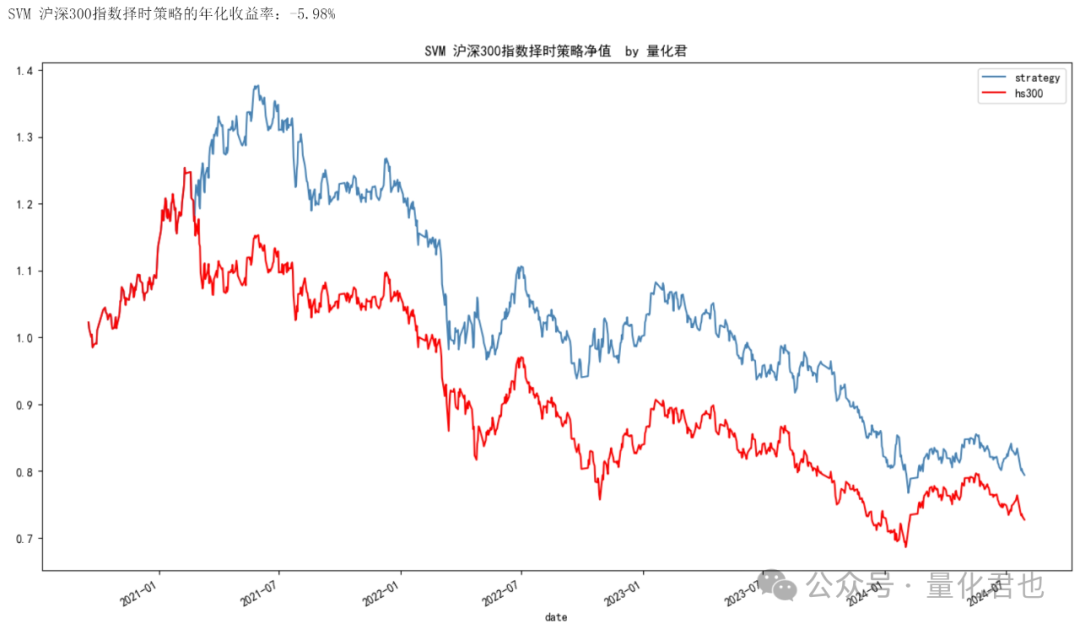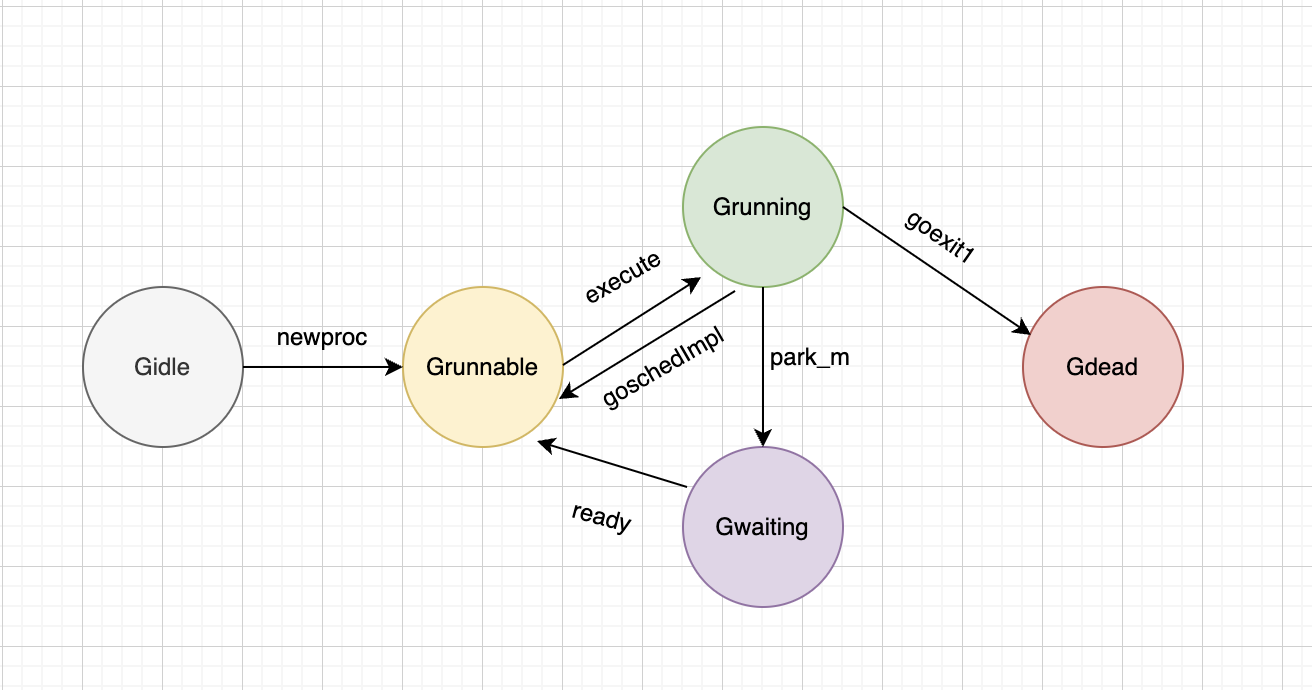
Gidle -> Grunnable
newproc获取新的goroutine,并放置到P运行队列中
这也是go关键字之后实际编译调用的方法
func newproc(fn *funcval) {
// 获取当前正在运行中的goroutine
gp := getg()
// 获取调用者的程序计数器地址,用于调试和跟踪
pc := getcallerpc()
systemstack(func() {
// 创建一个新的 goroutine 并返回新创建的 goroutine 结构 newg
newg := newproc1(fn, gp, pc)
// 获取当前P,并将新创建的goroutine放到P的运行队列中
pp := getg().m.p.ptr()
runqput(pp, newg, true)
// 如果主 goroutine 已经启动(mainStarted 为 true),则调用 wakep() 唤醒或启动一个处理器以执行运行队列中的 goroutine
if mainStarted {
wakep()
}
})
}
newproc1用于获取新的goroutine
// Create a new g in state _Grunnable, starting at fn. callerpc is the
// address of the go statement that created this. The caller is responsible
// for adding the new g to the scheduler.
func newproc1(fn *funcval, callergp *g, callerpc uintptr) *g {
if fn == nil {
fatal("go of nil func value")
}
mp := acquirem() // disable preemption because we hold M and P in local vars.
pp := mp.p.ptr()
// 首先从P的gfree获取回收的g,如果没有,那么再从全局调度器sched中gfree窃取给P,再不然就只能调用malg()新建g
newg := gfget(pp)
if newg == nil {
newg = malg(stackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}
if newg.stack.hi == 0 {
throw("newproc1: newg missing stack")
}
if readgstatus(newg) != _Gdead {
throw("newproc1: new g is not Gdead")
}
// 计算和分配堆栈指针
totalSize := uintptr(4*goarch.PtrSize + sys.MinFrameSize) // extra space in case of reads slightly beyond frame
totalSize = alignUp(totalSize, sys.StackAlign)
sp := newg.stack.hi - totalSize
