大型语言模型(LLMs)在许多不同的自然语言处理(NLP)任务上表现出了显著的性能。提示工程在提升LLMs已有能力方面发挥着关键作用,使其在各种NLP任务上取得了显著的性能提升。提示工程需要编写自然语言指令,即提示,以结构化的方式从LLMs中提取知识。与以往的最先进(SoTA)模型不同,提示工程不需要根据给定的NLP任务进行广泛的参数重新训练或微调,而是仅依赖于LLMs的内嵌知识。此外,LLMs的爱好者可以通过基本的自然语言对话交换或提示工程,智能地提取LLMs的知识,使得越来越多的人即使没有深厚的数学机器学习背景,也能与LLMs进行实验。随着提示工程在过去两年中越来越受欢迎,研究人员提出了许多围绕设计提示以提高从LLMs中提取信息准确性的工程技术。在本文中,我们总结了不同的提示技术,并将它们根据不同的NLP任务进行分类。我们进一步详细突出了这些提示策略在各种数据集上的性能,讨论了相应的LLMs的使用情况,展示了分类图,并讨论了特定数据集的可能SoTA。总的来说,我们阅读并展示了44篇研究论文的调查,其中讨论了29个不同NLP任务上的39种不同的提示方法,其中大部分已在最近两年内发表。

1 引言
随着LLMs的引入,人工智能取得了显著的进步。LLMs在包含数百万甚至数十亿个标记的大量文本文档上进行训练。已经证明,随着模型参数数量的增加,机器学习模型的性能会提高,LLMs也是如此。由于这些原因,它们在广泛的NLP任务上取得了前所未有的性能(Chang等人,2023年),因此吸引了学术界和包括医学、法律、金融等多个行业的极大兴趣。目前对LLMs的研究重点在于通过提示而不是仅仅预测下一个标记来提高它们的推理能力,这开辟了提示工程的新研究领域。
提示工程是创建自然语言指令或提示的过程,以有组织的方式从LLMs中提取知识。与早期的传统模型不同,提示工程仅依赖于LLMs的内嵌知识,不需要根据底层NLP任务进行广泛的参数重新训练或微调。理解模型参数在现实世界知识中的含义超出了人类的能力,因此这个新的提示工程领域引起了所有人的注意,因为它允许研究人员与LLMs之间通过自然语言交换来实现底层NLP任务的目标。
在这项工作中,我们列举了几种提示策略,并根据它们被使用的不同的NLP任务对它们进行分组。我们提供了一个分类图,列出了在不同NLP任务的不同数据集上尝试的各种提示技术,讨论了所使用的LLMs,并列出每个数据集的潜在SoTA方法。作为这项调查的一部分,我们总共回顾并分析了44篇研究论文,其中大部分在前两年发表,涵盖了29个不同的NLP任务上应用的39种提示技术。以前没有很多系统的提示工程调查。Sahoo等人(2024年)基于它们的应用调查了29种提示技术论文。这是一个非常广泛的分类,因为一个单一的应用可以包含许多NLP任务。例如,他们讨论的一个应用是推理和逻辑,这可以包含诸如常识推理、数学问题解决、多跳推理等众多NLP任务。这与我们的方法不同,我们根据NLP任务对提示策略进行了更细粒度的分类。Edemacu和Wu(2024)提供了一个隐私保护提示方法的概述,因此专注于提示工程的相对较小的子领域。Chen等人(2023)将提示策略的讨论限制在一些9-10种方法上,并且也没有将它们根据NLP任务进行分类。
本文的其余部分组织如下。第2节讨论了各种提示工程技术;第3节突出了不同的NLP任务。第3节的小节讨论了在给定NLP任务上应用的不同提示策略及其相应的结果。第4节总结了本文。
2 提示工程技术
在本节中,我们将简要讨论不同的提示方法以及它们如何在发布时带来现有性能的改进。一个重要的注意事项是,以下大多数提示策略都至少在两种不同的变体或设置中进行了实验,如果没有更多的话。这些变体包括零样本(zero-shot)和少样本(few-shot)。一些提示技术可能本质上存在于零样本或少样本变体中,可能没有其他变体存在的可能性。在零样本设置中(Radford et al., 2019),没有涉及训练数据,而是要求LLM通过提示指令执行任务,同时完全依赖于其在预训练阶段学习到的内嵌知识。另一方面,在少样本变体中(Brown et al., 2020),提供了少量训练数据点以及基于任务的提示指令,以更好地理解任务。各种提示工程工作的结果表明,少样本变体有助于提高性能,但这需要仔细准备少样本数据点,因为LLM可能对策划的少样本数据点表现出无法解释的偏见。
2.1 基础提示(Basic/Standard/Vanilla Prompting)
基础提示是指直接向LLM提出查询的方法,无需对其进行任何工程改进以提高性能,这是大多数提示策略背后的核心目标。基础提示在不同的研究论文中也被称为标准或香草提示。
2.2 思维链(Chain-of-Thought, COT)
在这种提示策略中(Wei et al., 2022),作者们建立了一个想法,即人类如何将复杂问题分解为更小、更容易的子问题,然后才到达复杂问题的最终解决方案。同样地,作者们研究了LLMs通过产生思维链或一系列中间推理步骤来增强其复杂推理能力的能力。结果显示,与基础提示相比,COT有相当大的改进,COT和基础提示结果之间的最大差异在数学问题解决任务中约为39%,在常识推理任务中约为26%。这项工作为提示工程领域开辟了一个新的研究方向。
2.3 自洽性(Self-Consistency)
自洽性提示技术(Wang et al., 2022)基于这样一个直觉:复杂推理问题可以通过多种方式解决,因此可以通过不同的推理路径达到正确答案。自洽性使用了一个新颖的解码策略,与COT使用的贪婪策略不同,包括三个重要步骤。第一步需要使用COT提示LLM,第二步从LLM的解码器中采样多样化的推理路径,最后一步涉及在多个推理路径中选择最一致的答案。与COT相比,自洽性在数学问题解决任务上平均提高了11%,在常识推理任务上提高了3%,在多跳推理任务上提高了6%。
