 4.3.2、训练过程说明⭐
- 4.3.3、重要代码解读
- 5、预测函数
- 5.1、代码
- 5.2、model.eval()⭐
- 6、完整代码
- 6.1、CPU
- 6.2、GPU
- 7、改进之处🔺
- 8、小结
🍃作者介绍:双非本科大三网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅长web应用开发、数据结构和算法,初步涉猎人工智能和前端开发。
🦅个人主页:@逐梦苍穹
📕所属专栏:人工智能
🌻gitee地址:xzl的人工智能代码仓库
✈ 您的一键三连,是我创作的最大动力🌹
1、内容简介
本章学习目标:
了解CIFAR10数据集
掌握分类网络搭建
掌握模型构建流程
本文用前面的学习到的知识来构建一个卷积神经网络,并 训练该网络实现图像分类
要完成这个案例,需要学习的内容如下:
- 了解 CIFAR10 数据集
- 搭建卷积神经网络
- 编写训练函数
- 编写预测函数
2、CIFAR10 数据集
CIFAR-10 数据集是计算机视觉领域非常著名的一个数据集,常用于图像分类和机器学习算法的训练和评估。
以下是一些关于 CIFAR-10 数据集的详细信息:
2.1、数据集概述
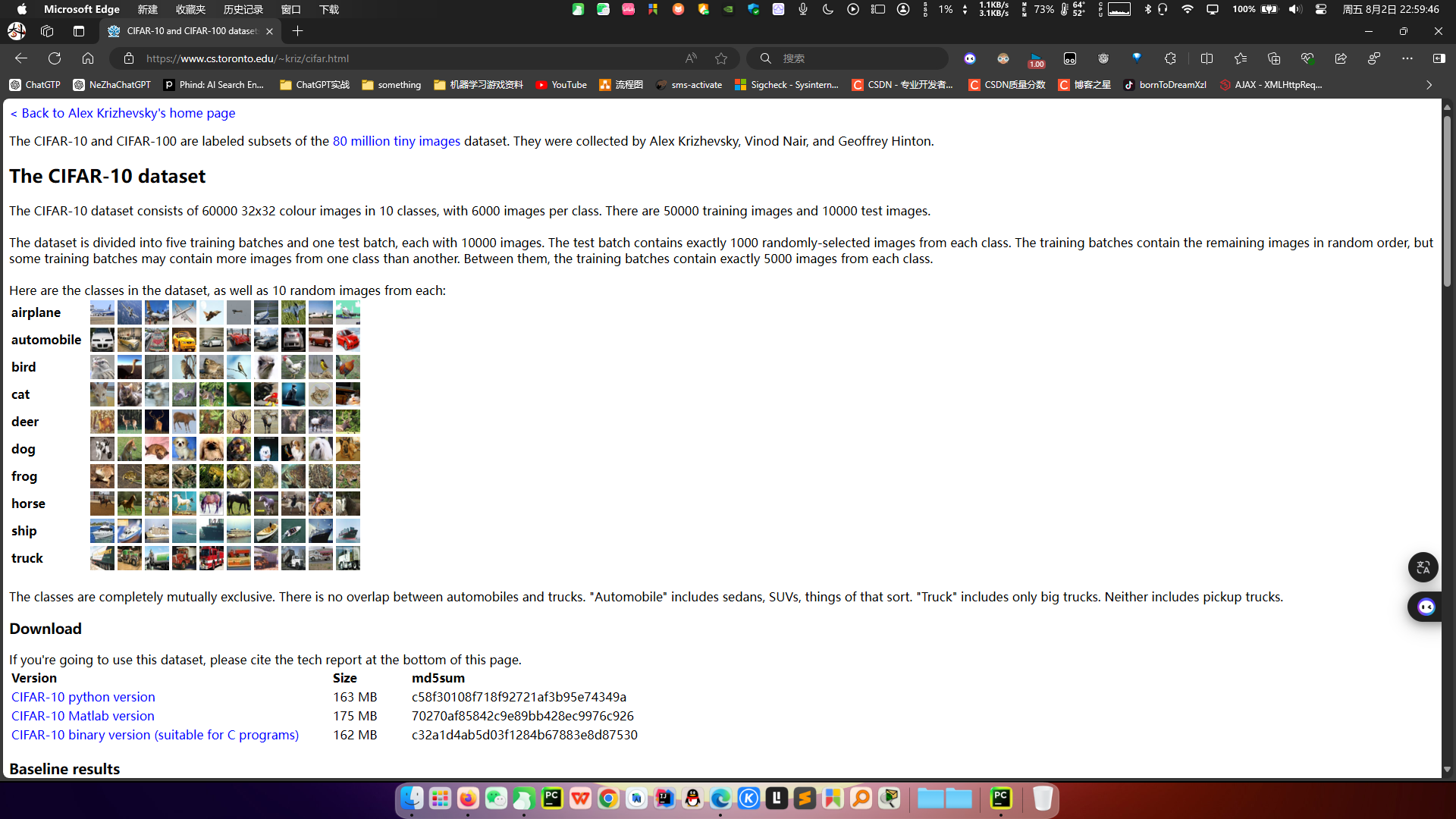
数据集内容:CIFAR-10 数据集包含 10 个类别的 60000 张 32x32 像素的彩色图像;
类别:飞机(airplane)、汽车(automobile)、鸟(bird)、猫(cat)、鹿(deer)、狗(dog)、青蛙(frog)、马(horse)、船(ship)、卡车(truck);
训练和测试集:50000 张训练图像和 10000 张测试图像。
总结起来一句话:
CIFAR-10数据集5万张训练图像、1万张测试图像、10个类别、每个类别有6k个图像,图像大小32×32×3。
下图列举了10个类,每一类随机展示了10张图片:

官网显示如下:
2.2、代码使用
不用自己去下载了,在PyTorch 中的 torchvision.datasets 计算机视觉模块封装了 CIFAR10 数据集,方便我们使用。
重中之重,先导包:

2.2.1、查看数据集基本信息
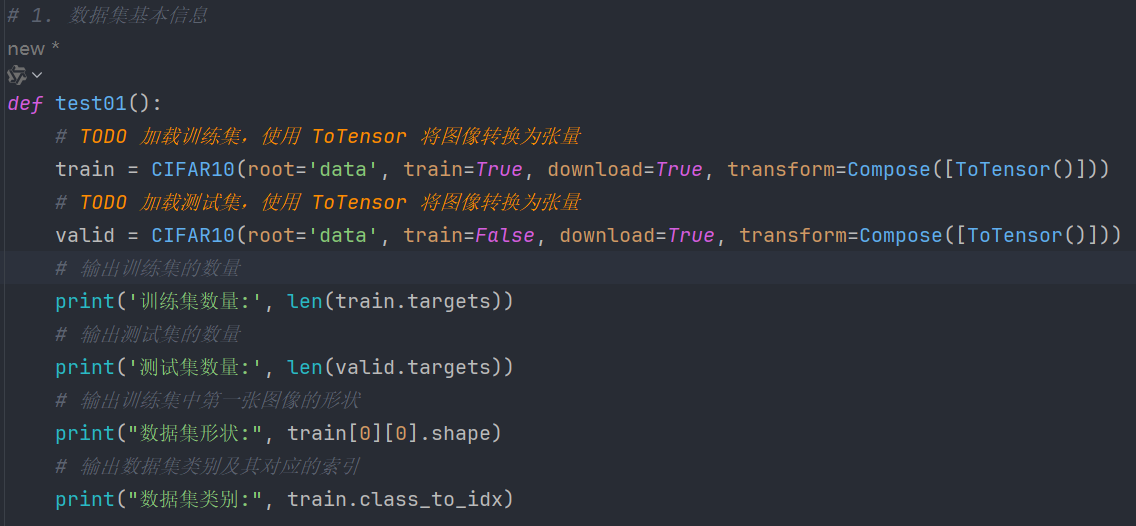
输出如下:
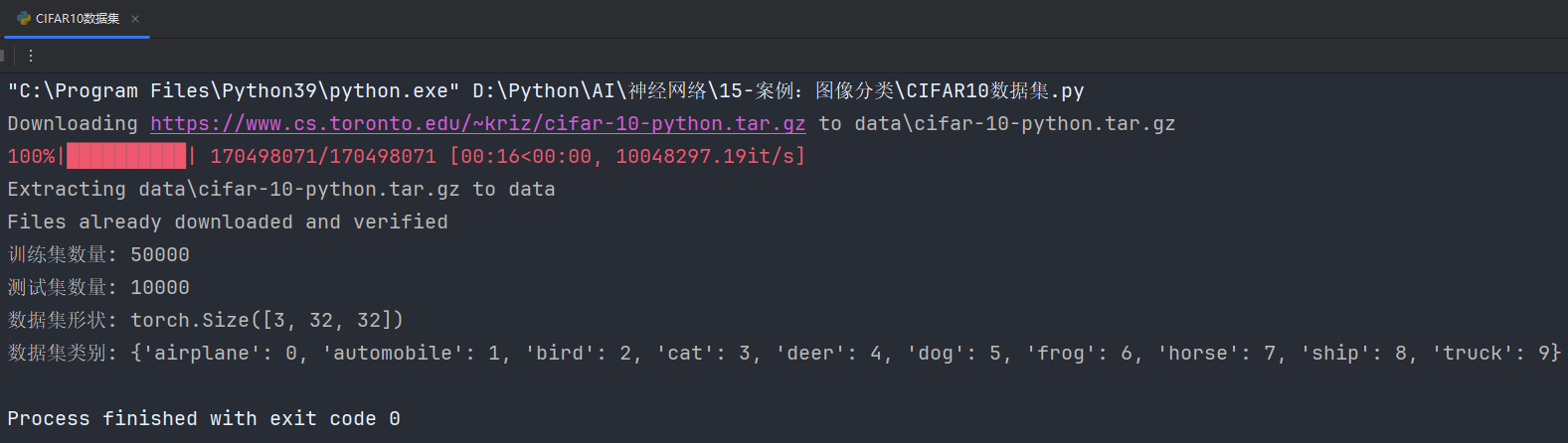
这里如果没有下载过数据集的,需要在代码里面指定’download=True’:

下载过后再运行代码,就不会重复运行了:
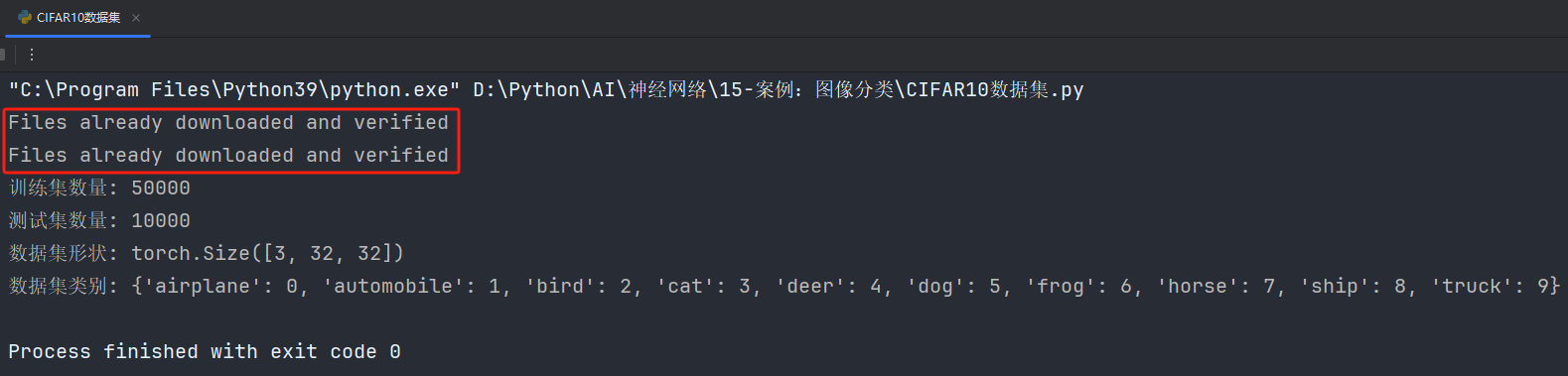
显示文件夹已下载
2.2.2、数据加载器
调用DataLoader:from torch.utils.data import DataLoader

输出如下:
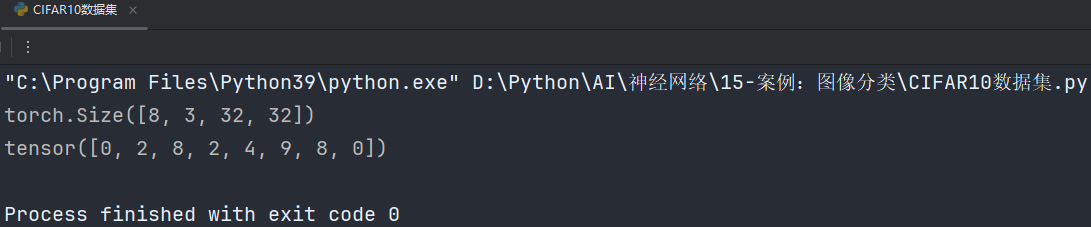
2.2.3、完整代码
# -*- coding: utf-8 -*-
# @Author: CSDN@逐梦苍穹
# @Time: 2024/8/2 23:10
from torchvision.datasets import CIFAR10 # 导入 CIFAR10 数据集类
from torchvision.transforms import Compose # 导入 Compose 用于组合多个数据变换
from torchvision.transforms import ToTensor # 导入 ToTensor 用于将图像转换为张量
from torch.utils.data import DataLoader # 导入 DataLoader 用于批量加载数据
# 1. 数据集基本信息
def test01():
# TODO 加载训练集,使用 ToTensor 将图像转换为张量
train = CIFAR10(root='data', train=True, download=True, transform=Compose([ToTensor()]))
# TODO 加载测试集,使用 ToTensor 将图像转换为张量
valid = CIFAR10(root='data', train=False, download=True, transform=Compose([ToTensor()]))
# 输出训练集的数量
print('训练集数量:', len(train.targets))
# 输出测试集的数量
print('测试集数量:', len(valid.targets))
# 输出训练集中第一张图像的形状
print("数据集形状:", train[0][0].shape)
# 输出数据集类别及其对应的索引
print("数据集类别:", train.class_to_idx)
# 2. 数据加载器
def test02():
# 加载训练集,使用 ToTensor 将图像转换为张量
train = CIFAR10(root='data', train=True, transform=Compose([ToTensor()]))
