"然后自然老去吧,别再依依惜别了"
条款5:了解C++默默编写并调用了哪些函数
(1)小试牛刀地回顾
C++编译器为类提供的默认函数很多人知道是有6个的。默认构造、拷贝构造、赋值重载、析构函数、重载取地址运算符,但是在C++11更新后,又为类对象增添两个新的函数,移动构造函数、重载移动赋值运算符,当然这是为了解决性能提的要求,但并非本小节的重点。
1.默认构造:
是一种无参的构造函数。我们所认为的默认构造函数, 一个是我们不写,编译器自己生成的,二个是我们自己写的无参的构造函数,三个是我们写的,全缺省的构造函数。
2.拷贝构造:
顾名思义,是一个并不存在的对象,依靠着已经存在的对象的内容,进行拷贝。是构造函数的一种重载,针对的是本对象的类型。
注:拷贝构造函数的参数只有一个且必须使用引用传参,使用传值方式会引发无穷递归调用。
3.赋值重载:
C++为了提高代码的可读性,引入的新的语法。即,可以将一些运算符进行重载,从而能让它像函数一样地使用。 不过,对于赋值重载与拷贝构造的最大区别在于,调用前该对象是否存在!
有了上面的预备知识,我们也就不难理解下面的一系列现象。
class Empty
{
public:
Empty(){} //defualt构造函数
Empty(const Empty& ref){} //copy构造函数
~Empty(){} //析构函数
Empty& operator=(const Empty& ref){} //赋值运算符重载
};
int main()
{
Empty e1; //调用默认构造
Empty e2(e1); //拷贝构造
e2 = e1; //赋值
return 0;
}
取自《Effictive C++》这些编译器为我们生成的默认函数,在做这些什么?
default构造与析构;
当我们引入类的继承概念,来看待default构造和析构时,当我们调用derived class的构造函数时,会默认去调用base class的default构造,从而来初始化base class以及其包含的non-static 成员变量。编译器产生的析构函数,通常不会是个虚函数(virtual),除非这个base class自身进行声明virtual 析构。
copy构造与copy assignment操作符
对待一些特殊的类型,如string\vector等于堆空间打交道的容器。编译器为我们自动生成的拷贝构造和赋值运算符重载(如果它们被调用的话),仅仅只会将来源对象的每一个non-static成员变量一一拷贝到目标对象(例如int类型,拷贝来源对象的每个bits的内容)。也就是我们俗称的浅拷贝。
当我们不再需要编译器那糟糕的默认构造,仅仅需要声明其中的构造函数,那么编译器不会再为该类对象创建default构造函数,你也无所担心,你写的无参的构造函数,会被编译器默认生成的default构造函数覆盖掉!
template<class T>
class NameObject
{
public:
//构造函数与copy构造的声明 编译器不会再为类生成默认的~
NameObject(const char* name, const T& val);
NameObject(const NameObject& ref,const T& val);
private:
std::string name;
T objectValue;
};
取自《Effictive C++》(2)开胃菜
难道编译器默认生成copy构造与赋值重载会给我们解决一切 构造与赋值的问题吗?
此时我们将nameObj的成员变量变为引用;
template<class T>
class NameObject
{
public:
//这里的构造运用了 初始化列表! 是每个成员变量的初始化处
NameObject(std::string& name, const T& val)
:namevalue(name),
objectValue(val)
{}
//此时我们并没有写 operator=
private:
std::string& namevalue;
const T objectValue;
};
int main()
{
std::string newDog("Persephone");
std::string oldDog("Satch");
NameObject<int> p(newDog, 2);
NameObject<int> s(oldDog, 36);
p = s; //我们进行赋值
return 0;
}
取自《Effictive C++》
怎么回事?编译器怎么给把这个默认赋值重载函数删除了?
在赋值之前,p.namevalue 与 s.namevalue都是引用的不同的值string,那么赋值操作的作用就是,让p.namevalue去引用s.namevalue,也就是refernce自身是被改动了的, 这可能嘛?!
我们来看看一个简单的例子;
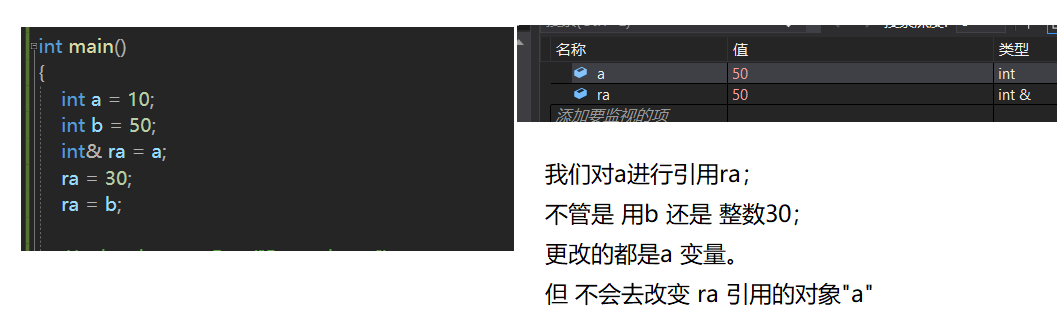
换言之,C++并不允许,“让reference指向一个不同的对象”。
不能改变引用的对象,对象不能因为赋值操作而受到这样的影响(持有的reference不该指向该string外的其他对象)。显然,面对这个难题,编译器的处理还是一贯的雷厉风行,干脆拒绝"编译"这样的赋值操作!编译器,也无法处理这个问题。
因此,如果你打算对一个内含reference的成员支持赋值的操作,很简单,你自己实现一个吧,也就不劳烦编译器帮你自动生成了。当然,面对const成员变量也是这样的,对const成员变量进行更改也是不能忍受的!
还有一种情况,base class当把copy构造函数的权限设为private时,编译器不会再为derived class生成默认的copy assignment操作符。毕竟,derived class中base class的成员变量,需要base class自己处理。
可是连derived自己都无法调用时,编译器也束手无策,双手一摊~


请记住:
编译器可以暗自为class创建default构造函数、copy构造函数、copy assignment操作符、以及析构函数。
条款6:若不想使用编译器自动生成的函数,就该明确拒绝
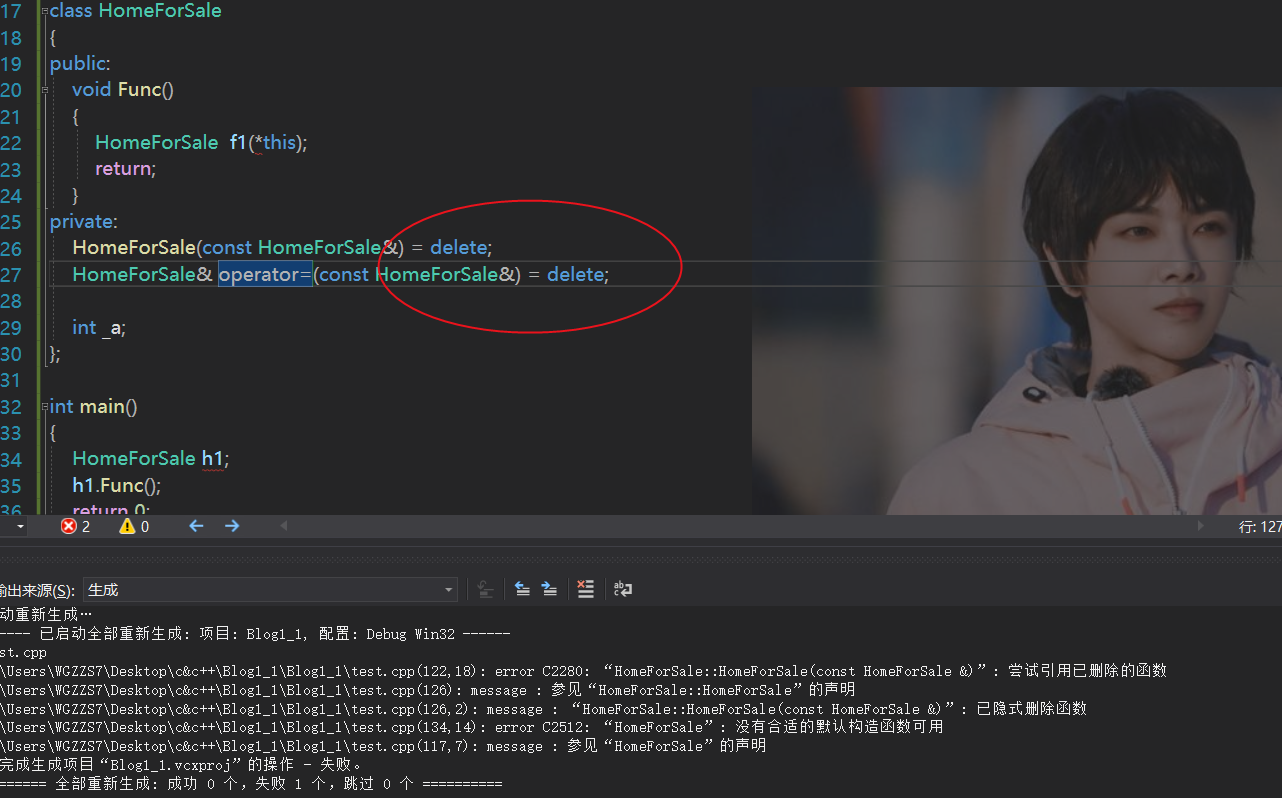
当将编程放到不同的社会场景,往往书本上的理论会显得生涩。正如这本书举的例子,假如房地产商要卖房子,对他们而言,每一份地产资产都是"独一无二"的!此时,我们设计一个类为HomeForSale,显然如果该类能被复制,也就是说,地产资产不再是"独一无二"的了,我想,他们一定不会乐意看到这种情况!
