欢迎来到雲闪世界。“生成式人工智能革命”的核心是谷歌于 2017 年推出的 Transformer 模型。
但每一次技术革命都会带来混乱。在快速增长的环境中,很难公正地评估创新——更不用说估计其影响了。
开启人工智能这一突破的Transformer模型,如今已成为一个“备受争议的模型”。有两种极端观点:
- 热心采用者:他们在任何地方都使用 Transformer,包括 NLP 之外。即使他们不能或不想使用,他们也会使用它们 — — 他们的雇主、经理、投资者等强迫他们使用。
- 怀疑论者和卢德分子:他们批评人工智能模型,包括 Transformers。他们无法理解/接受,使用更多数据和层数扩展模型通常可以胜过基于严格证明的优雅数学模型。
如今尘埃落定,是时候进行公正的研究了。
本文重点介绍用于预测的 Transformers。我将讨论学术界、工业界 和领先研究人员的最新进展。
我还将解释如何以及在什么情况下使用基于 Transformer 的预测模型才能实现最佳效率。
我将把这个分析分为两个部分:
- 背景:Transformers 和深度学习如何开始应用于预测。
- 最新发展:深入了解最新进展和尖端时间序列模型。
开始吧!
深度学习在预测领域的简史
2012 年,AlexNet 模型彻底改变了计算机视觉,标志着深度学习的崛起。有人可能会说这是深度学习诞生的一年(或者神经网络被重新命名的一年)。
最初,深度学习专注于自然语言处理 (NLP) 和计算机视觉,而时间序列预测等领域尚未得到探索。
NLP 中的两个关键模型是Word2Vec和带有注意力机制的 LSTM。例如,LSTM为谷歌的神经机器翻译(图 1)提供支持,而神经机器翻译当时是谷歌翻译的支柱:
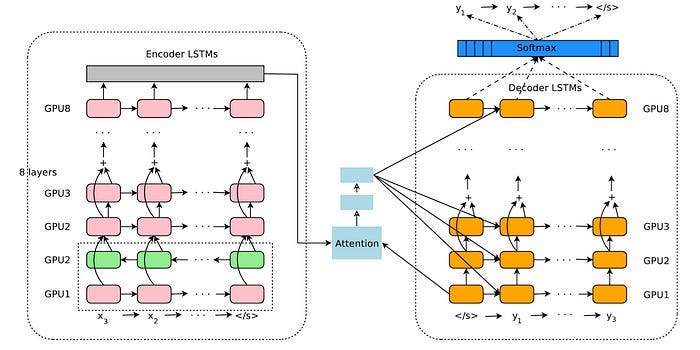
图 1:谷歌神经机器翻译——GNMT 架构(来源)
