一、项目介绍
(1)为什么要做这样一个项目?
(2)介绍一下你的项目
这个项⽬是我在学习计算机⽹络和Linux socket编程过程中独⽴开发的轻量级Web服务器,服务器的⽹络模型是主从reactor加线程池的模式,IO处理使⽤了⾮阻塞IO和IO多路复⽤技术,具备处理多个客户端的http请求和ftp请求,以及对外提供轻量级储存的能⼒。这个项⽬从4⽉份开始做,到7⽉份完成了项⽬的整体功能。
项⽬中的⼯作可以分为两部分,⼀部分是服务器⽹络框架、⽇志系统、存储引擎等⼀些基本系统的搭建,另⼀部分是为了提⾼服务器性能所做的⼀些优化,⽐如缓存机制、内存池等⼀些额外系统的搭建。最后还对系统中的部分功能进⾏了功能和压⼒测试。对于存储引擎的压⼒测试,在本地测试下,存储引擎读操作的QPS可以达到36万,写操作的QPS可以达到30万。对于⽹络框架的测试,使⽤webbench创建1000个进程对服务器进⾏60s并发请求,测试结果表明,对于短连接的QPS为1.8万,对于⻓连接的QPS为5.2万。
在开发阶段对于⼀些功能的不同实现⽅法,我先思考⼀下各个⽅法的应⽤场景和效率,再进⾏选择,通过这个项⽬,我学习了两种Linux下的⾼性能⽹络模式,熟悉了Linux环境下的编程,并在后期优化的过程中了解了⼀些服务端性能调优的⽅法。
二、线程池相关
(1)手写线程池
(2)线程的同步机制有哪些?
(3)线程池中的工作线程是一直等待吗?
(4)你的线程池工作线程处理完一个任务后的状态是什么?
这⾥要分两种情况考虑
(1)当处理完任务后如果请求队列为空时,则这个线程重新回到阻塞等待的状态
(2)当处理完任务后如果请求队列不为空时,那么这个线程将处于与其他线程竞争资源的状态,谁获得锁谁就获得了处理事件的资格。
(5)如果1000个客户端同时进行访问请求,线程数不多,怎么能及时响应处理每一个呢?
⾸先这种问法就相当于问服务器如何处理⾼并发的问题。
⾸先我项⽬中使⽤了I/O多路复⽤技术,每个线程中管理⼀定数量的连接,只有线程池中的连接有请求,epoll就会返回请求的连接列表,管理该连接的线程获取活动列表,然后依次处理各个连接的请求。如果该线程没有任务,就会等待主reactor分配任务。这样就能达到服务器⾼并发的要求,同⼀时刻,每个线程都在处理⾃⼰所管理连接的请求。
