前言:目标检测 | yolov1 原理和介绍
简介
论文链接:https://arxiv.org/abs/1612.08242
时间:2016年
作者:Joseph Redmon
作者首先在YOLOv1的基础上提出了改进的YOLOv2,然后提出了一种检测与分类联合训练方法,使用这种联合训练方法在COCO检测数据集和ImageNet分类数据集上训练出了YOLO9000模型,其可以检测超过9000多类物体。所以,这篇文章其实包含两个模型:YOLOv2和YOLO9000,不过后者是在前者基础上提出的,两者模型主体结构是一致的。YOLOv2相比YOLOv1做了很多方面的改进,这也使得YOLOv2的mAP有显著的提升,并且YOLOv2的速度依然很快,保持着自己作为one-stage方法的优势.
改进策略
YOLOv1虽然检测速度很快,但是在检测精度上却不如R-CNN系检测方法,YOLOv1在物体定位方面(localization)不够准确,并且召回率(recall)较低。YOLOv2共提出了几种改进策略来提升YOLO模型的定位准确度和召回率,从而提高mAP,YOLOv2在改进中遵循一个原则:保持检测速度,这也是YOLO模型的一大优势。YOLOv2的改进策略如图所示,可以看出,大部分的改进方法都可以比较显著提升模型的mAP。

- Batch Normalization
Batch Normalization可以提升模型收敛速度,而且可以起到一定正则化效果,降低模型的过拟合。在YOLOv2中,每个卷积层后面都添加了Batch Normalization层,并且不再使用droput。使用Batch Normalization后,YOLOv2的mAP提升了 2.4 % 2.4\% 2.4%。
解释:BN层是把神经元的输出减去均值除以标准差,变成以0为均值,标准差为1得分布。
强行把神经元输出集合在0附近原因是:一些激活函数比如sigmod激活函数或者双曲正切激活函数在0附近是非饱和区,如果输出太大或者太小,会陷入激活函数的饱和区,意味着梯度消失,会难以训练。经过BN之后,原本很分散的数据都集中到了0得附近,对于双曲正切函数来说在0附近有较大得梯度。经过BN层之后,双峰的图像数据在中间也有较好的体现,可以更好地保留原始数据。
CNN在训练过程中网络每层输入的分布一直在改变, 会使训练过程难度加大,对网络的每一层的输入(每个卷积层后)都做了归一化,这样网络就不需要每层都去学数据的分布,收敛会更快。
-
High Resolution Classifier 高分辨率分类器
目前大部分的检测模型都会在先在ImageNet分类数据集上预训练模型的主体部分(CNN特征提取器),由于历史原因,ImageNet分类模型基本采用大小为 224 × 224 224 \times 224 224×224的图片作为输入,分辨率相对较低,不利于检测模型。所以YOLOv1在采用 224 × 224 224 \times 224 224×224 分类模型预训练后,将分辨率增加至 448 × 448 448\times 448 448×448,并使用这个高分辨率在检测数据集上finetune。但是直接切换分辨率,检测模型可能难以快速适应高分辨率。所以YOLOv2增加了在ImageNet数据集上使用 448 × 448 448\times 448 448×448输入来finetune分类网络这一中间过程(10 epochs),这可以使得模型在检测数据集上finetune之前已经适用高分辨率输入。使用高分辨率分类器后,YOLOv2的mAP提升了约 4 % 4\% 4%。 -
Convolutional With Anchor Boxes 带锚框的卷积