大约在同一时间,研究人员和企业开始将LSTM应用于时间序列预测。毕竟,文本翻译是一个序列到序列的任务,时间序列预测也是如此(在多步预测场景中)。
但事情没那么简单。虽然LSTM在 NLP 和机器翻译任务中取得了重大突破,但在时间序列预测方面几乎没有什么革命性。当然,LSTM比统计方法有一些优势(它们不需要额外的预处理,比如使序列平稳,它们允许额外的未来协变量等)。
在某些任务和数据集上,LSTM表现更佳,但没有证据表明存在重大的范式转变。
这在实践中很明显。在Makridakis 等人于 2018 年发表的一篇论文中,对各种时间序列模型进行了基准测试。包括LSTM在内的 ML 和 DL 模型表现不佳,其中 LSTM 排名最差!(图 2)
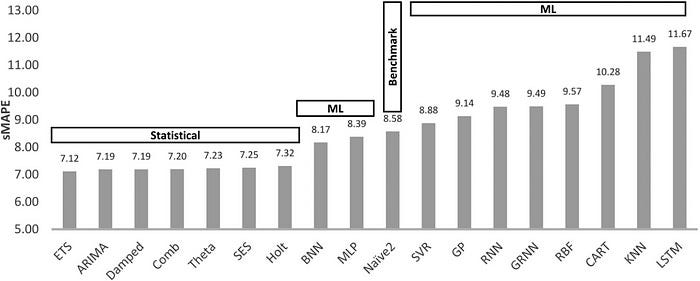
图 2: Makridakis 等人在 2018 年研究的八种统计方法和十种 ML 预测方法的预测准确度 (sMAPE)。所有 ML 方法都排在最后几位。
最终,在比赛的第四次迭代(即M4)中,获胜的解决方案是ES-RNN,这是 Uber 研究人员开发的混合 LSTM 和指数平滑模型。
问题很明显:研究人员试图将深度学习方法强行应用于时间序列预测,而没有进行适当的调整。
但时间序列预测是一项难以实现的任务——单纯地添加更多层或神经元并不能带来突破。一个鲜为人知但有效的模型是时间卷积网络 (TCN) ——一个基于Deepmind 的Wavenet 的隐藏宝石,它采用 CNN 进行时间序列预测(图 3):
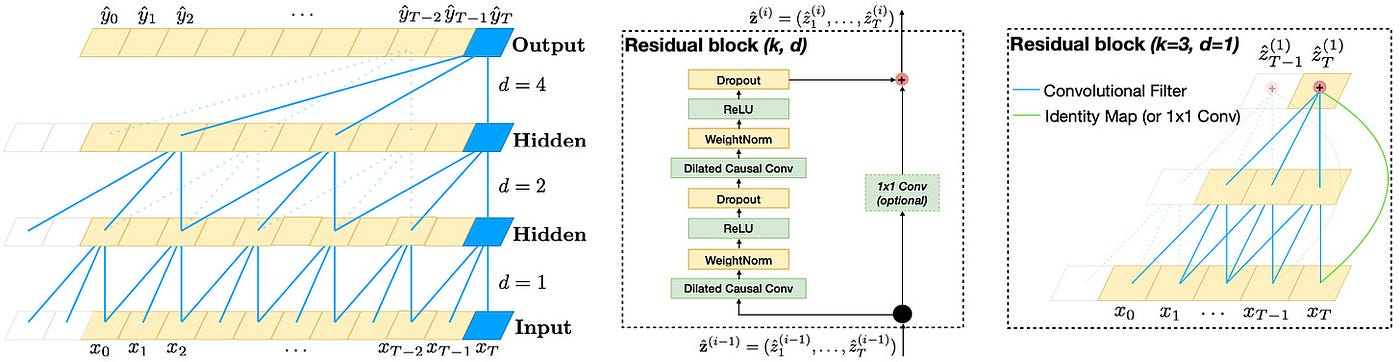
图 3: 时间卷积网络的顶层架构(来源)
TCN 至今仍在使用(作为独立模型或作为其他模型的一部分),在预测任务中,其表现通常优于 LSTM —因为它们可以并行化,从而速度更快。它们还用于金融和交易应用。
为了彻底改变时间序列预测,深度学习需要一种独特的方法。接下来我们将探讨这一点。
