文章目录
- 1、需求痛点
- 2、完整代码⭐
- 3、代码分析
- 3.1、需要改动的地方
- 3.2、OpenCV库的使用
- 3.3、多线程技术
- 4、执行效率
- 5、效果展示⭐
- 6、注意事项🔺
- 7、总结
🍃作者介绍:双非本科大三网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅长web应用开发、数据结构和算法,初步涉猎人工智能和前端开发。
🦅个人主页:@逐梦苍穹
📕所属专栏:项目
🌻您的一键三连,是我创作的最大动力🌹
1、需求痛点
有时候看见一个视频,想要截图里面的素材来自己用,但是此时又记不得自己需要的内容大概在视频的哪个地方,那么就得从头看视频,不断暂停、播放视频,循环往复 ,以寻找需要的内容进行截图。
那么,本文就带你用 python 实现一个提取视频帧的程序,把视频帧提取成图片;
然后你只需要在键盘上利用 “->” 键,就可以轻松快速的找到想要的素材内容。
那么话不多说,进入正题!
2、完整代码⭐
# -*- coding: utf-8 -*-
# @Author:︶ㄣ释然
# @Time: 2024/7/31 1:19
import cv2 # 导入OpenCV库,用于视频处理
import os # 导入os库,用于文件和目录操作
import concurrent.futures # 导入并发库,用于多线程处理
import time # 导入时间库,用于计算时间
# 定义保存帧的函数
def save_frame(frame, frame_filename):
cv2.imwrite(frame_filename, frame) # 使用OpenCV保存帧到文件
# 定义提取视频帧的函数
def extract_frames(video_path, output_folder, frame_interval, max_threads):
cap = cv2.VideoCapture(video_path) # 打开视频文件
frame_count = 0 # 初始化帧计数器
futures = [] # 初始化futures列表,用于存储线程任务
start_time = time.time() # 记录开始时间
# 使用ThreadPoolExecutor创建一个线程池,最大线程数为max_threads
with concurrent.futures.ThreadPoolExecutor(max_workers=max_threads) as executor:
while cap.isOpened(): # 当视频文件打开时
ret, frame = cap.read() # 读取一帧
if not ret: # 如果读取失败,跳出循环
break
if frame_count % frame_interval == 0: # 每隔frame_interval帧处理一次
seconds = frame_count // frame_interval # 计算当前帧对应的秒数
frame_filename = os.path.join(output_folder, f'frame_{seconds:04d}.jpg') # 构建帧文件名
futures.append(executor.submit(save_frame, frame, frame_filename)) # 提交保存帧的任务到线程池
frame_count += 1 # 增加帧计数器
cap.release() # 释放视频文件
for future in concurrent.futures.as_completed(futures): # 等待所有线程完成
future.result() # 获取线程结果
end_time = time.time() # 记录结束时间
elapsed_time = end_time - start_time # 计算执行时间
print(f'提取完成,共提取了 {frame_count // frame_interval} 帧') # 输出提取的帧数
print(f'程序执行时间: {elapsed_time:.2f} 秒') # 输出程序执行时间
# 创建文件夹保存帧
output_folder = 'video_frames'
os.makedirs(output_folder, exist_ok=True) # 如果文件夹不存在,则创建
# 打开视频文件
video_path = '1.mp4'
# 获取视频帧率
cap = cv2.VideoCapture(video_path)
fps = cap.get(cv2.CAP_PROP_FPS) # 获取视频的帧率
cap.release() # 释放视频文件
frame_interval = int(1 * fps) # 每秒提取一帧
# 用户指定的线程数
max_threads = 8
# 提取视频帧
extract_frames(video_path, output_folder, frame_interval, max_threads) # 调用提取帧的函数
3、代码分析
3.1、需要改动的地方
首先,保存图片的文件夹名称,你可以修改:

然后,你需要把视频下载下来,填写视频路径:

接着,本程序是多线程的,你需要指定你所需要的线程数量:

最后,该程序默认是一秒提取一帧图片,你可以修改这个数字:

“
1 * fps"即每秒提取一帧图片,同理,如果想要十秒提取一张,则是"10 * fps”。
3.2、OpenCV库的使用
OpenCV是一个强大的计算机视觉库,支持视频和图像处理。
在本程序中,OpenCV被用来读取视频文件和保存帧图像。
cv2.VideoCapture用于打开视频文件,cv2.imwrite用于将帧图像保存到文件。
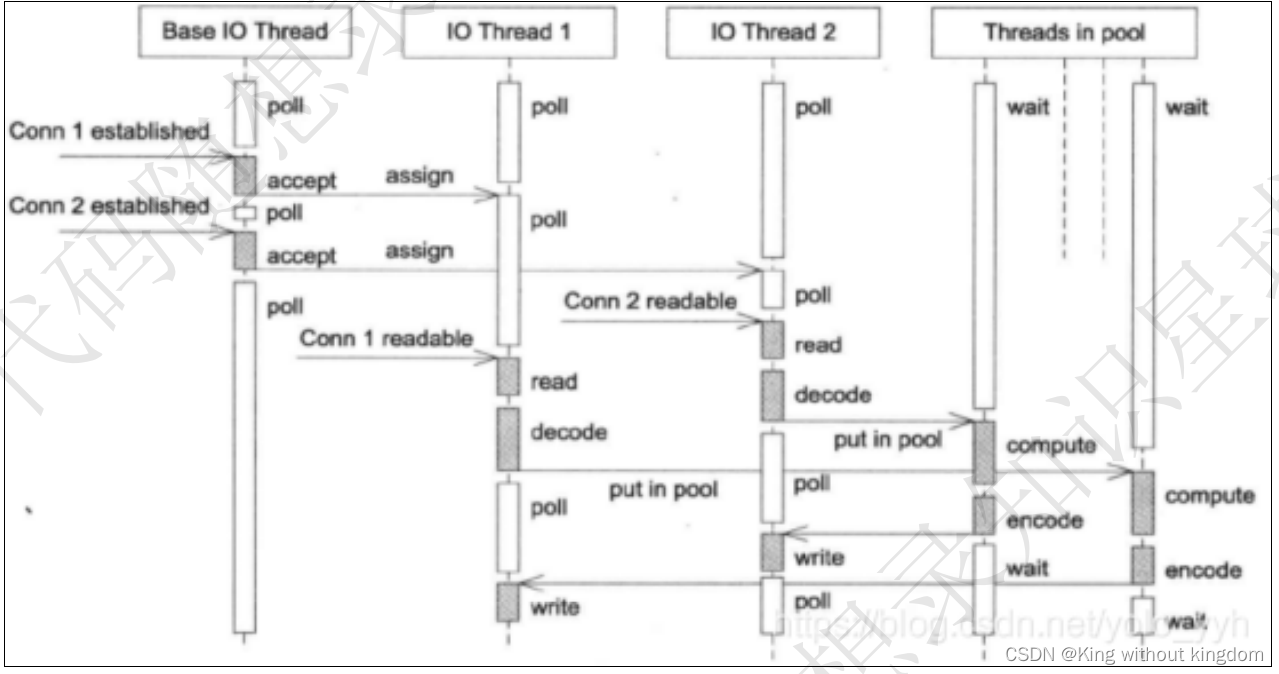
3.3、多线程技术
为了提高帧提取和保存的效率,程序使用了Python的concurrent.futures库中的ThreadPoolExecutor进行多线程处理。
ThreadPoolExecutor允许我们轻松地管理和调度多个线程,特别适合I/O密集型任务。
该程序实现了从视频中每秒提取一帧并多线程保存到文件夹的功能,极大地提升了处理效率。
多线程的使用有效地利用了计算资源,减少了帧提取和保存过程中的等待时间。
4、执行效率
我的CPU型号:11th Gen Intel® Core™ i5-1135G7 @ 2.40GHz (8 CPUs), ~2.4GHz
经过我的测试:提取13分钟的视频,每秒一帧共提取出800张图,8线程,用时是 2分钟:

5、效果展示⭐
运行程序之后,会生成一个文件夹,里面是保存的图片,效果如下图:

清晰度都不错,放几张给大家看一下:


此时你想要哪个素材,就不用一直在视频里面不断重复暂停、播放的过程了。
6、注意事项🔺
用了别人的素材,如果需要发成文章,比如像我这样发一篇博客的话,最好艾特原作者或者附上引用素材的链接。
我这里用到的演示视频,用于提取素材图片,来源于:
https://www.bilibili.com/video/BV1fY411H7g8?t=245.4
7、总结
通过对该代码的分析,我们可以看到利用Python的多线程技术可以显著提高视频处理任务的效率。
OpenCV库提供了强大的视频处理功能,而concurrent.futures库则简化了多线程的实现。
对于需要处理大量视频数据的应用场景,这种方法无疑是高效且实用的。