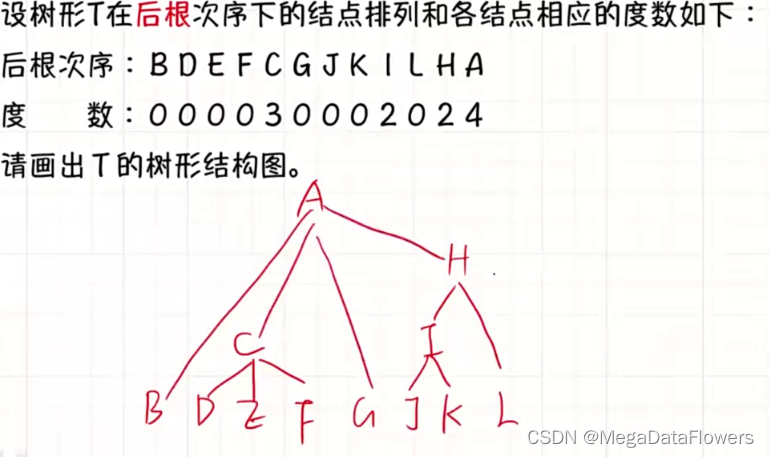
本文是openmmlab AI实战营的第二次课程的笔记,以下是我比较关注的部分。
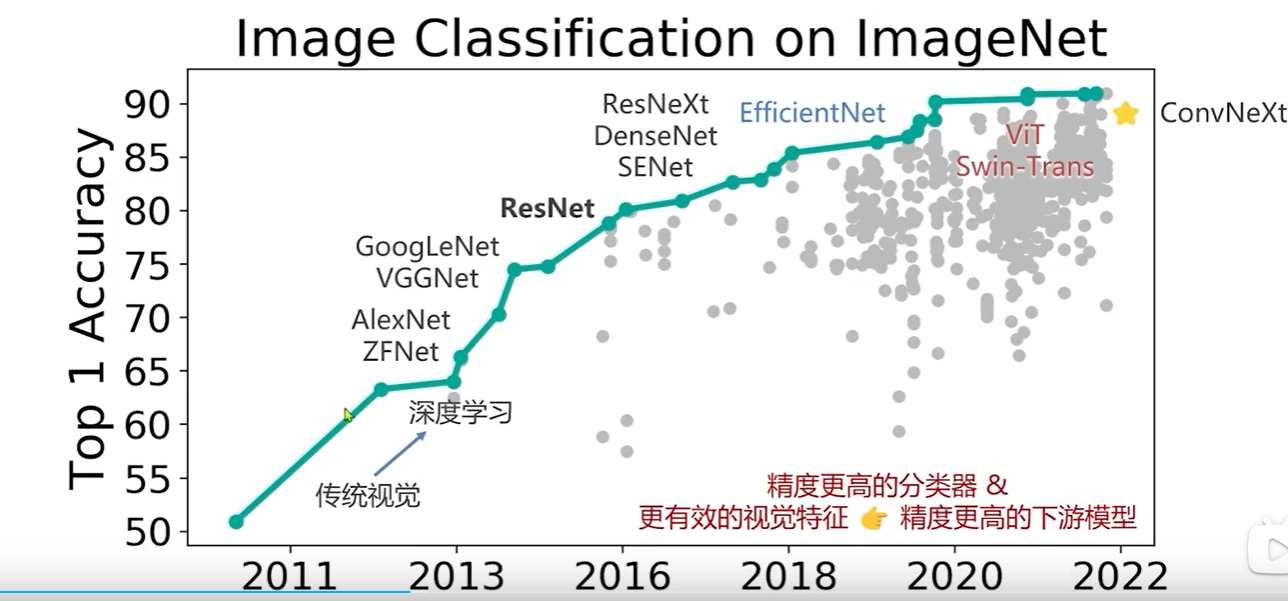
在图像分类任务上,视觉基础模型的发展,最新的是convNeXt。
convNeXt : 返璞归真,将Swin Transformer 的模型元素迁移到卷积网络中,性能反超Transformer
他更好的一个事情就是,卷积在视觉领域已经做了很多年了,包括很多工程问题,一些算法,一些硬件,很多都对卷积进行了优化,突然换到transformer 可能有些工作是需要重来的。下图为在图像分类任务上视觉基础模型的发展:
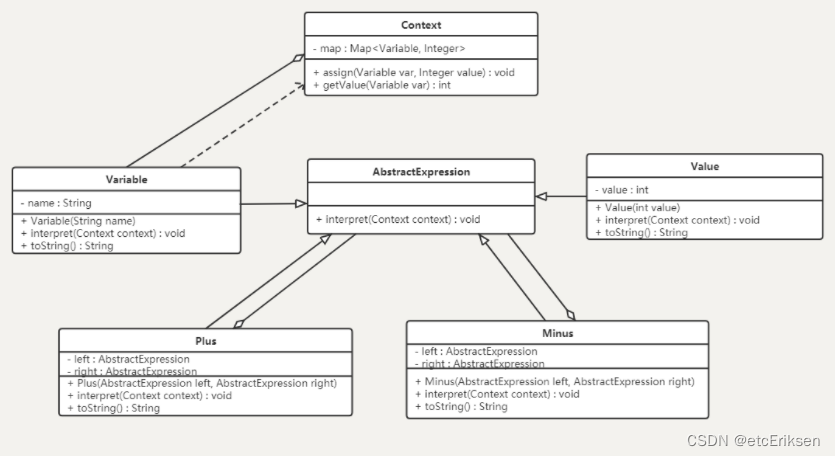
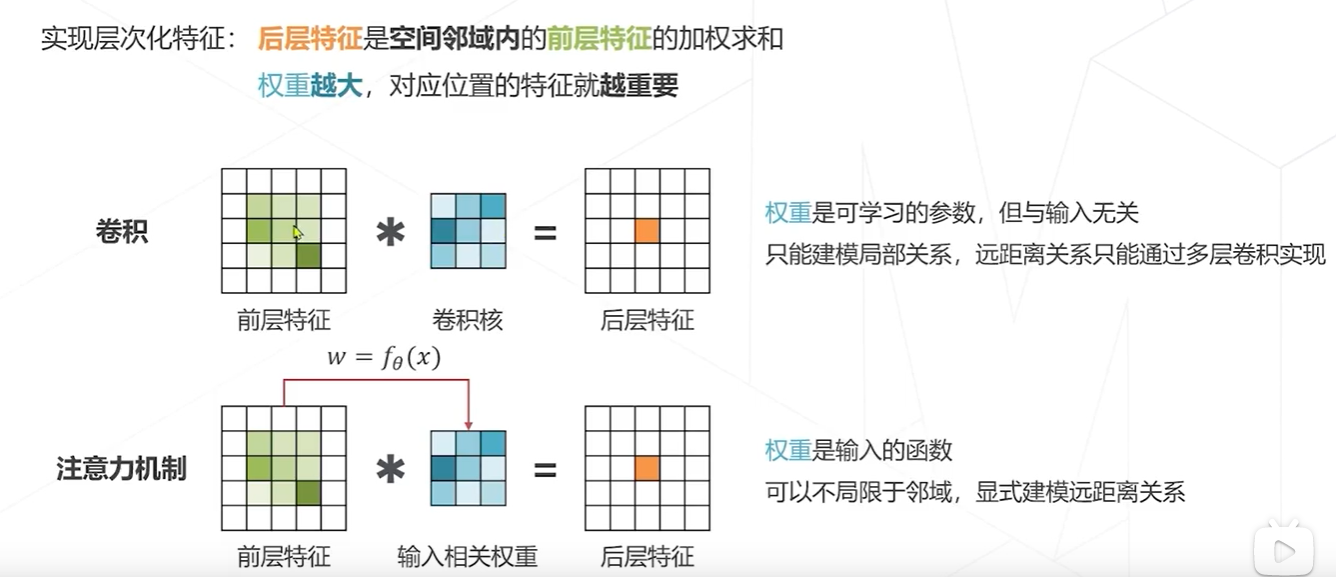
卷积和transformer的区别