# 创建数据加载器,每批加载 8 张图像,并打乱顺序
dataloader = DataLoader(train, batch_size=8, shuffle=True)
# 遍历数据加载器,取出一批数据
for x, y in dataloader:
# 输出一批数据的图像张量形状
print(x.shape)
# 输出一批数据的标签
print(y)
# 只取一批数据就跳出循环
break
# 主函数
if __name__ == '__main__':
# 运行数据集基本信息函数
test01()
# 运行数据加载器函数
test02()
3、搭建图像分类网络🔺
3.1、网络结构⭐
我们要搭建的网络结构如下:
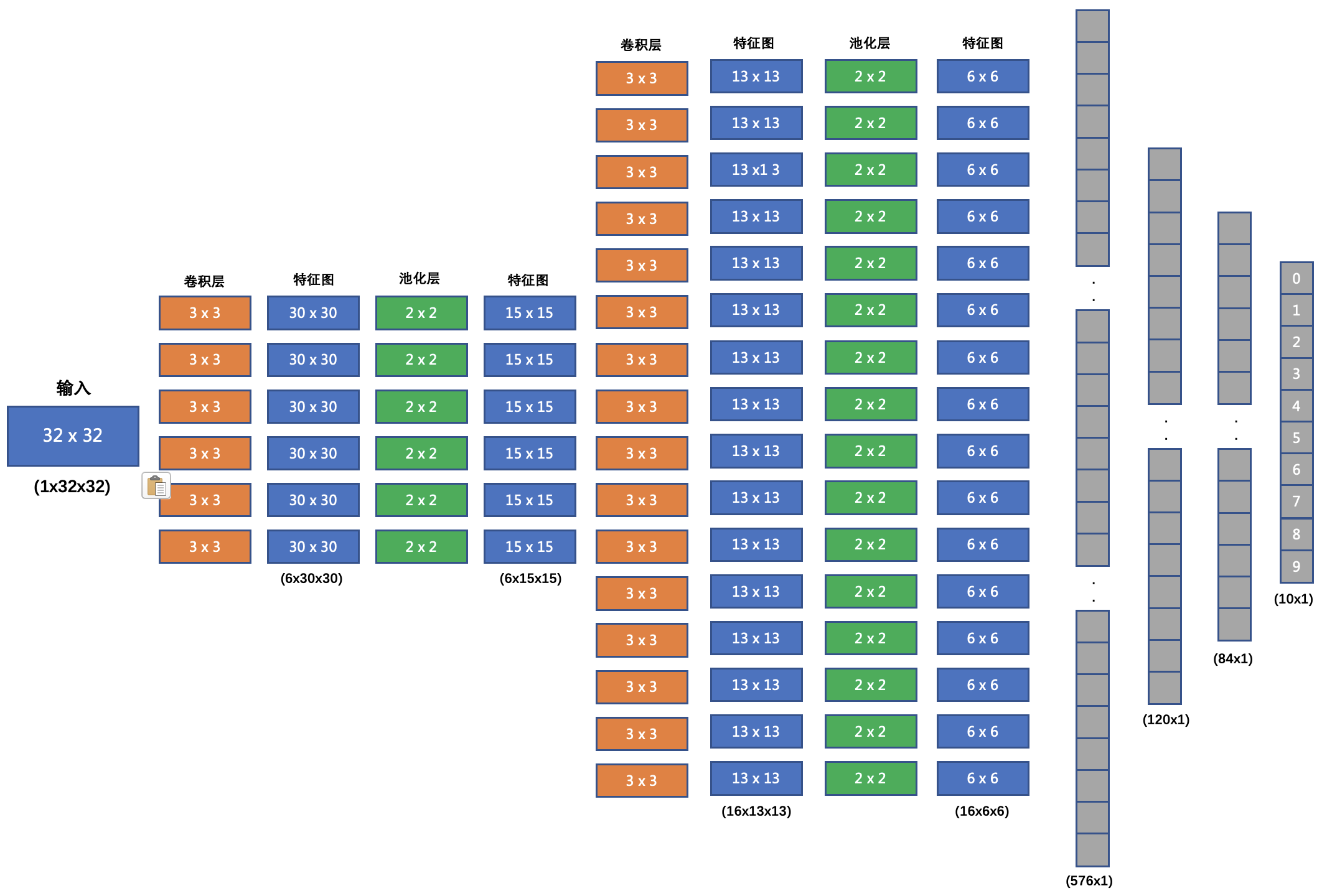
下面是这个图的详细解释:
- 输入形状:32x32
第一个卷积层:
- 输入 Channel:3(因为输入是一个 32×32 的彩色图像,有 RGB 三个通道)
- 输出 Channel:6(图中显示第一个卷积层有 6 个输出特征图,说明使用了 6 个卷积核)
- Kernel Size:3×33 \times 33×3(每个卷积核的大小)
第一个池化层输入 30x30, 输出 15x15, Kernel Size 为: 2x2, Stride 为: 2第二个卷积层输入 6 个 Channel, 输出 16 个 Channel, Kernel Size 为 3x3第二个池化层输入 13x13, 输出 6x6, Kernel Size 为: 2x2, Stride 为: 2第一个全连接层输入 576 维, 输出 120 维第二个全连接层输入 120 维, 输出 84 维- 最后的输出层输入 84 维, 输出 10 维
3.2、代码构建网络⭐
我们在每个卷积计算之后应用 relu 激活函数来给网络增加非线性因素。
relu函数公式:
ReLU
(
x
)
=
max
(
0
,
x
)
\text{ReLU}(x) = \max(0, x)
ReLU(x)=max(0,x)
网络代码实现——定义一个图像分类的神经网络类,继承自 nn.Module。
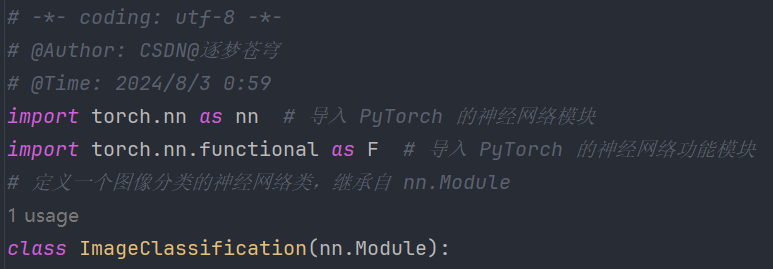
类里面实现两个方法:init(self)和forward(self, x):
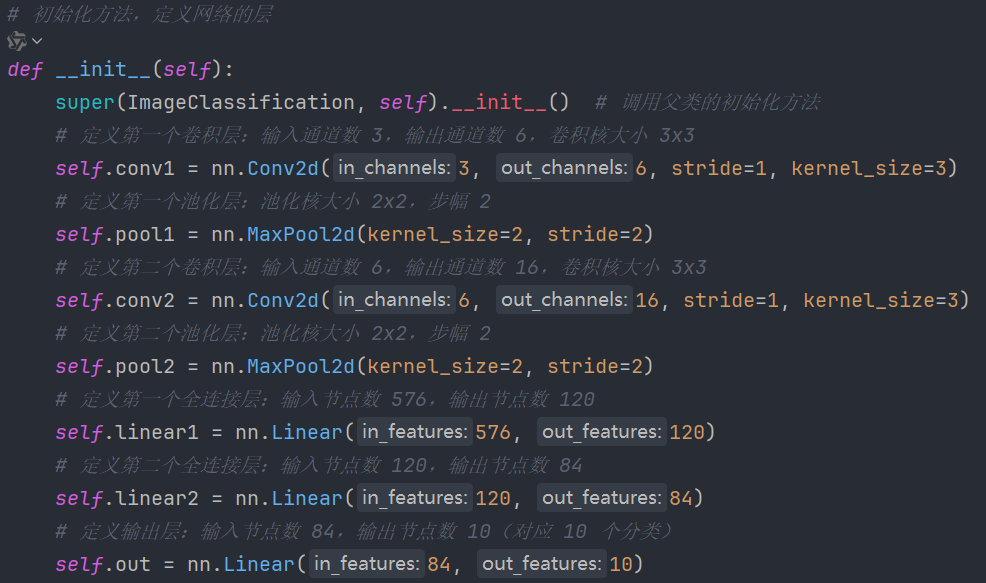
init(self)初始化:
forward(self, x)前向传播:
4、编写训练函数
我们的训练时,使用多分类交叉熵损失函数,Adam 优化器。
下面先简单复习一下这两个概念。
4.1、多分类交叉熵损失函数🔺
多分类交叉熵损失函数(Multiclass Cross-Entropy Loss)是深度学习中常用的损失函数,特别适用于多分类任务。
它计算模型 输出的概率分布与真实类别分布之间的差异。
对于一个具有
N
N
N 个样本和
C
C
C 类别的多分类问题,多分类交叉熵损失函数定义为:
Loss
=
−
1
N
∑
i
=
1
N
∑
c
=
1
C
y
i
,
c
log
(
y
^
i
,
c
)
\text{Loss} = -\frac{1}{N} \sum_{i=1}^{N} \sum_{c=1}^{C} y_{i,c} \log(\hat{y}_{i,c})
Loss=−N1∑i=1N∑c=1Cyi,clog(y^i,c)
其中:
- N N N 是样本数量。
- C C C 是类别数量。
- y i , c y_{i,c} yi,c 是样本 i i i 的真实标签,如果样本 i i i 的真实类别是 c c c,则 y i , c = 1 y_{i,c} = 1 yi,c=1,否则 y i , c = 0 y_{i,c} = 0 yi,c=0。
- y ^ i , c \hat{y}_{i,c} y^i,c 是模型对样本 i i i 的类别 c c c 的预测概率。
实现:
- 在PyTorch中,多分类交叉熵损失函数可以使用
torch.nn.CrossEntropyLoss类来实现。 - 该类结合了
nn.LogSoftmax和nn.NLLLoss,因此无需手动应用 softmax 函数到模型的输出。 CrossEntropyLoss会自动计算 softmax,然后再计算交叉熵损失。
4.2、Adam🔺
Adam简介:
Adam(Adaptive Moment Estimation)优化器是 深度学习中常用的一种优化算法。
它结合了AdaGrad和RMSProp的优点,既能够适应稀疏梯度,又能够处理非平稳目标。
Adam通过计算梯度的一阶和二阶矩估计来动态调整每个参数 的 学习率。
一阶动量是梯度的指数加权移动平均。它可以看作是梯度的平均值,表示了梯度的方向和大小。
二阶动量是梯度平方的指数加权移动平均。它可以看作是梯度的方差,表示了梯度的变化范围。
Adam 优化器的关键特点:
- 自适应学习率:每个参数都有独立的学习率,可以根据一阶和二阶梯度估计动态调整。
- 计算效率:相对于简单的随机梯度下降 (SGD),
Adam计算效率高,存储需求小。- 适用于大规模数据集:在处理大规模数据集和高维参数空间时表现优越。