(6)如果一个客户请求需要占用线程很久的时间,会不会影响接下来的客户请求呢?有什么好的策略呢?
影响分析
会影响这个⼤请求的所在线程的所有请求,因为每个eventLoop都是依次处理它通过epoll获得的活动事件,也就是活动连接。如果该eventloop处理的连接占⽤时间过⻓的话,该线程后续的请求只能在请求队列中等待被处理,从⽽影响接下来的客户请求。
应对策略
- 主 reactor 的⻆度:可以记录⼀下每个从reactor的阻塞连接数,主reactor根据每个reactor的当前负载来分发请求,达到负载均衡的效果。
- 从 reactor 的⻆度:
超时时间:为每个连接分配⼀个时间⽚,类似于操作系统的进程调度,当当前连接的时间⽚⽤完以后,将其重新加⼊请求队列,响应其他连接的请求,进⼀步来说,还可以为每个连接设置⼀个优先级,这样可以优先响应重要的连接,有点像 HTTP/2 的优先级。
关闭时间:为了避免部分连接⻓时间占⽤服务器资源,可以给每个连接设置⼀个最⼤响应时间,当⼀个连接的最⼤响应时间⽤完后,服务器可以主动将这个连接断开,让其重新连接。
三、并发模型相关
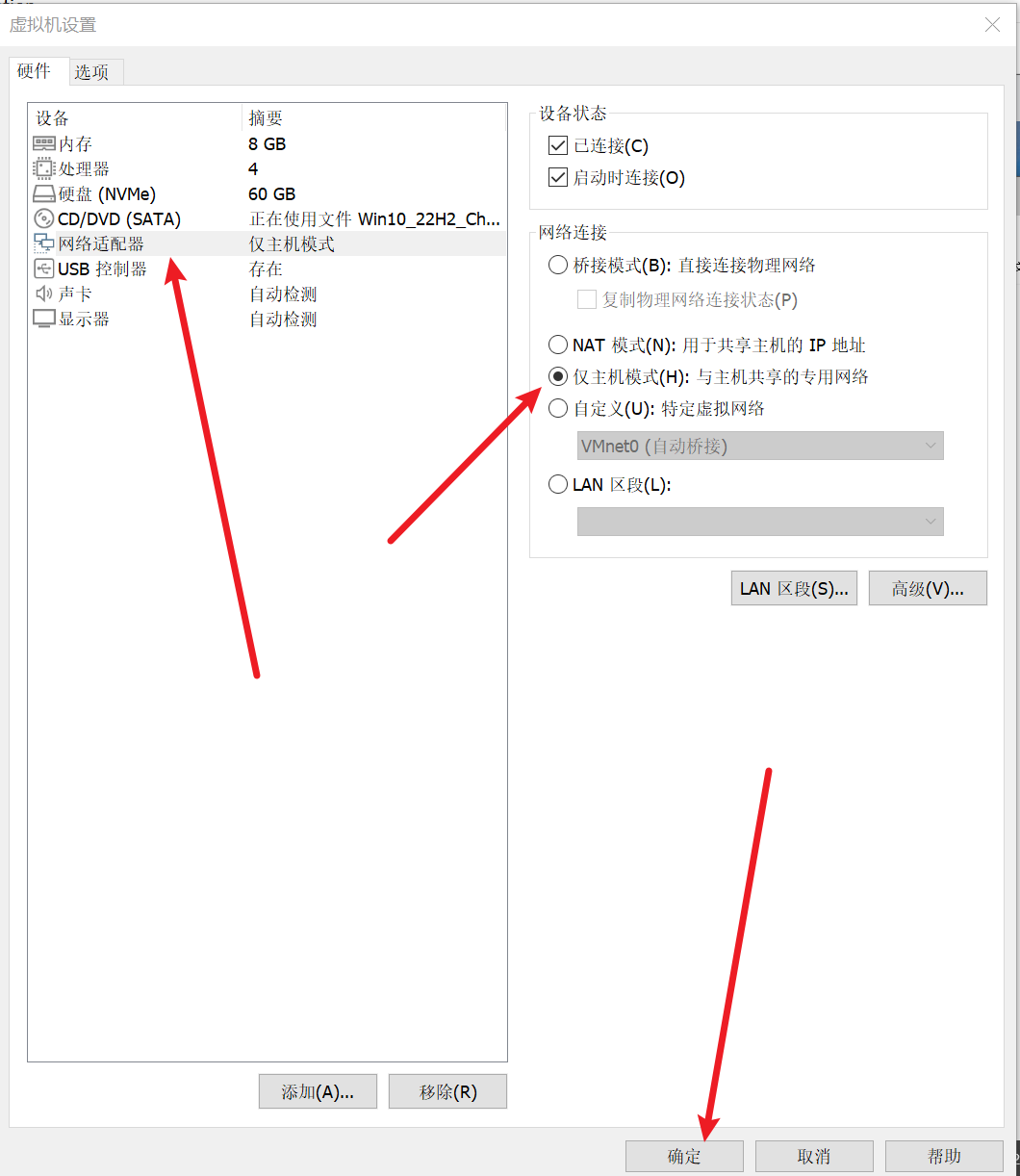
(1)简单说一下服务器使用的并发模型
(2)reactor\proactor\主从reactor模型的区别
- Reactor 是⾮阻塞同步⽹络模式,感知的是就绪可读写事件。在每次感知到有事件发⽣(⽐如可读就绪事件)后,就需要应⽤进程主动调⽤ read ⽅法来完成数据的读取,也就是要应⽤进程主动将 socket 接收缓存中的数据读到应⽤进程内存中,这个过程是同步的,读取完数据后应⽤进程才能处理数据。
- Proactor 是异步⽹络模式, 感知的是已完成的读写事件。在发起异步读写请求时,需要传⼊数据缓冲区的地址(⽤来存放结果数据)等信息,这样系统内核才可以⾃动帮我们把数据的读写⼯作完成,这⾥的读写⼯作全程由操作系统来做,并不需要像 Reactor 那样还需要应⽤进程主动发起 read/write 来读写数据,操作系统完成读写⼯作后,就会通知应⽤进程直接处理数据。
Proactor这么好⽤,那你为什么不⽤?
