🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
一、Prophet介绍
二、实验背景
三、数据集介绍
四、技术工具
五、实验过程
六、总结
源代码
文末推荐与福利
一、Prophet介绍
Prophet 是由 Facebook 开发的一个开源时间序列预测库,设计考虑了业务场景中的时间序列特点,如季节性变化、假日效应和趋势变化。Prophet 特别适合处理日级别(或以上频率)的时间序列数据,并且在处理缺失数据和异常值方面表现出色。
安装
pip install prophet学习文档
github地址:https://github.com/facebook/prophet
文档地址:http://facebook.github.io/prophet
英文教程文档:https://facebook.github.io/prophet/docs/quick_start.html#python-api
中文翻译:https://www.cnblogs.com/wt11/collections/1524
模型原理
y(t)=g(t)+s(s)+h(t)+ϵt
g(t)表示增长函数,用来拟合非周期性变化的。
s(t)用来表示周期性变化,比如说每周,每年,季节等。
h(t)表示假期,节日等特殊原因等造成的变化。
ϵt为噪声项,用他来表示随机无法预测的波动,我们假设ϵt是高斯的。
Prophet的默认参数
def __init__(
self,
growth='linear',
changepoints=None,
n_changepoints=25,
changepoint_range=0.8,
yearly_seasonality='auto',
weekly_seasonality='auto',
daily_seasonality='auto',
holidays=None,
seasonality_mode='additive',
seasonality_prior_scale=10.0,
holidays_prior_scale=10.0,
changepoint_prior_scale=0.05,
mcmc_samples=0,
interval_width=0.80,
uncertainty_samples=1000,
)1、growth:增长趋势模型,分为“linear”与“logistic”,分别代表线性与非线性的增长,默认值为linear。
2、Capacity:在增量函数是逻辑回归函数的时候,需要设置的容量值,表示非线性增长趋势中限定的最大值,预测值将在该点达到饱和.
3、Change Points:可以通过 n_changepoints 和 changepoint_range 来进行等距的变点设置,也可以通过人工设置的方式来指定时间序列的变点,默认值:“None”.
4、n_changepoints:用户指定潜在的”changepoint”的个数,默认值:25。
5、changepoint_prior_scale:增长趋势模型的灵活度。调节”changepoint”选择的灵活度,值越大,选择的”changepoint”越多,从而使模型对历史数据的拟合程度变强,然而也增加了过拟合的风险。默认值:0.05。
6、seasonality_prior_scale(seasonality模型中的):调节季节性组件的强度。值越大,模型将适应更强的季节性波动,值越小,越抑制季节性波动,默认值:10.0.
7、holidays_prior_scale(holidays模型中的):调节节假日模型组件的强度。值越大,该节假日对模型的影响越大,值越小,节假日的影响越小,默认值:10.0。
8、freq:数据中时间的统计单位(频率),默认为”D”,按天统计.
9、periods:需要预测的未来时间的个数。例如按天统计的数据,想要预测未来一年时间内的情况,则需填写365。
10、mcmc_samples:mcmc采样,用于获得预测未来的不确定性。若大于0,将做mcmc样本的全贝叶斯推理,如果为0,将做最大后验估计,默认值:0。
11、interval_width:衡量未来时间内趋势改变的程度。表示预测未来时使用的趋势间隔出现的频率和幅度与历史数据的相似度,值越大越相似,默认值:0.80。当mcmc_samples = 0时,该参数仅用于增长趋势模型的改变程度,当mcmc_samples > 0时,该参数也包括了季节性趋势改变的程度。
12、uncertainty_samples:用于估计未来时间的增长趋势间隔的仿真绘制数,默认值:1000。
13、yearly_seasonality: 数据是否有年季节性,默认“自动检测”。
14、weekly_seasonality: 数据是否有周季节性,默认“自动检测”。
15、daily_seasonality: 数据是否有天季节性,默认“自动检测”。
16、seasonality_mode: 季节性效应模式,默认加法模式“additive”,可选“multiplicative”乘法模式。
二、实验背景
在当今复杂多变的金融市场中,股票价格预测一直是投资者和分析师关注的焦点。准确预测股票价格趋势对于投资者制定投资策略、规避风险和实现资本增值具有重要意义。然而,股票价格受到多种因素的影响,包括宏观经济环境、公司财务状况、市场情绪等,这些因素使得股票价格预测变得复杂且充满挑战。
阿里巴巴(BABA)作为全球知名的电子商务平台,其股票价格一直受到广泛关注。投资者和分析师对阿里巴巴股票价格趋势的预测需求日益增长,希望通过预测结果来指导投资决策。然而,由于股票价格受到多种因素的影响,传统的线性预测模型往往难以准确捕捉股票价格的动态变化。