if usesLR {
// caller's LR
*(*uintptr)(unsafe.Pointer(sp)) = 0
prepGoExitFrame(sp)
}
if GOARCH == "arm64" {
// caller's FP
*(*uintptr)(unsafe.Pointer(sp - goarch.PtrSize)) = 0
}
// 初始化调用帧
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
newg.sched.sp = sp
newg.stktopsp = sp
newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
// 设置新G元数据
newg.parentGoid = callergp.goid
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp)
newg.startpc = fn.fn
if isSystemGoroutine(newg, false) {
sched.ngsys.Add(1)
} else {
// Only user goroutines inherit pprof labels.
if mp.curg != nil {
newg.labels = mp.curg.labels
}
if goroutineProfile.active {
// A concurrent goroutine profile is running. It should include
// exactly the set of goroutines that were alive when the goroutine
// profiler first stopped the world. That does not include newg, so
// mark it as not needing a profile before transitioning it from
// _Gdead.
newg.goroutineProfiled.Store(goroutineProfileSatisfied)
}
}
// Track initial transition?
newg.trackingSeq = uint8(cheaprand())
if newg.trackingSeq%gTrackingPeriod == 0 {
newg.tracking = true
}
gcController.addScannableStack(pp, int64(newg.stack.hi-newg.stack.lo))
// Get a goid and switch to runnable. Make all this atomic to the tracer.
// 分配gid,并更新状态为_Grunnable
trace := traceAcquire()
casgstatus(newg, _Gdead, _Grunnable)
if pp.goidcache == pp.goidcacheend {
// Sched.goidgen is the last allocated id,
// this batch must be [sched.goidgen+1, sched.goidgen+GoidCacheBatch].