在YOLOv1中,输入图片最终被划分为 7 × 7 7 \times 7 7×7 网格,每个单元格预测2个边界框。YOLOv1最后采用的是全连接层直接对边界框进行预测,其中边界框的宽与高是相对整张图片大小的,而由于各个图片中存在不同尺度和长宽比(scales and ratios)的物体,YOLOv1在训练过程中学习适应不同物体的形状是比较困难的,这也导致YOLOv1在精确定位方面表现较差。YOLOv2借鉴了Faster R-CNN中RPN网络的先验框(anchor boxes,prior boxes,SSD也采用了先验框)策略。RPN对CNN特征提取器得到的特征图(feature map)进行卷积来预测每个位置的边界框以及置信度(是否含有物体),并且各个位置设置不同尺度和比例的先验框,所以RPN预测的是边界框相对于先验框的offsets值(其实是transform值,详细见Faster R_CNN论文),采用先验框使得模型更容易学习。所以YOLOv2移除了YOLOv1中的全连接层而采用了卷积和anchor boxes来预测边界框。为了使检测所用的特征图分辨率更高,移除其中的一个pool层。在检测模型中,YOLOv2不是采用 448 × 448 448 \times 448 448×448 图片作为输入,而是采用 416 × 416 416 \times 416 416×416 大小。因为YOLOv2模型下采样的总步长为 32 32 32 ,对于 416 × 416 416 \times 416 416×416 大小的图片,最终得到的特征图大小为 13 × 13 13\times 13 13×13,维度是奇数,这样特征图恰好只有一个中心位置。对于一些大物体,它们中心点往往落入图片中心位置,此时使用特征图的一个中心点去预测这些物体的边界框相对容易些。所以在YOLOv2设计中要保证最终的特征图有奇数个位置。对于YOLOv1,每个cell都预测 2 2 2个boxes,每个boxes包含 5 5 5个值: ( x , y , w , h , c ) (x,y,w,h,c) (x,y,w,h,c),前 4 4 4个值是边界框位置与大小,最后一个值是置信度(confidence scores,包含两部分:含有物体的概率以及预测框与ground truth的IOU)。但是每个cell只预测一套分类概率值(class predictions,其实是置信度下的条件概率值),供 2 2 2个boxes共享。YOLOv2使用了anchor boxes之后,每个位置的各个anchor box都单独预测一套分类概率值,这和SSD比较类似(但SSD没有预测置信度,而是把background作为一个类别来处理)。
使用anchor boxes之后,YOLOv2的mAP有稍微下降(这里下降的原因,我猜想是YOLOv2虽然使用了anchor boxes,但是依然采用YOLOv1的训练方法)。YOLOv1只能预测 98 98 98个边界框( 7 × 7 × 2 7 \times 7 \times 2 7×7×2),而YOLOv2使用anchor boxes之后可以预测上千个边界框( 13 × 13 13 \times 13 13×13anchors_num )。所以使用anchor boxes之后,YOLOv2的召回率大大提升,由原来的 81 % 81\% 81%升至 88 % 88\% 88%。 -
Dimension Clusters 维度集群
在Faster R-CNN和SSD中,先验框的维度(长和宽)都是手动设定的,带有一定的主观性。如果选取的先验框维度比较合适,那么模型更容易学习,从而做出更好的预测。因此,YOLOv2采用k-means聚类方法对训练集中的边界框做了聚类分析。因为设置先验框的主要目的是为了使得预测框与ground truth的IOU更好,所以聚类分析时选用box与聚类中心box之间的IOU值作为距离指标:
d ( box , centroid ) = 1 − IOU ( box , centroid ) d(\text { box }, \text { centroid })=1-\operatorname{IOU}(\text { box }, \text { centroid }) d( box , centroid )=1−IOU( box , centroid ) -
New Network: Darknet-19