因此,本实验旨在利用Prophet时间序列模型对阿里巴巴股票价格趋势进行预测。Prophet模型是一种基于可分解的时间序列模型,由趋势项、季节项和假期因素组成,能够灵活捕捉时间序列数据中的周期性、趋势性和异常值等特点。该模型在处理时间序列数据时具有较高的精度和可解释性,已被广泛应用于各种预测场景。
三、数据集介绍
本实验数据集来源于Kaggle,数据集包含阿里巴巴集团控股公司(BABA)从[2020年1月1日]到[2024年5月1日]的历史股价数据。数据集包括每日开盘价、最高价、最低价和收盘价,以及调整后的收盘价和成交量。

四、技术工具
Python版本:3.10
代码编辑器:jupyter notebook+VScode
五、实验过程
首先导入第三方库并加载数据集
import numpy as np
import pandas as pd
from prophet import Prophet
import warnings
warnings.filterwarnings("ignore")
df = pd.read_csv('BABA.csv')
df.head()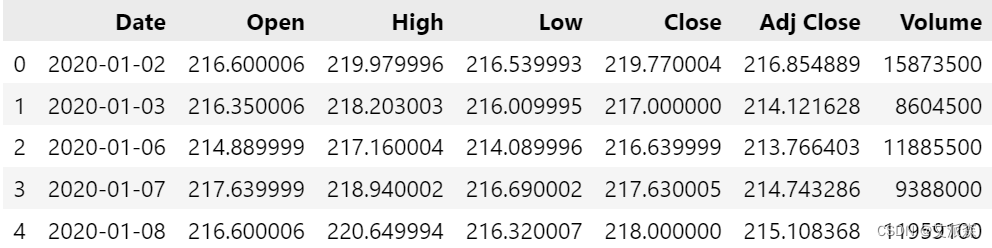
筛选出建模需要的特定列并重命名
模型需要两列:1.ds 时间列 2.y 数据列
对于ds的要求:
- 对于只有日期没有时间的数据,ds列应该是YYYY-MM-DD格式的字符串或者pandas的datetime类型数据。
- 如果数据包含时间戳,ds列应该是YYYY-MM-DD HH:MM:SS格式的字符串或者pandas的datetime类型数据。
# 筛选特定列
new_df = df[['Date','Close']]
# 为Prophet Model 时间序列:ds, price:y重命名列
new_df.columns = ['ds','y']
new_df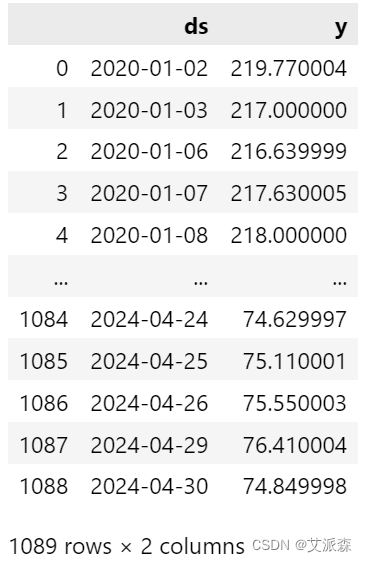
初始化模型并训练,最后使用模型预测未来360天的数据
主要的理解在make_future_dataframe是根据freq以及periods,创建未来日期的数据帧,freq可以为'30s', 'T',默认为'D',分别为30s,每分钟,每天,periods的意思就是多少个freq的时间。
# 初始化模型
model = Prophet()
# 训练模型
model.fit(new_df)
future = model.make_future_dataframe(periods=360,freq='D') # 预测未来360天
# 模型预测
guess = model.predict(future)
guess
最后将模型预测结果可视化
model.plot(guess)
上图中黑色的点表示原始的时间序列离散点;深蓝色的线表示使用时间序列来拟合所得到的取值;
浅蓝色的区域表示时间序列的一个置信区间,也就是所谓的合理的上界和下界。原始数据只到2024-04-30就结束了,后面的都是模型预测的数据趋势。
六、总结
本实验利用阿里巴巴集团控股公司(BABA)从2020年1月1日至2024年5月1日的历史股价数据,通过Prophet时间序列模型对其未来360天的股票价格趋势进行了预测。实验的目的是评估Prophet模型在股票价格预测方面的应用效果,并为投资者提供参考信息。同时本实验证明了Prophet模型在股票价格预测方面的应用潜力。未来,我们可以进一步优化模型结构、引入更多相关因素,以提高预测准确性和可靠性。同时,我们也将关注其他先进的预测方法和技术,以探索更优秀的股票价格预测方案。
源代码
import numpy as np
import pandas as pd
from prophet import Prophet
import warnings
warnings.filterwarnings("ignore")
df = pd.read_csv('BABA.csv')
df.head()
# 筛选特定列
new_df = df[['Date','Close']]
# 为Prophet Model 时间序列:ds, price:y重命名列
new_df.columns = ['ds','y']
new_df
# 初始化模型
model = Prophet()
# 训练模型
model.fit(new_df)
future = model.make_future_dataframe(periods=360,freq='D') # 预测未来360天
# 模型预测
guess = model.predict(future)
guess
model.plot(guess)
文末推荐与福利
《码农职场 IT人求职就业手册》免费包邮送出2本!

内容简介:
专为广大IT 行业求职者量身定制的指南,提供了从职前准备到成功就业的全方位指导。全书分为“职前调整”和“就业指南”上下两篇,涵盖了职业目标规划、自我技能评估、求职策略、简历准备技巧、薪资福利谈判以及职场心理准备等关键环节。全书通过深入浅出的解析和简明实用的建议,可帮助IT 求职者清晰地定义自己的职业目标,有效地评估和展示自己的技能,以及掌握求职过程中的关键技巧,从而在激烈的职场竞争中脱颖而出,成功收到理想的录取通知。
- 抽奖方式:评论区随机抽取2位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2024-8-5 20:00:00
名单公布时间:2024-8-5 21:00:00
资料获取,更多粉丝福利,关注下方公众号获取