实例(Instance)是 KubeBlocks 中的基本单元,它由一个 Pod 和若干其它辅助对象组成。为了容易理解,你可以先把它简化为一个 Pod,下文中将统一使用实例这个名字。
InstanceSet 是一个通用 Workload API,负责管理一组实例。KubeBlocks 中所有的 Workload 最终都通过 InstanceSet 进行管理。
相比于 K8s 原生的 StatefulSet、Deployment 等 Workload API,InstanceSet 加入了更多数据库领域相关特性的考虑和设计,比如角色、高可用等,使得其在支持数据库等有复杂状态的 Workload 上,具备更强的能力。
使用 InstanceSet
InstanceSet 为其管理的每一个实例生成一个固定的名字,并会生成一个 Headless Service,从而使得每一个实例都有一个固定的网络标识。基于该标识,属于同一个 InstanceSet 的实例可以相互发现对方,属于同一个 Kubernetes 集群中的其它系统也可以发现该 InstanceSet 下的每个实例。
InstanceSet 通过 VolumeClaimTemplates 为每个实例生成固定标识的存储卷(Volume),其它实例或系统可以通过实例的固定标识找到实例,进而进一步访问到存储卷里的数据。
在进行更新时,InstanceSet 支持按照确定性顺序对所有实例进行滚动更新(RollingUpdate),并且可配置滚动更新的多种行为。
类似的,在进行水平扩缩容时,InstanceSet 会按照确定性的顺序进行添加或删除实例操作。
在这些基础特性之上,InstanceSet 针对数据库高可用等需求,进一步支持了原地更新、实例模板、指定实例下线、基于角色的服务、基于角色的更新策略等特性。
下面对这些特性做进一步说明。
实例名称如何生成
InstanceSet 通过实例模板渲染实例对象,渲染的实例数量通过 Replicas 字段进行控制。
apiVersion: workloads.kubeblocks.io/v1alpha1
kind: InstanceSet
metadata:
name: mydb
spec:
replicas: 3
template:
spec:
terminationGracePeriodSeconds: 10
containers:
- name: mydb
image: registry.kubeblocks.io/mydb:15.1
ports:
- containerPort: 5123
name: db
volumeMounts:
- name: data
mountPath: /var/mydb/
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "my-storage-class"
resources:
requests:
storage: 10Gi
上面这个例子,声明了一个名叫 mydb 的 InstanceSet,它由 3 个实例(replicas=3)构成。每个实例由 template 和 volumeClaimTemplates 组成的实例模板渲染生成。其中 template 用来渲染实例中的 Pod,volumeClaimTemplates 用来渲染实例中的 PVC。
实例名称生成的模式(Pattern)是 $(instanceSet.name)-$(instanceID)。默认情况下,instanceID 为 ordinal,在该示例中,instanceSet.name 为 mydb,ordinal 从 0 开始递增,最终生成的实例名称为:mydb-0,mydb-1,mydb-2。当使用了多实例模板特性时,instanceID 的生成规则将进一步扩展为 $(template.name)-$(ordinal),详细说明可参考实例模板说明文档。
为了提供固定的网络标识,每个 InstanceSet 会生成一个 Headless Service 对象,该 Service 名字的生成模式(Pattern)为 $(instanceSet.name)-headless。在该示例中,最终生成的 Headless Service 的名字为:mydb-headless。通过这样的方式,该 InstanceSet 下的 3 个实例获得了三个固定的网络标识,即:mydb-0.mydb-headless.default.local,mydb-1.mydb-headless.default.local,mydb-2.mydb-headless.default.local。
因为 InstanceSet 名字会成为固定网络标识的组成部分,所以要求该名字必须符合 DNS Label 规范。
如何获取 InstanceSet 下的实例
