文章目录
- 压缩
- 存储&索引
- codegen
- 优化器
- 向量化
如何解决深度分页问题?
- scoll 游标分页 使用的是快照,没法保证实时
- from+size 最差的实现,内存占用和时间都很差
- search_after 搜索上下文 通过记录自增id来查询,减少了内存占用
lucene如何实现倒排索引的?
FST + skiplist
- key/term dict的实现
两个前缀树.tip和.tim
.tip用于快速过滤和找到tim在的block
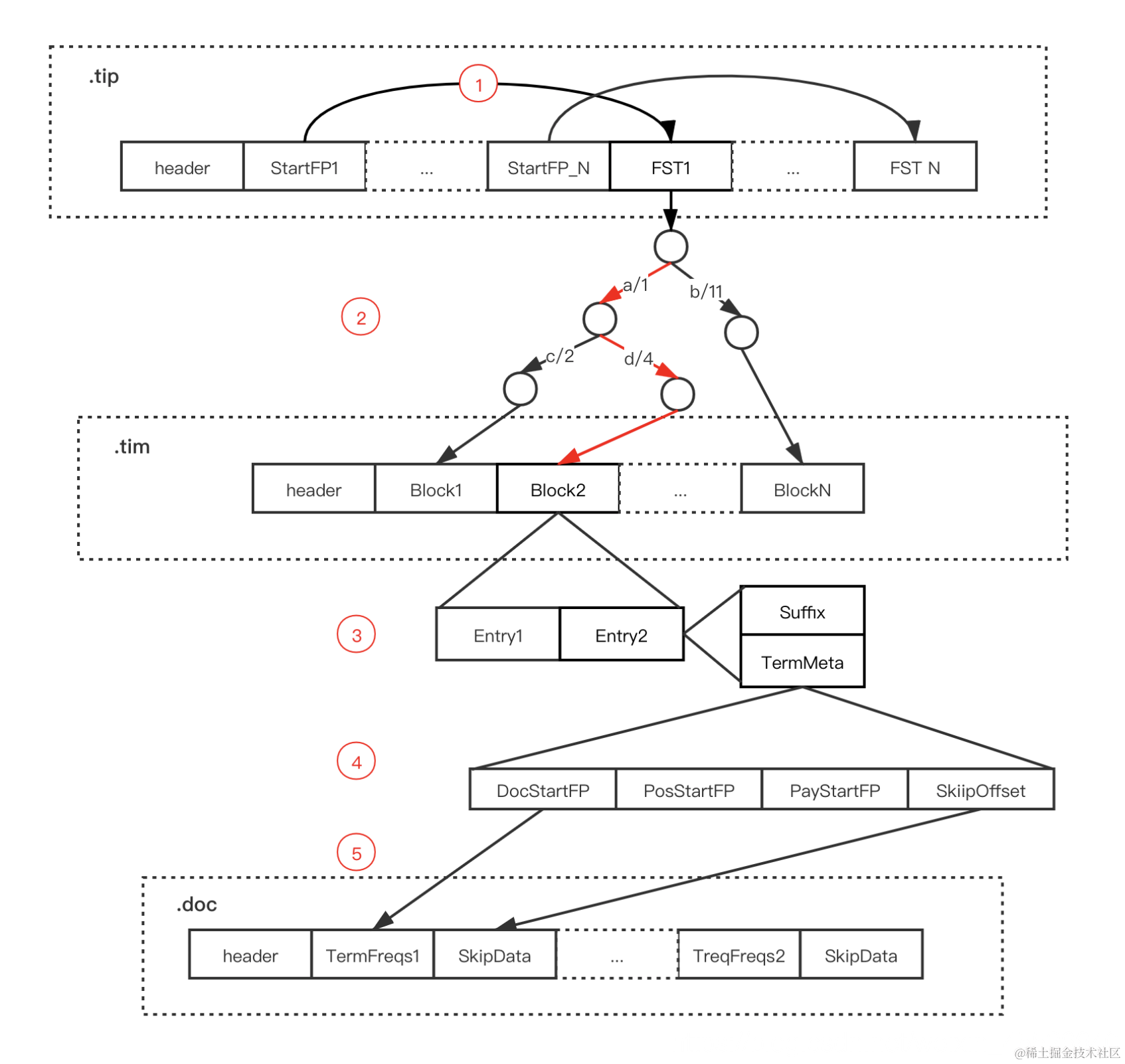
- postlist分成三个文件
.doc后缀文件:记录 Postings 的 docId 信息和 Term 的词频
.pay后缀文件:记录 Payload 信息和偏移量信息
.pos后缀文件:记录位置信息
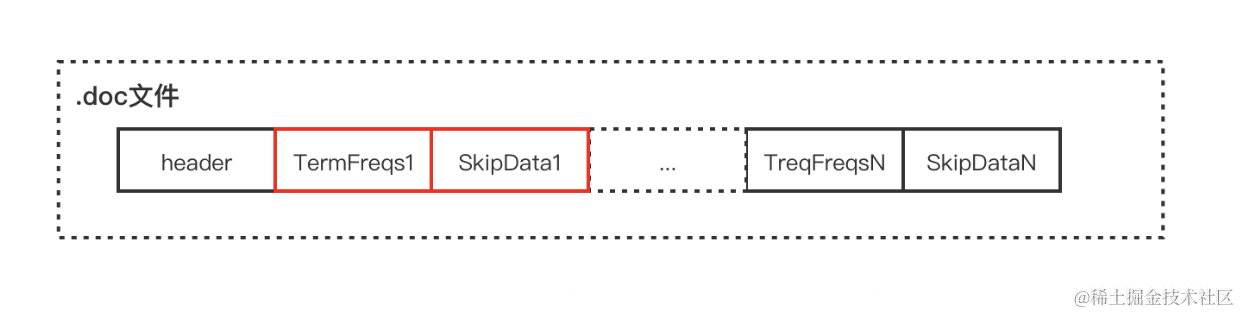
文件结构都是下面这种表示,termFreqs中存储的是文档id和词频(压缩二元组),skipdata用于加速文档id的查找
ES集群的结构是怎样的?