class HomeForSale{...}
HomeForSale h1;
HomeForSale h2; //h1\h2都是两份独一无二的地产资产
HomeForSale h3(h2); //h3企图拷贝h2的! 不应该通过编译!
--------取自《Effictive C++》通常而言,如果不需要class实现一些功能,大可不声明对应函数即可。可是,这个策略对copy与copy assignment却起不到作用。(你不写,编译器会默认给你的类生成)。
这显然就很棘手!你不想实现copy 与 copy assignment函数,却因为编译器的原因,不得不实现,而目标是阻止copy,你却在支持copy!
编译器默认产出的所有函数,都是public的。为阻止这些函数的产生,你大可自行声明,难道不可以将函数的声明放置private里吗?既可以,阻止编译器的实现,也可以让类外的访问copy行为得到遏制!
class HomeForSale
{
public:
...
private:
HomeForSale(const HomeForSale&);
HomeForSale& operator=(const HomeForSale&);
}
取自《Effictive C++》但是这种方式并不是完全得安全!因为,你无法保证member函数 或者 friend函数 进行copy操作。不过,当你只进行声明而不去定义时,那么就算被不慎调用,编译器也会报错。

这样也就把问题从连接时期,转移到了编译器。
当然解决上面的问题,除开将copy、copy assignment操作符声明为private,还可以专门HomeForSale自身设计一个base class,专门用来组织copying的动作。
class Uncopytable
{
protected:
Uncopytable(){}
~Uncopytable(){}
private:
Uncopytable(const Uncopytable&);
Uncopytable& operator=(const Uncopytable&);
};
//为阻止HomeForSale的拷贝 我们只需让它继承 Uncopytable
class HomForSale:private\public\protected Uncopytable
{
...
};
取自《Effictive C++》当任何人甚至是friend函数或者member函数,尝试进行它的拷贝时,编译器会尝试调用base class
里的函数,但是编译器会被拒绝,因为base class里的拷贝函数是private。
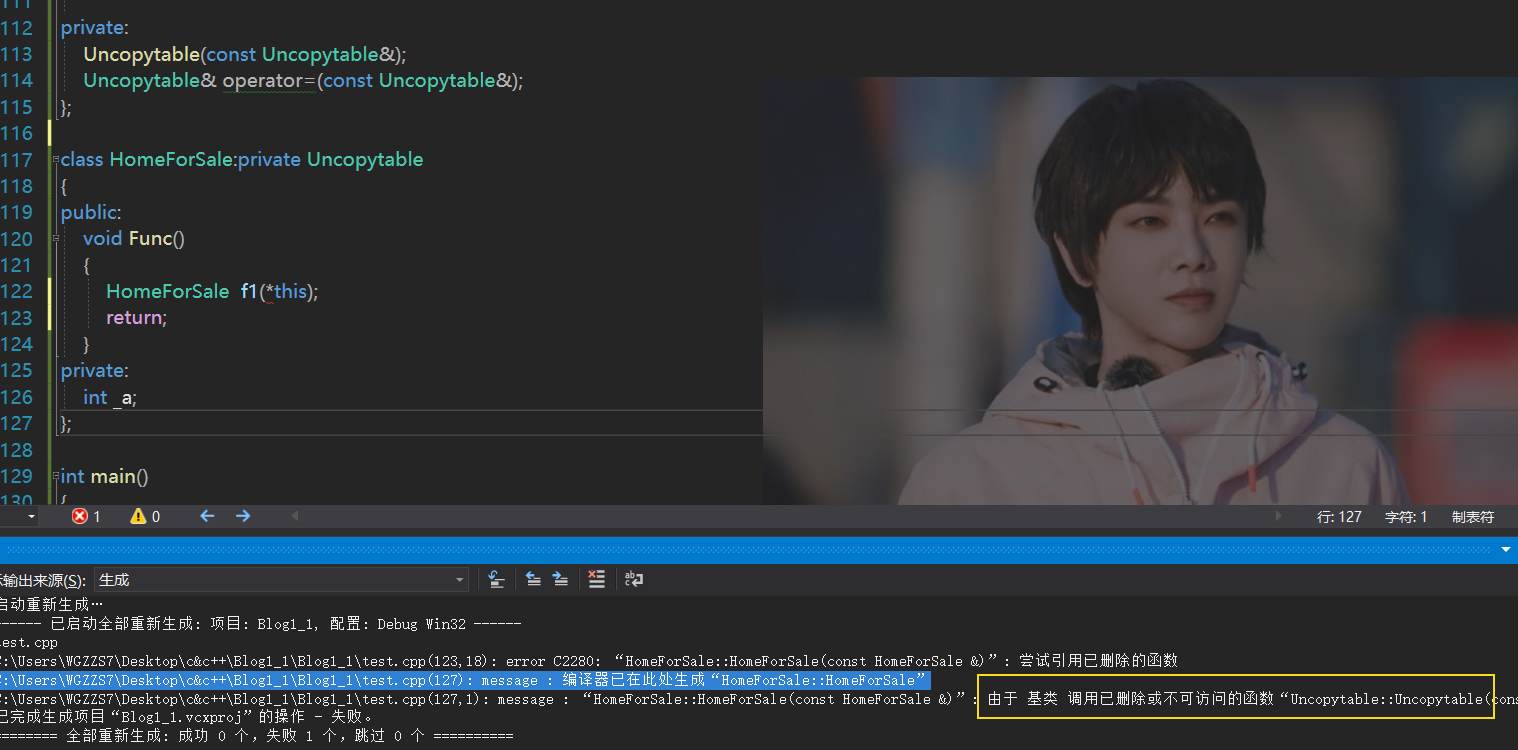
当然,C++的继承的设计经常遭人诟病,其中的一个原因是支持了多重继承(菱形继承),从而使得类变得复杂,这项技术可能会对base class阻止copying有一定的影响。
同样也可以使用boost提供的版本,去继承那个名为noncopyable class。可以看看这里
在C++11中增加了两个关键字 default\delete ,一个是针对默认函数,一个就是针对本节的内容。
请记住:
为驳回编译器自动(暗自)提供的技能,可将相应的成员函数声明为private并不予实现。使用像Uncopyable这样的base class 也是一种做法。
条款7:为多态基类声明virtual析构函数
(1)小试牛刀地回顾
什么是多态?一句话,父类对象的引用或指针调用重写的虚函数。
(2)开胃菜
任何class只要带有virtual函数,几乎应该也有一个virtual 析构函数
我们有很多方法可以看到知道现在的时间,如墙上挂上的钟表,随手可拿的手机,或是戴在手上的手表。在这里 设计一个类TimeKeeper 的基类和继承下去的不同计算时间的不同方法。
class TimeKeeper
{
public:
TimeKeeper(){}
~TimeKeeper()
{
std::cout << "~TimeKepper()" << std::endl;
}
static TimeKeeper* GetTimeKeeper()
{
return new TimeKeeper;
}
};
class AtomicClock :public TimeKeeper{ public: ~AtomicClock() { std::cout << "~AtomicClock()" << std::endl; } };
class WaterClock :public TimeKeeper { public: ~WaterClock() { std::cout << "~WaterClock()" << std::endl; } };
class WristWatch :public TimeKeeper { public: ~WristWatch() { std::cout << "~WristWatch()" << std::endl; } };
《取自Effictive C++》此时我们通过getTimeKeepe(),得到基类指针。并对指针进行释放动作。

如我们预期所,delete父类指针,去调用了父类的析构函数。
但是如果我们此时将父类指针指向一个子类对象呢?