2.4 集成精炼(Ensemble Refinement, ER)
这种提示方法在Singhal et al. (2023)中进行了讨论。它建立在COT和自洽性之上。ER包括两个阶段。首先,给定一个少样本COT提示和一个查询,通过调整其温度,使LLM产生多个生成。每个生成包含对查询的推理和答案。接下来,LLM被条件化到原始提示、查询和前一阶段的连接生成上,以生成更好的解释和答案。这个第二阶段会多次进行,然后像自洽性一样对这些第二阶段生成的答案进行多数投票,以选择最终答案。ER在许多属于上下文无关问答任务的数据集上的表现优于COT和自洽性。
2.5 自动思维链(Automatic Chain-of-Thought, Auto-COT)
在这项工作中(Zhang et al., 2022),作者们解决了少样本CoT或手动CoT面临的问题,即需要策划高质量的训练数据点。Auto-CoT包括两个主要步骤。第一步要求将给定数据集的查询分成几个簇。第二步涉及从每个簇中选择一个代表性查询,然后使用零样本CoT生成相应的思维链。作者声称Auto-CoT在数学问题解决、多跳推理和常识推理任务上的表现要么优于要么匹配少样本CoT。这表明可以排除为少样本或手动CoT策划训练数据点的步骤。
2.6 复杂思维链(Complex Chain-of-Thought, Complex CoT)
Fu等人(2022)介绍了一种新的提示策略,旨在选择复杂数据点提示而不是更简单的提示。这里定义的数据点的复杂性是通过涉及的推理步骤数量来衡量的。作者假设,如果使用复杂数据点作为上下文训练示例,可以增加LLMs的推理性能,因为它们已经包含了更简单的数据点。Complex CoT除了使用复杂数据点作为训练示例外,另一个重要方面是,在解码过程中,就像自洽性一样,在N个采样的推理链中,选择前K个最复杂链的多数答案作为最终答案。本文还介绍了另一种基线提示方法,称为随机CoT。在随机CoT中,数据点是随机采样的,而不考虑它们的复杂性。Complex CoT在数学问题解决、常识推理、基于表格的数学问题解决和多跳推理任务的各种数据集上平均提高了5.3%的准确率,最高可达18%。
2.7 思维程序(Program-of-Thoughts, POT)
Chen等人(2022a)在CoT的基础上构建,与CoT使用LLMs执行推理和计算不同,POT生成Python程序,从而将计算部分交给Python解释器。这项工作认为,减少LLMs的责任使其在数值推理方面更准确。POT在数学问题解决、基于表格的数学问题解决、上下文问答和对话上下文问答任务上比CoT平均提高了约12%的性能。
2.8 从少到多(Least-to-Most)
Zhou等人(2022)的提示技术试图解决CoT在准确解决比示例更难的问题时失败的问题。它包括两个阶段。首先,LLM被提示将给定问题分解为子问题。接下来,LLM被提示按顺序解决子问题。任何子问题的答案都依赖于前一个子问题的答案。作者表明,Least-to-Most提示在常识推理、基于语言的任务完成、数学问题解决和上下文问答任务上显著优于CoT和基础提示方法。
2.9 符号链(Chain-of-Symbol, CoS)
Hu等人(2023)在CoT的基础上构建。在传统的CoT中,中间推理步骤以自然语言表达。这种方法在许多情况下都取得了显著的结果,但可能包含错误或冗余信息。本文的作者提出假设,空间描述在自然语言中难以表达,这使得LLMs难以理解。相反,使用符号在单词序列中表达这些关系可能是LLMs更好的表示形式。CoS在空间问答任务上实现了高达60.8%的准确率提升。
2.10 结构化思维链(Structured Chain-of-Thought, SCoT)
SCoT背后的直觉是(Li et al., 2023b),使用程序结构如序列化、分支和循环来结构化中间推理步骤,比在传统CoT中使用自然语言的中间推理步骤更有助于更准确的代码生成。作者声称前者比后者更接近人类开发人员的思维过程,并且最终结果证实了这一点,SCoT在代码生成任务上比CoT高出最多13.79%。
2.11 计划与解决(Plan-and-Solve, PS)
Wang等人(2023)讨论并试图解决CoT的三个缺点:计算错误、遗漏步骤错误和语义理解错误。PS包含两个组成部分,其中第一个部分需要制定一个计划,将整个问题分解为更小的子问题;第二个部分需要根据计划执行这些子问题。一个更好的PS版本称为PS+,它增加了更详细的指令,有助于提高推理步骤的质量。PS提示方法在零样本设置下几乎所有数学问题解决任务的数据集上比CoT至少提高了5%的准确率。同样,在常识推理任务中,它在零样本设置下至少比CoT提高了5%,而在多跳推理任务中,它的准确率大约提高了2%。
2.12 数学提示器(MathPrompter)
Imani等人(2023)试图解决CoT在数学问题解决任务中的两个关键问题:(1)CoT解决问题所遵循步骤的有效性缺乏;(2)LLM对其预测的置信度如何。MathPrompter提示策略总共包括4个步骤。(I)给定一个查询,第一步需要为查询生成一个代数表达式,将数值替换为变量。(II)接下来,LLM被提示通过推导出代数表达式或编写Python函数来解析解决查询。(III)第三步,通过给变量分配不同的值来解决第一步中的查询。(IV)如果第三步在N次迭代中的解决方案是正确的,那么变量最终被替换为原始查询值并计算答案。如果不是,那么重复步骤(II)、(III)和(IV)。MathPrompter能够在数学问题解决任务的数据集上将性能从78.7%提高到92.5%。
2.13 对比思维链/对比自洽性(Contrastive Chain-of-Thought/Contrastive Self-Consistency)