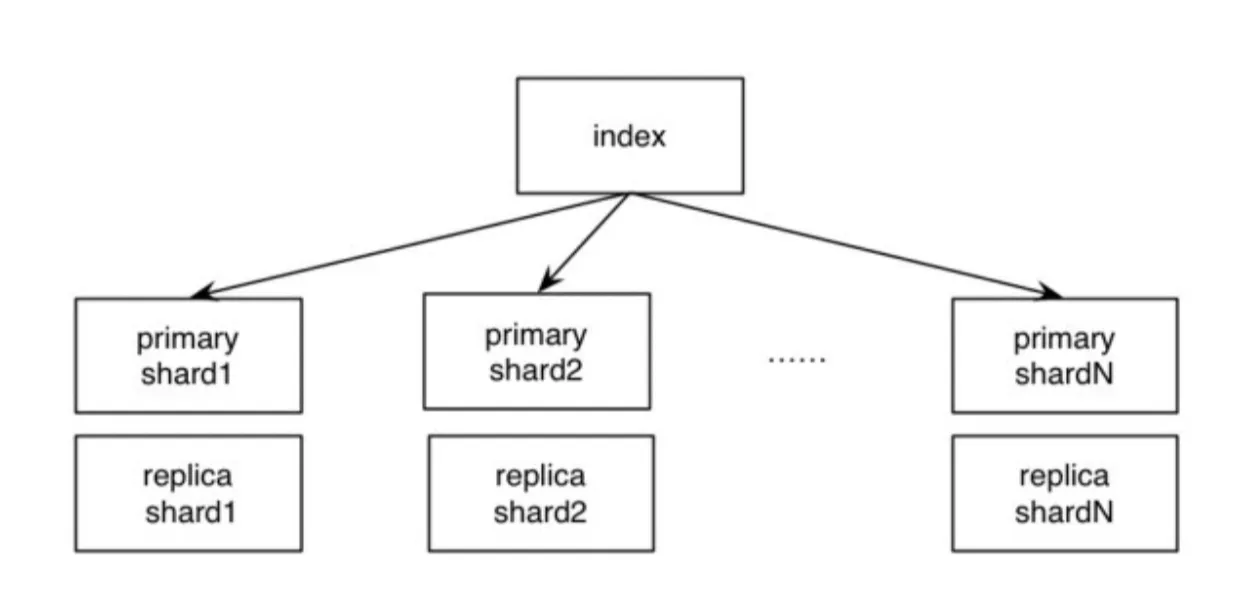
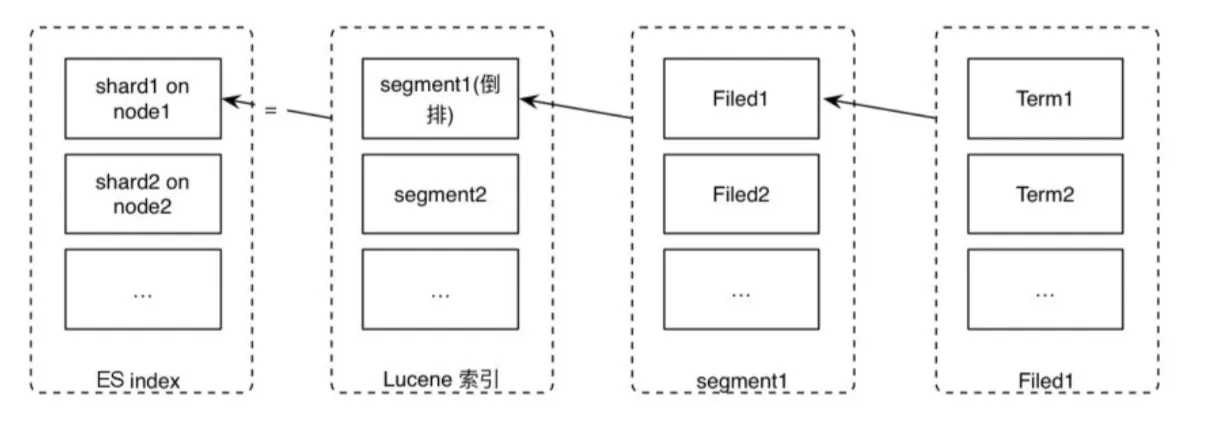
index拆分shard和kafka的topic拆分partition一样的
ES的选主流程是什么样的?
bully算法
(1)参选人数需要过半,达到 quorum(多数)后就选出了临时的主。
(2)得票数需过半。某节点被选为主节点,必须判断加入它的节点数过半,才确认Master身份。解决第一个问题。
(3)当探测到节点离开事件时,必须判断当前节点数是否过半。如果达不到quorum,则放弃Master身份,重新加入集群。
Master节点的作用?