卷积里面最关键的计算是卷积, 而在transformer中他的一个基本的计算单元叫注意力机制,卷积是用一个卷积核对前一层的特征加权求和,得到后一层的特征,卷积核对输入来说是一个常数,无论用一个什么样的图片都是一个3*3的卷积核来卷,而且卷积有一个局部的限制
transformer ,本省意义没变,权重越大,特征越重要,在注意力机制里面,特征是一个输入的函数,就是说不同的图像,这个特征怎么去组合,事实上跟你输入的是什么有关系,可以不限于领域,它可以在全局中查找,谁有用就给他拽过来,融入到自己的特征里面,形成下一层特征 。
学习率和优化器
通常进行随机的初始化
朴素方法:依照均匀分布或高斯分布
XAVIER
KAMING
如果有预训练模型的话,可以基于预训练模型进行权重初始化,可以达到更好的预训练速度。
学习率对训练是非常重要的

给两个建议:

还有几点优化,我这里没有列出,内容较多
无监督学习建议玩的 代码库 MMSelfSup
MMSelfSup
基于 PyTorch 的自监督学习工具箱和测试基准
多种自监督算法集成
标准化的性能评测
强大的MM系列兼容性及丰富的下游任务
我想玩玩无监督学习,自豪兄大佬,给的建议,在openMMLab上。