apply函数是我们经常用到的一个Pandas操作。虽然这在较小的数据集上不是问题,但在处理大量数据时,由此引起的性能问题会变得更加明显。虽然apply的灵活性使其成为一个简单的选择,但本文介绍了其他Pandas函数作为潜在的替代方案。
在这篇文章中,我们将通过一些示例讨论apply、agg、map和transform的预期用途。
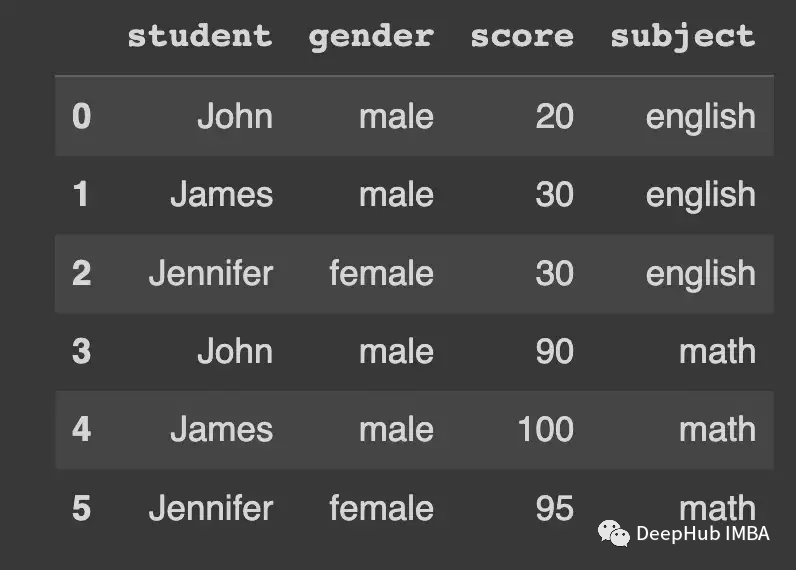
我们一个学生分数为例
df_english=pd.DataFrame(
{
"student": ["John", "James", "Jennifer"],
"gender": ["male", "male", "female"],
"score": [20, 30, 30],
"subject": "english"
}
)
df_math=pd.DataFrame(
{
"student": ["John", "James", "Jennifer"],
