摘要
In this paper, we uncover the untapped potential of diffusion U-Net, which serves as a “free lunch” that substantially improves the generation quality on the fly.
We initially investigate the key contributions of the U-Net architecture to the denoising process and identify that its main backbone primarily contributes to denoising, whereas its skip connections mainly introduce high-frequency features into the decoder module, causing the network to overlook the backbone semantics.
Capitalizing on this discovery, we propose a simple yet effective method—termed “FreeU” — that enhances generation quality without additional training or finetuning.
Our key insight is to strategically re-weight the contributions sourced from the U-Net’s skip connections and backbone feature maps, to leverage the strengths of both components of the U-Net architecture.
Promising results on image and video generation tasks demonstrate that our FreeU can be readily integrated to existing diffusion models, e.g., Stable Diffusion, DreamBooth, ModelScope, Rerender and ReVersion, to improve the generation quality with only a few lines of code. All you need is to adjust two scaling factors during inference.
在本文中,我们揭示了扩散U-Net尚未开发的潜力,它可以作为“免费午餐”,在运行中大幅提高发电质量。
我们首先研究了U-Net架构对去噪过程的关键贡献,并确定其主要骨干主要有助于去噪,而其跳过连接主要将高频特征引入解码器模块,导致网络忽略骨干语义。
利用这一发现,我们提出了一种简单而有效的方法-称为“FreeU”-无需额外的培训或微调即可提高生成质量。
我们的关键见解是战略性地重新权衡来自U-Net的跳过连接和骨干特征映射的贡献,以利用U-Net架构的两个组件的优势。
在图像和视频生成任务上的良好结果表明,我们的FreeU可以很容易地集成到现有的扩散模型中,例如,Stable diffusion, DreamBooth, ModelScope, renderer和ReVersion,只需要几行代码就可以提高生成质量。您所需要的只是在推理过程中调整两个比例因子。
Fig.1
FreeU,一种无需任何成本就能大幅提高扩散模型样本质量的方法:无需训练,无需额外参数
Introduction
Beyond the application of diffusion models, in this paper, we are interested in investigating the effectiveness of diffusion U-Net for the denoising process.
To better understand the denoising pronizhe cess, we first present a paradigm shift toward the Fourier domain to perspective the generated process of diffusion models, a research area that has received limited prior investigation.
As illustrated in Fig. 2, the uppermost row provides the progressive denoising process, showcasing the generated images across successive iterations.
The subsequent two rows exhibit the associated low-frequency and high-frequency spatial domain information after the inverse Fourier Transform, aligning with each respective step.
除了扩散模型的应用之外,本文还对扩散U-Net在去噪过程中的有效性进行了研究。
为了更好地理解去噪过程,我们首先提出了一种范式转移到傅里叶域,以透视扩散模型的生成过程,这是一个研究领域,之前的研究有限。
如图2所示,最上面一行提供了渐进去噪过程,展示了在连续迭代中生成的图像。
随后的两行显示了傅里叶反变换后相关的低频和高频空间域信息,与每个步骤对齐。

Evident from Fig. 2 is the gradual modulation of lowfrequency components, exhibiting a subdued rate of change, while their high-frequency components display more pronounced dynamics throughout the denoising process. These findings are further corroborated in Fig.3. This can be intuitively explained: 1) Low-frequency components inherently embody the global structure and characteristics of an image, encompassing global layouts and smooth color. These components encapsulate the foundational global elements that constitute the image’s essence and representation. Its rapid alterations are generally unreasonable in denoising processes. Drastic changes to these components could fundamentally reshape the image’s essence, an outcome typically incompatible with the objectives of denoising processes. 2) Conversely, high-frequency components contain the rapid changes in the images, such as edges and textures. These finer details are markedly sensitive to noise, often manifesting as random high-frequency information when noise is introduced to an image. Consequently, denoising processes need to expunge noise while upholding indispensable intricate details.
从图2中可以明显看出,低频分量的逐渐调制表现出较低的变化率,而高频分量在整个去噪过程中表现出更明显的动态。
这些发现在图3中得到进一步证实。
这可以直观地解释为:
1) 低频分量固有地体现了图像的全局结构和特征,包括全局布局和平滑的颜色。
这些组件封装了构成图像本质和表现形式的基本全局元素。
它的快速变化通常在去噪过程中是不合理的。
这些成分的剧烈变化可能会从根本上重塑图像的本质,这一结果通常与去噪过程的目标不相容。
2) 相反,高频分量包含图像的快速变化,如边缘和纹理。这些更精细的细节对噪声非常敏感,当噪声被引入图像时,它们通常表现为随机的高频信息。
因此,去噪过程需要在去除噪声的同时保留必要的复杂细节。
Fig.3
Figure 3. Relative log amplitudes of Fourier with variations of the backbone scaling factor b. Increasing in b correspondingly results in a suppression of highfrequency components in the images generated by the diffusion model.