管理索引(创建索引、删除索引)、分配分片
维护元数据
管理集群节点状态
不负责数据写入和查询,比较轻量级
ES的写流程是怎么样的?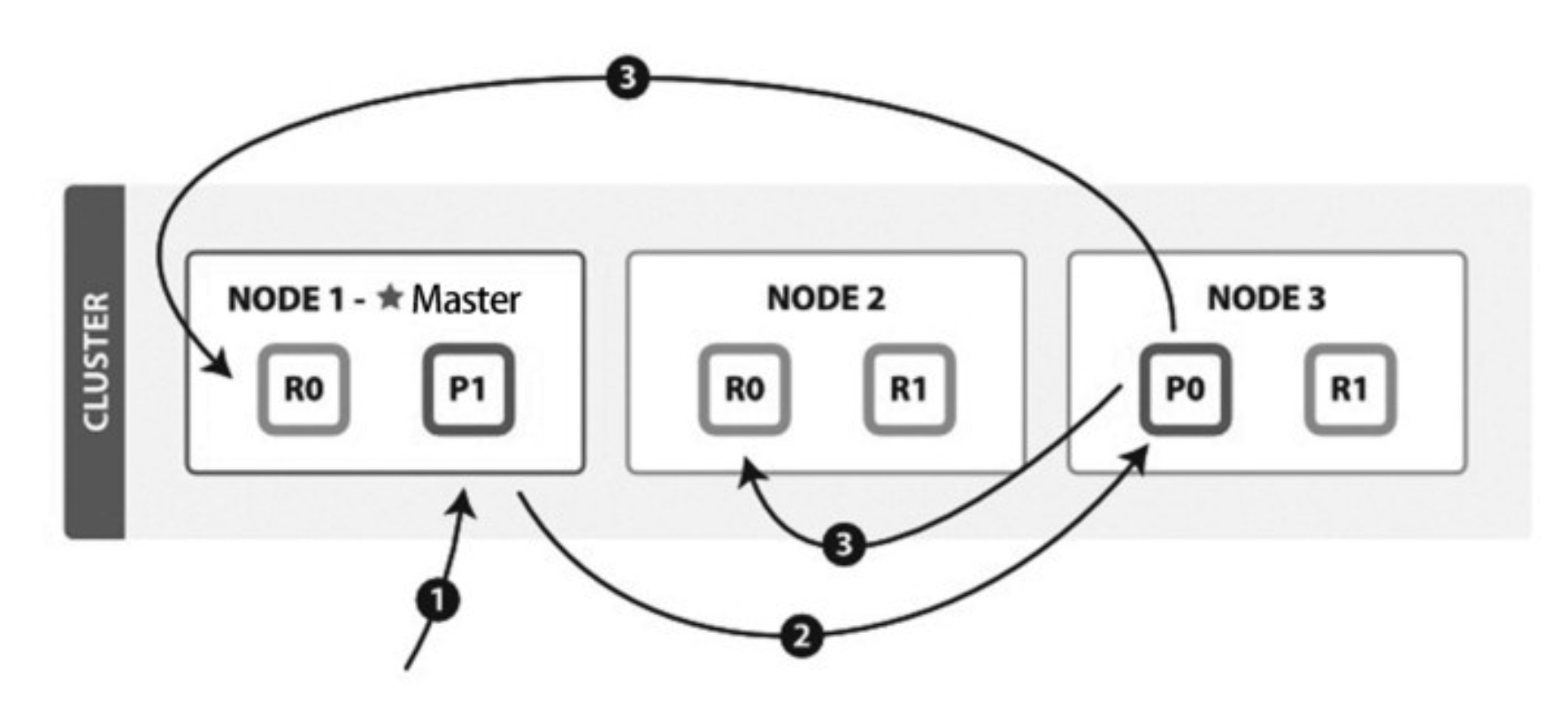
上层写原理
发给随机协调节点 – 转发主分片 – 并行转发副分片
(1)客户端向NODE1(协调节点)发送写请求。
(2)NODE1使用文档ID来确定文档属于分片0,通过集群状态中的内容路由表信息获知分片0的主分片位于NODE3,因此请求被转发到NODE3上。
(3)NODE3上的主分片执行写操作。如果写入成功,则它将请求并行转发到NODE1和NODE2的副分片上,等待返回结果。当所有的副分片都报告成功,NODE3将向协调节点报告成功,协调节点再向客户端报告成功。
写一致性的默认策略是quorum(仲裁一致),即多数的分片(其中分片副本可以是主分片或副分片)在写入操作时处于可用状态。
translog的写入同步还是异步可以被控制。
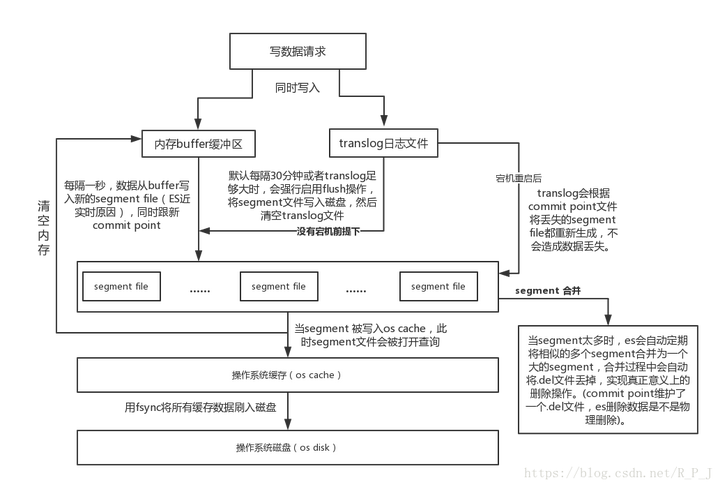
底层写原理
预写日志 – 内存buffer缓冲区
写入的底层原理是什么?