- 默认超参数效果好:在许多情况下,Adam的默认超参数配置能取得很不错的效果。
Adam通过以下公式来更新参数:
- 计算梯度的移动平均:
- m t = β 1 m t − 1 + ( 1 − β 1 ) g t m_t = \beta_1 m_{t-1} + (1 - \beta_1) g_t mt=β1mt−1+(1−β1)gt
- v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 v_t = \beta_2 v_{t-1} + (1 - \beta_2) g_t^2 vt=β2vt−1+(1−β2)gt2
- 其中, g t g_t gt 是当前时间步的梯度, m t m_t mt 和 v t v_t vt 分别是梯度的一阶和二阶矩的移动平均, β 1 \beta_1 β1 和 β 2 \beta_2 β2 是衰减率(通常取 β 1 = 0.9 \beta_1 = 0.9 β1=0.9 和 β 2 = 0.999 \beta_2 = 0.999 β2=0.999)。
- 偏差修正:
- m t ^ = m t 1 − β 1 t \hat{m_t} = \frac{m_t}{1 - \beta_1^t} mt^=1−β1tmt
- v t ^ = v t 1 − β 2 t \hat{v_t} = \frac{v_t}{1 - \beta_2^t} vt^=1−β2tvt
- 参数更新:
- θ t = θ t − 1 − α m t ^ v t ^ + ϵ \theta_t = \theta_{t-1} - \alpha \frac{\hat{m_t}}{\sqrt{\hat{v_t}} + \epsilon} θt=θt−1−αvt^+ϵmt^
- 其中, α \alpha α 是学习率, ϵ \epsilon ϵ 是一个小常数(防止分母为零,通常取 1 0 − 8 10^{-8} 10−8)。
4.3、训练函数代码
4.3.1、代码
# 训练模型
def train(BATCH_SIZE, epoch) -> None:
"""
Args:
BATCH_SIZE (int): 批量大小。
epoch (int): 训练轮数。
"""
# 定义图像转换操作,将图像转换为张量
transgform = Compose([ToTensor()])
# 加载 CIFAR10 训练集,并应用定义的图像转换操作
cifar10 = torchvision.datasets.CIFAR10(root='data', train=True, download=True, transform=transgform)
# TODO 构建图像分类模型, 此时完成卷积神经网络初始化
model = ImageClassification()
# 定义损失函数为交叉熵损失
criterion = nn.CrossEntropyLoss()
# 定义优化器为 Adam,学习率为 1e-3
optimizer = optim.Adam(model.parameters(), lr=1e-3)
for epoch_idx in range(epoch):
# 构建数据加载器,批次大小为 BATCH_SIZE,打乱数据顺序
dataloader = DataLoader(cifar10, batch_size=BATCH_SIZE, shuffle=True)
# 初始化样本数量
sam_num = 0
# 初始化损失总和
total_loss = 0.0
# 记录开始时间
start = time.time()
# 初始化正确分类样本数量
correct = 0
for x, y in dataloader:
# TODO 开始训练
# 将输入数据送入模型,得到输出
output = model(x)
# 计算损失
loss = criterion(output, y)
# 梯度清零
optimizer.zero_grad()
# 反向传播,计算梯度
loss.backward()
# 更新模型参数
optimizer.step()
# 计算正确分类的样本数量
correct += (torch.argmax(output, dim=-1) == y).sum().item()
# 累加损失
total_loss += (loss.item() * len(y))
# 累加样本数量
sam_num += len(y)
# 打印每个 epoch 的损失、准确率和训练时间
print('epoch:%2s loss:%.5f acc:%.2f time:%.2fs' %
(epoch_idx + 1,
total_loss / sam_num,
correct / sam_num,
time.time() - start))
# 序列化模型,将模型参数保存到文件
torch.save(model.state_dict(), 'model/image_classification.bin')
4.3.2、训练过程说明⭐
- 定义图像转换操作
- 加载 CIFAR10 训练集