Chia等人(2023)的作者声称,对比思维链或对比自洽性是对传统思维链或自洽性的一般性增强。这种提示方法的灵感来自于人类如何从正面和负面例子中学习。同样地,在这种提示技术中,提供正面和负面的示例以增强LLMs的推理能力。对比思维链在多个数据集上平均能够为数学问题解决任务带来10%的改进。类似地,对比自洽性在多个数据集上能够比传统自洽性在数学问题解决任务上高出超过15%。对于多跳推理任务,对比思维链和对比自洽性都比它们的传统对应物提高了超过10%。
2.14 联邦化相同/不同参数自洽性/思维链(Federated Same/Different Parameter Self-Consistency/Chain-of-Thought, FED-SP/DP-SC/COT)
Liu等人(2023)介绍的这种提示方法基于使用同义词众包查询来提高LLMs推理能力的核心思想。这种提示方法有两种略有不同的变体。第一种是Fed-SP-SC,其中众包查询是原始查询的释义版本,但具有相同的参数。在这里,参数可以指数学问题解决任务数据点中的数值。对于Fed-SP-SC,首先直接生成答案,然后在此之上应用自洽性。另一个是Fed-DP-CoT。在Fed-DP-CoT中,LLMs首先用于生成对不同查询的答案,然后通过形成思维链来为LLMs提供提示。这些方法在数学问题解决任务上的结果表明,它们能够比传统CoT至少提高10%,最高可达20%。
2.15 类比推理(Analogical Reasoning)
Yasunaga等人(2023)的工作从心理学概念类比推理中汲取灵感,人们使用相关的以往经验来解决新问题。在LLMs的领域中,作者首先提示它们生成与原始问题相似的例子,然后解决它们,再继续回答原始问题。结果表明,类比推理在与CoT相比时,在数学问题解决、代码生成、逻辑推理和常识推理任务上平均能够实现4%的准确率提升。
2.16 合成提示(Synthetic Prompting)
Shao等人(2023)提出了使用LLMs生成合成示例的合成提示,这些示例被增强并添加到传统少样本设置中看到的现有手工制作示例中。这种提示方法包括两个步骤:(1)后向步骤,其中LLM基于自生成的思维链合成查询;(2)前向步骤,其中LLM为合成的查询生成思维链,使思维链更准确。最后,为了选择最佳示例,这项工作使用簇内复杂度和最长推理链的最复杂示例在推理中使用。结果表明,合成提示在与不同数学问题解决、常识推理和逻辑推理任务数据集的实验中实现了高达15.6%的绝对增益。
2.17 思维树(Tree-of-Thoughts, ToT)
Yao等人(2024)的思维树提示技术源自于这样一种观点,即任何问题解决都需要通过搜索表示为树的组合空间,其中每个节点代表一个部分解决方案,每个分支对应于修改它的运算符。现在,选择哪个分支的决定是由帮助导航问题空间并引导问题解决者朝着解决方案前进的启发式方法确定的。基于这个想法,作者提出了ToT,它积极维护一个思维树,其中每个思维是作为问题解决的中间推理步骤的连贯语言序列。这个框架允许LLMs在尝试解决问题时评估由思维生成的进展。ToT进一步结合了搜索技术,如广度优先或深度优先搜索,与模型生成和评估思维的能力。ToT在数学问题解决任务上的成功率比CoT提高了65%,在不同的逻辑推理任务数据集上提高了约40%。ToT在自由响应任务上的一致性得分为7.56,而CoT平均只有6.93。
2.18 逻辑思考(Logical Thoughts, LOT)
在这项工作中(Zhao et al., 2023b),作者们研究了使用逻辑等价以提高LLMs零样本推理能力的方法。除了允许LLMs逐步推理外,LOT还允许LLMs根据归谬法原则逐步验证,并在需要时修正推理链以确保有效的推理。LOT能够在数学问题解决任务上超过CoT最多3.7%,常识推理任务上最多16.2%,逻辑推理任务上最多2.5%,因果推理任务上最多15.8%,社会推理任务上最多10%的准确率。
2.19 助产士提示(Maieutic Prompting)
通过使用深度递归推理来引出各种假设的演绎性解释,Jung等人(2022)的助产士提示鼓励LLM产生一致的响应,通过协作消除相互矛盾的替代方案。助产士提示的生成过程衍生出一个生成命题的树状结构,其中一个命题为另一个命题的正确性建立逻辑基础。最后,为了推断原始查询的答案,测量LLM相信每个命题的程度以及助产士树中命题之间的逻辑联系。助产士提示在常识推理任务上的结果表明,与基础提示、CoT、自洽性和GKP Liu等人(2021)相比,它能够实现高达20%的更好准确率,同时与监督模型表现竞争。
2.20 验证与编辑(Verify-and-Edit, VE)
Zhao等人(2023a)专注于开发一种技术,可以对CoT生成的推理链进行后续编辑,以获得更符合事实的输出。该方法包括三个阶段:(1)决定何时编辑阶段,作者使用自洽性找到不确定的输出;(2)如何编辑理由阶段,作者通过从外部知识源搜索支持事实来编辑不确定输出的CoT推理链;(3)推理阶段,使用上一阶段编辑的理由来得出最终答案。VE在多跳推理任务上能够比CoT、自洽性和基础提示高出最多10%,在真实性任务上高出最多2%。
2.21 推理+行动(Reason + Act, REACT)
Yao等人(2022b)提出了REACT,它结合了推理和行动,使LLM能够解决多样的语言推理和决策任务。为了使模型能够进行动态推理,构建和修改高层次的行动计划(推理以行动),REACT提示LLM以交错的方式生成与任务相关的口头推理轨迹和行动。Yao等人(2022b)讨论了一种类似于REACT的提示方法,称为Act,它基本上去除了REACT轨迹中的思想或推理,但在所有讨论的任务中表现次优。对于多跳推理和真实性任务,REACT能够比基础提示表现得更好,并且与CoT竞争。当REACT与CoT或自洽性结合时,它能够获得比CoT更好的结果。对于基于语言的任务完成任务,REACT在不同数据集上的成功率分别提高了超过10%。