深度学习预测——第一届 Sparks 大会(2017-2019 年)
还记得我们之前提到过的Word2Vec吗?这种新方法引入了创建嵌入的概念 - 允许 DL 模型使用有限词汇表中的单词作为输入。
但Word2Vec也意味着:“嘿,我们现在可以在神经网络中使用分类变量”。
使用嵌入,我们可以同时对多个时间序列进行建模 - 换句话说,构建一个受益于交叉学习的全局模型。
但研究人员很快意识到,提升性能的并不是嵌入或更深的模型,而是利用统计概念和更多数据的优雅架构。
这个时代的两个成功模型分别是亚马逊研究院的DeepAR和Elemental AI ( Yoshua Bengio共同创办的一家初创公司)的NBEATS 。后来,谷歌发布了Temporal Fusion Transformer (TFT),这是一个强大的模型,至今仍是 SOTA。TFT是Nixtla 超级基准测试中表现最好的模型之一(更多内容请参见第二部分)。
第一个重大突破是N-BEATS,其表现超越了M4竞赛冠军:
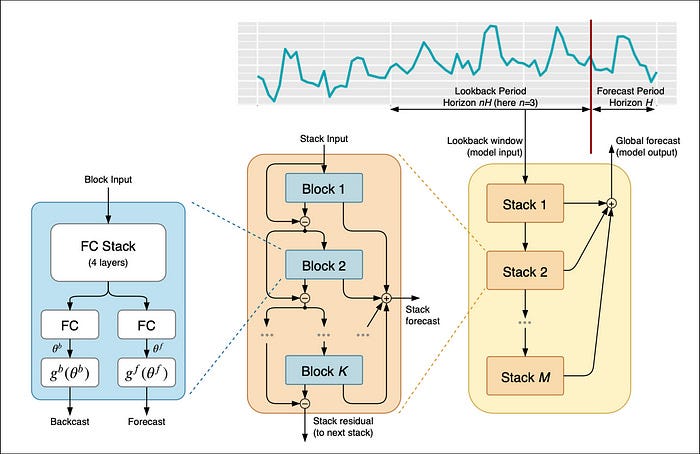
图 4: N-BEATS 的顶层架构(
N-BEATS是一个里程碑模型,因为:
- 它结合了深度学习+信号处理理念。
- 它是可解释的(趋势和季节性)。
- 支持迁移学习。
在N-BEATS 之前,没有任何深度学习预测模型具备所有这些功能。可以说:
N-BEATS 通过在其架构中尊重和利用时间序列的统计属性而成功成为 DL 模型。
同样,DeepAR是首批将概率预测融入深度学习的模型之一。
DeepAR充当全局模型,利用多个时间序列的交叉学习,并结合额外的协变量。模型架构如图5所示:
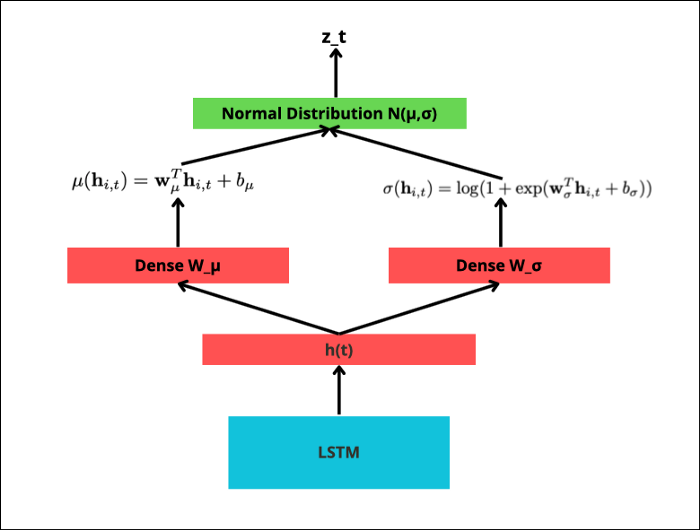
图 5:在 DeepAR 中计算以创建预测数据点 zt (作者提供的图片)