- 构建图像分类模型
- 定义损失函数
- 定义优化器
- 进行多个 epoch 的训练:
- 6.1 构建数据加载器:
- 使用
DataLoader构建数据加载器,设置批次大小为BATCH_SIZE,并打乱数据顺序。- 6.2 初始化样本数量计数器:
sam_num初始化为 0,用于记录样本数量。- 6.3 初始化损失总和计数器:
total_loss初始化为 0.0,用于累加每个批次的损失。- 6.4 初始化正确分类样本数量计数器:
- 6.5 进行一个批次的训练:
- 6.5.1 将输入数据送入模型
- 6.5.2 计算损失——计算预测输出与真实标签之间的损失
- 6.5.3 梯度清零
- 6.5.4 反向传播,计算梯度:
loss.backward()- 6.5.5 更新模型参数:
optimizer.step()- 6.5.6 计算正确分类的样本数量
- 6.5.7 累加当前批次的损失
- 6.5.8 累加当前批次的样本数量
4.3.3、重要代码解读

分步解释:
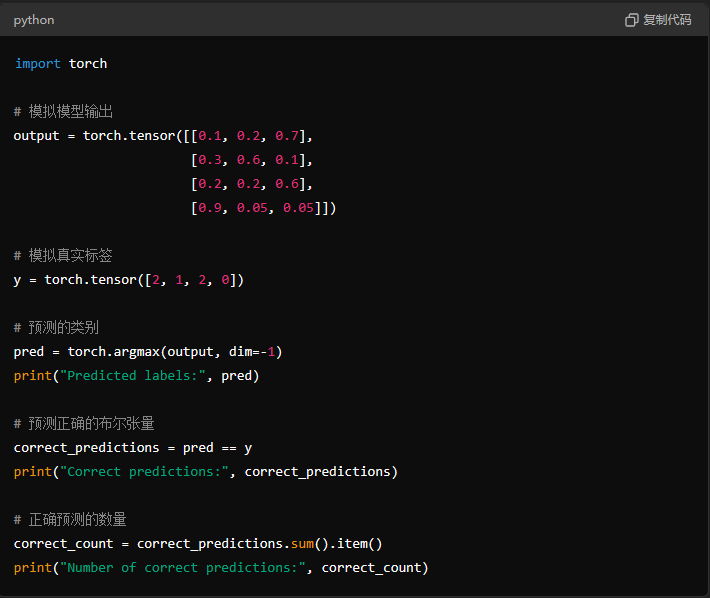
- torch.argmax(output, dim=-1):
torch.argmax函数返回指定维度上最大值的索引。output是模型的输出,通常是一个包含预测分数的张量。dim=-1指定在最后一个维度上寻找最大值的索引,通常这个维度对应于类别的维度。- 结果是一个张量,其中包含每个样本的预测类别索引。
- (torch.argmax(output, dim=-1) == y):
y是实际的标签张量。torch.argmax(output, dim=-1)计算得到的是模型的预测类别索引。- sum():
- 对布尔张量中的元素求和。
- 在 PyTorch 中,布尔值
True被视为1,False被视为0。
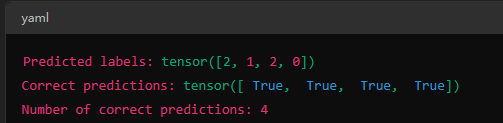
假设有一个批次的输出 output 和真实标签 y,形状分别为 [4, 3] 和 [4]:
输出结果为:
5、预测函数
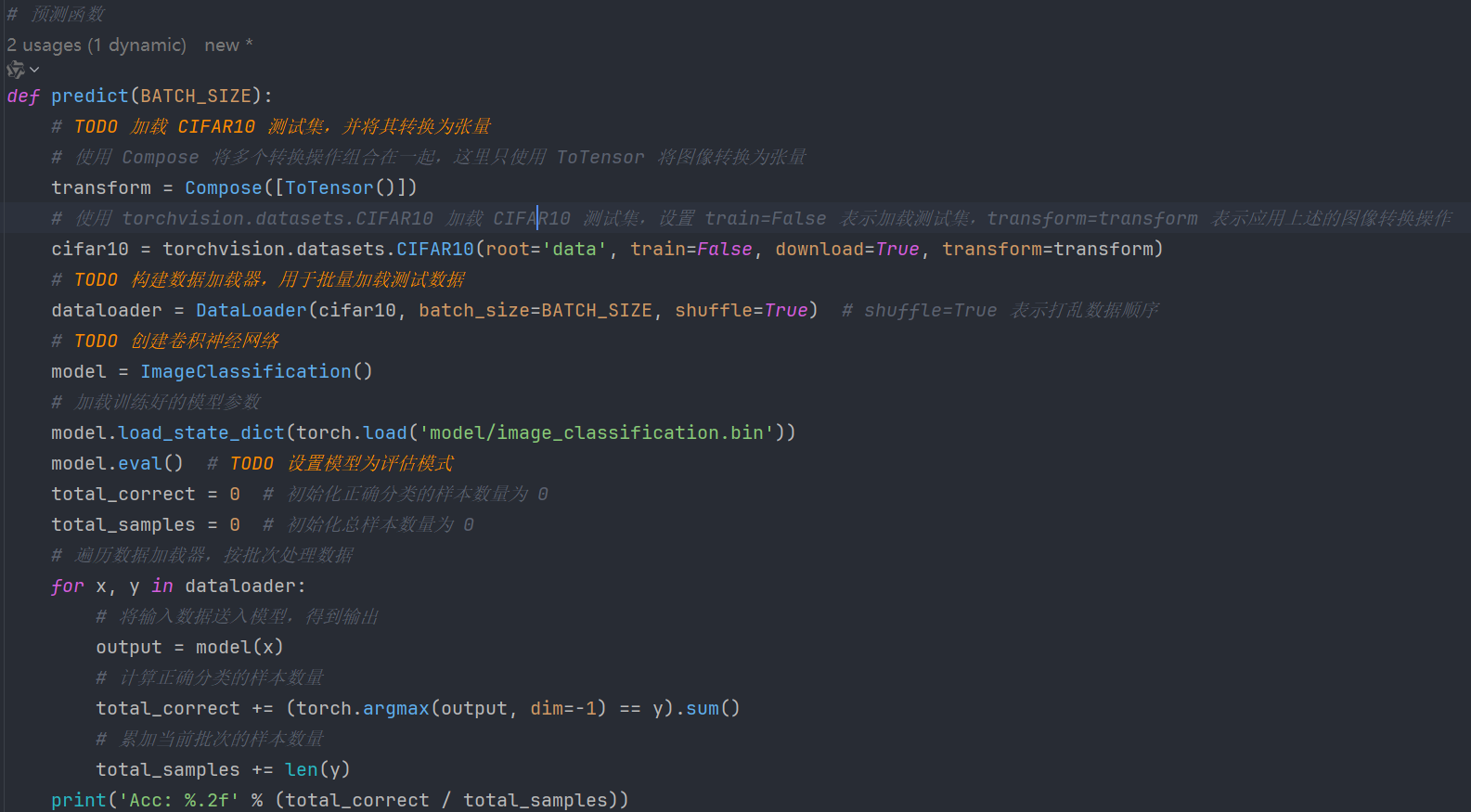
5.1、代码
我们加载训练好的模型,对测试集中的 1 万条样本进行预测,查看模型在测试集上的准确率。
代码总览:
程序输出结果(这是读取训练10轮的模型):

训练过程:
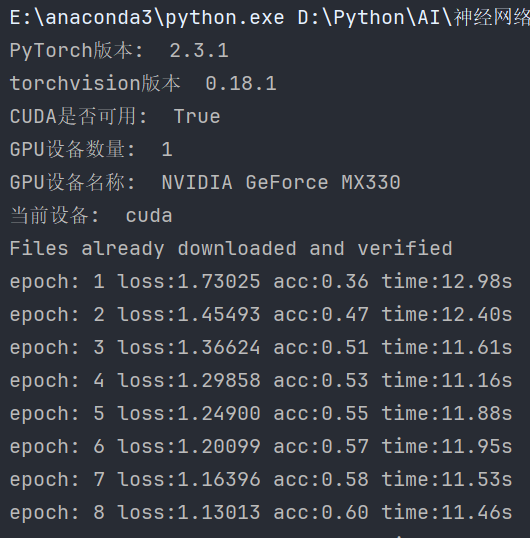
我独显的算力不行,凑合看吧😭
5.2、model.eval()⭐
在深度学习中,模型在训练和评估(推理)阶段的行为可能会有所不同。
PyTorch 提供了 model.train() 和 model.eval() 两种模式,用于切换模型在训练和评估时的行为。
model.train() 与 model.eval():
- model.train():
- 用于设置模型为训练模式。
- 这会启用训练时特有的操作,例如 Dropout 和 Batch Normalization。
- Dropout 在训练时会随机地丢弃部分神经元,以防止过拟合;Batch Normalization 在训练时会根据当前批次的数据动态调整均值和方差。
- model.eval():
- 用于设置模型为评估模式。
- 这会关闭训练时特有的操作,例如 Dropout 和 Batch Normalization 的动态调整。
- Dropout 在评估时不丢弃任何神经元;Batch Normalization 在评估时使用训练时计算的全局均值和方差,而不是当前批次的数据。
6、完整代码
6.1、CPU
# -*- coding: utf-8 -*-
# @Author: CSDN@逐梦苍穹
# @Time: 2024/8/3 2:21
import torch # 导入 PyTorch 主库
import torch.nn.functional as F # 导入 PyTorch 的神经网络功能模块
import torch.nn as nn # 导入 PyTorch 的神经网络模块
import torch.optim as optim # 导入 PyTorch 的优化器模块
import torchvision # 导入 PyTorch 的计算机视觉工具包
from torchvision.transforms import Compose # 导入 Compose 用于组合多个数据变换
from torchvision.transforms import ToTensor # 导入 ToTensor 用于将图像转换为张量
from torch.utils.data import DataLoader # 导入数据加载器模块
import time # 导入时间模块
# 定义一个图像分类的神经网络类,继承自 nn.Module
class ImageClassification(nn.Module):
# 初始化方法,定义网络的层
def __init__(self):
super(ImageClassification, self).__init__() # 调用父类的初始化方法