2.22 活跃提示(Active-Prompt)
Diao等人(2023)提出了活跃提示,以帮助LLM通过识别最相关的数据点作为示例,在少样本设置中适应不同任务。活跃提示是一种四步技术。第一步,LLM被提示对训练集中的每个查询进行k次提示,生成k个可能的答案及其相应的推理链。下一步需要基于第一步生成的答案计算不确定性度量。第三步,选择前n个最不确定的查询并由人工进行注释。最后一步,使用新注释的示例对测试数据进行少样本提示。作者还介绍了活跃提示的不同版本,称为随机CoT,其中在第三步中,选择前n个查询是基于随机选择而不是基于不确定性度量。结果表明,活跃提示在多个数据集上的数学问题解决、常识推理、多跳推理、常识推理任务中比自洽性、CoT、自动CoT和随机CoT获得更好的结果。
2.23 思维线索(Thread-of-Thought, THOT)
Zhou等人(2023)提出了一种专注于处理长篇混乱上下文的提示方法。它基于这样一个想法:人们在处理大量信息时保持一种不间断的思维流,这使得他们能够选择性地提取相关数据并排除不相关的信息。在文档的不同部分之间平衡注意力对于准确解释和响应提供的信息至关重要。THOT包括两个步骤。第一步要求LLM分析和总结上下文的不同部分。第二步,LLM被提示根据第一步的输出回答所提出的问题。THOT能够通过在上下文无关问答任务中实现约0.56的精确匹配得分,超越了CoT和基础促进技术。对于对话系统任务,THOT能够获得最高的平均得分3.8,再次超越了其他讨论的提示技术。
2.24 隐式检索增强生成(Implicit Retrieval Augmented Generation, Implicit RAG)
与传统的RAG Lewis等人(2020)相反,隐式RAG Vatsal和Singh(2024);Vatsal等人(2024)要求LLM自己从给定的上下文中检索重要的部分或部分,然后继续回答所提出的问题。这种技术需要调整两个超参数。第一个是提取的部分数量,第二个是每个部分中的单词数量。隐式RAG在Vatsal等人(2024)的患者病例报告数据集上实现了SoTA结果,而在Vatsal和Singh(2024)的生物医学上下文问答任务数据集中实现了SoTA或接近SoTA的结果。
2.25 系统2注意力(System 2 Attention, S2A)
LLMs在面对无关上下文时经常会做出错误的判断。Weston和Sukhbaatar(2023)尝试用两步提示策略解决这个问题。第一步指示LLM重新生成给定的上下文,以便重新生成的版本不包含可能对输出产生不利影响的任何无关部分。第二步则指示LLM使用第一步中重新生成的上下文产生最终响应。结果表明,S2A能够在不同的真实性任务数据集上超越基础、CoT和指导提示 Shi等人(2023)。
2.26 指导提示(Instructed Prompting)
指导提示 Shi等人(2023)再次围绕与S2A相同的理念,即解决LLMs被无关上下文分散注意力的问题。它只包括一个步骤,明确指示语言模型在问题描述中忽略无关信息。指导提示在真实性任务上能够实现88.2的标准化微准确率,并且能够超越所有它的对应物,包括CoT、最少到最多、程序提示和自洽性。程序提示 Chowdhery等人(2023)的策略在这里尝试通过编写Python程序来解决问题。稍后,通过使用外部Python解释器运行Python代码来验证编写的程序的正确性,以获得最终答案。
2.27 验证链(Chain-of-Verification, COVE)
LLMs容易产生事实上不正确的信息,称为幻觉。Dhuliawala等人(2023)的作者尝试通过CoVe解决幻觉问题并提高性能。CoVe执行四个核心步骤。首先,LLM为给定查询生成基线响应。其次,使用原始查询和第一步的基线响应,生成能够检查基线响应中是否有错误的验证查询列表。第三步,为第三步生成的所有验证查询生成答案。第四步,纠正第三步检测到的基线响应中的所有错误,并产生修订后的响应。结果表明,CoVe能够在上下文无关问答、上下文问答和自由响应任务上至少比CoT和基础提示高出10%。
2.28 知识链(Chain-of-Knowledge, COK)
与CoVe类似,Li等人(2023c)尝试通过COK解决幻觉问题以获得更准确的结果。它是一种三阶段的提示技术。第一阶段是推理准备,在此阶段,给定一个查询,COK准备几个初步的理由和答案,同时识别相关的知识领域。第二阶段是动态知识适应,如果答案中没有大多数共识,COK会逐步更正理由,通过适应第一阶段识别的领域的知识。第三阶段是答案整合,使用第二阶段更正的理由作为最终答案整合的更好基础。CoVe在上下文无关问答、基于表格的问答、多跳推理和真实性任务上超越了CoT、自洽性、VE和基础提示,并且分别至少提高了3%、3%、1%和1%。
2.29 代码链(Chain-of-Code, COC)
在这项工作中(Li et al., 2023a),作者提出了一个扩展,使LLM的代码导向推理更好。在这里,LLM不仅编写程序代码,还选择性地模拟解释器,产生某些代码行的预期输出,这些代码行不能由解释器实际执行。主要思想是激励LLM将程序中的语义子任务格式化为灵活的伪代码,这些伪代码可能在运行时被明确捕获并传递给LLM进行仿真,作者称其为LMulator。实验表明COC在包括推荐系统、因果推理、常识推理、空间问答、情感/情绪理解、机器翻译、逻辑推理、基于表格的数学问题解决和数学问题解决等多种任务中都超越了CoT和其他基线。