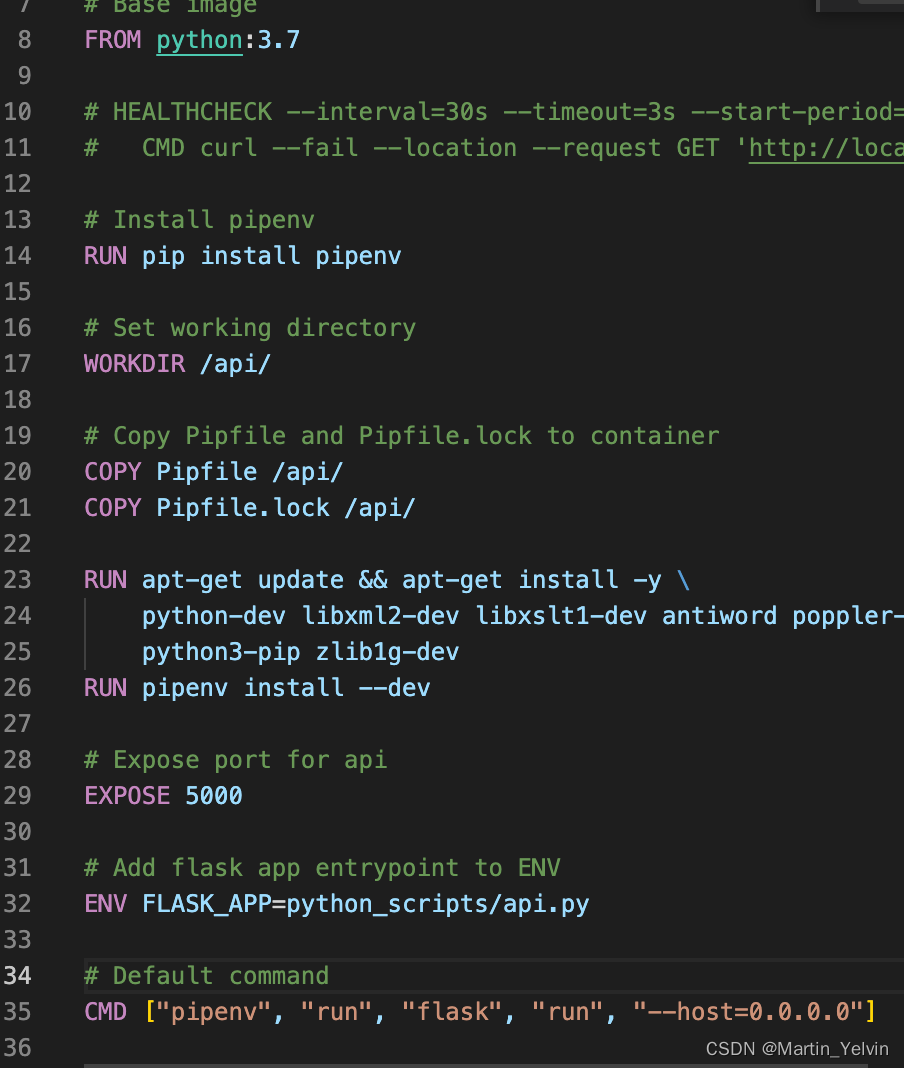
"gender": ["male", "male", "female"],
"score": [90, 100, 95],
"subject": "math"
}
)
df=pd.concat(
[df_english, df_math],
ignore_index=True
)
map
Series.map(arg, na_action=None) -> Series
map方法适用于Series,它基于传递给函数的参数将每个值进行映射。arg可以是一个函数——就像apply可以取的一样——也可以是一个字典或一个Series。
na_action是指定序列的NaN值如何处理。当设置为"ignore "时,arg将不会应用于NaN值。
例如想用映射替换性别的分类表示时:
GENDER_ENCODING= {
"male": 0,
"female": 1
}
df["gender"].map(GENDER_ENCODING)