# 定义第一个卷积层:输入通道数 3,输出通道数 6,卷积核大小 3x3
self.conv1 = nn.Conv2d(3, 6, stride=1, kernel_size=3)
# 定义第一个池化层:池化核大小 2x2,步幅 2
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
# 定义第二个卷积层:输入通道数 6,输出通道数 16,卷积核大小 3x3
self.conv2 = nn.Conv2d(6, 16, stride=1, kernel_size=3)
# 定义第二个池化层:池化核大小 2x2,步幅 2
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# 定义第一个全连接层:输入节点数 576,输出节点数 120
self.linear1 = nn.Linear(576, 120)
# 定义第二个全连接层:输入节点数 120,输出节点数 84
self.linear2 = nn.Linear(120, 84)
# 定义输出层:输入节点数 84,输出节点数 10(对应 10 个分类)
self.out = nn.Linear(84, 10)
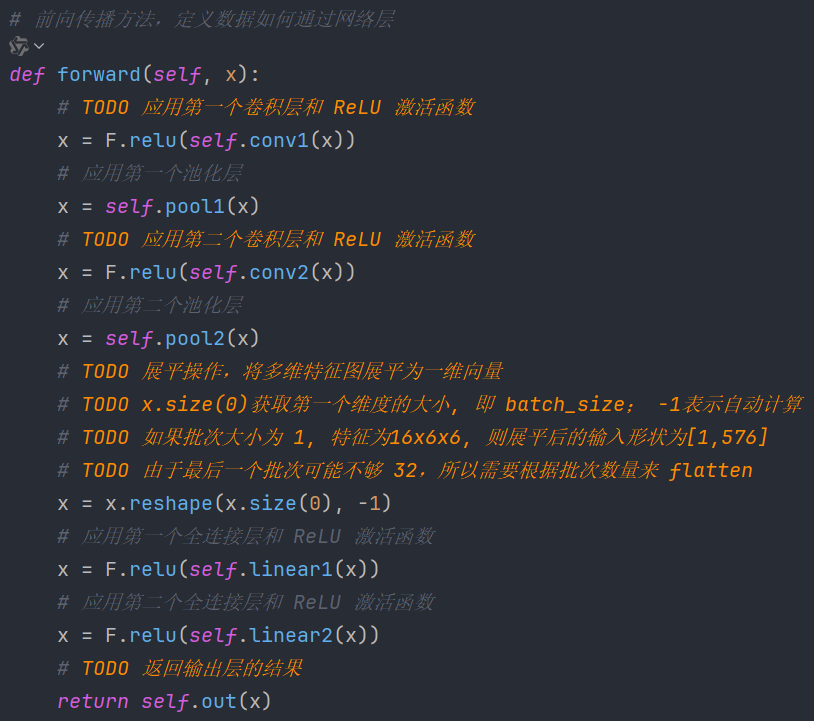
# 前向传播方法,定义数据如何通过网络层
def forward(self, x):
# TODO 应用第一个卷积层和 ReLU 激活函数
x = F.relu(self.conv1(x))
# 应用第一个池化层
x = self.pool1(x)
# TODO 应用第二个卷积层和 ReLU 激活函数
x = F.relu(self.conv2(x))
# 应用第二个池化层
x = self.pool2(x)
# TODO 展平操作,将多维特征图展平为一维向量
# TODO x.size(0)获取第一个维度的大小, 即 batch_size; -1表示自动计算
# TODO 如果批次大小为 1, 特征为16x6x6, 则展平后的输入形状为[1,576]
# TODO 由于最后一个批次可能不够 32,所以需要根据批次数量来 flatten
x = x.reshape(x.size(0), -1)
# 应用第一个全连接层和 ReLU 激活函数
x = F.relu(self.linear1(x))
# 应用第二个全连接层和 ReLU 激活函数
x = F.relu(self.linear2(x))
# TODO 返回输出层的结果
return self.out(x)
# 训练模型
def train(BATCH_SIZE, epoch) -> None:
"""
Args:
BATCH_SIZE (int): 批量大小。
epoch (int): 训练轮数。
"""
# 定义图像转换操作,将图像转换为张量
transgform = Compose([ToTensor()])
# 加载 CIFAR10 训练集,并应用定义的图像转换操作
cifar10 = torchvision.datasets.CIFAR10(root='data', train=True, download=True, transform=transgform) # TODO train=False测试集
# TODO 构建图像分类模型, 此时完成卷积神经网络初始化
model = ImageClassification()
# 定义损失函数为交叉熵损失
criterion = nn.CrossEntropyLoss()
# 定义优化器为 Adam,学习率为 1e-3
optimizer = optim.Adam(model.parameters(), lr=1e-3)
for epoch_idx in range(epoch):
# 构建数据加载器,批次大小为 BATCH_SIZE,打乱数据顺序
dataloader = DataLoader(cifar10, batch_size=BATCH_SIZE, shuffle=True)
# 初始化样本数量
sam_num = 0
# 初始化损失总和
total_loss = 0.0
# 记录开始时间
start = time.time()
# 初始化正确分类样本数量
correct = 0
for x, y in dataloader:
# TODO 开始训练
# 将输入数据送入模型,得到输出
output = model(x)
# 计算损失
loss = criterion(output, y)
# 梯度清零
optimizer.zero_grad()
# 反向传播,计算梯度
loss.backward()
# 更新模型参数
optimizer.step()
# 计算正确分类的样本数量
correct += (torch.argmax(output, dim=-1) == y).sum().item()
# 累加损失
total_loss += (loss.item() * len(y))
# 累加样本数量
sam_num += len(y)
# 打印每个 epoch 的损失、准确率和训练时间
print('epoch:%2s loss:%.5f acc:%.2f time:%.2fs' %