在 Linux 下的异步 I/O 是不完善的, aio 系列函数是由 POSIX 定义的异步操作接⼝,不是真正的操作系统级别⽀持的,⽽是在⽤户空间模拟出来的异步,并且仅仅⽀持基于本地⽂件的 aio 异步操作,⽹络编程中的 socket 是不⽀持的,也有考虑过使⽤模拟的proactor模式来开发,但是这样需要浪费⼀个线程专⻔负责 IO 的处理。
⽽ Windows ⾥实现了⼀套完整的⽀持 socket 的异步编程接⼝,这套接⼝就是 IOCP ,是由操作系统级别实现的异步 I/O,真正意义上异步 I/O,因此在 Windows ⾥实现⾼性能⽹络程序可以使⽤效率更⾼的 Proactor ⽅案。
reactor模式中,各个模式的区别?
Reactor模型是⼀个针对同步I/O的⽹络模型,主要是使⽤⼀个reactor负责监听和分配事件,将I/O事件分派给对应的Handler。新的事件包含连接建⽴就绪、读就绪、写就绪等。reactor模型中⼜可以细分为单reactor单线程、单reactor多线程、以及主从reactor模式。
- 单reactor单线程模型就是使⽤ I/O 多路复⽤技术,当其获取到活动的事件列表时,就在reactor中进⾏读取请求、业务处理、返回响应,这样的好处是整个模型都使⽤⼀个线程,不存在资源的争夺问题。但是如果⼀个事件的业务处理太过耗时,会导致后续所有的事件都得不到处理。
- 单reactor多线程就是⽤于解决这个问题,这个模型中reactor中只负责数据的接收和发送,reactor将业务处理分给线程池中的线程进⾏处理,完成后将数据返回给reactor进⾏发送,避免了在reactor进⾏业务处理,但是 IO 操作都在reactor中进⾏,容易存在性能问题。⽽且因为是多线程,线程池中每个线程完成业务后都需要将结果传递给reactor进⾏发送,还会涉及到共享数据的互斥和保护机制。
- 主从reactor就是将reactor分为主reactor和从reactor,主reactor中只负责连接的建⽴和分配,读取请求、业务处理、返回响应等耗时的操作均在从reactor中处理,能够有效地应对⾼并发的场合。
subreactor负责读写数据,由线程池进⾏业务处理。
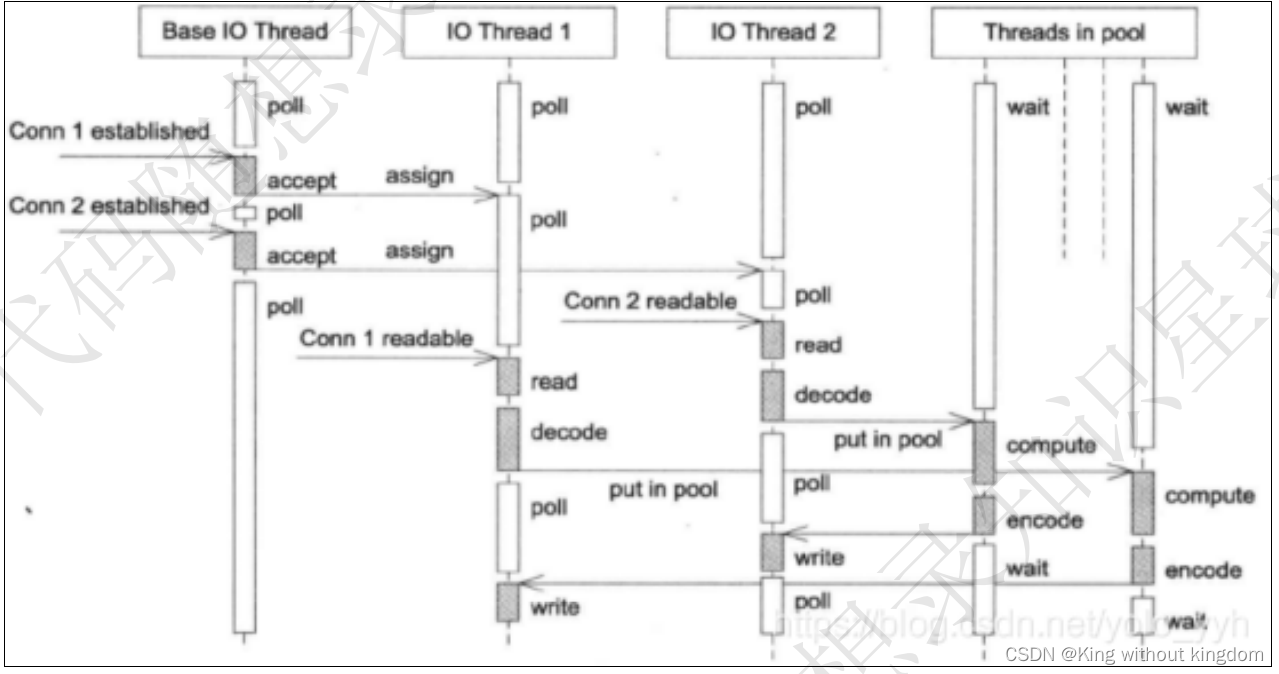
(3)你用了epoll,说一下为什么用epoll,还有其他复用方式吗?区别是什么
⽂件描述符集合的存储位置
对于 select 和 poll 来说,所有⽂件描述符都是在⽤户态被加⼊其⽂件描述符集合的,每次调⽤都需要将整个集合拷⻉到内核态;epoll 则将整个⽂件描述符集合维护在内核态,每次添加⽂件描述符的时候都需要执⾏⼀个系统调⽤。系统调⽤的开销是很⼤的,⽽且在有很多短期活跃连接的情况下,由于这些⼤量的系统调⽤开销,epoll 可能会慢于 select 和 poll。
⽂件描述符集合的表示⽅法