DeepAR本质上是一个自回归模型,它使用LSTM(和一些额外的线性层)来预测正态分布的参数(视情况而定)——在推理过程中用于绘制样本并输出预测。
它的成功启发了诸如DeepState(状态空间模型)和Deep GPVAR(使用高斯 copula)等变体。
然而,当深度学习在时间序列预测方面迈出第一步时,NLP 却随着Transformer的出现而经历了革命。
进入变压器
2017 年,谷歌在论文中推出了 Transformer,其模因名称为“ Attention is All You Need ”,以取代基于 LSTM 的翻译模型。
Transformer 是我们之前提到的两个模型的子模型:Wavenet和带有注意机制的 Stacked LSTM。
- 具有注意力机制的 LSTM可以学习长距离依赖关系——但不可并行化。
- Wavenet使用卷积——这对于文本数据来说并不理想,但具有高度可并行性。
因此,Transformer 应运而生,将两全其美的优点融为一体。
Transformer 是一个编码器-解码器模型,利用了多头注意力机制。当然,注意力机制(以更简单的形式)以来就已经在神经机器翻译任务中为人所知。
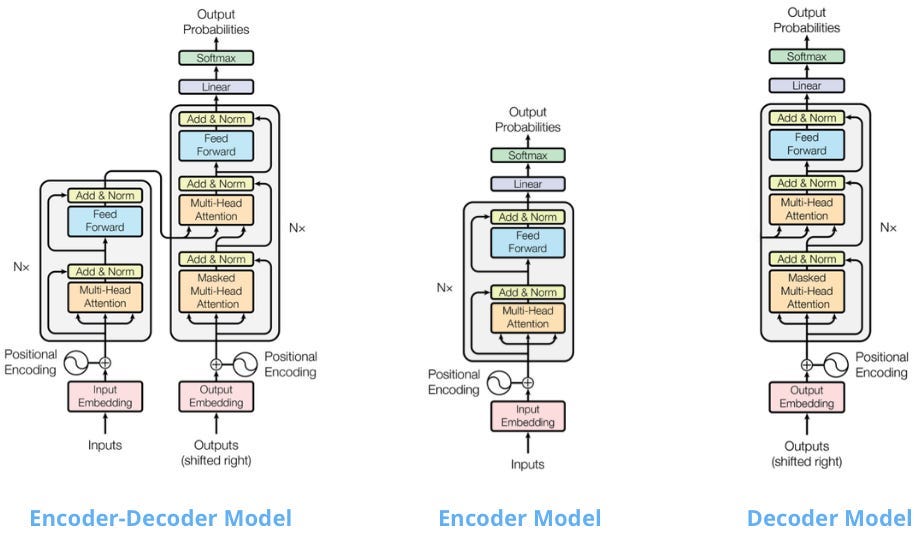
图 6: Transformer 模型的初始变体 —左:Attention 的原始 Transformer 模型就是您所需要的,中:仅编码器模型 (Bert),右:仅解码器模型 (GPT-1)(图片注释自此处)
接下来,OpenAI抢了谷歌的风头,发布了Transformer 模型的第一个流行变体GPT。GPT是一个仅解码器模型,适用于自然语言生成 (NLG)。
几个月后,谷歌发布了其标志性模型BERT ,这是一个仅编码器的模型。BERT适用于自然语言理解任务(NLU)——例如文本分类和命名实体识别(图 6)。因此:
- 仅编码器模型使用双向注意力(以两种方式寻找上下文)来理解句子并预测句子中的掩码词。它们擅长 NLU 任务。
- 仅解码器模型使用因果注意力(模型仅回顾上下文)并学习预测下一个单词。它们擅长 NLG 任务。
GPT 和 BERT 都是预训练模型(或基础模型)。然而,第一个探索预训练的流行 NLP 模型是通用语言模型微调 ( ULMFiT ) — 它基于 RNN
自然,变形金刚也进入了该系列的视线。最成功的模型之一是时间融合变形金刚 (TFT):
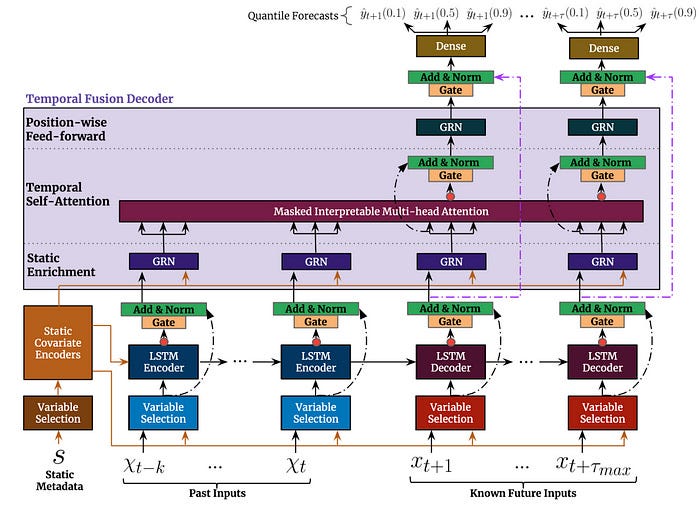
图 7:TFT 的顶层架构及其主要组件
TFT是一个突破性的模型,支持:
- 多时间序列:我们可以在数千个单变量或多变量时间序列上训练TFT 。
- 多视野预测:模型输出一个或多个目标变量的多步预测 - 包括作为分位数预测的预测区间
- 异构特征: TFT 支持多种类型的特征,包括时变和静态外生变量。
- 可解释的预测:可以根据变量重要性和季节性来解释预测。
TFT 的表现优于统计模型和早期的 ML 实现。它之所以成功,是因为:
- 它不只是复制了多头注意力机制。相反,TFT将注意力机制重构为一种可解释的机制
- 虽然注意力被用来捕捉长期时间动态,但TFT仍然使用LSTM编码器-解码器来模拟局部依赖性。
你现在注意到一种模式了吗?
TFT 的成功并非源于复制 Transformer 模型,而是源于巧妙地将其应用于时间序列预测。
然而,与 NLP 相比,深度学习和 Transformers 在时间序列预测方面的进展较慢。
即使在计算机视觉领域,第一个成功的 Transformer 应用 Vision Transformer (ViT) 也于 2020 年发布。经过进一步修改后,该模型在许多图像分类任务中的表现优于 CNN。研究人员还发现,将这两个组件结合起来可以产生更好的结果。