InstanceSet 在生成二级资源时,会为它们添加两个 Label:workloads.kubeblocks.io/managed-by=InstanceSet 和 workloads.kubeblocks.io/instance=<instanceSet.name>。可通过这两个 label 获取某个 InstanceSet 下的所有二级资源,包括 Pod 和 PVC。
在上面的示例中,获取相应 Pod 的 Label 为:
workloads.kubeblocks.io/managed-by=InstanceSet
workloads.kubeblocks.io/instance=mydb
如果想自定义获取 InstanceSet 下的 Pod 的 Label,可通过设置 spec.selector 字段实现。例如:
apiVersion: workloads.kubeblocks.io/v1alpha1
kind: InstanceSet
metadata:
name: mydb
spec:
selector:
matchLabels:
db: mydb
通过 spec.selector 设置的 MatchLabels 将被自动添加到 InstanceSet 所生成的 Pod 上。
实例创建与销毁
默认情况下,InstanceSet 会按照 Ordinal 从小到大的顺序依次生成实例。在创建一个新的实例时,会先等前一个实例中的 Pod 处于 Ready 状态。
实例销毁时,会按照相反的顺序进行。在销毁一个实例前,会先等该实例中的 Pod 处于 Ready 状态,这里主要的考虑是,如果一个 Pod 没有处于 Ready 状态,其所挂载的 PVC 中的数据可能已经存在问题,在确保数据修复前,InstanceSet 不会做进一步动作。
InstanceSet 新建和水平扩容时,会采用上述实例创建逻辑,水平缩容时,会采用上述实例销毁逻辑。
同时 InstanceSet 支持通过 spec.podManagementPolicy 设置实例创建和销毁策略,目前支持 Ordered (即默认策略)和 Parallel 两种策略。Parallel 是指会采取并行的方式进行实例创建或销毁。
指定实例缩容
有些场景下,需要在缩容时销毁特定实例。
比如,某个 Node 因所在物理机故障需要下线,该 Node 上所有的实例(Pod)需要销毁。此时可通过指定实例缩容特性,实现销毁该 Node 上的实例的目的。
以前面名字为 mydb 的 InstanceSet 为例,可通过如下方式,实现缩容 Ordinal 为 1 的实例,并保留 Ordinal 为 0 和 2 的实例:
apiVersion: workloads.kubeblocks.io/v1alpha1
kind: InstanceSet
metadata:
name: mydb
spec:
replicas: 2
offlineInstances: ["mydb-1"]
# ...
详细介绍可参考指定实例缩容特性介绍章节。
实例更新
当对实例模板中的字段进行了更新后,InstanceSet 下的所有实例会进行更新操作。
默认情况下,InstanceSet 会按照 Ordinal 从大到小的顺序依次更新每个实例,在更新一个实例前,会先等前序实例已经更新并达到 Ready 状态。
如果是有角色(下面章节会讲)的实例,InstanceSet 会按照角色权重从低到高进行更新,如果实例角色权重相同,则进一步按照 Ordinal 从大到小顺序进行更新。
InstanceSet 支持通过 spec.updateStrategy 配置更多的更新行为,比如通过 spec.UpdateStrategy.rollingUpdate.partition 控制更新的实例总数量,通过 spec.UpdateStrategy.rollingUpdate.maxUnavailable 控制更新期间最大不可用实例数量。详细说明可参考 spec.updateStrategy API 描述。
原地更新(In-place update)
应用系统通常对数据库有很高的可用性要求,通常情况下,Pod 更新实际采取的动作是重建(Recreate),重建 Pod 需要一定的时间,这会导致数据库服务有一段时间不可用。
为了降低更新对数据库服务可用性的影响,InstanceSet 支持了实例原地更新能力,在实例模板中部分字段更新时,InstanceSet 会采用原地更新 Pod 或扩容 PVC 的方式,实现实例更新。
哪些字段支持原地更新
从原理上来讲,InstanceSet 原地更新复用了 Kubernetes Pod API 原地更新能力。所以具体支持的字段如下:
spec.template.metadata.annotationsspec.template.metadata.labelsspec.template.spec.activeDeadlineSecondsspec.template.spec.initContainers[*].imagespec.template.spec.containers[*].imagespec.template.spec.tolerations(只支持新增 Toleration)spec.instances[*].annotationsspec.instances[*].labelsspec.instances[*].image
