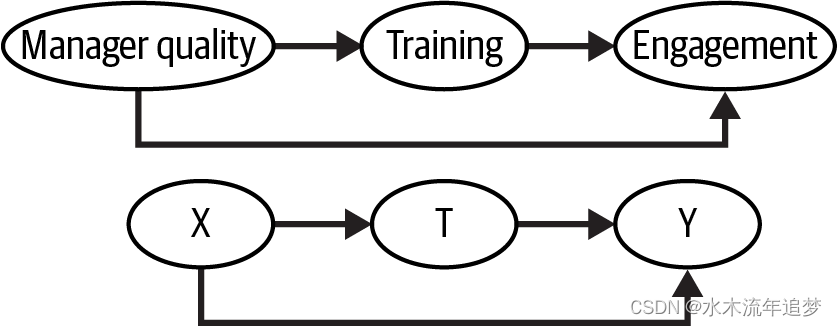
发表于: Knowledge and Information Systems, ccfb
推荐指数: #paper/ ⭐
总结: 重新定义了相似度矩阵, 重新定义了特征, 重新设计了节点删除概率等, 但是, 换汤不换药, 引入了大量的超参 (快 10 个了吧). 创新点不够, 所以 ccf B 期刊理所应该. (甚至我觉得更低)

相关知识:
本地组合性:
r
(
v
)
=
1
Q
max
∑
g
(
e
g
g
(
v
)
−
a
g
2
)
(1)
r(v)=\frac1{Q_{\max}}\sum_g(e_{gg}(v)-a_g^2)\tag{1}
r(v)=Qmax1g∑(egg(v)−ag2)(1)
∑
h
e
g
h
=
∑
i
∈
g
k
i
/
2
m
(2)
\sum_he_{gh}=\sum_{i\in g}k_i/2m\tag{2}
h∑egh=i∈g∑ki/2m(2)
本地特征组合性:
r
(
v
)
(
f
)
=
1
Q
max
∑
g
(
e
g
g
(
v
)
(
f
)
−
a
g
2
(
f
)
)
,
f
∈
R
F
(3)
r(v)(f)=\frac1{Q_{\max}}\sum_g\left(e_{gg}(v)(f)-a_g^2(f)\right),f\in\mathbb{R}^{F}\tag{3}
r(v)(f)=Qmax1g∑(egg(v)(f)−ag2(f)),f∈RF(3)
最终,我们定义如下同配性:
r
(
f
)
=
1
N
∑
v
∈
V
r
(
v
)
(
f
)
(4)
r(f)=\frac1N\sum_{v\in\mathcal{V}}r(v)(f)\tag{4}
r(f)=N1v∈V∑r(v)(f)(4)
本地特征组合向量可以被写作:
r
^
(
v
)
=
[
r
(
v
)
(
f
1
)
,
r
(
v
)
(
f
2
)
,
…
,
r
(
v
)
(
f
F
)
]
,
r
^
(
v
)
∈
R
F
,
(5)
\hat{r}(v)=\begin{bmatrix}r(v)(f_1),r(v)(f_2),\ldots,r(v)(f_F)\end{bmatrix}, \hat{r}(v)\in\mathbb{R}^F,\tag{5}
r^(v)=[r(v)(f1),r(v)(f2),…,r(v)(fF)],r^(v)∈RF,(5)
其中,
f
i
f_{i}
fi是特征矩阵X的列
特征/结构相似性:
S
(
u
,
v
)
=
α
⋅
P
S
(
u
,
v
)
+
(
1
−
α
)
⋅
F
S
(
u
,
v
)
(6)
S(u,v)=\alpha\cdot PS(u,v)+(1-\alpha)\cdot FS(u,v)\tag{6}
S(u,v)=α⋅PS(u,v)+(1−α)⋅FS(u,v)(6)
其中,
S
u
,
v
S_{u,v}
Su,v代表我们提出的特征&FDP-based 节点u和v的相似性
预增强
我们设置如上相似性矩阵的阈值为: S k = S max ⋅ k S_k=S_{\max}\cdot k Sk=Smax⋅k.我们使用邻接矩阵 A ∗ A^{*} A∗取表示预增强图.其中, A i j ∗ = 1 i f S i j > S k A_{ij}^{*}=1\mathrm{~if~}S_{ij}>S_{k} Aij∗=1 if Sij>Sk或 A i j = 1 , A i j ∗ = 0 A_{ij}=1,A_{ij}^*=0 Aij=1,Aij∗=0。
视图生成
基于相似性的边删除
我们根据如下概率矩阵取删除边:
P
d
r
o
p
(
u
,
v
)
=
min
(
(
1
−
S
(
u
,
v
)
)
⋅
p
r
,
τ
r
)
P_{\mathrm{drop}}(u,v)=\min\left(\left(1-S(u,v)\right)\cdot p_r,\tau_r\right)
Pdrop(u,v)=min((1−S(u,v))⋅pr,τr)
其中,