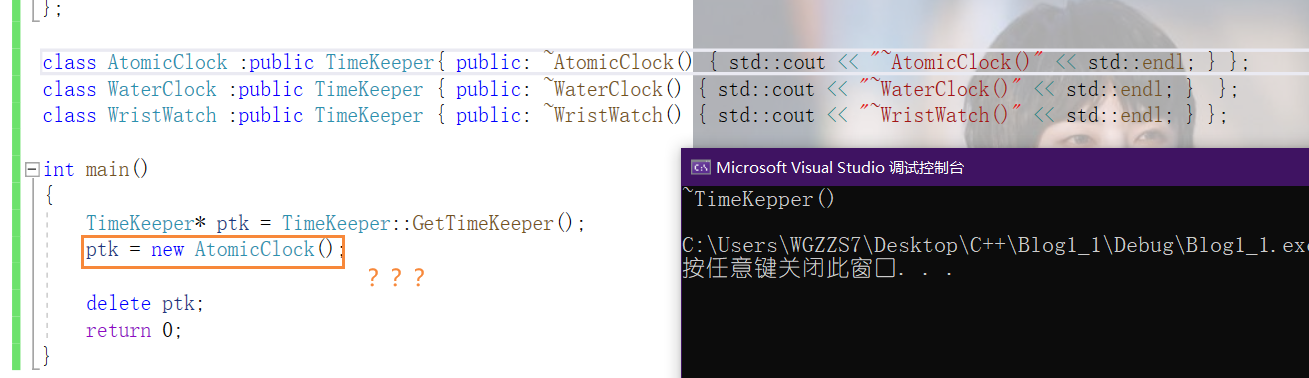
当getTimeKeepr返回的指针指向一个derived class对象时(如上图AtomicClock),那个对象经由base 指针删除,却仅仅是调用了base它自己的析构函数。
"C++明白指出,当derived class 对象经由一个base class指针被删除,而该base class带着一个non-virtual 析构函数,其结果未定义——实际执行时通常发送的是对象的derived成分没有被销毁掉。"
这不难理解,什么对象调用什么函数,既然是base类型的指针delete,当然是调用它自己的析构函数。可是,当场景应用到多态,这样的所谓的很符合我们早已烂熟于心的理解却为我们的程序引来灾难(资源泄漏)。AtomicClock的析构未执行起来,而base class中的成员却被销毁,造成一个诡异的"局部销毁"。我想,这对于调试Bug的人来说,无疑是咬牙切齿的。
根据上述那段标黄的引用,我们给base class一个virtual的析构函数,然后继续执行同一段代码逻辑。
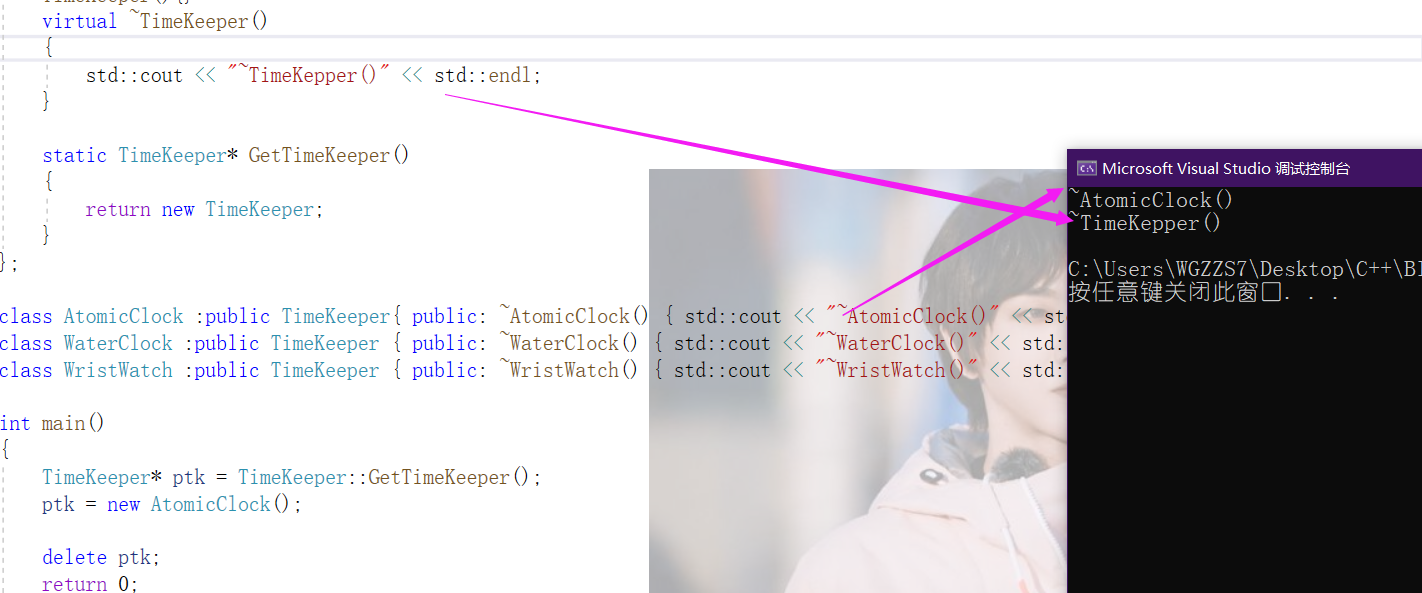
很好!它会销毁整个对象,包括前些时刻那"顽固派"derived class。
当然,virtual函数不仅仅是在析构函数,解决子类可能留下的"局部销毁"的问题。
"virtual函数的目的是允许derived class的实现得以客制化"。例如TimeKeepr就可能拥有一个虚函数的virtual GetCurTime(获取当前时间),那么不管是AtomicClock\WaterClock\WristClock,他们都得为这个基类的函数,实现一份属于自己时间计算的细节代码。
并非任何时候析构函数都需要带上virtual
也许你对什么场景该用什么样的类设计不清楚,但是又怕因为类设计的不当,引起上述情况(内存泄漏)的恼人问题,干脆什么时候都给一个类的析构函数带上virtual。这对吗?我们看看下面的场景。
这是一个坐标类,也许在它身上考虑作为base设计确凿有些大概异想天开。
class Point
{
public:
Point(int xCoord,int yCoord){}
~Point(){}
private:
int x, y;
};
《取自Effictive C++》
计算类的大小,嗯?并不陌生。如果有需要,它可以传递给其他语言如:C。那么我给析构函数加上virtual再试试呢?

嗯???对象类型变大了。这是为什么呢?

这里也就牵涉到多态的原理,也就能解释为什么一个父类指针\引用,调用被重写的虚函数时,看似是调用的同一个函数,其实这个函数调用取决于传递给父类指针\引用的对象。
一旦出现virutal函数,对象就必须携带某些信息, 主要用于在运行期间决定哪一个virutal函数被调用(动态绑定)。我们在vs见到的_vfptr就是一个指针,叫做虚函数表指针(虚表指针)。它指向的是一个函数指针构成的数组vtbl。这个数组里面存的是,完成重写(覆盖)的虚函数。
当对象调用某一个虚函数时,这不是在编译期间就决定的!(这和我们调用普通的函数不一样,调用普通函数在编译期间就知道该函数的地址。执行到这个代码时,直接call地址即可。),而是编译器拿到_vfptr,找到vtbl,在其中寻找适当的函数指针。
因此,无端地将所有classes的析构函数声明为virtual,就像那些需要声明的地方而不声明一样,都是错误的。所以,也就有本小段的第一个标题:只有当class内含中至少一个virtual函数,才能把它的析构函数声明成virtual。
别妄想继承STL容器
或许哪天你学有所成,突发奇想,我能否去继承STL库中的类?