虽然apply不接受字典,但也可以完成同样的操作。
df["gender"].apply(lambdax:
GENDER_ENCODING.get(x, np.nan)
)
性能对比
在对包含一百万条记录的gender序列进行编码的简单测试中,map比apply快10倍。
random_gender_series=pd.Series([
random.choice(["male", "female"]) for_inrange(1_000_000)
])
random_gender_series.value_counts()
"""
>>>
female 500094
male 499906
dtype: int64
"""
看看对比结果
"""
map performance
"""
%%timeit
random_gender_series.map(GENDER_ENCODING)
# 41.4 ms ± 4.24 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
"""
apply performance
"""
%%timeit
random_gender_series.apply(lambdax:
GENDER_ENCODING.get(x, np.nan)
)
# 417 ms ± 5.32 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
因为map也可以接受函数,所以任何不依赖于其他元素的转换操作都可以使用。比如使用map(len)或map(upper)这样的东西可以让预处理变得更容易。
applymap
DataFrame.applymap(func, na_action=None, **kwargs) -> DataFrame
applymap与map非常相似,并且是使用apply内部实现的。applymap就像map一样,但是是在DataFrame上以elementwise的方式工作,但由于它是由apply内部实现的,所以它不能接受字典或Series作为输入——只允许使用函数。
try:
df.applymap(dict())
exceptTypeErrorase:
print("Only callables are valid! Error:", e)
"""
Only callables are valid! Error: the first argument must be callable
"""
na_action的工作原理和map中的一样。
transform
DataFrame.transform(func, axis=0, *args, **kwargs) -> DataFrame
前两个函数工作在元素级别,而transform工作在列级别。我们可以通过transform来使用聚合逻辑。
假设要标准化数据:
df.groupby("subject")["score"] \
.transform(
lambdax: (x-x.mean()) /x.std()
)
"""
0 -1.154701
1 0.577350
2 0.577350
3 -1.000000
4 1.000000
5 0.000000
Name: score, dtype: float64
我们需要做的是从每个组中获取分数,并用其标准化值替换每个元素。这肯定不能用map来实现,因为它需要按列计算,而map只能按元素计算。
如果使用熟悉apply,那么实现很简单。
df.groupby("subject")["score"] \
.apply(
lambdax: (x-x.mean()) /x.std()
)
"""
0 -1.154701
1 0.577350
2 0.577350
3 -1.000000
4 1.000000
5 0.000000
Name: score, dtype: float64
"""
不仅本质上,代码基本上都是一样的。那么transform有什么意义呢?
Transform必须返回一个与它所应用的轴长度相同的数据框架。
也就是说即使transform与返回聚合值的groupby操作一起使用,它会将这些聚合值赋给每个元素。
例如,假设我们想知道每门课所有学生的分数之和。我们可以像这样使用apply:
df.groupby("subject")["score"] \
.apply(
sum
)
"""
subject
english 80
math 285
Name: score, dtype: int64
"""
但我们按学科汇总了分数,丢失了学生个体与其分数之间的关联信息。用transform做同样的事情,我们会得到更有趣的东西:
df.groupby("subject")["score"] \
.transform(
sum
)
"""
0 80
1 80
2 80
3 285
4 285
5 285
Name: score, dtype: int64
"""
因此,尽管我们在分组上操作,但仍然能够得到组级信息与行级信息的关系。
所以任何形式的聚合都会报错,如果逻辑没有返回转换后的序列,transform将抛出ValueError。
try:
df["score"].transform("mean")
exceptValueErrorase:
print("Aggregation doesn't work with transform. Error:", e)
"""
Aggregation doesn't work with transform. Error: Function did not transform
"""
而Apply的灵活性确保它即使使用聚合也能很好地工作。
df["score"].apply("mean")
"""
60.833333333333336
"""
性能对比
就性能而言,transform的速度是apply的2倍。
random_score_df=pd.DataFrame({
"subject": random.choices(["english", "math", "science", "history"], k=1_000_000),
"score": random.choices(list(np.arange(1, 100)), k=1_000_000)
})
"""
Transform Performance Test
"""
%%timeit
random_score_df.groupby("subject")["score"] \
.transform(
lambdax: (x-x.mean()) /x.std()
)
"""
202 ms ± 5.37 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
"""
"""
Apply Performance Test
"""
%%timeit
random_score_df.groupby("subject")["score"] \
.apply(
lambdax: (x-x.mean()) /x.std()
)
"""
401 ms ± 5.37 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
"""
agg
DataFrame.agg(func=None, axis=0, *args, **kwargs)
-> scalar | pd.Series | pd.DataFrame
agg函数更容易理解,因为它只是返回传递给它的数据的聚合。所以无论自定义聚合器是如何实现的,结果都将是传递给它的每一列的单个值。
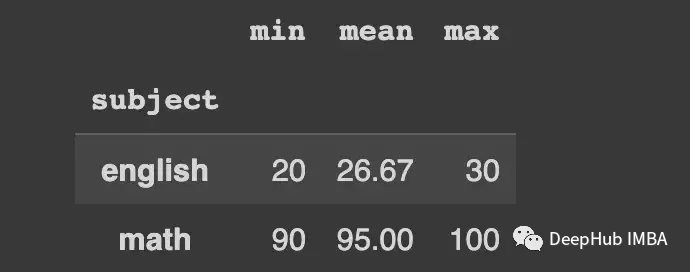
来看看一个简单的聚合——计算每个组在得分列上的平均值。
df.groupby("subject")["score"].agg(mean_score="mean").round(2)