(1)数据先写入 memory buffer,然后定时(默认每隔1s)将 memory buffer 中的数据写入一个新的 segment 文件中,并进入 Filesystem cache(同时清空 memory buffer),这个过程就叫做 refresh;ES 的近实时性:数据存在 memory buffer 时是搜索不到的,只有数据被 refresh 到 Filesystem cache 之后才能被搜索到(分两步猜测是为了减轻pdflush压力),而 refresh 是每秒一次, 所以称 es 是近实时的,可以通过手动调用 es 的 api 触发一次 refresh 操作,让数据马上可以被搜索到;
(2)由于 memory Buffer 和 Filesystem Cache 都是基于内存,假设服务器宕机,那么数据就会丢失,所以 ES 通过 translog 日志文件来保证数据的可靠性,在数据写入 memory buffer 的同时,将数据写入 translog 日志文件中,在机器宕机重启时,es 会自动读取 translog 日志文件中的数据,恢复到 memory buffer 和 Filesystem cache 中去;
(3)flush 操作:不断重复上面的步骤,translog 会变得越来越大,当 translog 文件默认每30分钟或者阈值超过 512M 时,就会触发 commit 操作,即 flush操作。
读流程 【读取是知道在哪个文档】
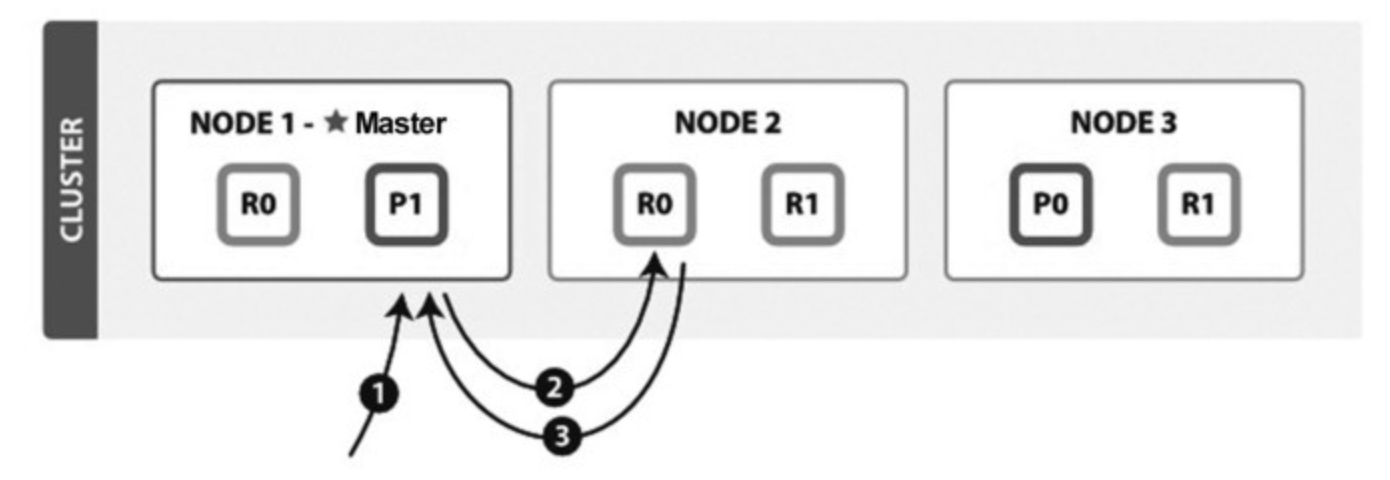
(1)客户端向NODE1发送读请求。
(2)NODE1使用文档ID来确定文档属于分片0,通过集群状态中的内容路由表信息获知分片0有三个副本数据,位于所有的三个节点中,此时它可以将请求发送到任意节点,这里它将请求转发到NODE2。
(3)NODE2将文档返回给 NODE1,NODE1将文档返回给客户端。NODE1作为协调节点,会将客户端请求轮询发送到集群的所有副本来实现负载均衡。
**ES检索的过程是怎样的? 【检索是不知道在哪个文档】1. Query 在初始查询阶段时,查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。 每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。
每个分片返回各自优先队列中所有文档的 ID 和排序值 给协调节点,它合并这些值到自己的优先队列中来产生一个全局排序**后的结果列表。
2. Fetch 接下来就是 取回阶段,协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。每个分片加载并 丰富 文档,如果有需要的话,接着返回文档给协调节点。一旦所有的文档都被取回了,协调节点返回结果给客户端。
在高并发场景下,ES如何保证读写一致的?