class SpecialString :public std::string
{
public:
SpecialString(const char* msg)
:std::string(msg)
{}
~SpecialString()
{
std::cout << "~SpecialStrig" << std::endl;
}
};
int main()
{
SpecialString* pss = new SpecialString("I am string");
std::string* ps = pss; //SpacialString* --> string*
delete ps; //SepcialString的析构函数不会被调用
return 0;
}
取自《Effictive C++》标准库中的string中不含有任何的virtual函数,同样例如vector,list,set……也是如此。C++11后引入了一个final关键字,该关键字通常放在一个类名的后面,表示该类"不可被继承"。因此,也就不会诱惑你看到任何析构函数都会去给人家填上virtual,或者看上任何好的类设计都跑去继承,而在析构时引发不必要的麻烦。
纯虚函数
类的继承通常 分为两种,一种是实现继承,一种是接口继承。我们常见的包括上面的例子都是一种实现继承。
接口继承主要体现在一种类设计上——抽象类,什么是抽象呢?在哲学上总是归结为提取一个事物的特征,因此它总会被拿来用作一个base class。而什么是抽象类呢?包含纯虚函数的类,称谓抽象类。其中最显著的特点就是,该类不可以实例化出对象。换言之,只有当子类继承并重写了它提供的虚函数,才有意义。因此所谓接口继承,我想也就不难理解了。
class AWOV
{
public:
virtual ~AWOV() = 0; //声明纯虚哈数
};
AWOV::~AWOV(){} //这里给出定义是因为 编译器做出调用析构函数的动作。
取自《Effictive C++》析构函数的运作方式:
最深层的派生类的那个析构函数最先被调用,最后才是其每一个base class的对象被其析构函数清理。
请记住:
polymorphic(带有多态性质的) base class应该声明一个virtual函数。如果class带有任何virtual函数,那么其析构函数也应该拥有一个virtual函数。
Classes 的设计目的如果不作为class base使用,或不是为了实现具备多态性的设计,不应该将析构函数声明为virtual。
条款8:别让异常逃离析构函数
(1)小试牛刀地回顾
什么是异常;
异常指的是在程序运行过程中发生的异常事件,通常是由外部问题(如硬件错误、输入错误)所导致的。在Java\C++等面向对象的编程语言中异常属于对象。 取自这里
异常(Exception)vs 错误(Error);
异常(Exception)都是运行时的。编译时产生的不是异常,而是错误(Error)。
传统C语言处理错误的方式有三种;
①assert:暴力终止程序 发生错误会立即中断程序。
②exit code(错误码):需要程序员根据错误信息 去对应错误原因。系统的很多库的接口函数都是通
过把错误码放到errno中,表示错误。
③C 标准库中 setjmp和longjmp组合:不是很 常用。
实际中C语言基本都是使用错误码的方式处理错误,部分情况下甚至会采用终止程序(assert)的方式处理错误。
异常使用;
throw: 当问题出现时,程序会抛出一个异常。这是通过使用 throw 关键字来完成的。
catch: 在您想要处理问题的地方,通过异常处理程序捕获异常.catch 关键字用于捕获异
常,可以有多个catch进行捕获。
try: try 块中的代码标识将被激活的特定异常,它后面通常跟着一个或多个 catch 块。
注:
1.异常是通过 抛出对象而引发的,该 对象的类型决定了应该激活哪个catch的处理代码
2.被 选中的处理代码是调用链中 与该对象类型匹配且离抛出异常位置最近的那一个。
double Divsion(int a,int b)
{
if (b == 0)
{
throw "除零错误";
}
return ((double)a / (double)b);
}
void Test()
{
int i = 0;
int j = 0;
std::cin >> i >> j;
std::cout << Divsion(i, j) << std::endl;
}
int main()
{
try {
Test();
}
catch (const char* errmsg)
{
std::cout << errmsg << std::endl;
}
catch (const std::exception& e) //C++官方提供的异常类
{
std::cout << e.what() << std::endl;
}
catch (...) //捕捉任意类型
{
std::cout << "未知错误" << std::endl;
}
return 0;
}
官方库中的Exception;
C++ 提供了一系列标准的异常,定义在 中,我们可以在程序中使用这些标准的异常。它们是以父
、子类层次结构组织起来的。


实际中我们可以可以去继承exception类实现自己的异常类。但是实际中很多公司像上面一样自己定义一套异常继承体系。因为C++标准库设计的不够好用。
异常安全;
1.构造函数完成对象的构造和初始化,最好不要在构造函数中抛出异常,否则可能导致 对象不
完整或没有完全初始化。
2.析构函数主要完成资源的清理,最好不要在析构函数内抛出异常,否则可能导致资源泄漏(内
存泄漏、句柄未关闭等)。
3.C++中异常经常会导致资源泄漏的问题,比如在new和delete中抛出了异常,导致内存泄
漏,在lock和unlock之间抛出了异常导致死锁。
(2)开胃菜
"C++并不禁止在析构函数中吐出异常,但它也不鼓励你这样做。"
我们先来看看下面一份代码;
class Widget
{
public:
//..
~Widget()
{
//..可能吐出异常
}
};
void dosomething()
{
std::vector<Widget> w;
} //函数结束 就会对Widget进行销毁
取自《Effictive C++》假设w中内含n个Widegt,也就意味着当函数结束时,Widget类会相应做出n次的析构动作。在析构其中一个元素期间,突然有个异常抛出,但这并不影响其他n-1个Widget调用它们各自的析构函数,完成对它们申请资源释放的责任。此时,第二个Widget析构函数又抛出异常。
"这个对于C++而言太多了,两个异常同时存在的情况下,程序若不是结束执行,就是导致不明确的行为。"
那么当我们遇到一个能在析构函数中,可能会抛出异常 的代码段该怎么办?我们建立一个新的场景:
为确保客户不要忘记调用DBConnection中的close,我们又封装一个类DBConn,并在其中的析构函数调用DBConnection中的close。
class DBConnection
{
public:
static DBConnection create()
{}
void close()
{}
};
//解决关闭
class DBConn
{
~DBConn()
{
db.close();
}
private:
DBConnection db;
};
int main()
{
//DBConnection中的资源管理 交付给了DBConn中的析构函数
DBConn dbc(DBConnection::create());
return 0;
}
取自《Effictive C++》上述的伪代码只用在意析构函数的功能即可。只要调用了close,似乎和我们的预期一样。资源得到了有效地清理。但,一旦close 的调用发生异常,受这个异常的影响,就会跳出该析构函数,返回到"上层栈帧"。
有两个方法可以应对调用close发生异常的情况:
①如果close抛出异常,即结束程序.
~DBConn()
{
try {
db.close();
}
catch (...) {
std::abort(); //强迫进程结束
}
}
取自《Effictive C++》"阻止异常从析构函数传播出去导致的不明确行",这里原文给我的理解是,难以让程序员知道异常来自哪里。
②吞下close抛出的异常.
~DBConn()
{
try{
db.close();
}
catch (...) {
//吞下异常 记录close调用失败
std::cout << "Error Happen" << std::endl;
}
}
取自《Effictive C++》不过,即便将异常吞掉是个坏主意,它往往不能清晰地反映异常发生的原因,但却往往会比"草率结束程序"或者出现"不明确行为带来的风险"要好得多。因为,你不希望当你使用微信时,信息是因为网络环境差而迟迟发不出去,而不是当信息发布出去时,直接将你这个微信进程给干掉了!
"程序必须能够继续可靠地执行下去,及时遭遇到并忽略了一个错误信息后。"
上述的两个办法,都没有对当异常发生时,该做何如反应。
我们不得不需要对DBConn重新设计一番。
//解决关闭
class DBConn
{
public:
//为用户提供一个关闭
void close()
{
db.close();
closed = true;
}
~DBConn()
{
if (!closed){
try {
db.close(); //如果客户不调用close的话
}
catch (...) {
//吞下异常
std::cout << "Error Happen" << std::endl;
}
}
}
private:
DBConnection db;
bool closed = false;
};
取自《Effictive C++》现在,我们再增添一个close接口,从而赋予客户一个机会得以处理"因该操作而发生的异常"。DBConn也可以通过 closed追踪链接是否已经被关闭,在得到为false的情况下,在析构函数处自动调用db.close()。那么此时,又让我们回到了abort()程序 或者 吞下异常的 老路:
这什么牛马?! 上述的代码,无非就是将调用close的任务,交付了两个对象(从只有DBConn管理,到客户与DBConn共同管理的"双保险"调用)。实际上,如果某个操作可能在失败时抛出异常,并在某个需要下必须处理这个异常,那么这个处理异常的函数,必须来自除析构之外的任何函数。
正如本条款的标题,"别让异常逃离析构"。通过析构来处理异常就是很危险,不是很可取的。本例子要说的,就是针对客户们自己来调用close,这不是一种负担而是一种机会。这种机会存在于当异常发生时,你有机会做出响应和提出针对某种需要下的处理方法。那么,当DBConn吞下异常或者选择终止掉程序时,客户也就没有理由抱怨它的不作为!毕竟,是他们自身选择了放弃。
请记住:
析构函数绝对不要吐出异常,如果一个析构函数调用的函数可能会抛出异常,析构函数应该捕捉任何异常,要么吞并它们,要么终止掉程序,"不让异常逃离析构函数"
如果客户需要针对某个操作函数运行期间,抛出的异常做出反应,那么class应该提供一个普通函数(除析构外的任何函数)执行该操作。
条款9:绝不在构造和析构的过程中调用virtual函数
那么在条款7处"大肆"讲了一些面向对象编程语言的特征之一多态,在这里也就不回顾了。直接"上菜"!