图3。傅里叶的相对对数振幅与主干比例因子b的变化。
增加b相应的结果抑制了扩散模型产生的图像中的高频成分。
没看懂

In light of these observations between low-frequency and high-frequency components during the denoising process, we extend our investigation to ascertain the specific contributions of the U-Net architecture within the diffusion framework.
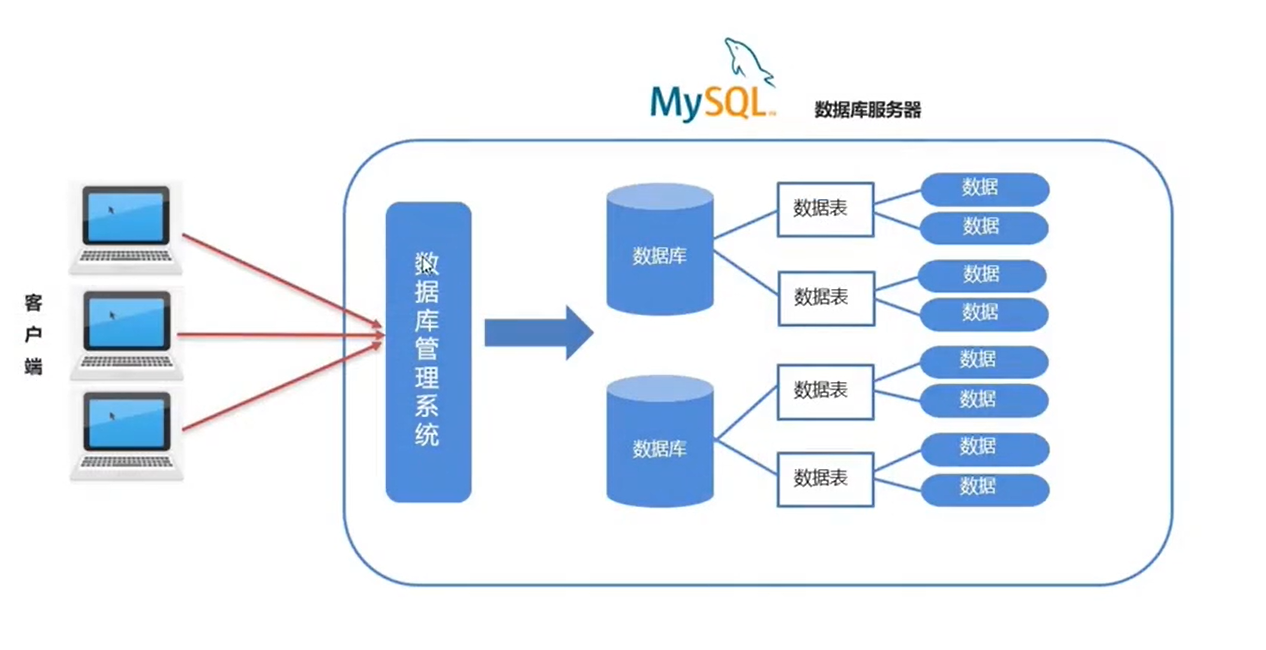
In each stage of the U-Net decoder, the skip features from the skip connection and the backbone features are concatenated together.
Our investigation reveals that the main backbone of the U-Net primarily contributes to denoising. Conversely, the skip connections are observed to introduce high-frequency features into the decoder module.
These connections propagate fine-grained semantic information to make it easier to recover the input data.
However, an unintended consequence of this propagation is the potential weakening of the backbone’s inherent denoising capabilities during the inference phase.
This can lead to the generation of abnormal image details, as illustrated in the first row of Fig. 1.
鉴于在去噪过程中低频和高频分量之间的这些观察结果,我们扩展了我们的研究,以确定U-Net架构在扩散框架中的具体贡献。
在U-Net解码器的每一阶段,从跳变连接得到的跳变特征和骨干特征被连接在一起。我们的研究表明,U-Net的主干网主要有助于去噪。
相反,可以观察到跳过连接将高频特征引入解码器模块。这些连接传播细粒度的语义信息,以便更容易地恢复输入数据。
然而,这种传播的一个意想不到的后果是在推理阶段骨干网固有的去噪能力的潜在削弱。这可能导致生成异常的图像细节,如图1第一行所示。
Figure 4. FreeU Framework. (a) U-Net Skip Features and Backbone Features. In U-Net, the skip features and backbone features are concatenated together at each decoding stage. We apply the FreeU operations during concatenation. (b) FreeU Operations. The factor b aims to amplify the backbone feature map x, while factor s is designed to attenuate the skip feature map h
图4。FreeU框架。
(a) U-Net跳变特征和骨干特征。在U-Net中,跳过特征和骨干特征在每个解码阶段都串联在一起。我们在连接期间应用FreeU操作。
(b)FreeU。因子b用于放大骨干特征图x,因子s用于衰减跳跃特征图h