(1)对于更新操作:可以通过版本号使用乐观并发控制,以确保新版本不会被旧版本覆盖
每个文档都有一个_version 版本号,这个版本号在文档被改变时加一。Elasticsearch使用这个 _version 保证所有修改都被正确排序。当一个旧版本出现在新版本之后,它会被简单的忽略。
利用_version的这一优点确保数据不会因为修改冲突而丢失。比如指定文档的version来做更改。如果那个版本号不是现在的,我们的请求就失败了。
(2)对于写操作,一致性级别支持 quorum/one/all,默认为 quorum,即只有当大多数分片可用时才允许写操作。但即使大多数可用,也可能存在因为网络等原因导致写入副本失败,这样该副本被认为故障,分片将会在一个不同的节点上重建。
- one:要求我们这个写操作,只要有一个primary shard是active活跃可用的,就可以执行
- all:要求我们这个写操作,必须所有的primary shard和replica shard都是活跃的,才可以执行这个写操作
- quorum:默认的值,要求所有的shard中,必须是大部分的shard都是活跃的,可用的,才可以执行这个写操作
(3)对于读操作,可以设置 replication 为 sync(默认),这使得操作在主分片和副本分片都完成后才会返回;如果设置replication 为 async 时,也可以通过设置搜索请求参数_preference 为 primary 来查询主分片,确保文档是最新版本。
可以看到,ES采用了和Cassandra以及Dynamo一样的仲裁一致读写方案,参考DDIA,这种方案能够保证线性一致的读写,但是不能保证比较和更新的线性一致性。
倒排索引的结构?如何优化posting list?
倒排索引由key和posting list构成,posting list可以用很多结构实现,比如红黑树、跳表、链表等。
优化归并过程
posting list往往会用于归并过程(join),这里我们很容易想到spark的join策略:嵌套循环、排序归并和哈希归并。他们的复杂度分别是m*n,m+n和n(较大)。