Base class构造期间调用的virtual虚函数不再是虚函数
假设一个class继承体系。模拟塑膜股市交易,买进、卖出的订单等等。每当创建一个交易对象时,我们在审计日志(logTransaction)创建一笔适当的记录。
class Transaction
{
public:
Transaction();//交易的base class
virtual void logTransacion() const = 0; //设计为纯虚函数,任何对象都得去实现这个函数
};
Transaction::Transaction()
{
//...
logTransacion();
}
void Transaction::logTransacion()const
{
std::cout << "Base class" << std::endl;
}
class BuyTransaction :public Transaction
{
public:
virtual void logTransacion() const;
};
void BuyTransaction::logTransacion()const
{
std::cout << "derived class" << std::endl;
}
int main()
{
//我们创建对象b 会发生什么?
BuyTransaction b;
return 0;
}
取自《Effictive C++》此时,我们创建b。我们预想b的构造过程时,首先调用Transaction中的构造函数,完成继承下来的那部分成员的初始化,其次再是调用BuyTransaction中的构造函数,完成该类成员变量的初始化工作。
"derived class对象内的base class成分会在derived class自身成分构造之前先构造妥当。"
惊奇的点来了!base class中的最后一行调用了logTransaction这个纯虚函数。这个时候被调用的版本应该是Transaction中的而非BuyTransaction中的——即便你的BuyTransaction对象即将建立。为此,base class构造期间的virtual函数不再是virtual函数。
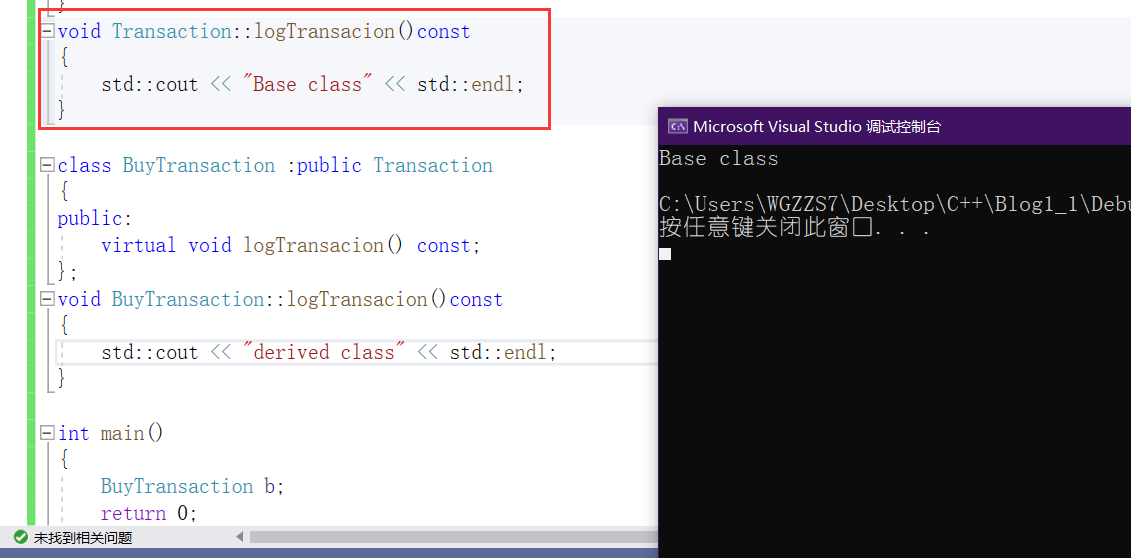
这个似乎反直觉的行为有一个好的理由:
"base class成分的构造始终优先derived class的成分,如果此期间调用的virtual函数下降至derived class阶层,要知道derived class的函数几乎必然取用local成员变量,而那些变量还没有完成初始化呢,'使用对象内部尚未初始化的部分',C++不会让你走这条路的"。
另外一个更根本的原因在于是:
"derived class在base class调用期间,它的this指针的类型是base class。这很符合我们的习惯,即是什么类,调用什么类的成员方法。编译器包括运行期间的类型信息,都会将这个对象视为base class(这个是C++对待次成分的态度)。因为在它们未完成初始化之前使用是不安全的,而对待它们最安全的做法就是无视它们的存在。即,derived class再为构造函数开始前,不会成为一个derived 对象。"
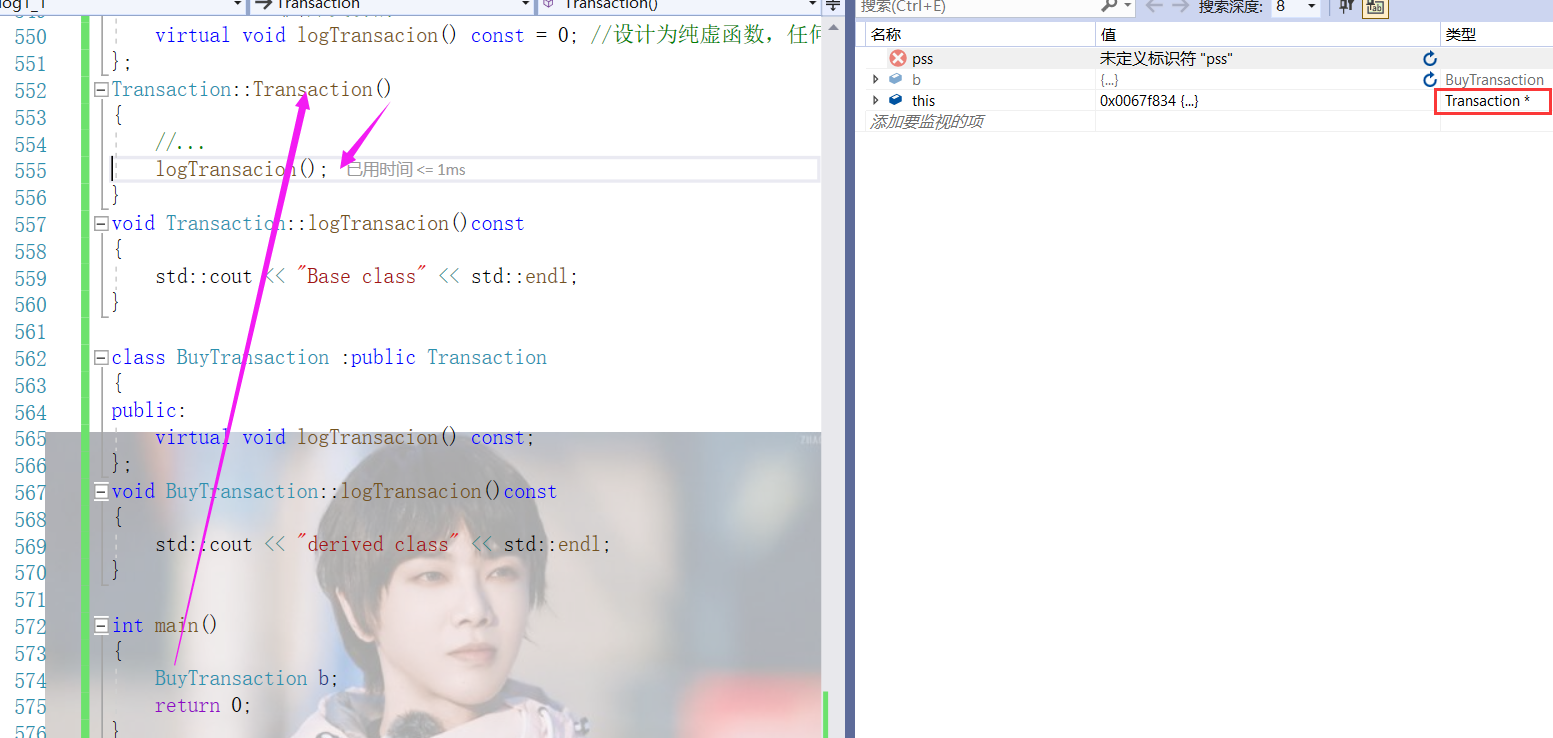
"这样同样适用于析构函数,当derived的析构函数被执行时,对象内的成员变量便呈现未定义值,当调用base class的析构函数时,则会无视它们的存在。"

实例中,就看到代码违反了本条款。在Transaction构造中直接调用了虚函数。logTransacion其实是在Transaction中定义的纯虚函数,除非它被定义(不太有希望,也有可能),所以对于BuyTransaction对象的建立,甚至无法成功(如果这里没有定义logTransaction的话,因为连接器找不到其实现的代码)。
构造信息向上传递
但是,并非所有的"构造函数或析构函数运行期间是否调用虚函数"都会被检测出来。我们对代码改一改。让构造时一些重复代码写进在init()中完成。
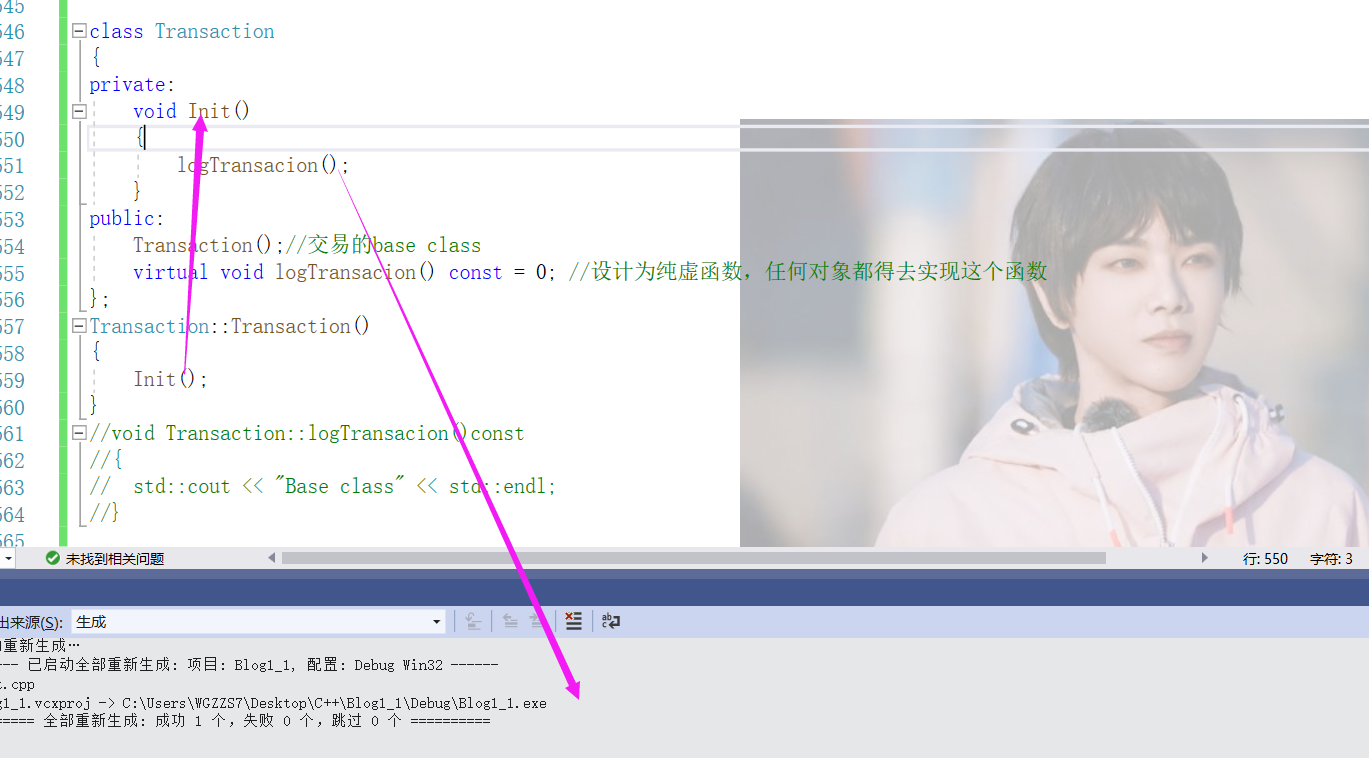
这份代码比刚刚那个编译时,编译器发出的埋怨更含蓄,且暗中危害。
此时logTransaction是Transaction中的纯虚函数,此时运行起来,程序会直接给终止掉。
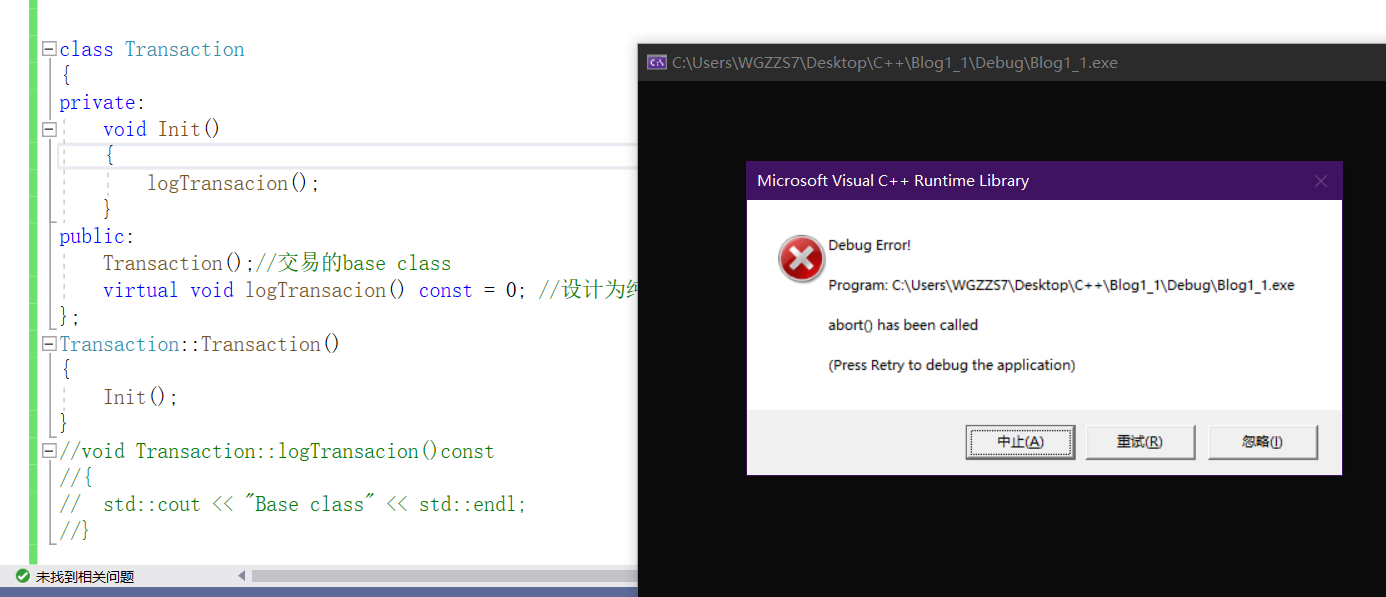
如果这个logTransaction是个正常的虚函数(不是纯虚函数),那么它就会被正常调用。

唯独让你弄不清头脑的是,此时却调用的是base class里的logTransaction。
唯一能够避免此做法的是:
"确定你的构造函数与析构函数(对象创建与销毁期间)中都没有调用virtual虚函数,而他们调用的所有函数都服从同一约束。"