多个聚合器也可以作为列表传递。
df.groupby("subject")["score"].agg(
["min", "mean", "max"]
).round(2)
Agg提供了更多执行聚合的选项。我们还可以构建自定义聚合器,并对每一列执行多个特定的聚合,例如计算一列的平均值和另一列的中值。
性能对比
就性能而言,agg比apply稍微快一些,至少对于简单的聚合是这样。
random_score_df=pd.DataFrame({
"subject": random.choices(["english", "math", "science", "history"], k=1_000_000),
"score": random.choices(list(np.arange(1, 100)), k=1_000_000)
})

"""
Agg Performance Test
"""
%%timeit
random_score_df.groupby("subject")["score"].agg("mean")
"""
74.2 ms ± 5.02 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
"""
"""
Apply Performance Test
"""
%%timeit
random_score_df.groupby("subject")["score"].apply(lambda x: x.mean())
"""
102.3 ms ± 1.16 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
"""
可以看到大约30%的性能提升。当对多个聚合进行测试时,我们会得到类似的结果。
"""
Multiple Aggregators Performance Test with agg
"""
%%timeit
random_score_df.groupby("subject")["score"].agg(
["min", "mean", "max"]
)
"""
90.5 ms ± 16.7 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
"""
"""
Multiple Aggregators Performance Test with apply
"""
%%timeit
random_score_df.groupby("subject")["score"].apply(
lambda x: pd.Series(
{"min": x.min(), "mean": x.mean(), "max": x.max()}
)
).unstack()
"""
104 ms ± 5.78 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
"""
apply
我们用它是因为它灵活。上面的每个例子都可以用apply实现,但这种灵活性是有代价的:就像性能测试所证明的那样,它明显变慢了。

apply的一些问题
apply灵活性是非常好的,但是它也有一些问题,比如
从 2014 年开始,这个问题就一直困扰着 pandas。当整个列中只有一个组时,就会发生这种情况。 在这种情况下,即使 apply 函数预期返回一个Series,但最终会产生一个DataFrame。
结果类似于额外的拆栈操作。 我们这里尝试重现它。 我们将使用我们的原始数据框并添加一个城市列。 假设我们的三个学生 John、James 和 Jennifer 都来自波士顿。
df_single_group=df.copy()
df_single_group["city"] ="Boston"

让我们计算两组组的组均值:一组基于subject 列,另一组基于city。
在subject 列上分组,我们得到了我们预期的多索引。
df_single_group.groupby("subject").apply(lambda x: x["score"])

但当我们按city列分组时,只有一个组(对应于“波士顿”),我们得到:
df_single_group.groupby("city").apply(lambda x: x["score"])

看到结果是如何旋转的吗?如果我们把这些叠起来,我们就会得到预期的结果。
df_single_group.groupby("city").apply(lambda x: x["score"]).stack()
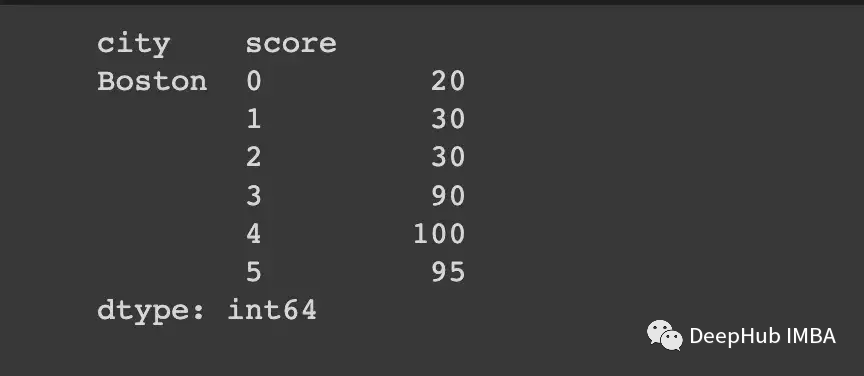
在撰写本文时,这个问题仍然没有得到解决。
总结
apply提供的灵活性使其在大多数场景中成为非常方便的选择,所以如果你的数据不大,或者对处理时间没有硬性的要求,那就直接使用apply吧。如果真的对时间有要求,还是找到优化的方式来操作,这样可以省去大量的时间。
本文代码:
https://avoid.overfit.cn/post/9917bf07402b473c909248dbb5cdebef
作者:Aniruddha Karajgi