Kubernetes 从 1.27 版本开始,通过 PodInPlaceVerticalScaling 特性开关可进一步开启对 CPU 和 Memory 的原地更新支持。InstanceSet 会自动探测 Kubernetes 版本和特性开关,并进一步支持如下能力:
对于大于等于 1.27 且 PodInPlaceVerticalScaling 已开启的 Kubernetes,支持如下字段的原地更新:
spec.template.spec.containers[*].resources.requests["cpu"]spec.template.spec.containers[*].resources.requests["memory"]spec.template.spec.containers[*].resources.limits["cpu"]spec.template.spec.containers[*].resources.limits["memory"]spec.instances[*].resources.requests["cpu"]spec.instances[*].resources.requests["memory"]spec.instances[*].resources.limits["cpu"]spec.instances[*].resources.limits["memory"]
对于 PVC,InstanceSet 同样复用 PVC API 的能力,仅支持 Volume 的扩容。
详细介绍可以参考原地更新特性介绍章节。
实例模板
默认情况下,InstanceSet 通过同一个模板生成所有的实例。
部分场景下,同一个 InstanceSet 中,需要有不同设置的实例,比如不同的资源配置或环境变量。InstanceSet 支持在默认实例模板基础上,定义更多实例模板,以便满足此类需求。
仍以前文中名称为 mydb 的 InstanceSet 为例,如果要将其配置为一个大规格主实例、两个小规格从实例,可通过如下方式实现:
apiVersion: workloads.kubeblocks.io/v1alpha1
kind: InstanceSet
metadata:
name: mydb
spec:
replicas: 3
template:
spec:
terminationGracePeriodSeconds: 10
containers:
- name: mydb
image: registry.kubeblocks.io/mydb:15.1
ports:
- containerPort: 5123
name: db
volumeMounts:
- name: data
mountPath: /var/mydb/
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "my-storage-class"
resources:
requests:
storage: 10Gi
instances:
- name: primary
replicas: 1
resources:
limits:
cpu: 8
memory: 16Gi
- name: secondary
replicas: 2
resources:
limits:
cpu: 4
memory: 8Gi
详细介绍可以参考实例模板特性介绍章节。
角色
大部分数据库系统都支持多实例部署,同时每个实例承担不同的角色,这个角色通常由它们内在的数据复制关系决定。比如 PostgreSQL 中有 Primary、Secondary 角色,etcd 中有 leader、follower、learner等角色。
在一个数据库系统中,不同角色的实例会存在差异。比如在对外提供的服务能力上,通常主节点可以提供读写能力,其它节点提供只读能力。在运维时,按照数据库运维最佳实践,通常先逐个升级备实例,最后升级主实例,在升级主实例前,需要先做一次 switchover,以保证数据的完整性并降低服务不可用时间。
针对这些特点,InstanceSet 中设计了若干与数据库角色相关的特性。
围绕角色相关的功能特性包括角色定义、角色探测、基于角色的服务、基于角色的更新策略等。
角色定义用来描述系统中有几个角色、分别有哪些属性。
角色探测根据配置的探测方法去周期性探测每个实例中的角色,并及时更新到对应实例的 Label 上。
基于每个实例的角色 Label,在 Service 中可以筛选出特定的角色,以便提供相应的服务能力,同时基于实例的角色,在做实例更新时,可基于角色优先级确定实例更新顺序。
角色定义
InstanceSet 可通过 spec.roles 定义所有的角色信息,包括角色名称、读写能力、是否参与选举、是否 Leader 等。
比如 PostgreSQL 数据库可配置如下:
spec:
roles:
- name: "primary"
accessMode: ReadWrite
isLeader: true
- name: "secondary"
accessMode: Readonly
角色探测
InstanceSet 中会预制一个角色探测 Sidecar,该 Sidecar 会根据周期性的执行配置的角色探测脚本,并配合 InstanceSet Controller 最终将角色名称更新到对应的实例 Label 上。
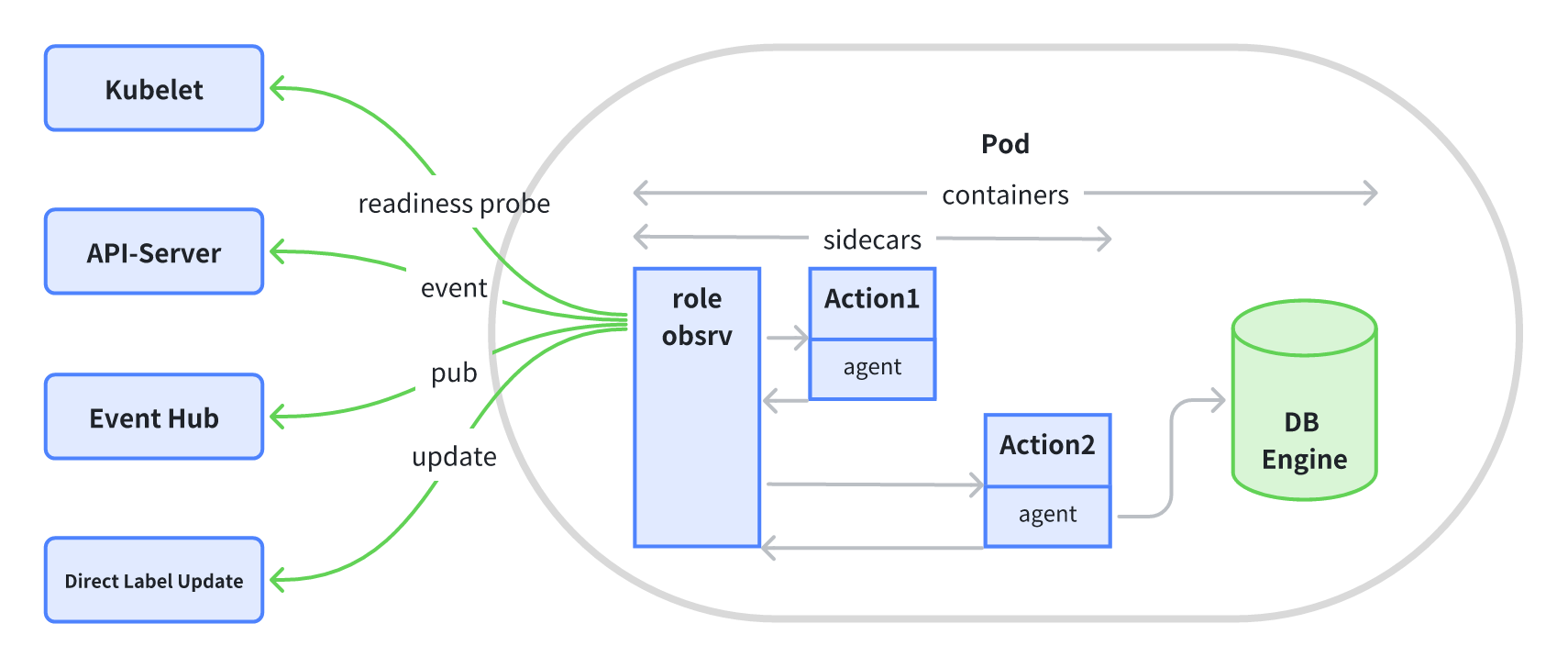
角色探测脚本可通过如下方式配置:
spec:
roleProbe:
customHandler:
- image: probe.kubeblocks.io/sample-probe:1.0
cmd: ["probe"]
args: ["redis"]
periodSeconds: 5
roleUpdateMechanism: DirectAPIServerEventUpdate
该示例中,通过这配置,角色探测 Sidecar 会每隔 5 秒执行一次 sample-probe 镜像中的 probe 命令,并将探测结果封装在 K8s Event 中发给 InstanceSet Controller。InstanceSet Controller 在收到该事件后,会解析出每个实例的角色信息,并更新到到每个实例的角色 Label 上。角色 Label 的格式为:kubeblocks.io/role=<role.name>。同时 InstanceSet Controller 会进一步将角色读写能力也更新到实例 Label 上,格式为:workloads.kubeblocks.io/access-mode=<role.accessMode>。
基于角色的服务
通过配置 Service 中的 Selector,以匹配实例上不同的角色 Label 和读写能力 Label,可以使得该 Service 具备不同的服务能力。
比如 PostgreSQL 的读写服务可配置如下:
apiVersion: v1
kind: Service
metadata:
name: pg-readwrite-svc
spec:
selector:
workloads.kubeblocks.io/managed-by: InstanceSet
workloads.kubeblocks.io/instance: mydb
kubeblocks.io/role: primary
基于角色的更新策略
前文中讲述实例更新时提到,当配置了角色后,InstanceSet 在做更新时会进一步考虑角色的优先级。
具体来说,InstanceSet 通过 spec.memberUpdateStrategy 支持三种角色更新策略:Serial,Parallel,BestEffortParallel。
Serial 即按照角色优先级从低到高依次更新实例。如果两个实例角色优先级相同,则进一步按照 Ordinal 从大到小进行更新。
Parallel 即所有实例并行进行更新,同时遵循 spec.updateStrategy 中的更新策略。
BestEffortParallel 即在保证系统可用的前提下,按照角色优先级从小到大分批进行。更新时同时遵循 spec.updateStrategy 中的更新策略。
大规模实例管理
InstanceSet 最高可管理 10,000 实例,当管理实例数量较多时,可通过 KUBEBLOCKS_RECONCILE_WORKERS 环境变量配置 InstanceSet Controller 的并发工作节点数量,以提高处理速度。
End
KubeBlocks 已发布 v0.9.0!KubeBlocks v0.9.0 全面升级了 API,构建一个 Cluster 更像是在用 Component “搭积木”!新增 topologies 字段,支持多种部署形态。InstanceSet 代替了 StatefulSet 来管理 Pods,支持将指定的 Pod 下线、Pod 原地更新,同时也支持数据库主从架构里主库和从库采用不同的 Pod spec。v0.9.0 还新增了 Reids 集群模式(分片模式),系统的容量、性能以及可用性显著提升!还支持了 MySQL 主备,资源的要求更少,数据复制的开销也更小!快来试试看!
小猿姐诚邀各位体验 KubeBlocks,也欢迎您成为产品的使用者和项目的贡献者。跟我们一起构建云原生数据基础设施吧!
💻 官网: www.kubeblocks.io
🌟 GitHub: https://github.com/apecloud/kubeblocks
🚀 Get started: https://cn.kubeblocks.io/docs/preview/user-docs/try-out-on-playground/try-kubeblocks-on-local-host
关注小猿姐,一起学习更多云原生技术干货。