select 使⽤线性表描述⽂件描述符集合,⽂件描述符有上限;poll使⽤链表来描述;epoll底层通过红⿊树来描述,并且维护⼀个就绪列表,将事件表中已经就绪的事件添加到这⾥,在使epoll_wait调⽤时,仅观察这个list中有没有数据即可。
遍历⽅式
select 和 poll 的最⼤开销来⾃内核判断是否有⽂件描述符就绪这⼀过程:每次执⾏ select 或 poll 调⽤时,它们会采⽤遍历的⽅式,遍历整个⽂件描述符集合去判断各个⽂件描述符是否有活动;epoll 则不需要去以这种⽅式检查,当有活动产⽣时,会⾃动触发 epoll 回调函数通知epoll⽂件描述符,然后内核将这些就绪的⽂件描述符放到就绪列表中等待epoll_wait调⽤后被处理。
触发模式
select和poll都只能⼯作在相对低效的LT模式下,⽽epoll同时⽀持LT和ET模式。
适⽤场景
当监测的fd数量较⼩,且各个fd都很活跃的情况下,建议使⽤select和poll;当监听的fd数量较多,且单位时间仅部分fd活跃的情况下,使⽤epoll会明显提升性能。
(4)IO多路复⽤
1)说⼀下什么是ET,什么是LT,有什么区别?
- LT:⽔平触发模式,只要内核缓冲区有数据就⼀直通知,只要socket处于可读状态或可写状态,就会⼀直返回sockfd;是默认的⼯作模式,⽀持阻塞IO和⾮阻塞IO
- ET:边沿触发模式,只有状态发⽣变化才通知并且这个状态只会通知⼀次,只有当socket由不可写到可写或由不可读到可读,才会返回其sockfd;只⽀持⾮阻塞IO
2)LT什么时候会触发?ET呢?
LT模式 - 对于读操作
只要内核读缓冲区不为空,LT模式返回读就绪。 - 对于写操作
只要内核写缓冲区还不满,LT模式会返回写就绪。
ET模式 - 对于读操作
当缓冲区由不可读变为可读的时候,即缓冲区由空变为不空的时候。
当有新数据到达时,即缓冲区中的待读数据变多的时候。
当缓冲区有数据可读,且应⽤进程对相应的描述符进⾏EPOLL_CTL_MOD 修改EPOLLIN事件时。 - 对于写操作
当缓冲区由不可写变为可写时。
当有旧数据被发送⾛,即缓冲区中的内容变少的时候。
当缓冲区有空间可写,且应⽤进程对相应的描述符进⾏EPOLL_CTL_MOD 修改EPOLLOUT事件时。
3)为什么ET模式不可以⽂件描述符阻塞,⽽LT模式可以呢?
因为ET模式是当fd有可读事件时,epoll_wait()只会通知⼀次,如果没有⼀次把数据读完,那么要到下⼀次fd有可读事件epoll才会通知。⽽且在ET模式下,在触发可读事件后,需要循环读取信息,直到把数据读完。如果把这个fd设置成阻塞,数据读完以后read()就阻塞在那了。⽆法进⾏后续请求的处理。
LT模式不需要每次读完数据,只要有数据可读,epoll_wait()就会⼀直通知。所以 LT模式下去读的话,内核缓冲区肯定是有数据可以读的,不会造成没有数据读⽽阻塞的情况。
四、http报文解析相关
(1)为什么用状态机
(2)状态机转移图画一下
(3)https协议为什么安全
(4)https的ssl连接过程
(5)GET和POST的区别
五、数据库登录注册相关
(1)登录说一下?