因此,你无法保证在Transaction这个基础体系上,创建的对象,就会调用其对应的logTransaction对应的版本。显然,在构造函数里调用virutal是个错误的做法。
其他方法可以解决这个问题,就是把logTransaction在Transaction中不要设计为virtual,要求派生类传递必要的信息给基类,然后那个构造函数安全地调用 non-virtual logTransaction。
class Transaction
{
public:
explicit Transaction(const std::string & loginfo);
void logTransacion(const std::string& loginfo) const; //non-virtual
};
Transaction::Transaction(const std::string& loginfo)
{
logTransacion(loginfo);
}
void Transaction::logTransacion(const std::string& logoinfo)const
{
std::cout << "logoinfo: " << logoinfo << std::endl;
}
class BuyTransaction:public Transaction
{
public:
BuyTransaction(std::string& parametrs)
:Transaction(createLogString(parametrs)) //通过函数构造logoinfo信息 因为是静态所以不需要this指针的传递
{
std::cout << "BuyTransaction: " << ¶metrs << std::endl;
}
private:
//令函数为静态函数
static std::string createLogString(std::string& parametrs)
{
loginfo = parametrs;
return loginfo;
}
static std::string loginfo;
};
std::string BuyTransaction::loginfo;
取自《Effictive C++》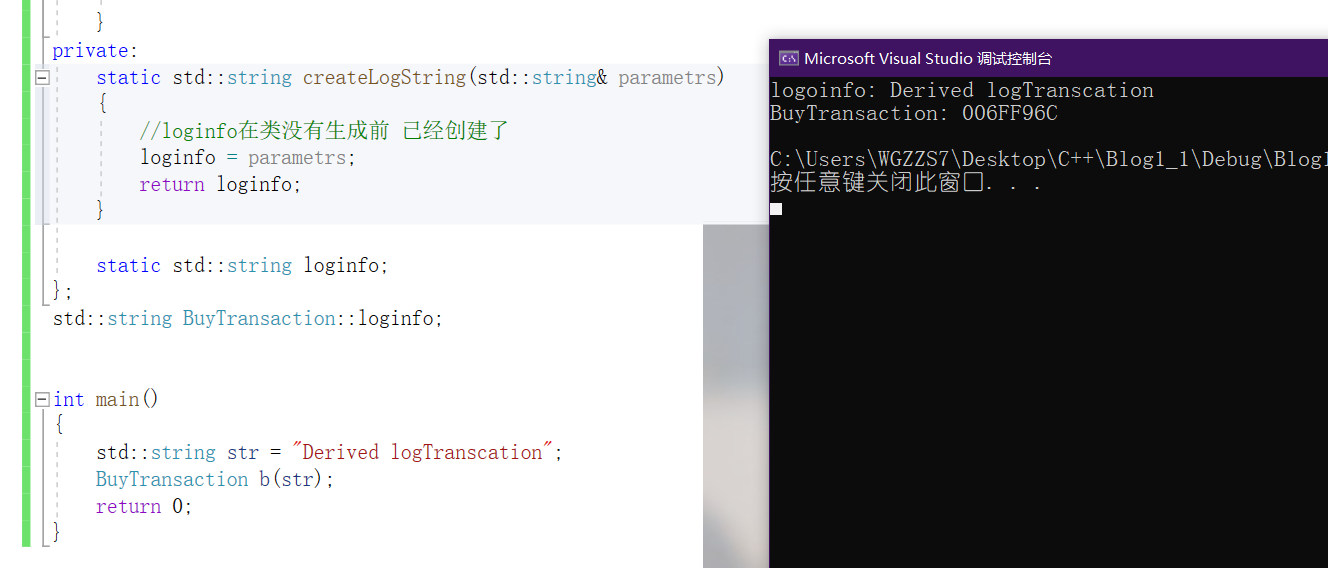
一定程度上,"令derived class将必要的构造信息传递给base class至构造函数。",进行替换加以弥补。
注意:
这里的createLogString这里令函数static为,也就不可能意外指向"初期未成熟之BuyTransaction对象内部尚未初始化的成员变量。"正是因为那些"成员变量处于未定义的状态",所以"在base class构造析构期间调用virutal函数不可下降至derived class。"
请记住:
在构造和析构函数期间不要调用virtual函数,因为这类调用从不下将至derived class(比起当前执行构造与析构函数的那一层)。
条款10:令operator=返回一个reference to *this
关于赋值,你可以写成如下的两个形式;
int x,y,z;
//1.
x = 10;
y = 10;
z = 10;
//2.赋值的连锁形式
x = y = z = 10;
取自《Effictive C++》此时,赋值会采用右结合的规律,可以将上述的赋值连锁形式改写为"x=(y=(z=10));"。z首先被10进行初始化,y再作为接收方,接收更新后的z的值,同理x也是在这样。上面的例子,是针对内置类型。我们是自定义的类,是否支持这样的"连锁形式"赋值?一定支持!
因为运算符(operator)重载的本质就是方便自定义类型像内置类型一样进行操作。
为了实现"连锁赋值",赋值运算操作符必须返回一个指向操作符左侧实参的reference。(这被归为是一种协议)。"当然,协议是可以不遵守的"。
class Widget
{
public:
//...
//返回类型是一个 操作符左侧的对象
Widget& operator=(const Widget& ref)
{
//...
//返回对象
return *this;
}
};
取自《Effictive C++》这个协议不仅仅适用于=,比如"+=","-=","*="。
class Widget
{
public:
//...
//返回类型是一个 操作符左侧的对象
Widget& operator=(const Widget& ref)
{
//...
//返回对象
return *this;
}
Widget& operator+=(const Widget& ref)
{
//..
return *this;
}
Widget& operator-=(const Widget& ref)
{
//..