(epoch_idx + 1,
total_loss / sam_num,
correct / sam_num,
time.time() - start))
# 序列化模型,将模型参数保存到文件
torch.save(model.state_dict(), 'model/image_classification.bin')
# 预测函数
def predict(BATCH_SIZE):
# TODO 加载 CIFAR10 测试集,并将其转换为张量
# 使用 Compose 将多个转换操作组合在一起,这里只使用 ToTensor 将图像转换为张量
transform = Compose([ToTensor()])
# 使用 torchvision.datasets.CIFAR10 加载 CIFAR10 测试集,设置 train=False 表示加载测试集,transform=transform 表示应用上述的图像转换操作
cifar10 = torchvision.datasets.CIFAR10(root='data', train=False, download=True, transform=transform) # TODO train=False测试集
# TODO 构建数据加载器,用于批量加载测试数据
dataloader = DataLoader(cifar10, batch_size=BATCH_SIZE, shuffle=True) # shuffle=True 表示打乱数据顺序
# TODO 创建卷积神经网络
model = ImageClassification()
# 加载训练好的模型参数
model.load_state_dict(torch.load('model/image_classification.bin'))
model.eval() # TODO 设置模型为评估模式
total_correct = 0 # 初始化正确分类的样本数量为 0
total_samples = 0 # 初始化总样本数量为 0
# 遍历数据加载器,按批次处理数据
for x, y in dataloader:
# 将输入数据送入模型,得到输出
output = model(x)
# 计算正确分类的样本数量
total_correct += (torch.argmax(output, dim=-1) == y).sum()
# 累加当前批次的样本数量
total_samples += len(y)
print('Acc: %.2f' % (total_correct / total_samples))
if __name__ == '__main__':
train(BATCH_SIZE=32, epoch=10) # 训练模型, 批次大小为 32, 训练轮数为 10
predict(BATCH_SIZE=32) # 测试模型, 批次大小为 32
6.2、GPU
# -*- coding: utf-8 -*-
# @Author: CSDN@逐梦苍穹
# @Time: 2024/8/3 2:29
# -*- coding: utf-8 -*-
# @Author: CSDN@逐梦苍穹
# @Time: 2024/8/3 2:21
import torch # 导入 PyTorch 主库
import torch.nn.functional as F # 导入 PyTorch 的神经网络功能模块
import torch.nn as nn # 导入 PyTorch 的神经网络模块
import torch.optim as optim # 导入 PyTorch 的优化器模块
import torchvision # 导入 PyTorch 的计算机视觉工具包
from torchvision.transforms import Compose # 导入 Compose 用于组合多个数据变换
from torchvision.transforms import ToTensor # 导入 ToTensor 用于将图像转换为张量
from torch.utils.data import DataLoader # 导入数据加载器模块
import time # 导入时间模块
# 定义一个图像分类的神经网络类,继承自 nn.Module
class ImageClassification(nn.Module):
# 初始化方法,定义网络的层
def __init__(self):
super(ImageClassification, self).__init__() # 调用父类的初始化方法
# 定义第一个卷积层:输入通道数 3,输出通道数 6,卷积核大小 3x3
self.conv1 = nn.Conv2d(3, 6, stride=1, kernel_size=3)
# 定义第一个池化层:池化核大小 2x2,步幅 2
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