2.30 程序辅助语言模型(Program-Aided Language Models, PAL)
Gao等人(2023)提出了一种提示策略,使用LLM阅读自然语言问题并生成交错的自然语言和编程语言语句作为推理步骤。最后,使用Python解释器执行编程语句以获得答案。结果表明,PAL在包括数学问题解决、基于表格的数学问题解决、常识推理和逻辑推理在内的多个NLP任务上,比CoT和基础提示表现得更好。
2.31 绑定器(Binder)
作者声称Binder Cheng等人(2022)是一种无需训练的神经符号技术,将输入映射到程序,该程序(I)使LLM功能的单个API绑定到编程语言(如Python或SQL)以增加其语法覆盖范围并解决更广泛的问题;(II)在执行期间使用LLM作为底层模型以及程序解析器;(III)只需要少量的上下文样本注释。Binder管道有两个阶段。首先,在解析阶段,LLM根据查询和知识源将输入映射到程序。其次,在执行阶段,LLM返回所选编程语言中的值,最后使用解释器运行程序。与需要显式训练或微调的先前方法相比,Binder在基于表格的真实性和基于表格的问答任务上能够获得更好的准确性。
2.32 日期器(Dater)
Ye等人(2023)探索了LLMs的少样本学习理念,以分解证据和查询,进行高效的基于表格的推理。这种提示策略涉及三个重要步骤。它从将大型表格分解为与查询相关的较小子表格开始。接下来,使用SQL编程语言将复杂的自然语言查询分解为逻辑和数值计算。最后,使用前两个步骤中的子表格和子查询来以少样本设置得出最终答案。结果表明,Dater在基于表格的真实性任务上能够比需要显式微调的先前方法至少提高2%。同样,对于基于表格的问答任务,它能够比这些方法至少提高1%。Dater在上述两项任务上也比Binder表现得更好。
2.33 表格链(Chain-of-Table)
在Wang等人(2024)中,作者在著名的CoT提示技术上进行了构建,并将其引入到表格设置中。这种多步骤的表格提示方法导致更准确的表格理解。表格链是一种三步提示技术。第一步指示LLM通过上下文学习动态规划下一个表格操作。这里的操作可能包括从添加列到排序行的任何操作。第二步为选定的表格操作生成参数。前两个步骤有助于转换表格并创建各种中间表格表示,目标是回答原始查询。在最后一步中,使用前两个步骤中的最后一个表格表示来最终回答问题。表格链在基于表格的问答和基于表格的真实性任务上实现了SoTA性能。对于基于表格的问答任务,它比之前SoTA结果平均提高了约3%的性能;对于基于表格的真实性任务,它能够平均提高约1.5%的性能。
2.34 分解提示(Decomposed Prompting, Decomp)
Khot等人(2022)提出了Decomp技术,将复杂问题分解为更简单的子问题,然后将这些子问题委托给具有自己提示和分解器的特定子问题的LLMs,这些分解器可以进一步分解子问题。分解器可以采用层次分解、递归分解或进行外部API调用来解决子问题。Decomp在常识推理任务上平均比CoT和最少到最多高出25%的精确匹配率。对于多跳推理任务,Decomp在四个不同的数据集上轻松地超越了CoT。
2.35 三跳推理(Three-Hop Reasoning, THOR)
Fei等人(2023)的作者提出了THOR,以模仿人类类似的推理过程,用于情感/情绪理解任务。THOR包括三个步骤。第一步,LLM被要求识别给定查询中提到的方面。接下来,基于前一步的输出和原始查询,LLM被要求详细回答查询中嵌入的潜在观点。最后,将上述所有信息结合起来,LLM被要求推断与给定查询相关的情感极性。THOR能够在多个情感/情绪理解任务数据集上显著超越先前的SoTA监督和零样本模型。
2.36 元认知提示(Metacognitive Prompting, MP)
MP Wang和Zhao(2023)基于元认知概念,这是从认知心理学中衍生出来的,与个体对自己认知过程的意识和自我反思有关。它包括五个阶段。1)理解输入文本,2)做出初步判断,3)批判性地评估这个初步分析,4)伴随着推理解释做出最终决定,5)评估整个过程的信心水平。结果显示,MP在多个NLP任务中始终优于CoT和PS,包括释义、自然语言推理、上下文问答、词义消歧、命名实体识别、关系提取和多标签文本分类。
2.37 事件链(Chain-of-Event, COE)
Bao等人(2024)为摘要任务提出了COE。COE有四个连续步骤。第一个步骤专注于特定事件提取。接下来,第一步中提取的事件被分析并概括成更简洁、更精炼的形式。第三步,概括的事件被过滤,只选择覆盖大部分文本的事件。在最后一步中,第三步中选择的事件根据它们的重要性的顺序进行整合。结果显示,COE在两个摘要数据集上的表现优于CoT,同时在rouge分数上也更简洁。
2.38 基础与术语定义
这是Vatsal等人(2024)讨论的一种提示方法。在这种方法中,基础提示指令通过添加基于假设的医学术语定义得到增强,即添加这些定义将帮助LLM在回答问题时获得更多上下文。但结果显示,这些术语定义并没有真正帮助,可能是因为它们的知识范围狭窄,可能与LLM的更大知识库发生冲突。此外,医学术语的定义可能会随着上下文的变化而变化,因此为医学术语固定定义并不能真正帮助LLM,反而可能会让它们感到困惑。
2.39 基础 + 注释指南基础提示 + 错误分析基础提示
Hu等人(2024)测试了LLM在临床命名实体识别任务中的能力。这种提示策略有三个不同的组成部分。基础部分告诉LLM关于任务的基本信息以及LLM应以何种格式输出结果。注释指南部分包含从注释指南中得出的实体定义和语言规则。错误分析部分在训练数据中使用LLM输出进行错误分析后,增加了额外的指令。作者还通过创建上述组成部分的不同组合,尝试了这种提示方法的不同版本。这种提示方法在多个命名实体识别任务的数据集上平均获得了0.57的精确匹配F1分数。