return *this;
}
Widget& operator*=(const Widget& ref)
{
//..
return *this;
}
};
取自《Effictive C++》请记住:
这只是一个协议。不过STL里的容器如vector\set\map\shared_ptr,包括很早之前的string类,都共同遵守这个。
令赋值(assignment)操作符返回一个 reference to *this。
条款11:在operator=中处理"自我赋值"
class Widget
{
//..
};
int main()
{
//自我赋值
Widget w;
w = w;
//当i\j相同时 他们访问的是一个位置
int arr[10];
int i, j;
a[i] = a[j];
//潜在的自我赋值
int* px, * py;
*px = *py;
return 0;
}别名;
大千世界无奇不有,"自我赋值"是合法的,虽然看起来,这样的做法很蠢。
px,py这种潜在的自我赋值,造成这样的结果的原因在于"别名(alias)"。即,有一个或者多个方法指向某个对象。
一般而言,这种情况的 出现,必然伴随着一段代码操作pointer或者reference,指向“多个相同类型的对象”。甚至,两个对象来自同一个继承体系,即使不是同一个类型 ,也可以造成"别名"的情况。
class Base {
//....
};
class Derived :public Base {
//...
};
//此时rb pd 接收的可能是同一个对象
void DoSomething(Base& rb,const Derived* pd)
{
}
int main()
{
Derived d1;
DoSomething(d1,&d1);
return 0;
}
取自《Effictive C++》自我赋值安全性;
假设我们需要建立一个class管理一个指针,它动态分配后指向的一块位图。
class BitMap {
//..
};
class Widget {
//..
public:
Widget& operator=(const Widget & ref)
{
delete pm; //停止使用当前的bitmap
pm = new BitMap(*ref.pm); //使用ref's 的bitmap
return *this; //不解释
}
private:
BitMap* pm;
};
取自《Effictive C++》乍一看,感觉这份赋值运算符重载没什么问题。先delete这个对象管理的 bitmap,再去管理ref中的bitmap。但是,如果ref 与 this是同一个对象呢? 第一行已经销毁了ref中的bitmap,但是函数走到了最后,却出现,一个指针指向一个已经被释放掉的资源。
证同测试;
解决这个自我赋值安全性问题的方法之一是,在函数的最前面进行"证同测试"。像这样:
class BitMap {
//..
};
class Widget {
//..
public:
Widget& operator=(const Widget & ref)
{
//"证同测试"
if (this == &ref) return *this;
delete pm;
pm = new BitMap(*ref.pm);
return *this;
}
private:
BitMap* pm;
};
取自《Effictive C++》异常安全性;
我们很好地躲过了,由自身赋值对代码安全性造成的潜在危害吗,但这并不意味着并不存在其他程序安全的隐患。
如果"new BitMap"导致异常(要么是分配内存不足,或者BitMap的copy出了问题),this中的pm仍然持有之前已经销毁掉的bitmap的地址。你无法真正地安全删除它。造成这样隐患的原因是,过早对原指针进行了delete。
class BitMap {
//..
};
class Widget {
//..
public:
Widget& operator=(const Widget & ref)
{
BitMap* pOrig = pm; //记住原来的pm
pm = new BitMap(*ref.pm); //令pb 指向ref.pb的空间
//此时如果没有抛异常 那么正常释放原来的空间
delete pOrig;
return *this;
}
private:
BitMap* pm;
};
取自《Effictive C++》此时,我们解决了遇到异常的情况下,存在的程序安全问题。即便此时没有"同证测试",我们时候首先保存了一份bitmap的复件,然后指向新制造bitmap的那个复件,再删除了原来的bitmap。
这种通过解决"异常安全性",进而又解决了"自我赋值安全性"的麻烦,也使得越来越多人更倾向在前者的设计上下功夫。
copy and swap方案;
class BitMap {
//..