# 定义第二个卷积层:输入通道数 6,输出通道数 16,卷积核大小 3x3
self.conv2 = nn.Conv2d(6, 16, stride=1, kernel_size=3)
# 定义第二个池化层:池化核大小 2x2,步幅 2
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# 定义第一个全连接层:输入节点数 576,输出节点数 120
self.linear1 = nn.Linear(576, 120)
# 定义第二个全连接层:输入节点数 120,输出节点数 84
self.linear2 = nn.Linear(120, 84)
# 定义输出层:输入节点数 84,输出节点数 10(对应 10 个分类)
self.out = nn.Linear(84, 10)
# 前向传播方法,定义数据如何通过网络层
def forward(self, x):
# TODO 应用第一个卷积层和 ReLU 激活函数
x = F.relu(self.conv1(x))
# 应用第一个池化层
x = self.pool1(x)
# TODO 应用第二个卷积层和 ReLU 激活函数
x = F.relu(self.conv2(x))
# 应用第二个池化层
x = self.pool2(x)
# TODO 展平操作,将多维特征图展平为一维向量
# TODO x.size(0)获取第一个维度的大小, 即 batch_size; -1表示自动计算
# TODO 如果批次大小为 1, 特征为16x6x6, 则展平后的输入形状为[1,576]
# TODO 由于最后一个批次可能不够 32,所以需要根据批次数量来 flatten
x = x.reshape(x.size(0), -1)
# 应用第一个全连接层和 ReLU 激活函数
x = F.relu(self.linear1(x))
# 应用第二个全连接层和 ReLU 激活函数
x = F.relu(self.linear2(x))
# TODO 返回输出层的结果
return self.out(x)
# 训练模型
def train(BATCH_SIZE, epoch) -> None:
"""
Args:
BATCH_SIZE (int): 批量大小。
epoch (int): 训练轮数。
"""
# 定义图像转换操作,将图像转换为张量
transform = Compose([ToTensor()])
# 加载 CIFAR10 训练集,并应用定义的图像转换操作
cifar10 = torchvision.datasets.CIFAR10(root='data', train=True, download=True, transform=transform)
# TODO 构建图像分类模型, 并将模型移动到设备上
model = ImageClassification().to(device)
# 定义损失函数为交叉熵损失
criterion = nn.CrossEntropyLoss()
# 定义优化器为 Adam,学习率为 1e-3
optimizer = optim.Adam(model.parameters(), lr=1e-3)
for epoch_idx in range(epoch):
# 构建数据加载器,批次大小为 BATCH_SIZE,打乱数据顺序
dataloader = DataLoader(cifar10, batch_size=BATCH_SIZE, shuffle=True)
# 初始化样本数量
sam_num = 0
# 初始化损失总和
total_loss = 0.0
# 记录开始时间
start = time.time()
# 初始化正确分类样本数量
correct = 0
for x, y in dataloader:
# TODO 将输入数据移动到设备上
x, y = x.to(device), y.to(device)
# 将输入数据送入模型,得到输出
output = model(x)
# 计算损失
loss = criterion(output, y)
# 梯度清零
optimizer.zero_grad()
# 反向传播,计算梯度
loss.backward()
# 更新模型参数
optimizer.step()
# 计算正确分类的样本数量
correct += (torch.argmax(output, dim=-1) == y).sum().item()
# 累加损失
total_loss += (loss.item() * len(y))
# 累加样本数量
sam_num += len(y)
# 打印每个 epoch 的损失、准确率和训练时间
print('epoch:%2s loss:%.5f acc:%.2f time:%.2fs' %
(epoch_idx + 1,
total_loss / sam_num,
correct / sam_num,
time.time() - start))
# 序列化模型,将模型参数保存到文件
torch.save(model.state_dict(), 'model-gpu/image_classification.bin')