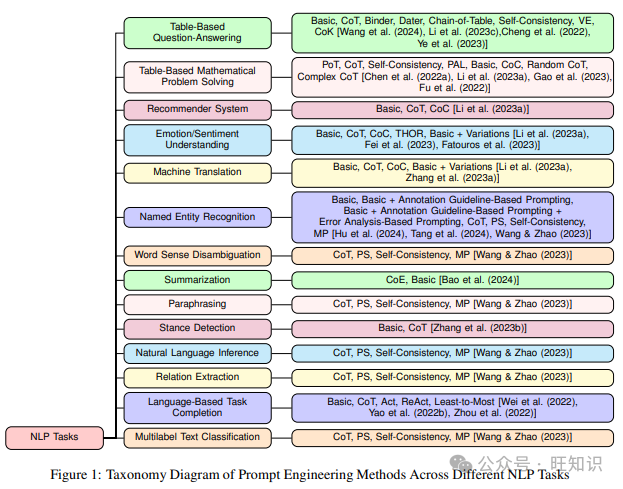
3 不同NLP任务上的提示工程
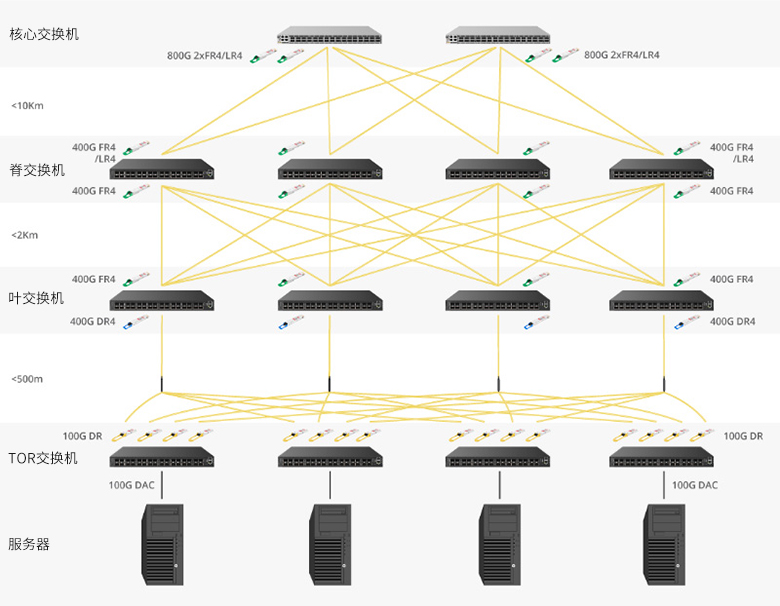
不同的研究论文在对数据集进行NLP任务分类时使用了不同的度量标准,这在不同的工作中不断变化。在本节中,我们尝试通过定义不同的NLP任务并将不同的数据集归入这些任务中,从而对这些先前分类方式进行标准化。我们进一步讨论了这些任务上应用的各种提示方法。图1显示了反映这一点的分类图。这里需要注意的一个重点是,一个数据集可能同时属于不同的NLP任务。但这可能导致对不同NLP任务上提示技术表现的结构化分析的复杂纠缠。因此,在我们的工作中,我们确保一个数据集只属于它最强关联的NLP任务。以下小节每个都定义了不同的NLP任务、相应的数据集和应用于这些数据集的各种提示策略。它们进一步包含了每个数据集的潜在SoTA提示技术。提示方法的表现因使用的LLM而异。因此,我们还包括了与给定数据集上的提示策略一起使用的LLM列表。对于SoTA,我们只提到了提示方法的名称,因为在许多情况下,特定的LLM尚未与给定的提示方法一起进行实验,因此不清楚它是否能够实现SoTA表现。因此,如果任何LLM从LLM列表中与提示策略一起使用,并在给定数据集上实现了最佳表现,我们将其指定为SoTA,而不管用于该技术的确切LLM是什么。同样,我们在列出SoTA时没有提到评估指标,因为它们可能因不同的研究论文而异。
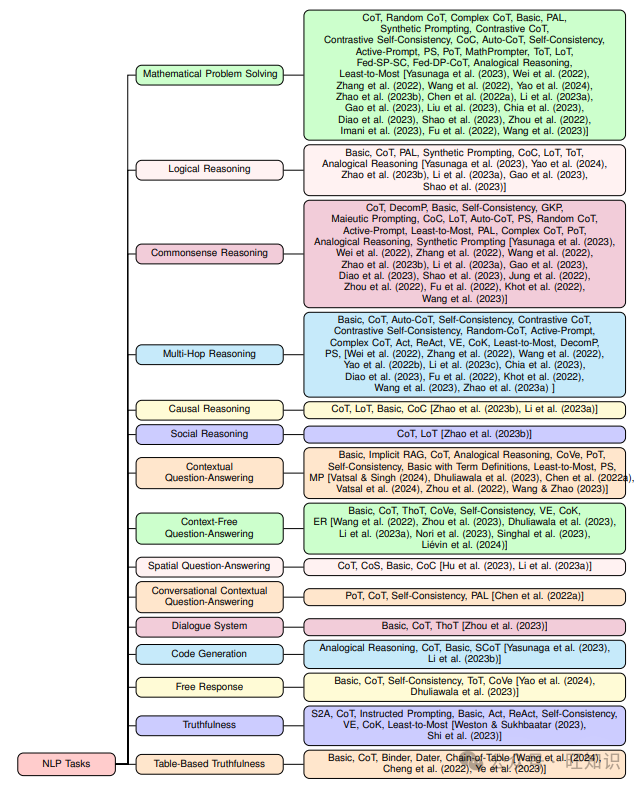
3.1 数学问题解决
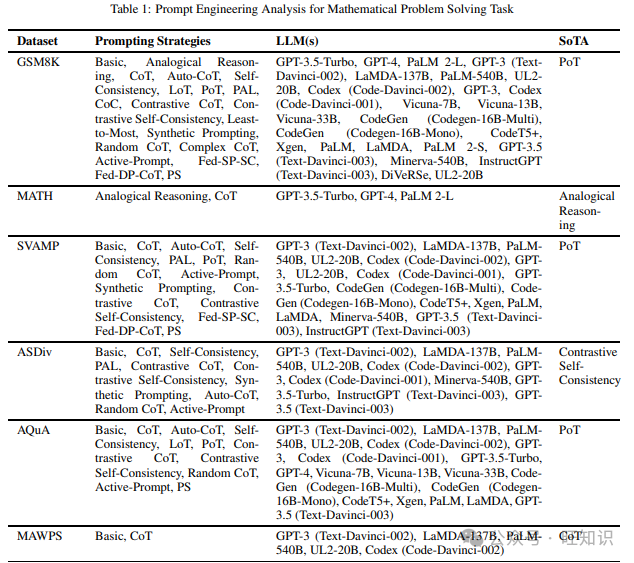
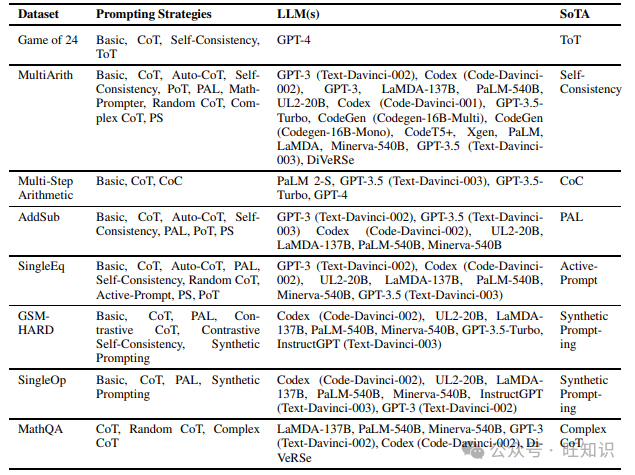
这项任务衡量模型在非表格设置中执行任何数学计算的能力。我们在阅读不同提示方法时遇到的不同数据集包括GSM8K、MATH、SVAMP、ASDiv、AQuA、MAWPS、MultiArith、AddSub、SingleEq、Game of 24、Multi-Step Arithmetic、GSM-HARD、SingleOp和MathQA。表1列出了上述数据集以及在它们上尝试的不同提示策略,以及表现最佳的提示策略。
3.2 逻辑推理
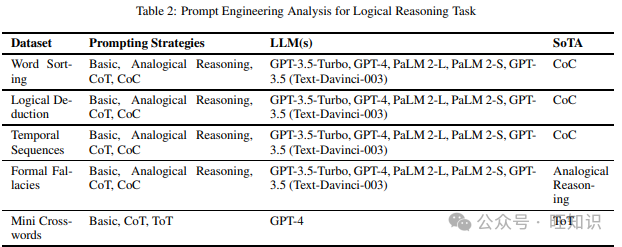
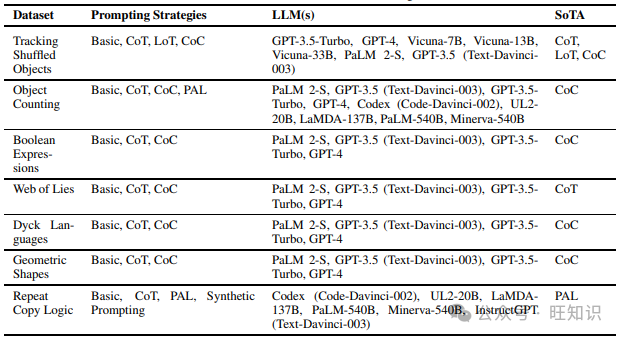
逻辑推理任务检查模型的自然语言理解能力,以遵循一组命令和输入并解决给定问题。我们在阅读不同提示策略时涵盖的不同数据集包括Word Sorting、Temporal Sequences、Formal Fallacies、Mini Crosswords、Object Counting、Logical Deduction、Boolean Expressions、Tracking Shuffled Objects、Web of Lies、Dyck Languages、Geometric Shapes和Repeat Copy Logic。表2包含了上述数据集和在它们上尝试的不同提示技术,以及表现最佳的提示方法。
3.3 常识推理
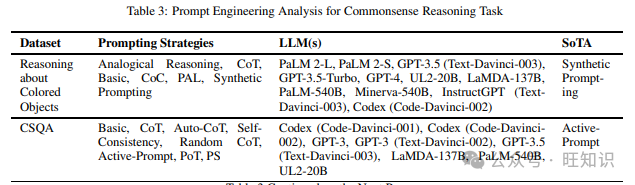
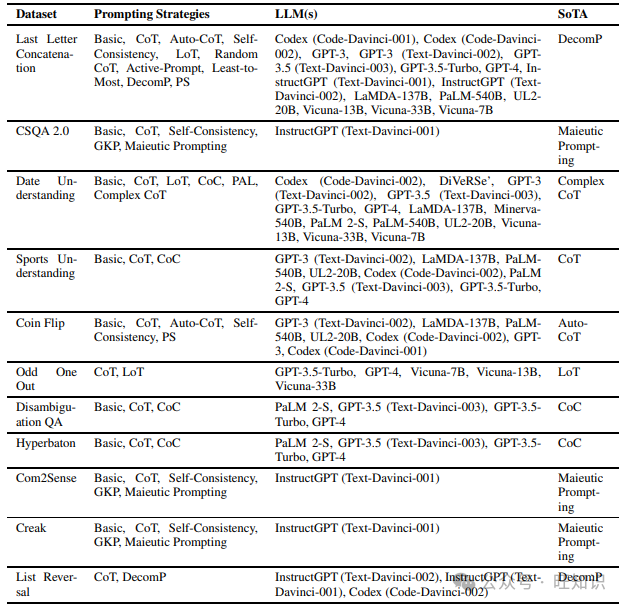
与逻辑推理任务相反,常识推理任务衡量模型在人类常称为常识的实用知识方面的能力,以做出任何判断。它不涉及解决问题以得出答案。相反,它更多地是一种固有的一般知识形式。我们在调查不同提示方法时发现的各种数据集包括Reasoning about Colored Objects、CSQA、Date Understanding、Sports Understanding、Last Letter Concatenation、Coin Flip、Odd One Out、Disambiguation QA、Hyperbaton、Com2Sense、CSQA 2.0、Creak Onoe等人(2021)和List Reversal。表3显示了上述数据集和在它们上尝试的不同提示策略,以及表现最佳的提示方法。
3.4 多跳推理
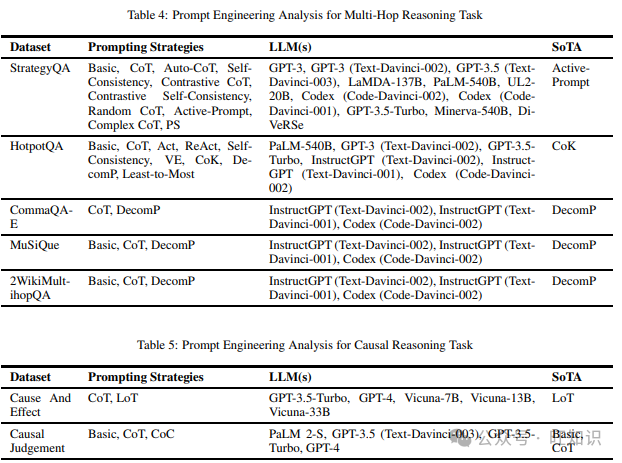
多跳推理任务评估模型将来自不同上下文部分的证据片段连接起来回答给定查询的能力。我们在阅读不同提示策略时涵盖的不同数据集包括StrategyQA、HotpotQA、BambooGle、CommaQA-E、MuSiQue、2WikiMultihopQA。表4列出了上述数据集和在它们上尝试的不同提示方法,以及表现最佳的提示策略。
3.5 因果推理
因果推理任务检查模型处理因果关系的能力。我们在阅读不同提示技术时遇到的两个数据集是Cause And Effect和Causal Judgement。表5显示了上述数据集和在它们上尝试的不同提示技术,以及表现最佳的提示方法。
3.6 社会推理
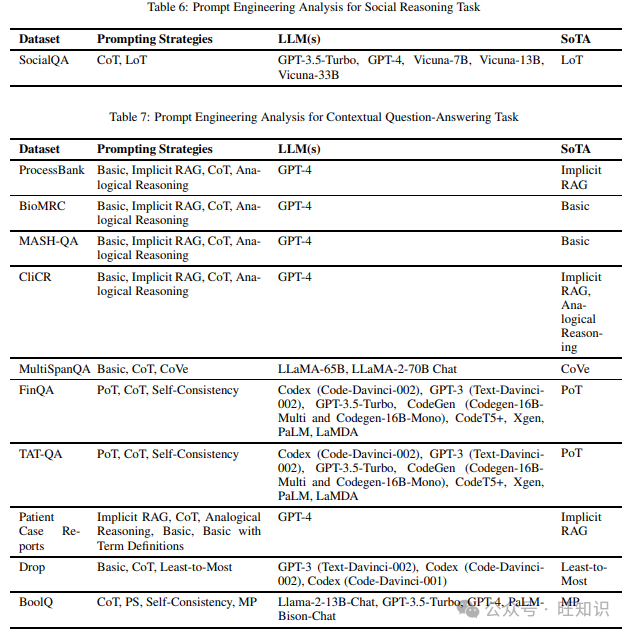
这项任务测试模型推理人类社会互动的能力。我们在调查不同提示技术时只发现了一个数据集,即SocialQA。表6包含了上述数据集和在它们上尝试的不同提示方法,以及表现最佳的提示策略。
3.7 上下文问答
这项任务衡量模型仅依靠给定上下文回答问题的能力。我们在阅读不同提示方法时涵盖的不同数据集包括ProcessBank、BioMRC、MASH-QA、CliCR、MultiSpanQA、FinQA、TAT-QA、Patient Case Reports、Drop和BoolQ。表7列出了上述数据集和在它们上尝试的不同提示方法,以及表现最佳的提示技术。
