目录
Positivity Assumption
An Identification Example with Data
Confounding Bias
Positivity Assumption
调整公式同样强调了正则性(positivity)的重要性。因为你正在对治疗和结果之间的差异在X的条件下求平均,你必须确保对于所有X的分组,治疗组和对照组中都有一定数量的样本,否则差异是没有定义的。更正式地说,治疗的条件概率需要严格大于0且小于1: 1 > P(T|X) > 0。即使正则性条件被违背,识别仍然是可能的,但这将要求你做出可能带来风险的外推。
An Identification Example with Data
由于这可能有些抽象,让我们通过一些具体数据来看看这一切是如何体现的。
为了继续我们的例子,假设你收集了六家公司的数据,其中三家在过去六个月的利润较低(1百万美元),而另外三家利润较高。正如你所猜测的,利润较高的公司更倾向于聘请顾问。三家高利润公司中有两家聘请了顾问,而三家低利润公司中只有一家聘请了顾问(如果样本量过少让你感到困扰,请假设这里的每个数据点实际上代表了10,000家公司):
df = pd.DataFrame(dict(
profits_prev_6m=[1.0, 1.0, 1.0, 5.0, 5.0, 5.0],
consultancy=[0, 0, 1, 0, 1, 1],
profits_next_6m=[1, 1.1, 1.2, 5.5, 5.7, 5.7],
))
df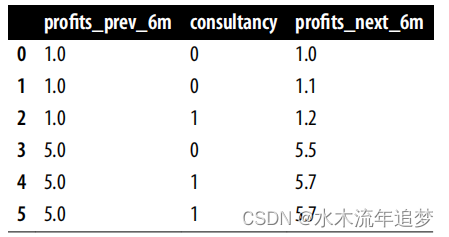
如果你仅仅比较聘请了顾问的公司与未聘请顾问的公司在未来六个月的利润(profits_next_6m),你会得到1.66百万美元的利润差额:
(df.query("consultancy==1")["profits_next_6m"].mean()
- df.query("consultancy==0")["profits_next_6m"].mean())
1.666666666666667但你了解得更多。这并不是咨询服务对公司业绩的因果效应,因为过去表现更好的公司在聘请顾问的群体中被过度代表了。为了获得顾问影响的无偏估计,你需要关注具有类似过往业绩的公司。如你所见,这样得出的结果更加谨慎:
avg_df = (df
.groupby(["consultancy", "profits_prev_6m"])
["profits_next_6m"]
.mean())
avg_df.loc[1] - avg_df.loc[0]
profits_prev_6m
1.0 0.15
5.0 0.20
Name: profits_next_6m, dtyp如果你对这些效应取加权平均,其中权重是各组的大小,你最终会得到一个无偏的ATE估计值。在这里,由于两组的规模相等,这只是一个简单的平均值,给出的ATE大约是175,000美元。因此,如果你是一名经理,在决定是否聘请顾问时面对上述数据,你可以得出结论,顾问对未来利润的影响约为175,000美元。当然,为了做到这一点,你必须援引CIA(条件独立性假设)。也就是说,你必须假设过去的业绩是聘请顾问和未来业绩之间唯一的共同原因。
你刚刚经历了一个完整的例子,将你对因果机制的信念编码到一个图中,并使用该图找出你需要对哪些变量进行条件化以估计ATE,甚至在没有随机化治疗的情况下也能做到。然后,你看到了一些数据,按照调整公式估计了ATE,并假设了条件独立性。这里使用的工具相当通用,将会指导你解决许多即将到来的因果问题。
Confounding Bias
第一个重要的偏差来源是混杂偏倚。这是我们迄今为止一直在讨论的偏差,现在我们只是给它起了个名字。当存在一个开放的后门路径,允许关联非因果地流动时,通常是因为治疗和结果共享一个共同的原因,就会发生混杂。例如,假设你在人力资源部门工作,你想知道你们新的管理培训项目是否提高了雇主的参与度。然而,由于培训是自愿的,你认为只有那些已经表现出色的经理才会参加培训,而最需要培训的人却不会参加。当你衡量接受过培训的经理手下团队的参与度时,它远高于那些未参加培训的经理手下团队的参与度。但很难判断这其中有多少是因果关系造成的。由于治疗和结果之间存在共同的原因,无论是否有因果效应,它们都会一起变化。
为了识别那个因果效应,你需要关闭治疗和结果之间的所有后门路径。如果你做到了这一点,剩下的唯一效应就是直接效应T->Y。在我们的例子中,你可以设法控制经理在参加培训之前的素质。在这种情况下,结果的差异将仅归因于培训,因为治疗组和对照组之间经理在培训前的素质将保持一致。简而言之,为了调整混杂偏倚,你需要调整治疗和结果的共同原因: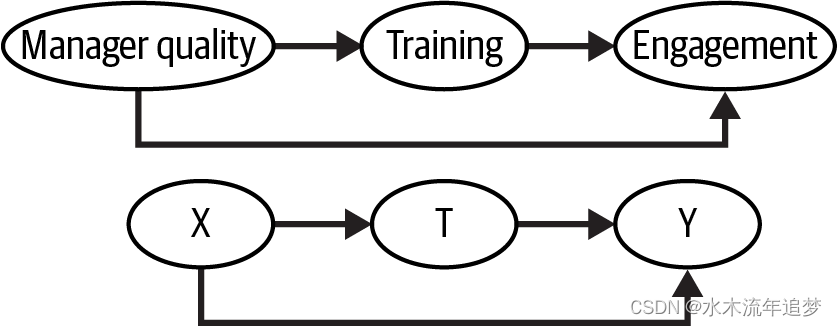
不幸的是,不可能总是调整所有共同的原因。有时,存在未知的原因或者已知但无法测量的原因。经理素质就是一个例子。尽管付出了所有努力,我们至今仍未弄清楚如何衡量管理质量。如果你无法观察到经理的素质,那么你就无法对其条件化,因此培训对参与度的影响是无法识别的。