因为posting list天生有序,所以这里主要的策略在于加速排序归并和哈希归并过程。
排序归并可以用跳表和红黑树,双指针相互二分查找将每次搜索的复杂度降低到logk。
Lucene和Elasticsearch就采用了这种方法。
同样,posting list也可以使用哈希表和位图来实现。
Roaring Bitmap
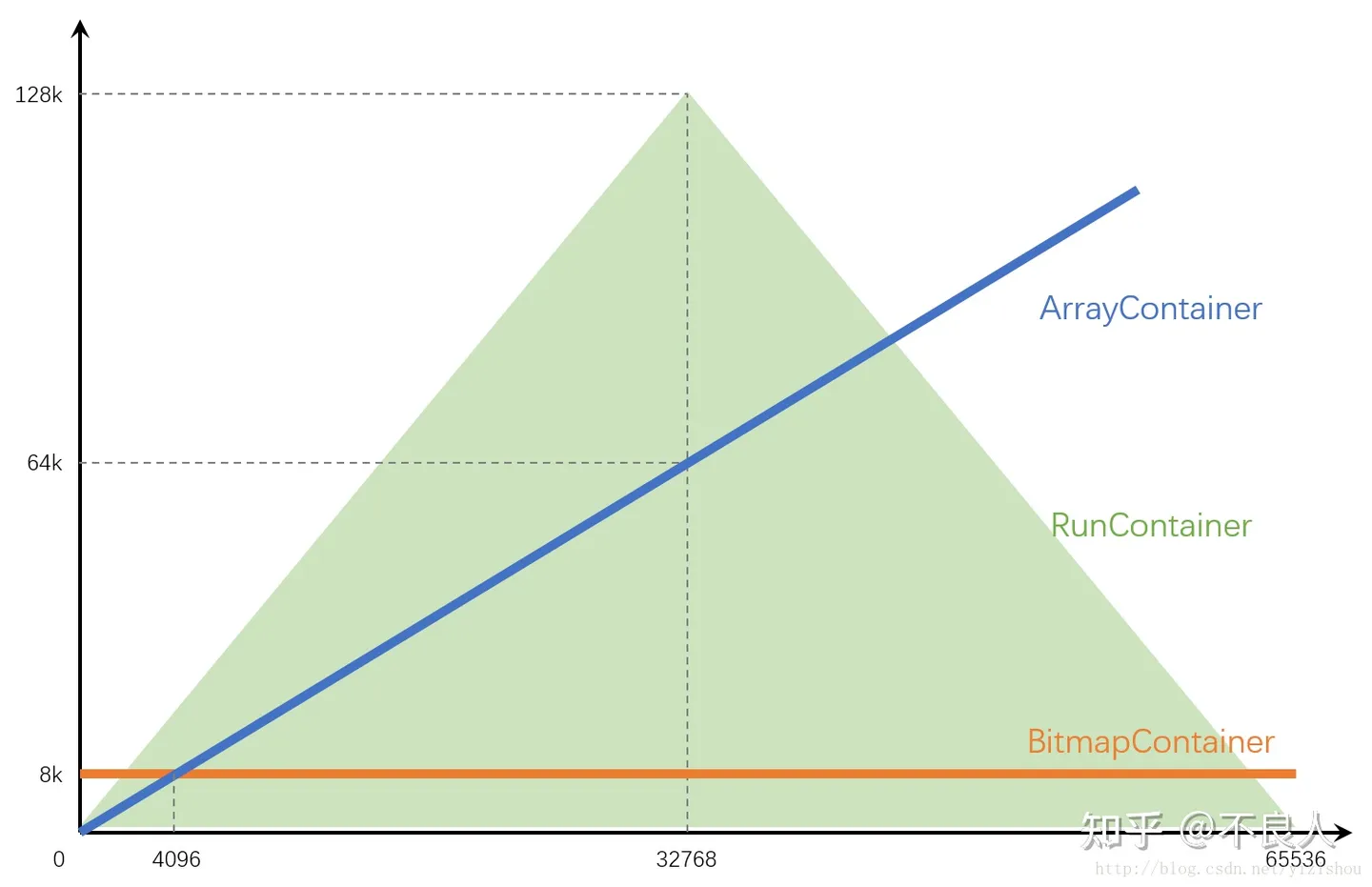
普通的哈希表和位图很简单,不再赘述。更广泛使用的是Roaring Bitmap(压缩位图)。
Roaring Bitmap简单来说,就是用高16位哈希到桶的编号,低16位再哈希到bitmap,这样如果元素稀疏的话,就能节省没有bitmap的桶的空间。
低16位桶的数量如果少于4096,那么bitmap就使用数组容器来节省空间,否则使用位图容器。
Roaring Bitmap的三种实现空间占用和数据大小的关系:RunContainer的编码是运行长度编码(RLE)
压缩
说一说常用的压缩方法
- 游程编码(RLC, Run Length Coding)
- 字典压缩 如哈夫曼编码
- 位图编码 (也可以当作字典压缩的一种,适用于基数较小的情况)
- 增量编码 (记录相邻行之间的差异)
- 比特打包 (缩短位数)
存储&索引
比较一下行存和列存的优缺点?
行存: 适合元组信息,适合复杂的业务型数据库(涉及多个字段);不适合对于部分列的扫描,不适合压缩
列存:减少io量,适合分析型数据库,压缩比更高
你做过spark,应该了解parquet和orc吧,说一下parquet和orc的存储方式?
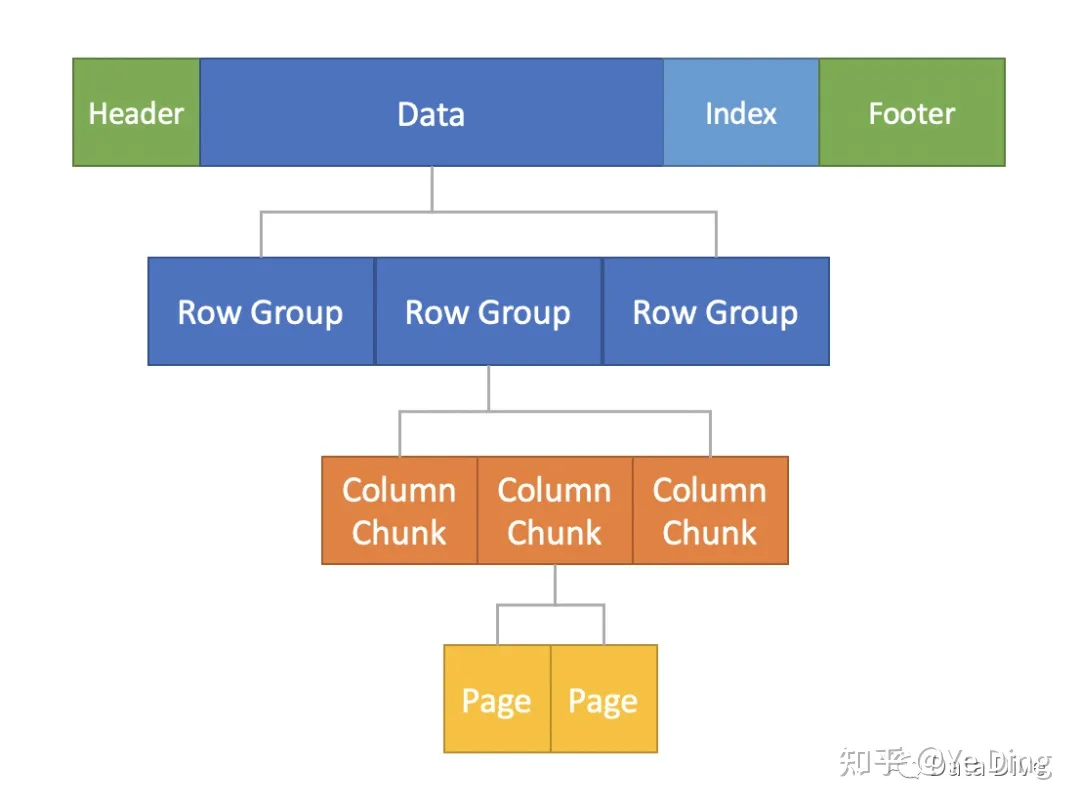
parquet
- 按照大小切分成group,group按照列切分成chunk,chunk按照page切分(先水平,再垂直)
目的是为了并行计算
- 元信息包括: min/max,编码字典
- 使用层级编码嵌套结构
ORC
和parquet一样,分为file、stripe、row group三个级别,分别有自己的元信息
支持布隆过滤器,并且对索引和压缩做了优化。支持事务,不支持复杂嵌套
元信息为什么一般写在尾部而不是头部?