// At startup sched.goidgen=0, so main goroutine receives goid=1.
pp.goidcache = sched.goidgen.Add(_GoidCacheBatch)
pp.goidcache -= _GoidCacheBatch - 1
pp.goidcacheend = pp.goidcache + _GoidCacheBatch
}
newg.goid = pp.goidcache
pp.goidcache++
newg.trace.reset()
if trace.ok() {
trace.GoCreate(newg, newg.startpc)
traceRelease(trace)
}
// Set up race context.
if raceenabled {
newg.racectx = racegostart(callerpc)
newg.raceignore = 0
if newg.labels != nil {
// See note in proflabel.go on labelSync's role in synchronizing
// with the reads in the signal handler.
racereleasemergeg(newg, unsafe.Pointer(&labelSync))
}
}
releasem(mp)
return newg
}
malg 创建新goroutine
主要就是分配了goroutine栈空间
// Allocate a new g, with a stack big enough for stacksize bytes.
func malg(stacksize int32) *g {
newg := new(g)
if stacksize >= 0 {
stacksize = round2(stackSystem + stacksize)
systemstack(func() {
newg.stack = stackalloc(uint32(stacksize))
})
newg.stackguard0 = newg.stack.lo + stackGuard
newg.stackguard1 = ^uintptr(0)
// Clear the bottom word of the stack. We record g
// there on gsignal stack during VDSO on ARM and ARM64.
*(*uintptr)(unsafe.Pointer(newg.stack.lo)) = 0
}
return newg
}
runqput g置P中
先尝试放高优先的runnext槽中,然后放P本地队列,实在不行就放全局队列
// runqput tries to put g on the local runnable queue.
// If next is false, runqput adds g to the tail of the runnable queue.
// If next is true, runqput puts g in the pp.runnext slot.
// If the run queue is full, runnext puts g on the global queue.
// Executed only by the owner P.
func runqput(pp *p, gp *g, next bool) {
if randomizeScheduler && next && randn(2) == 0 {
next = false
}
// 如果next为真,则尝试将gp发到pp.runnext中,如果有正在操作的,再进行尝试
if next {
retryNext:
oldnext := pp.runnext
if !pp.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) {
goto retryNext
}
if oldnext == 0 {
return
}
// Kick the old runnext out to the regular run queue.
// 如果已经有goroutine,则踢出并放入常规运行队列
gp = oldnext.ptr()
}
// 加入常规运行队列
retry:
// 加载运行队列的头指针和尾指针
h := atomic.LoadAcq(&pp.runqhead) // load-acquire, synchronize with consumers
t := pp.runqtail
// 如果队列未满,则将gp直接放入队列中
if t-h < uint32(len(pp.runq)) {
pp.runq[t%uint32(len(pp.runq))].set(gp)
atomic.StoreRel(&pp.runqtail, t+1) // store-release, makes the item available for consumption
return
}
// 如果队列已满,则尝试慢策略
if runqputslow(pp, gp, h, t) {
return
}
// the queue is not full, now the put above must succeed
goto retry
}
runqputslow将一次性将本地队列中的多个g放入到全局队列中
// Put g and a batch of work from local runnable queue on global queue.
// Executed only by the owner P.
func runqputslow(pp *p, gp *g, h, t uint32) bool {
var batch [len(pp.runq)/2 + 1]*g
// First, grab a batch from local queue.
// 先从本地队列中抓取一批g
n := t - h
n = n / 2
if n != uint32(len(pp.runq)/2) {
throw("runqputslow: queue is not full")
}
for i := uint32(0); i < n; i++ {
batch[i] = pp.runq[(h+i)%uint32(len(pp.runq))].ptr()
}
// 如果cas失败,说明已经有其它工作线程从_p_的本地运行队列偷走了一些goroutine,所以直接返回
if !atomic.CasRel(&pp.runqhead, h, h+n) { // cas-release, commits consume
return false
}
batch[n] = gp
if randomizeScheduler {
for i := uint32(1); i <= n; i++ {
j := cheaprandn(i + 1)
batch[i], batch[j] = batch[j], batch[i]
}
}
// 将需要放入全局运行队列的g连起来,减少后面对全局链表的锁住时间,从而降低锁冲突
// Link the goroutines.
for i := uint32(0); i < n; i++ {
batch[i].schedlink.set(batch[i+1])
}
var q gQueue
q.head.set(batch[0])
q.tail.set(batch[n])
// Now put the batch on global queue.