};
class Widget {
//..
public:
void swap(Widget& ref) //交换函数
{}
//1.
Widget& operator=(const Widget & ref)
{
//拷贝构造
Widget temp(ref); //ref副本做给temp
swap(temp); //temp与this的数据交换
return *this;
}
//传参发生的拷贝构造(pass by value)
Widget& operator=(Widget ref)
{
swap(ref);
return *this;
}
private:
BitMap* pm;
};
取自《Effictive C++》这个动作十分地精巧简洁,即使它付出的代价是清晰性降低了。但它不仅仅解决了自我赋值与异常安全的问题,并且将"copying"动作从函数体内移至到"参数构造阶段",令编译器生成更高效的代码。
请记住:
确保当前对象自我赋值时,operator= 有良好的行为。其中技术包括比较"来源对象"与"目标地址"、精心周到的语句顺序、以及copy-and-swap。
确定任何函数如果操作一个以上的对象,而其中多个对象是同一个对象时,仍然是正确的。
条款12:复制对象时勿忘其每一个成分
学完类和对象,我们都知道编译器会为我们类生成六个默认成员函数(前提是我们未进行声明)。它copy构造函数与assignment操作符的行为:将被拷贝对象的所有成员变量都做一份拷贝。
我们举一个顾客的例子,用class来表现。其中,我们手动声明copy函数,并实现一个log函数打印调用信息。
class Customer {
public:
//....
Customer(const Customer& ref)
:name(ref.name)
{
logCall("Customer copy constructor!");
}
Customer& operator=(const Customer& ref)
{
logCall("Customer copy assginment operator!");
name = ref.name;
return *this;
}
private:
std::string name;
};
取自《Effictive C++》我们手动为这个顾客类写了copy构造函数,assignment操作符重载。
此时,我们为这个类增添一个成员变量Date,很显然,增加一个成员变量,必然需要完善copy构造与assignment 操作符重载。
class Date
{};
class Customer {
public:
//....
Customer(const Customer& ref)
:name(ref.name)
{
logCall("Customer copy constructor!");
}
Customer& operator=(const Customer& ref)
{
logCall("Customer copy assginment operator!");
name = ref.name;
return *this;
}
private:
std::string name;
Date lastTransaction;
};
取自《Effictive C++》就算编译器不提醒你(也许是一种"复仇"表现,因为你不让它为你生成copy与assignment),这个隐患,终会在继承时,暴露出来。
class PriorityCustomer :public Customer
{
public:
//....
PriorityCustomer(const PriorityCustomer& ref)
:priority(ref.priority)
{
logCall("PriorityCustomer copy constructor");
}
PriorityCustomer& operator=(const PriorityCustomer& ref)
{
logCall("PriorityCustomer copy assignment operator");
priority = ref.priority;
return *this;
}
private:
int priority;
};
取自《Effictive C++》看看PriorityCustomer中的copy构造函数,好像对ref的成员完成了拷贝。然而,你再多看一眼,它仅仅拷贝 了ref中的成员变量,但是ref通过继承下来的成员变量,并没有进行拷贝!
copy构造也是构造函数,编译器不会再为你生成默认无参的构造函数!子类要初始化父类继承下来的对象,需要手动调用父类的构造函数,而Customer并没有合适的构造函数!
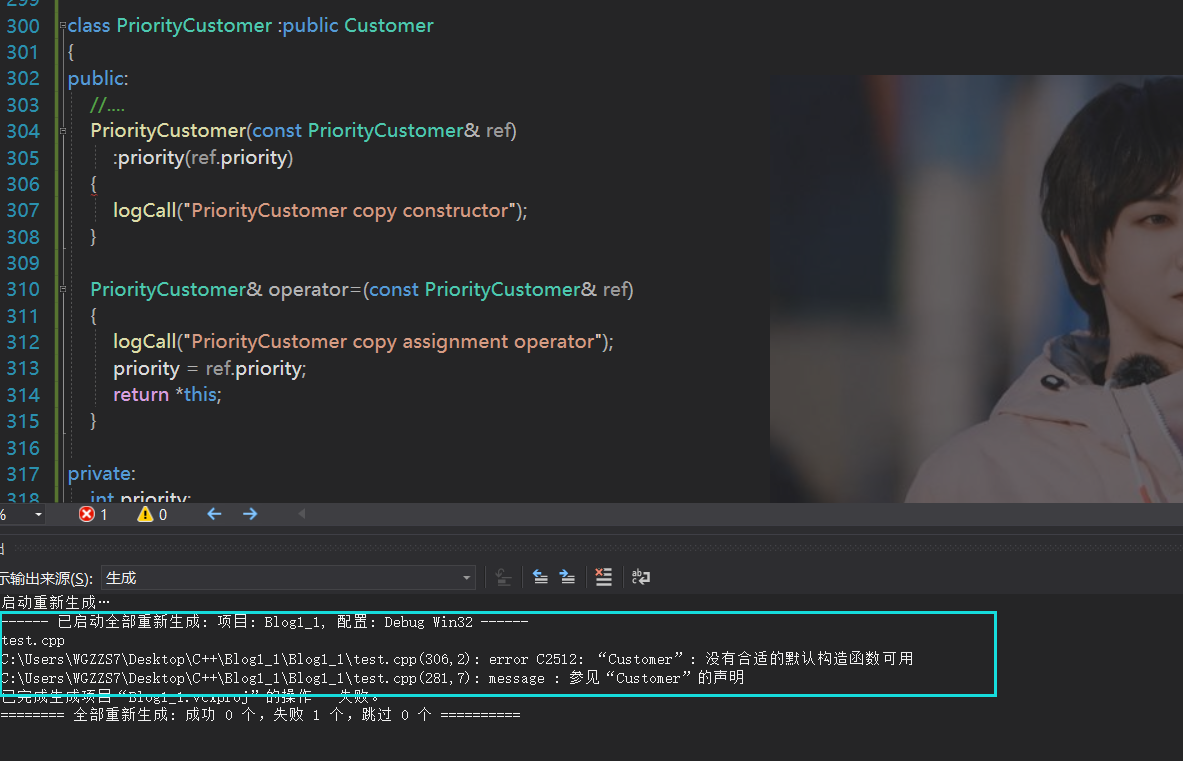
PriorityCustomer中的copy构造函数没有指定实参传给Customer初始化(即在初始化列表里)。换言之,如果PriorityCustomer中的Customer部分需要"不带参地"被Customer初始化,必然需要存在一个default构造函数!
但是,这对待assignment 操作符重载有些轻微不同。因为它不曾修改base class中的成员变量,那些变量也可以保持不变。
对于上述的解决方法,无非要求我们小心对待存在与derived class 里的base class部分。那些成员往往是private,derived class无法直接进行访问它们,为此你需要在derived class中的copy构造函数中显示调用base class对应的函数。
class PriorityCustomer :public Customer
{
public:
//....
PriorityCustomer(const PriorityCustomer& ref)
:Customer(ref), //切片 父类类型的指针、引用的对象 可以是子类对象!
priority(ref.priority)
{
logCall("PriorityCustomer copy constructor");
}
PriorityCustomer& operator=(const PriorityCustomer& ref)
{
logCall("PriorityCustomer copy assignment operator");
//显示调用operator= 不指定类域,会循环调用当前类里面的 operator
Customer::operator=(ref);
priority = ref.priority;
return *this;
}
private:
int priority;
};
取自《Effictive C++》切片;

copy构造 vs assignment操作符;
"如果你发现你的copy构造与assignment操作符有着极其相近似的代码。消除代码重复的方法是,建立一个新的成员函数,供它们两者调用,这样的函数通常被设置private,且被命名为init。"
copy构造函数针对的是未尚未构造初始化好的对象赋值。assignment操作符针对的是已经构造并初始化好的两个对象之间的操作。

请记住:
Copying函数应该确保复制"对象内的所有成员变量"及其"base class里的成分"
不要尝试让某个class里的 两个copying函数去互相调用。应该将这两者共同的代码成分,放在第三个函数中,供两者调用。
本篇的内容也就到此为止了,感谢你的阅读。
祝你好运,向阳而生~