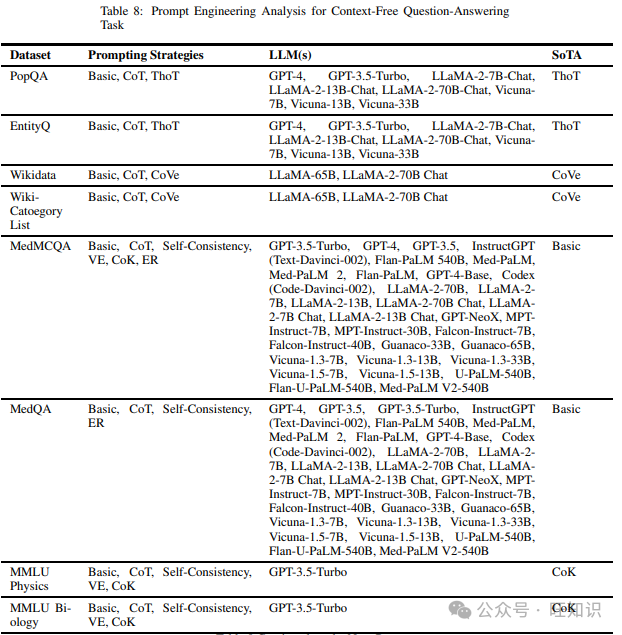
3.8 上下文无关问答
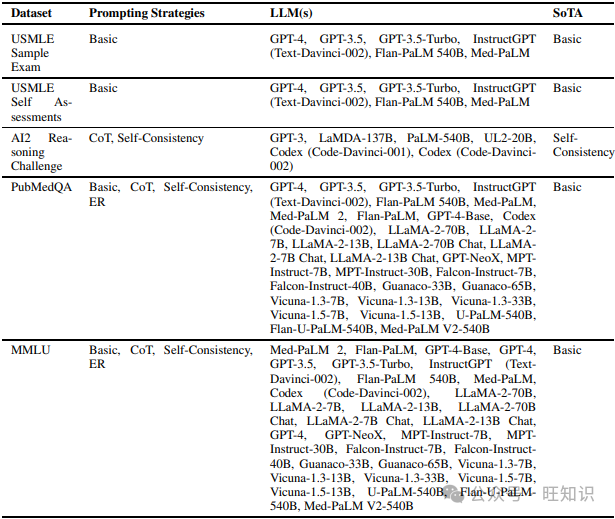
与上下文问答任务相反,上下文无关问答任务依靠模型的内嵌知识库或任何开源知识库(如维基百科)来回答查询,而不是仅使用提供的上下文。我们在调查不同提示技术时发现的各种数据集包括PopQA、EntityQ、Wikidata、Wiki-Category List、MedMCQA、MMLU Physics、MMLU Biology、USMLE Sample Exam、USMLE Self Assessments、MedQA、PubMedQA、MMLU和AI2 Reasoning Challenge。表8列出了上述数据集和在它们上尝试的不同提示策略,以及表现最佳的提示策略。
3.9 空间问答
空间问答任务衡量模型处理空间推理的能力,这是一种基于构建空间对象、关系和转换的心理表征的认知过程。我们在阅读不同提示技术时遇到的各种数据集包括Brick World、NLVR-Based Manipulation、Natural Language Navigation、Spartun和Navigate。表9包含了上述数据集和在它们上尝试的不同提示方法,以及表现最佳的提示策略。
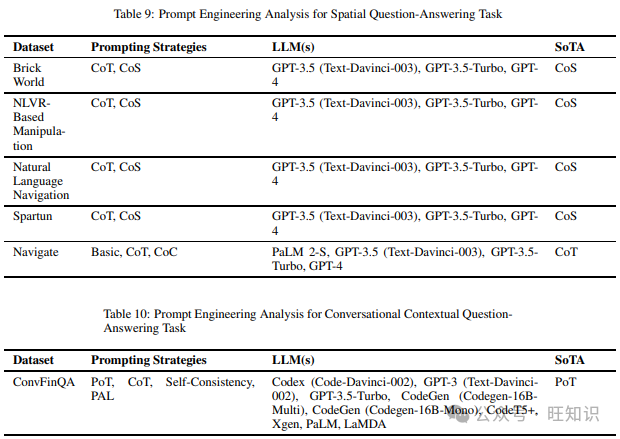
3.10 对话上下文问答
在这项任务中,模型的评估基于其对给定文本摘录的理解以及它如何能够回答以对话格式出现的一系列相互关联的查询。这里需要注意的一个关键是,每个查询可能依赖于之前查询的答案。我们在阅读不同提示方法时只涵盖了一个数据集,即ConvFinQA。表10显示了上述数据集和在它们上尝试的不同提示方法,以及表现最佳的提示策略。

3.11 对话系统
对话系统任务检查模型在用户到机器的对话设置中执行语言生成的能力,或者在已经生成的对话中回答查询。可能的情况是,当对话上下文问答中的文本摘录变成对话时,这两个任务之间会有强烈的重叠,但根据我们在调查中遇到的数据集和提示技术,我们决定将这两个任务保持为单独的任务。我们在调查不同提示方法时只发现了一个数据集,即Multi-Turn Conversation Response (MTCR)。表11列出了上述数据集和在它们上尝试的不同提示策略,以及表现最佳的提示技术。
3.12 代码生成
这项任务涉及所有输入或最终输出到模型是编程语言代码的案例。我们在阅读不同提示策略时遇到的不同数据集包括Codeforce Scraping、HumanEval、MBPP和MBCPP。表12包含了上述数据集和在它们上尝试的不同提示技术,以及表现最佳的提示策略。
3.13 自由响应
这项任务评估模型在生成不受限制的文本响应方面的能力。我们在阅读不同提示方法时涵盖的各种数据集包括Creative Writing和Longform Generation of Biographies。表13列出了上述数据集和在它们上尝试的不同提示策略,以及表现最佳的技术。
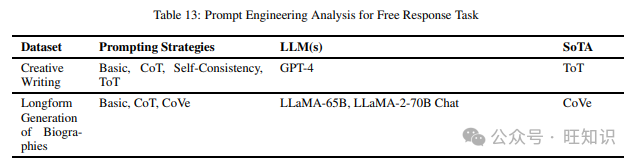
3.14 真实性
这项任务评估模型传达事实的能力,不传播任何形式的错误信息。这项任务并不代表模型理解给定上下文的能力,而是更侧重于它们不基于理解做出虚假陈述。我们在调查不同提示策略时发现的各种数据集包括SycophancyEval、GSM-IC和Fever。表14显示了上述数据集和在它们上尝试的不同提示技术,以及表现最佳的提示技术。
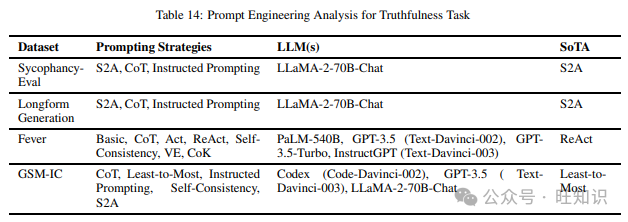
3.15 基于表格的真实性
这项任务是真实性任务的扩展,衡量模型在表格设置中传达事实的能力,不传播任何形式的错误信息。我们在阅读不同提示方法时遇到的唯一数据集是TabFact。表15包含了上述数据集和在它们上尝试的不同提示策略,以及表现最佳的提示策略。

3.16 基于表格的问答
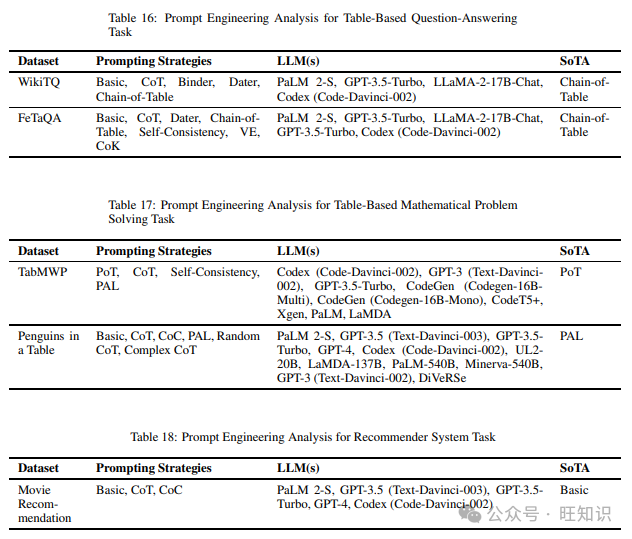
这项任务涉及在表格设置中的任何形式的问答。它可以被视为其他类型基于表格任务(如基于表格的真实性或基于表格的数学问题解决)的超集。但为了在这项工作中避免任何混淆,我们捕获了所有不属于更具体的基于表格任务(如基于表格的真实性或基于表格的数学问题解决)的数据集。我们在阅读不同提示策略时遇到的两个数据集是FeTaQA和WikiTQP。表16显示了上述数据集和在它们上尝试的不同提示方法,以及表现最佳的提示策略。
3.17 基于表格的数学问题解决
这项任务是数学问题解决任务的扩展,衡量模型在表格设置中执行任何数学计算的能力。我们在阅读不同提示技术时涵盖的不同数据集包括TabMWP和Penguins in a Table。表17列出了上述数据集和在它们上尝试的不同提示方法,以及表现最佳的提示策略。
3.18 推荐系统
这项任务衡量模型处理给定输入并从可能的项目列表中建议最相关项目集的能力。我们在调查不同提示技术时只发现了一个数据集,即Movie Recommendation。表18列出了上述数据集和在它们上尝试的不同提示方法,以及表现最佳的提示技术。
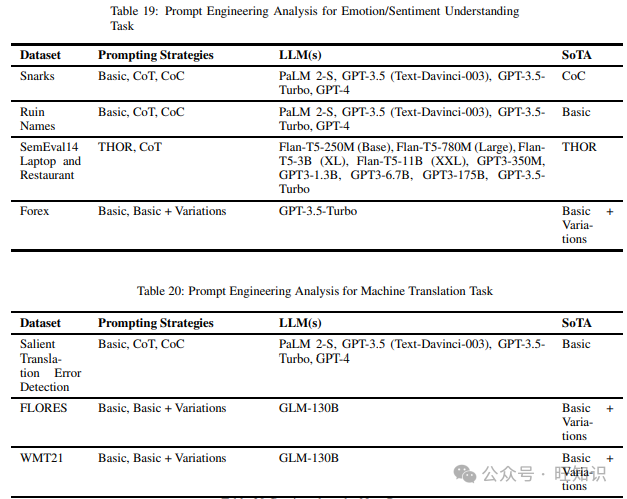
3.19 情感/情绪理解
这项任务检查模型理解人类情感或情绪的能力。我们在阅读不同提示方法时遇到的各种数据集包括Ruin Names、SemEval14 Laptop and Restaurant和Forex。表19包含了上述数据集和在它们上尝试的不同提示技术,以及表现最佳的提示策略。
3.20 机器翻译