p
r
p_{r}
pr是超参,
τ
r
\tau_{r}
τr是干涉值阻止图崩塌.删边在
A
∗
A^*
A∗上执行
基于本地assortativity的特征增强
由于特征在高LFA的维度重要性会降低,(即特征维度的重要性和LFA负相关),我们定义特征维度的重要性为:
w
f
=
1
−
r
(
f
)
w_f=1-r(f)
wf=1−r(f)
其中,
w
f
w_{f}
wf的范围为[0,1]
最终,我们可以应用正则化特征掩码概率:
P
m
a
s
k
(
f
)
=
min
(
w
max
−
w
f
w
max
−
w
min
⋅
p
f
,
τ
f
)
P_{mask}(f)=\min\left(\frac{w_{\max}-w_f}{w_{\max}-w_{\min}}\cdot p_f,\tau_f\right)
Pmask(f)=min(wmax−wminwmax−wf⋅pf,τf)
p
f
p_{f}
pf 是控制超参控制特征源码概率.
τ
f
<
1
\tau_{f}<1
τf<1 是为了控制掩码概率导致太系数的特征, 我们设置为 0.7
最终, 掩码后的节点特征矩阵可以表示为:
X
~
=
[
x
1
∘
m
~
;
x
2
∘
m
~
;
⋯
;
x
N
∘
m
~
]
\widetilde{\mathbf{X}}=[\mathbf{x}_1\circ\widetilde{\mathbf{m}};\mathbf{x}_2\circ\widetilde{\mathbf{m}};\cdots;\mathbf{x}_N\circ\widetilde{\mathbf{m}}]
X
=[x1∘m
;x2∘m
;⋯;xN∘m
]
m
~
\tilde{m}
m~ 表示节点特征掩码矩阵, 其通过贝努力分布生成.
基于相似性的负样本采样
N
S
R
(
u
)
=
{
v
∣
v
≠
u
,
v
≠
u
′
,
u
,
v
∈
V
1
∪
V
2
}
\mathrm{NSR}(u)=\{v\mid v\neq u,v\neq u',u,v\in V_1\cup V_2\}
NSR(u)={v∣v=u,v=u′,u,v∈V1∪V2}
其中, u 是目标/锚节点, u’是 u 在另外一个视图的置信节点.
V
i
V_{i}
Vi 表示第 i 个视图.
N
S
(
u
)
=
{
v
∣
S
(
u
,
v
)
<
ξ
,
v
∈
N
S
R
(
u
)
}
\mathrm{NS}(u)=\{v\mid S(u,v)<\xi,v\in\mathrm{NSR}(u)\}
NS(u)={v∣S(u,v)<ξ,v∈NSR(u)}
ξ
\xi
ξ 是控制负样本集的超参
损失函数
最终, 损失函数为:
ℓ
(
u
i
,
v
i
)
=
log
e
θ
(
u
i
,
v
i
)
/
τ
e
θ
(
u
i
,
v
i
)
/
τ
+
∑
v
k
∈
N
S
(
u
i
)
e
θ
(
u
i
,
v
k
)
/
τ
\ell(\mathbf{u}_i,\mathbf{v}_i)=\log\frac{e^{\theta(\mathbf{u}_i,\mathbf{v}_i)/\tau}}{e^{\theta(\mathbf{u}_i,\mathbf{v}_i)/\tau}+\sum_{v_k\in NS(u_i)}e^{\theta(\mathbf{u}_i,\mathbf{v}_k)/\tau}}
ℓ(ui,vi)=logeθ(ui,vi)/τ+∑vk∈NS(ui)eθ(ui,vk)/τeθ(ui,vi)/τ
u
i
u_{i}
ui 是 anchor 节点.
J
=
1
2
N
∑
i
=
1
N
[
ℓ
(
u
i
,
v
i
)
+
ℓ
(
v
i
,
u
i
)
]
.
\mathcal{J}=\frac1{2N}\sum_{i=1}^N\Big[\ell(\mathbf{u}_i,\mathbf{v}_i)+\ell(\mathbf{v}_i,\mathbf{u}_i)\Big].
J=2N1i=1∑N[ℓ(ui,vi)+ℓ(vi,ui)].