幸运的是,这种趋势现在已经改变。过去几个月,我们看到了生成式人工智能时间序列基础模型的发布。
这些突破性的模型无需训练即可轻松输出新数据的准确预测。这些模型包括:
- TimeGPT(尼克斯特拉)
- TimesFM(谷歌)[1]
- MOIRAI(Salesforce)[2]
- 微型时间搅拌机(IBM) [3]
- MOMENT(卡内基梅隆大学和宾夕法尼亚大学)[4]
最近,Nixtla 进行了一项大型研究(具有 30k 个时间序列的可重复基准)。他们发现基础模型的平均表现优于其他模型:
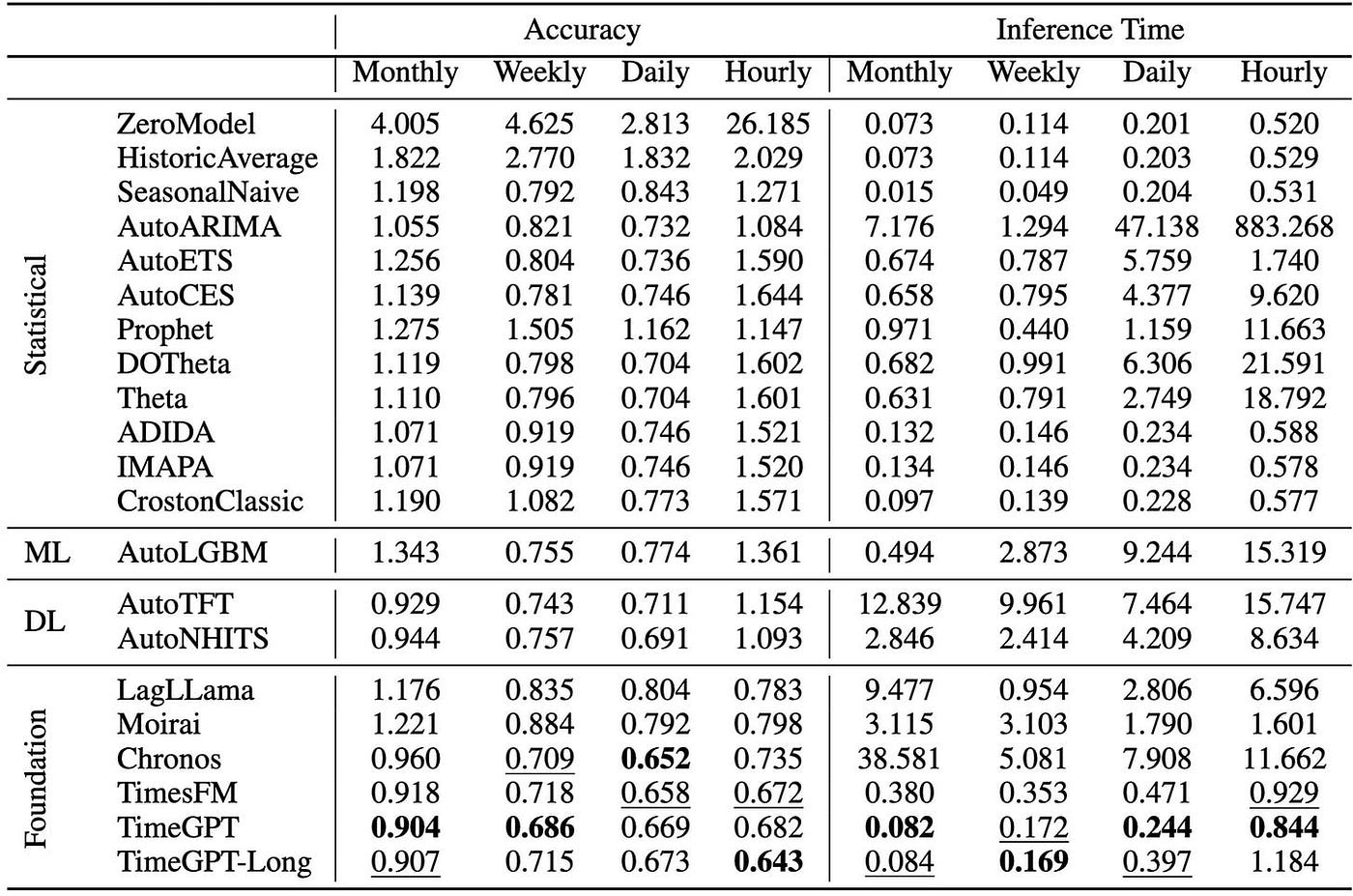
表 1: 对各个类别(统计、深度学习、提升树、基础模型)的许多流行时间序列模型的实证评估
结果非常出色。TimeGPT是最好的模型,其次是TimesFM 。这使得TimesFM成为本研究中最好的开源模型!
在AI 项目文件夹中查找所有最新生成式 AI 预测模型(包括 TimesFM)的深入项目
结束语——下一步
如果您仔细阅读了这篇文章,您现在应该很好地理解深度学习的发展将如何影响时间序列预测。
但仍有需要改进的地方。
深度学习在时间序列预测中应用缓慢的原因之一是缺乏工具和框架。虽然PyTorch和 TensorFlow中提供了LSTM和CNN等模型,但它们主要用于其他领域。
当时,Darts和Nixtla等库还不存在,这使得为时间序列模型准备、规范化和切片数据变得非常困难。处理额外的协变量和未来已知变量使这项任务更加困难。
我预测下一个重大突破可能是多模态。想象一下,一个时间序列模型不仅使用基于时间的数据,还集成了其他类型的数据,例如文本!让我们拭目以待!
感谢关注雲闪世界。(亚马逊aws和谷歌GCP服务协助解决云计算及产业相关解决方案)
订阅频道(https://t.me/awsgoogvps_Host)
TG交流群(t.me/awsgoogvpsHost)