在这项任务中,模型在两种语言之间的翻译能力受到测试。我们在阅读不同提示技术时遇到的各种数据集包括Salient Translation Error Detection、FLORES、WMT21、Multi-Domain和PDC。表20列出了上述数据集和在它们上尝试的不同提示方法,以及表现最佳的提示策略。
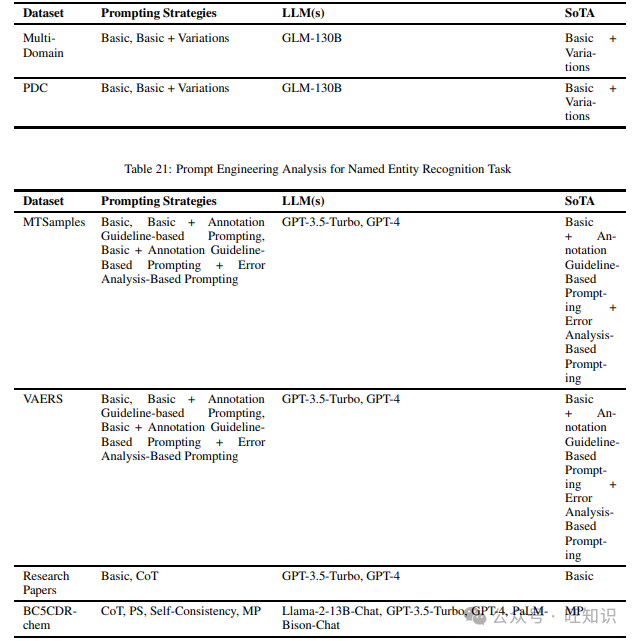
3.21 命名实体识别
命名实体识别任务旨在识别给定输入文本中预定义类别或类别的对象。我们在调查不同提示技术时发现的不同数据集包括MTSamples、VAERS、Research Papers和BC5CDR-chem。表21显示了上述数据集和在它们上尝试的不同提示策略,以及表现最佳的提示方法。
3.22 词义消歧
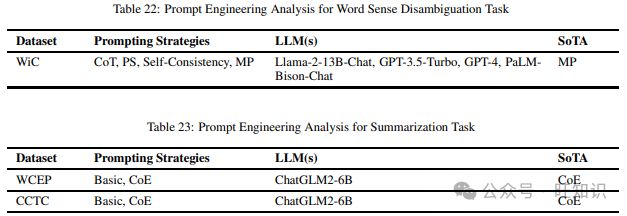
词义消歧任务检查模型在不同上下文环境中理解一个词不同含义的能力。我们在调查不同提示方法时只发现了一个数据集,即WiC。表22显示了上述数据集和在它们上尝试的不同提示技术,以及表现最佳的提示方法。
3.23 摘要
这项任务测试模型将长篇输入文本分解为更小的块,同时确保这些更小的块中保留关键信息的能力。我们在阅读不同提示方法时只发现了一个数据集,即CCTC。表23包含了上述数据集和在它们上尝试的不同提示技术,以及表现最佳的提示策略。
3.24 释义
释义任务旨在使用不同的词语重写给定的输入文本,同时保持原始输入文本的真实语义。释义任务与摘要任务的主要区别在于,摘要任务的主要目标是缩短输出文本与输入文本的长度比,而释义任务只关注在重写过程中使用不同的词语。我们在调查不同提示方法时只发现了一个数据集,即QQP。表24列出了上述数据集和在它们上尝试的不同提示方法,以及表现最佳的提示技术。

3.25 立场检测
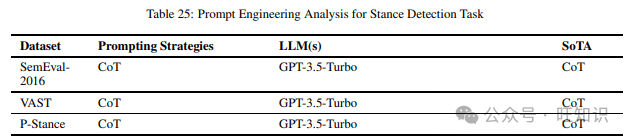
这项任务评估模型从文本中确定作者对某个主题或目标或评估对象是支持还是反对的能力。我们在阅读不同提示技术时遇到的不同数据集包括SemEval-2016、VAST和P-Stance。表25显示了上述数据集和在它们上尝试的不同提示方法,以及表现最佳的提示技术。
3.26 自然语言推理
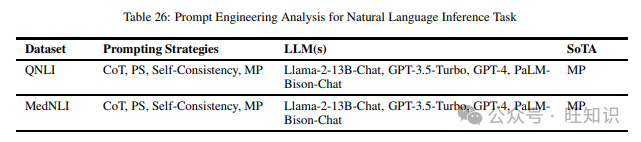
这项任务的主要目标是确定给定前提条件下的假设是真实的(蕴含)、虚假的(矛盾)还是不确定的(中立)。我们在阅读不同提示方法时涵盖的不同数据集包括QNLI和MedNLI。表26包含了上述数据集和在它们上尝试的不同提示策略,以及表现最佳的提示方法。
3.27 关系提取
关系提取评估模型识别预定义类别或类别的对象或命名实体之间的语义关系的能力。我们在调查不同提示技术时只发现了一个数据集,即DDI。表27显示了上述数据集和在它们上尝试的不同提示方法,以及表现最佳的提示策略。

3.28 基于语言的任务完成
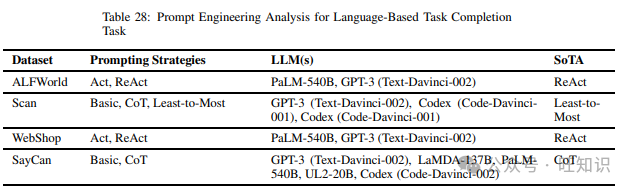
这项任务的主要目标是检查模型在遵循一系列基于语言的导航命令以决定其完成任务所需采取的行动方面的表现。我们在调查不同提示策略时发现的不同数据集包括ALFWorld、WebShop、SayCan和Scan。表28列出了上述数据集和在它们上尝试的不同提示方法,以及表现最佳的提示方法。
3.29 多标签文本分类
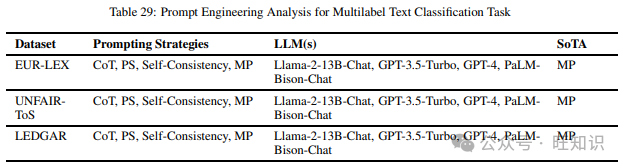
这项任务衡量模型将每个输入分配到一组预定义目标标签的能力。这项任务可以涵盖许多上述任务,如立场检测、命名实体识别等,但为了使任务定义尽可能不重叠,以便更好地调查提示方法,我们只包括了那些不能适当归类到上述讨论的任何任务中的数据集。我们在阅读不同提示策略时涵盖的不同数据集包括EUR-LEX、UNFAIR-ToS和LEDGAR。表29包含了上述数据集和在它们上尝试的不同提示策略,以及表现最佳的提示方法。
4 结论
提示工程在当前LLMs领域中变得不可或缺。它在实现LLMs的全部潜力方面发挥着关键作用。在这项工作中,我们深入调查了44篇研究论文,讨论了29个不同NLP任务上的39种提示策略。我们通过分类图形象地展示了这一点。我们尝试将不同的数据集标准化为29个NLP任务,并讨论了最新的提示技术在这些任务上的整体效果,同时列出了每个数据集的潜在SoTA提示方法。

如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践 - L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例 - L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词 - L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用 - L2.4 总结与展望
- L2.1 API接口
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节 - L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景 - L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例 - L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例 - L3.5 其他大模型介绍
- L3.1 Agent模型框架
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