YOLOv2采用了一个新的基础模型(特征提取器),称为Darknet-19,包括 19 19 19个卷积层和 5 5 5个maxpooling层。Darknet-19与VGG16模型设计原则是一致的,主要采用 3 × 3 3 \times 3 3×3 卷积,采用 2 × 2 2 \times 2 2×2 的maxpooling层之后,特征图维度降低2倍,而同时将特征图的channles增加两倍。与NIN(Network in Network)类似,Darknet-19最终采用global avgpooling做预测,并且在 3 × 3 3 \times 3 3×3 卷积之间使用 1 × 1 1 \times 1 1×1 卷积来压缩特征图channles以降低模型计算量和参数。Darknet-19每个卷积层后面同样使用了batch norm层以加快收敛速度,降低模型过拟合。在ImageNet分类数据集上,Darknet-19的top-1准确度为 72.9 % 72.9\% 72.9%,top-5准确度为 91.2 % 91.2\% 91.2%,但是模型参数相对小一些。使用Darknet-19之后,YOLOv2的mAP值没有显著提升,但是计算量却可以减少约 33 % 33\% 33%。

-
Direct location prediction 直接位置预测
YOLOv2边界框的解码过程修改。约束了边界框的位置预测值使得模型更容易稳定训练,结合聚类分析得到先验框与这种预测方法,YOLOv2的mAP值提升了约 5 % 5\% 5%。
预测边界框中心点相对于对应cell左上角位置的相对偏移值。将网格归一化为 1 × 1 1 \times 1 1×1,坐标控制在每个网格内,同时配合sigmod函数将预测值转换到 0 ∼ 1 0\sim1 0∼1之间的办法,做到每一个Anchor只负责检测周围正负一个单位以内的目标box。
YOLOv2借鉴RPN网络使用anchor boxes来预测边界框相对先验框的offsets。边界框的实际中心位置
(
x
,
y
)
(x, y)
(x,y) ,需要根据预测的坐标偏移值
(
t
x
,
t
y
)
(t_\text x,t_\text y)
(tx,ty) ,先验框的尺度
(
w
a
,
h
a
)
(w_\text a,h_\text a)
(wa,ha) 以及中心坐标
(
x
a
,
y
a
)
(x_\text a,y_\text a)
(xa,ya) (特征图每个位置的中心点)来计算:
x
=
(
t
x
∗
w
a
)
−
x
a
x=(t_\text x * w_\text a) - x_\text a
x=(tx∗wa)−xa
y
=
(
t
y
∗
h
a
)
−
y
a
y=(t_\text y * h_\text a) - y_\text a
y=(ty∗ha)−ya
但是上面的公式是无约束的,预测的边界框很容易向任何方向偏移,如当
t
x
=
1
t_\text x=1
tx=1 时边界框将向右偏移先验框的一个宽度大小,而当
t
x
=
−
1
t_\text x=-1
tx=−1 时边界框将向左偏移先验框的一个宽度大小,因此每个位置预测的边界框可以落在图片任何位置,这导致模型的不稳定性,在训练时需要很长时间来预测出正确的offsets。所以,YOLOv2弃用了这种预测方式,而是沿用YOLOv1的方法,就是预测边界框中心点相对于对应cell左上角位置的相对偏移值,为了将边界框中心点约束在当前cell中,使用sigmoid函数处理偏移值,这样预测的偏移值在
(
0
,
1
)
(0,1)
(0,1)范围内(每个cell的尺度看做
1
1
1)。总结来看,根据边界框预测的4个offsets
t
x
,
t
y
,
t
w
,
t
h
t_\text x,t_\text y,t_\text w,t_\text h
tx,ty,tw,th ,可以按如下公式计算出边界框实际位置和大小:
b
x
=
σ
(
t
x
)
+
c
x
b_\text x = \sigma(t_\text x) + c_\text x
bx=σ(tx)+cx
b
y
=
σ
(
t
y
)
+
c
y
b_\text y = \sigma(t_\text y) + c_\text y
by=σ(ty)+cy
b
w
=
p
w
e
t
w
/
W
b_\text w = p_\text w e^{tw} / W
bw=pwetw/W
b
h
=
p
h
e
t
h
/
H
b_\text h = p_\text h e^{th} / H
bh=pheth/H
如果再将上面的4个值分别乘以图片的宽度和长度(像素点值)就可以得到边界框的最终位置和大小了。这就是YOLOv2边界框的整个解码过程。约束了边界框的位置预测值使得模型更容易稳定训练,结合聚类分析得到先验框与这种预测方法,YOLOv2的mAP值提升了约