(2)你这个保存状态了吗?如果要保存,你会怎么做?(cookie和session)
(3)登录中的用户名和密码你是load到本地,然后使用map匹配的,如果有10亿数据,即使load到本地后hash,也是很耗时的,你要怎么优化?
(4)用的mysql啊,redis了解吗?用过吗?
六、定时器相关
(1)为什么要用定时器?
(2)说一下定时器的工作原理
(3)双向链表啊,删除和添加的时间复杂度说一下?还可以优化吗?
(4)最小堆优化?说一下时间复杂度和工作原理
七、日志相关
(1)说下你的日志系统的运行机制?
(2)为什么要异步?和同步的区别是什么?
(3)现在你要监控一台服务器的状态,输出监控日志,请问如何将该日志分发到不同的机器上?(消息队列)
八、压测相关
(1)服务器并发量测试过吗?怎么测试的?
(2)webbench是什么?介绍一下原理
(3)测试的时候有没有遇到问题?
九、综合能力
(1)你的项目解决了哪些其他同类项目没有解决的问题?
项⽬中我主要的⼯作可以分为两部分:
-
⼀部分是服务器⽹络框架、⽇志系统、存储引擎等⼀些基本系统的搭建,这部分的难点主要就是技术的理解和选型,以及将⼀些开源的框架调整后应⽤到我的项⽬中去。
-
另⼀部分是为了提⾼服务器性能所做的⼀些优化,⽐如缓存机制、内存池等⼀些额外系统的搭建。这部分的难点主要是找出服务器的性能瓶颈,然后结合⾃⼰的想法去突破这个瓶颈,提⾼服务器的性能
-
⼀⽅⾯是对不同的技术理解不够深刻,难以选出最合适的技术框架。这部分的话我主要是反复阅读作者在GitHub提供的⼀些技术⽂档,同时也去搜索⼀些技术对⽐的⽂章去看,如果没有任何相关的资料我会尝试去联系作者。
-
另⼀⽅⾯是编程期间遇到的困难,在代码编写的过程中由于⼯程能⼒不⾜,程序总会出现⼀些bug。这部分的话我⾸先是通过⽇志去定位bug,然后推断bug出现的原因并尝试修复,如果是⾃⼰⽬前⽔平⽆法修复的bug,我会先到⽹上去查找有没有同类型问题的解决⽅法,然后向同学或者直接到StackOverflow等⼀些国外知名论坛上求助。
(2)说一下前端发送请求后,服务器处理的过程,中间涉及哪些协议?
(3)项⽬中⽤到哪些设计模式?
单例模式:在线程池、内存池中都有使⽤到。
单例模式可以分为懒汉式和饿汉式,两者之间的区别在于创建实例的时间不同:
懒汉式:指系统运⾏中,实例并不存在,只有当需要使⽤该实例时,才会去创建并使⽤实例。(这种⽅式要考虑线程安全)
饿汉式:指系统⼀运⾏,就初始化创建实例,当需要时,直接调⽤即可。(本身就线程安全,没有多线程的问题)
(4)这个web服务器是你⾃⼰申请的域名吗
我没有申请域名,但是阿⾥云服务器上⾃带⼀个公⽹ip,可以直接通过公⽹ip来访问服务器。但是本地测试的话,我⼀般使⽤本地回环ip,127.0.0.1来进⾏访问。能 ping 通 127.0.0.1 说明本机的⽹卡和IP协议安装都没有问题。
(5)你是如何对项⽬进⾏测试的?
对项⽬的测试分为两部分:基本功能模块的测试和扩展功能模块的测试。
【基本功能测试】
- ⽇志系统
写⼊⽇志类型、等级
多个线程同时写⼊的响应
短期⼤量⽇志进⾏写⼊ - ⽹络框架
正确接收 client 连接和分发
正确感知 client 连接的读写事件
正确对 client 连接进⾏读写
⾼并发、多请求(webbench) - 存储引擎
正确写⼊和读取
定时落盘(写⼊⽂件和定时写⼊)
多个线程同时读取和写⼊
单个线程读取和写⼊⼤量数据
【扩展功能测试】 - 线程池
能否将任务放⼊任务队列,任务是否能够正确执⾏多个线程同时往任务队列放⼊任务 - 内存池
能否正确分配内存(空对象、⼤内存、⼩内存),调⽤对象的构造函数和析构函数多个线程同时申请内存 - 缓存机制
能否成功命中缓存
多个线程读取缓存