- 减少修改数据时的io,如果追加写需要修改元数据,那么就会造成更高的成本
- 减少读取数据时的io
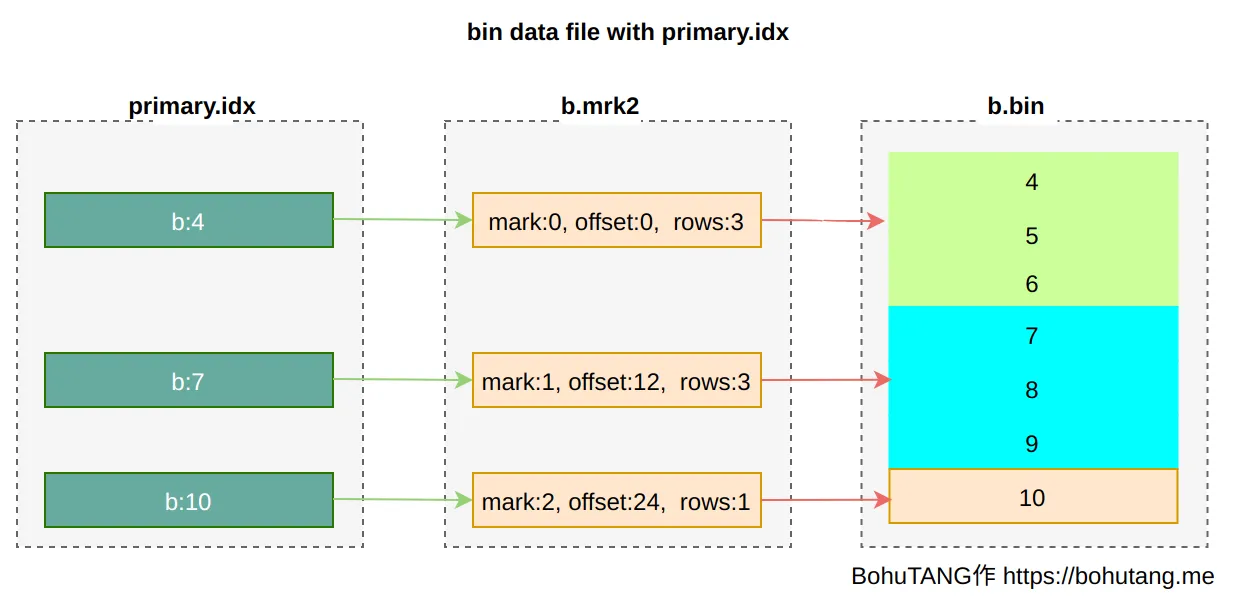
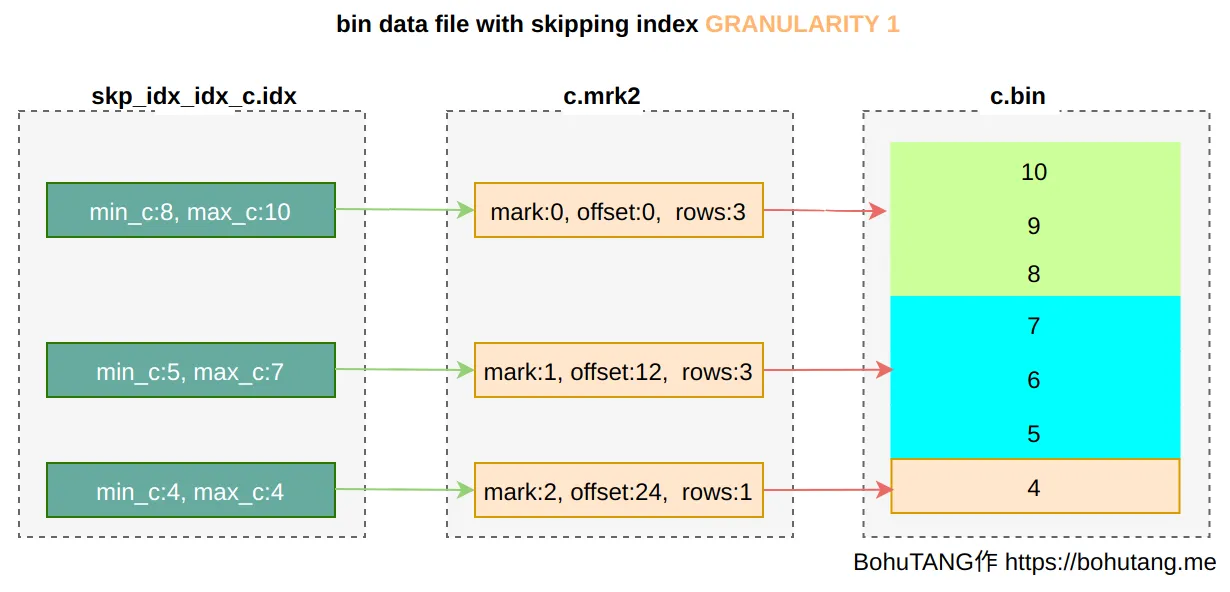
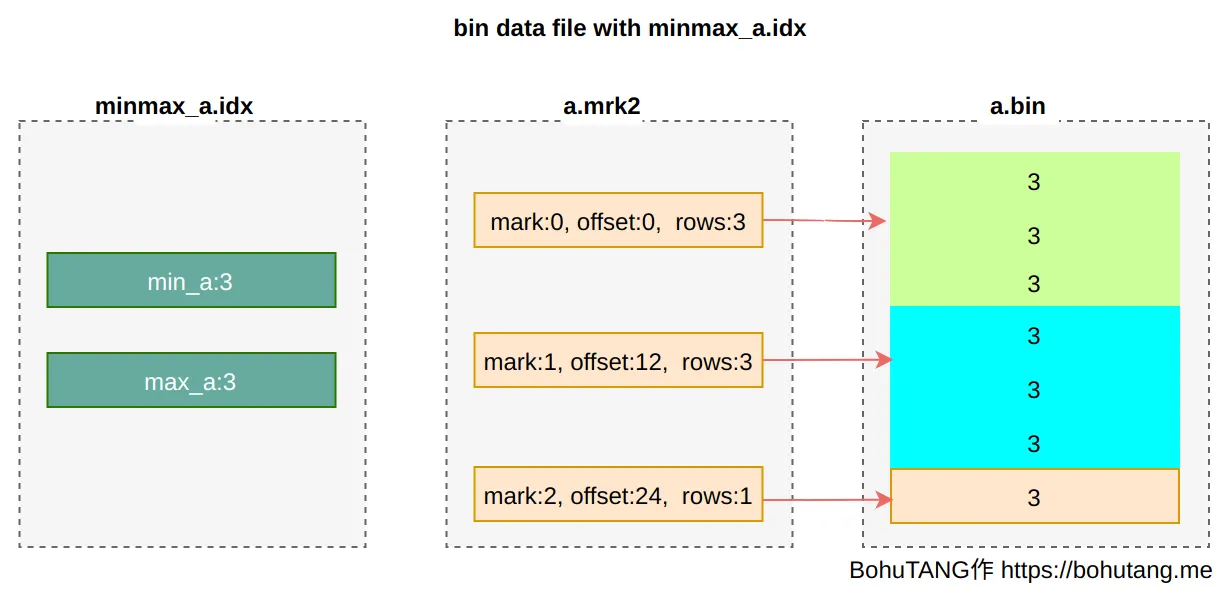
说一说ck的存储方式?
主键索引
普通索引
分区键索引
codegen
你了解codegen吗?怎么做的?
一般gen的都是weld IR/LLVM IR/当前语言。spark使用janino
手写代码的生成过程分为两个步骤:
- 从父节点到子节点,递归调用 doProduce,生成框架
- 从子节点到父节点,递归调用 doConsume,向框架填充每一个操作符的运算逻辑
优化器
说说你都在calcite做了什么
- 常量折叠、算子消除
- 谓词下推、列裁剪、投影下推
- 关联子查询优化
- IKKBZ算法做RBO
向量化
单独复习
说说向量化有哪些方法
遮罩 重排 选择性加载 压缩 扩散
说说向量化是什么
基本的并行手段主要有三种:
(1) instruction-level parallelism (ILP) 指令并行 如超标量、流水线(在GPU中叫做流水线并行)
(2) thread-level parallelism (TLP) 多核并行 如openmp 和 pthread (在GPU中叫数据并行或者SIMT)
(3) vector-level parallelism 张量并行 如SIMD(在GPU中叫张量并行)
说说你看过的CK向量化代码
- memcpy 预取 对齐 循环展开(8次) 内存直写避免污染缓存
- pargma 使用omp/simd/vector自动向量化
- restrict 显式告诉编译器参数是内存中的不同位置
#pragma omp parallel
说说你在项目中怎么用的向量化
- 将8个字节压缩到1个字节中,使用shuffle将1个字节扩展到8个字节
- 计算两个地址之间有多少个0
怎么处理对齐?
先处理128位或者512位不对齐的部分,再处理剩下的部分
矩阵乘法怎么优化?
- 列主序
- 向量化
两个相同大小的矩阵,a[i][j] = a[i][j]怎么优化?