5
%
5\%
5%。

- Fine-Grained Features 细粒度特征
YOLOv2的输入图片大小为
416
×
416
416 \times 416
416×416 ,经过5次maxpooling之后得到
13
×
13
13 \times 13
13×13 大小的特征图,并以此特征图采用卷积做预测。
大小的特征图对检测大物体是足够了,但是对于小物体还需要更精细的特征图(Fine-Grained Features)。因此SSD使用了多尺度的特征图来分别检测不同大小的物体,前面更精细的特征图可以用来预测小物体。YOLOv2提出了一种passthrough层来利用更精细的特征图。YOLOv2所利用的Fine-Grained Features是
26
×
26
26\times26
26×26 大小的特征图(最后一个maxpooling层的输入),对于Darknet-19模型来说就是大小为
26
×
26
×
512
26 \times 26 \times 512
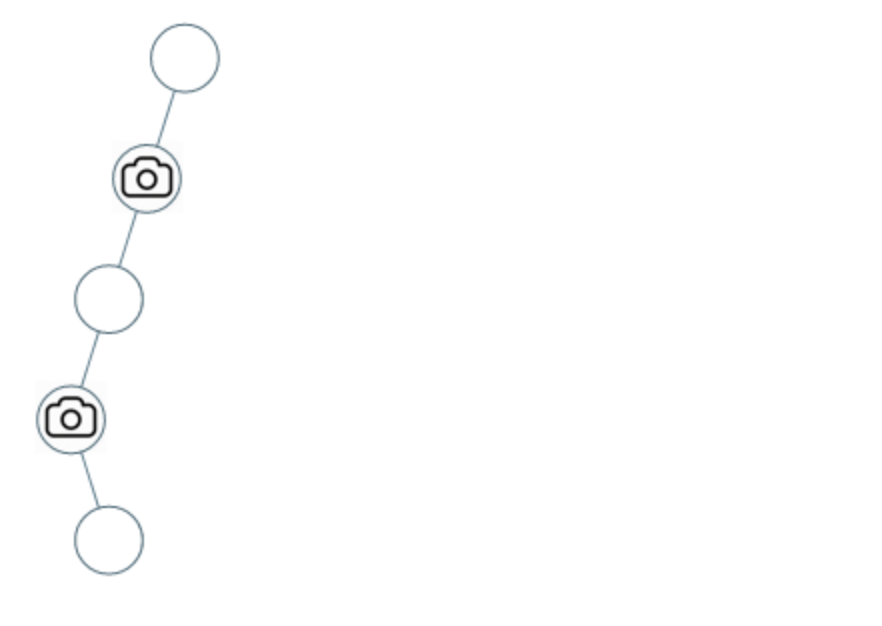
26×26×512 的特征图。passthrough层与ResNet网络的shortcut类似,以前面更高分辨率的特征图为输入,然后将其连接到后面的低分辨率特征图上。前面的特征图维度是后面的特征图的2倍,passthrough层抽取前面层的每个
2
×
2
2 \times 2
2×2 的局部区域,然后将其转化为channel维度,对于
26
×
26
×
512
26 \times 26 \times512
26×26×512 的特征图,经passthrough层处理之后就变成了
13
×
13
×
2048
13 \times 13 \times 2048
13×13×2048 的新特征图(特征图大小降低
4
4
4倍,而channles增加
4
4
4倍,图为一个实例),这样就可以与后面的
13
×
13
×
1024
13 \times 13 \times 1024
13×13×1024 特征图连接在一起形成
13
×
13
×
3072
13 \times 13 \times 3072
13×13×3072 大小的特征图,然后在此特征图基础上卷积做预测。在YOLO的C源码中,passthrough层称为reorg layer。在TensorFlow中,可以使用tf.extract_image_patches或者tf.space_to_depth来实现passthrough层:
out = tf.extract_image_patches(in, [1, stride, stride, 1], [1, stride, stride, 1], [1,1,1,1], padding="VALID")
// or use tf.space_to_depth
out = tf.space_to_depth(in, 2)

另外,作者在后期的实现中借鉴了ResNet网络,不是直接对高分辨特征图处理,而是增加了一个中间卷积层,先采用
64
64
64个
1
×
1
1\times1
1×1 卷积核进行卷积,然后再进行passthrough处理,这样
26
×
26
×
512
26\times26\times512
26×26×512 的特征图得到
13
×
13
×
256
13\times13\times256
13×13×256 的特征图。这算是实现上的一个小细节。使用Fine-Grained Features之后YOLOv2的性能有
1
%
1\%
1%的提升。
- Multi-Scale Training 多尺度训练
由于YOLOv2模型中只有卷积层和池化层,所以YOLOv2的输入可以不限于
416
×
416
416\times416
416×416 大小的图片。为了增强模型的鲁棒性,YOLOv2采用了多尺度输入训练策略,具体来说就是在训练过程中每间隔一定的iterations之后改变模型的输入图片大小。由于YOLOv2的下采样总步长为
32
32
32,输入图片大小选择一系列为
32
32
32倍数的值:
{
320
,
352
,
.
.
.