// 将链表放入全局队列中
lock(&sched.lock)
globrunqputbatch(&q, int32(n+1))
unlock(&sched.lock)
return true
}
Grunnable -> Gruning
将指定的goroutine绑定到当前M上,其状态设置为运行,然后运行实际代码
func execute(gp *g, inheritTime bool) {
// 获取当前正在运行的M
mp := getg().m
// 如果goroutine是活跃的,那么尝试记录当前goroutine的堆栈信息
if goroutineProfile.active {
tryRecordGoroutineProfile(gp, osyield)
}
// goroutine与M相互绑定,并更新goroutine为运行态
mp.curg = gp
gp.m = mp
casgstatus(gp, _Grunnable, _Grunning)
// 初始化goroutine其他信息
gp.waitsince = 0
gp.preempt = false
gp.stackguard0 = gp.stack.lo + stackGuard
if !inheritTime {
mp.p.ptr().schedtick++
}
// Check whether the profiler needs to be turned on or off.
hz := sched.profilehz
if mp.profilehz != hz {
setThreadCPUProfiler(hz)
}
trace := traceAcquire()
if trace.ok() {
// GoSysExit has to happen when we have a P, but before GoStart.
// So we emit it here.
if !goexperiment.ExecTracer2 && gp.syscallsp != 0 {
trace.GoSysExit(true)
}
trace.GoStart()
traceRelease(trace)
}
// 切换到goroutine调度上下文,实际执行goroutine代码
// 就是从g0切换到g栈空间,并执行g的用户代码
gogo(&gp.sched)
}
Gruning -> Gdead
对普通M(不是M0)而言,执行完任务之后,会进行到goexit,并等待重新调度
// Finishes execution of the current goroutine.
func goexit1() {
if raceenabled {
racegoend()
}
trace := traceAcquire()
if trace.ok() {
trace.GoEnd()
traceRelease(trace)
}
mcall(goexit0)
}
// goexit continuation on g0.
func goexit0(gp *g) {
// 销毁
gdestroy(gp)
// 调度:查找一个可运行的goroutine并执行
schedule()
}
gdestroy 销毁goroutine
销毁其实就是更新状态为Gdead,清除goroutine数据,重新放回P空闲池中
func gdestroy(gp *g) {
// 获取当前M与P
mp := getg().m
pp := mp.p.ptr()
// 更新goroutine状态为Gdead
casgstatus(gp, _Grunning, _Gdead)
// 更新GC控制器。减少可扫描的堆栈大小
gcController.addScannableStack(pp, -int64(gp.stack.hi-gp.stack.lo))
// 如果是系统goroutine,减少计数
if isSystemGoroutine(gp, false) {
sched.ngsys.Add(-1)
}
// 清除goroutine状态
gp.m = nil
locked := gp.lockedm != 0
gp.lockedm = 0
mp.lockedg = 0
gp.preemptStop = false
gp.paniconfault = false
gp._defer = nil // should be true already but just in case.
gp._panic = nil // non-nil for Goexit during panic. points at stack-allocated data.
gp.writebuf = nil
gp.waitreason = waitReasonZero
gp.param = nil
gp.labels = nil
gp.timer = nil
if gcBlackenEnabled != 0 && gp.gcAssistBytes > 0 {
// Flush assist credit to the global pool. This gives
// better information to pacing if the application is
// rapidly creating an exiting goroutines.
assistWorkPerByte := gcController.assistWorkPerByte.Load()
scanCredit := int64(assistWorkPerByte * float64(gp.gcAssistBytes))
gcController.bgScanCredit.Add(scanCredit)
gp.gcAssistBytes = 0
}
// 释放当前M的goroutine
dropg()
if GOARCH == "wasm" { // no threads yet on wasm
gfput(pp, gp)
return
}
if mp.lockedInt != 0 {
print("invalid m->lockedInt = ", mp.lockedInt, "\n")
throw("internal lockOSThread error")
}
// 将 goroutine 放回空闲池
gfput(pp, gp)
if locked {
// The goroutine may have locked this thread because
// it put it in an unusual kernel state. Kill it
// rather than returning it to the thread pool.