# 预测函数
def predict(BATCH_SIZE):
print('device:', device)
# TODO 加载 CIFAR10 测试集,并将其转换为张量
# 使用 Compose 将多个转换操作组合在一起,这里只使用 ToTensor 将图像转换为张量
transform = Compose([ToTensor()])
# 使用 torchvision.datasets.CIFAR10 加载 CIFAR10 测试集,设置 train=False 表示加载测试集,transform=transform 表示应用上述的图像转换操作
cifar10 = torchvision.datasets.CIFAR10(root='data', train=False, download=True, transform=transform)
# TODO 构建数据加载器,用于批量加载测试数据
dataloader = DataLoader(cifar10, batch_size=BATCH_SIZE, shuffle=True) # shuffle=True 表示打乱数据顺序
# TODO 创建卷积神经网络
model = ImageClassification()
# 加载训练好的模型参数
model.load_state_dict(torch.load('model-gpu/image_classification.bin'))
model.to(device) # TODO 将模型移动到设备上
model.eval() # TODO 设置模型为评估模式
total_correct = 0 # 初始化正确分类的样本数量为 0
total_samples = 0 # 初始化总样本数量为 0
# 遍历数据加载器,按批次处理数据
for x, y in dataloader:
# TODO 将输入数据移动到设备上
x, y = x.to(device), y.to(device)
# 将输入数据送入模型,得到输出
output = model(x)
# 计算正确分类的样本数量
total_correct += (torch.argmax(output, dim=-1) == y).sum().item()
# 累加当前批次的样本数量
total_samples += len(y)
print('Acc: %.2f' % (total_correct / total_samples))
if __name__ == '__main__':
# 选择运行设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print("PyTorch版本: ", torch.__version__) # 打印PyTorch版本
print("torchvision版本 ", torchvision.__version__) # 打印torchvision版本
print("CUDA是否可用: ", torch.cuda.is_available()) # 检查CUDA是否可用
print("GPU设备数量: ", torch.cuda.device_count())
print("GPU设备名称: ", torch.cuda.get_device_name(0))
print("当前设备: ", device)
# train(BATCH_SIZE=32, epoch=100) # 训练模型, 批次大小为 32, 训练轮数为 10
predict(BATCH_SIZE=32) # 测试模型, 批次大小为 32
7、改进之处🔺
网络模型还可以以下几个方面来调整:
- 增加卷积核输出通道数
- 增加全连接层的参数量
- 调整学习率
- 调整优化方法
- 修改激活函数
- 等等…
比如,对网络参数微调,让网络参数量增加,然后再调整一下学习率,由 1e-3 修改为 1e-4等等操作。

网络模型修改:
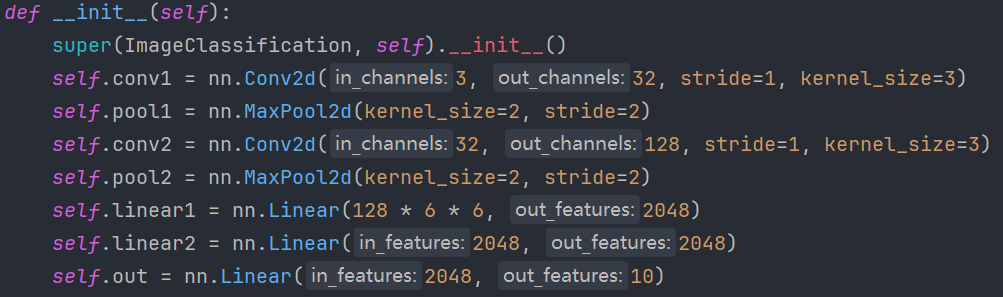
可以看到,就是增加了整个卷积神经网络的复杂性。
训练十次差不多提高准确率0.1,训练100次肯定更明显!
100次的你们去跑吧…这网络复杂度上来了,我这设备干不动了……😭
8、小结
本文主要讲解了如何使用卷积层和池化层来设计、构建一个卷积神经网络。
回顾一下训练过程:
- 定义损失函数
- 定义优化器
- 进行多个 epoch 的训练:
- 3.1 构建数据加载器
- 3.2 初始化样本数量计数器
- 3.3 初始化损失总和计数器
- 3.4 初始化正确分类样本数量计数器
- 3.5 进行一个批次的训练
- 3.5.1 将输入数据送入模型
- 3.5.2 计算损失
- 3.5.3 梯度清零
- 3.5.4 反向传播,计算梯度
- 3.5.5 更新模型参数
- 3.5.6 计算正确分类的样本数量
- 3.5.7 累加当前批次的损失
- 3.5.8 累加当前批次的样本数量




![Redis学习[5] ——Redis过期删除和内存淘汰](https://i-blog.csdnimg.cn/direct/0d8590b79bcd46bfb0fd5ad37e44b4ca.png)