,
608
}
\{320,352,...,608\}
{320,352,...,608},输入图片最小为
320
×
320
320\times320
320×320 ,此时对应的特征图大小为
10
×
10
10\times10
10×10 (不是奇数了,确实有点尴尬),而输入图片最大为
608
×
608
608\times608
608×608 ,对应的特征图大小为
19
×
19
19\times19
19×19 。在训练过程,每隔
10
10
10个iterations随机选择一种输入图片大小,然后只需要修改对最后检测层的处理就可以重新训练。

采用Multi-Scale Training策略,YOLOv2可以适应不同大小的图片,并且预测出很好的结果。在测试时,YOLOv2可以采用不同大小的图片作为输入,在VOC 2007数据集上的效果如下图所示。可以看到采用较小分辨率时,YOLOv2的mAP值略低,但是速度更快,而采用高分辨输入时,mAP值更高,但是速度略有下降,对于
544
×
544
544\times544
544×544 ,mAP高达
78.6
%
78.6\%
78.6%。注意,这只是测试时输入图片大小不同,而实际上用的是同一个模型(采用Multi-Scale Training训练)。

总结来看,虽然YOLOv2做了很多改进,但是大部分都是借鉴其它论文的一些技巧,如Faster R-CNN的anchor boxes,YOLOv2采用anchor boxes和卷积做预测,这基本上与SSD模型(单尺度特征图的SSD)非常类似了,而且SSD也是借鉴了Faster R-CNN的RPN网络。从某种意义上来说,YOLOv2和SSD这两个one-stage模型与RPN网络本质上无异,只不过RPN不做类别的预测,只是简单地区分物体与背景。在two-stage方法中,RPN起到的作用是给出region proposals,其实就是作出粗糙的检测,所以另外增加了一个stage,即采用R-CNN网络来进一步提升检测的准确度(包括给出类别预测)。而对于one-stage方法,它们想要一步到位,直接采用“RPN”网络作出精确的预测,要因此要在网络设计上做很多的tricks。YOLOv2的一大创新是采用Multi-Scale Training策略,这样同一个模型其实就可以适应多种大小的图片了。
训练
YOLOv2的训练主要包括三个阶段。
- 第一阶段就是先在ImageNet分类数据集上预训练Darknet-19,此时模型输入为 224 × 224 224 \times 224 224×224 ,共训练 160 160 160个epochs。
- 第二阶段将网络的输入调整为 448 × 448 448 \times 448 448×448 ,继续在ImageNet数据集上finetune分类模型,训练 10 10 10个epochs,此时分类模型的top-1准确度为 76.5 % 76.5\% 76.5%,而top-5准确度为 93.3 % 93.3\% 93.3%。
- 第三个阶段就是修改Darknet-19分类模型为检测模型,并在检测数据集上继续finetune网络。网络修改包括(网路结构可视化):移除最后一个卷积层、global avgpooling层以及softmax层,并且新增了三个
3
×
3
×
2014
3 \times 3 \times 2014
3×3×2014卷积层,同时增加了一个passthrough层,最后使用
1
×
1
1 \times1
1×1 卷积层输出预测结果,输出的channels数为:
n
u
m
_
a
n
c
h
o
r
s
×
(
5
+
n
u
m
_
c
l
a
s
s
e
s
)
{ num\_anchors \times (5 + num\_classes) }
num_anchors×(5+num_classes),和训练采用的数据集有关系。
由于anchors数为5,对于VOC数据集输出的channels数就是 125 125 125,而对于COCO数据集则为 425 425 425。这里以VOC数据集为例,最终的预测矩阵为 T { T } T(shape为 ( b a t c h _ s i z e , 13 , 13 , 125 ) (batch\_size,13,13,125) (batch_size,13,13,125)),可以先将其reshape为 ( b a t c h _ s i z e , 13 , 13 , 5 , 25 ) (batch\_size,13,13,5,25) (batch_size,13,13,5,25) ,其中 T [ : , : , : , : , 0 : 4 ] T[ : , : , : , : , 0 : 4] T[:,:,:,:,0:4] 为边界框的位置和大小 ( t x , t y , t w , t h ) (t_\text x, t_\text y, t_\text w, t_\text h) (tx,ty,tw,th) , T [ : , : , : , : , 4 ] T[:, :, :, :,4] T[:,:,:,:,4] 为边界框的置信度,而 T [ : , : , : , : , 5 : ] T[: , : , : , : , 5 : ] T[:,:,:,:,5:]为类别预测值。