// Return to mstart, which will release the P and exit
// the thread.
if GOOS != "plan9" { // See golang.org/issue/22227.
gogo(&mp.g0.sched)
} else {
// Clear lockedExt on plan9 since we may end up re-using
// this thread.
mp.lockedExt = 0
}
}
}
Grunning -> Gwaiting
park_m主要负责将当前的 goroutine 暂停,切换其状态,并在必要时重新调度执行
// park continuation on g0.
func park_m(gp *g) {
mp := getg().m
trace := traceAcquire()
// N.B. Not using casGToWaiting here because the waitreason is
// set by park_m's caller.
// 更改goroutine状态从Grunning到Gwaiting
casgstatus(gp, _Grunning, _Gwaiting)
if trace.ok() {
trace.GoPark(mp.waitTraceBlockReason, mp.waitTraceSkip)
traceRelease(trace)
}
// 将当前goroutine与M分离
dropg()
// 确保在某些条件下,安全地将 Goroutine 从等待状态移出,处理失败的解锁操作,并在必要时重新调度该 Goroutine
// 调用解锁函数
if fn := mp.waitunlockf; fn != nil {
ok := fn(gp, mp.waitlock)
mp.waitunlockf = nil
mp.waitlock = nil
if !ok {
trace := traceAcquire()
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.ok() {
trace.GoUnpark(gp, 2)
traceRelease(trace)
}
execute(gp, true) // Schedule it back, never returns.
}
}
// 调度,切换到其他 goroutine 执行
schedule()
}
Gwaiting -> Grunable
ready将指定的 goroutine 标记为可运行状态,并将其放入运行队列中
// Mark gp ready to run.
func ready(gp *g, traceskip int, next bool) {
// 读取 gp 的当前状态
status := readgstatus(gp)
// 标记为可运行
// Mark runnable.
mp := acquirem() // disable preemption because it can be holding p in a local var
if status&^_Gscan != _Gwaiting {
dumpgstatus(gp)
throw("bad g->status in ready")
}
// status is Gwaiting or Gscanwaiting, make Grunnable and put on runq
trace := traceAcquire()
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.ok() {
trace.GoUnpark(gp, traceskip)
traceRelease(trace)
}
// 将 gp 放入当前 P 的运行队列中。如果 next 为 true,表示将 gp 放在队列的前面,否则放在队列的后面
runqput(mp.p.ptr(), gp, next)
// 确保有一个 P 可以运行 gp
wakep()
// 重新启用当前M的抢占
releasem(mp)
}
Grunning -> Grunnable
goschedImpl 函数用于将当前 goroutine 交出 CPU,使其重新排队等待调度执行。它的实现涉及状态检查、状态变更、跟踪信息处理、全局运行队列操作和重新调度
goschedImpl 函数执行的主要步骤包括:
- 获取并验证 gp 的当前状态。
- 将 gp 的状态修改为 _Grunnable,表示它现在是可运行状态。
- 解绑当前 M 和 gp。
- 获取调度器锁并将 gp 放入全局运行队列。
- 如果主 goroutine 已经启动,则唤醒一个 P 以确保运行队列中的 goroutine 被处理。
- 重新进入调度循环,选择下一个可运行的 goroutine 开始执行。
func goschedImpl(gp *g, preempted bool) {
trace := traceAcquire()
status := readgstatus(gp)
if status&^_Gscan != _Grunning {
dumpgstatus(gp)
throw("bad g status")
}
casgstatus(gp, _Grunning, _Grunnable)
if trace.ok() {
if preempted {
trace.GoPreempt()
} else {
trace.GoSched()
}
traceRelease(trace)
}
dropg()
lock(&sched.lock)
globrunqput(gp)
unlock(&sched.lock)
if mainStarted {
wakep()
}
schedule()
}
大致总结下
go池是所有拥有goroutine的地方,包括P的runnext、P本地队列和全局队列
- Gidle -> Grunnable: 初始化g,放入go池
- Grunnable -> Grunning: 从go池取出,绑定M,执行实际代码
- Grunning
- -> Gdead: 解绑M,重置g,重新放入go池
- -> Gwaiting: 解绑M,等待被唤醒
- -> Grunnable: 解绑M,放入go全局队列
- Gwaiting -> Grunable: 被唤醒后放入go池
- https://github.com/LeoYang90/Golang-Internal-Notes/blob/master/Go%20%E5%8D%8F%E7%A8%8B%E8%B0%83%E5%BA%A6%E2%80%94%E2%80%94%E5%9F%BA%E6%9C%AC%E5%8E%9F%E7%90%86%E4%B8%8E%E5%88%9D%E5%A7%8B%E5%8C%96.md