一,表的创建
语法:


如果创建表没有指定字符集存储引擎,默认是继承表所在的数据库的。
修改表的字段
(1)增加
ALTER TABLE tablename ADD (column datatype [DEFAULT expr][,column datatype]...);

(2)删除
ALTER TABLE tablename MODIfy (column datatype [DEFAULT expr][,column datatype]...);
![]()
(3)修改
ALTER TABLE tablename MODIfy (column datatype [DEFAULT expr][,column datatype]...);

(1)修改表名:![]()
二,插入:insert
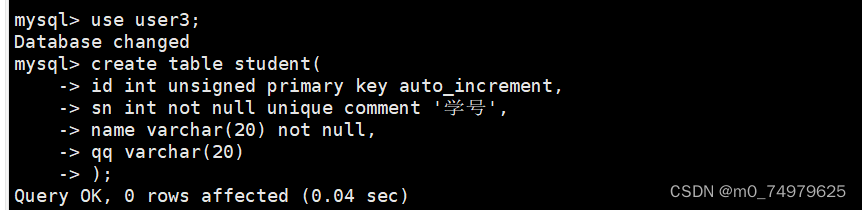
1.单行数据+全列插入。
插入的数据要和表结构的一一对应
![]()

2.多行数据+指定列插入

3.数据冲突插入
插入否则更新
1.如果我们插入的数据和主键或者唯一键,冲突了,就可以使用这个进行冲突数据的更新,有三种情况。
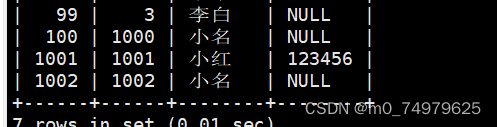
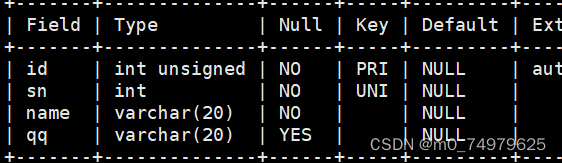
(1)插入的数据和与冲突的数据相同,没有冲突的数据那么就直接插入,插入的数据冲突同时对数据进行更新


没有冲突,直接插入,更新数据无效。
![]()
有冲突,修改了数据。

插入数据冲突同时跟新的数据和原来的一样。
插入替换:emplace
如果插入的数据和主键或者唯一键冲突,那么删除掉这行数据重新插入新的数据。如果没有冲突作用和普通的插入数据一样。
![]()

三,查询:select

1.全列查询
select* from 表名。
2.指定列查询
![]()
3.查询字段为表达式

如果指明名字,那么使用默认的比如(math+1),也可以指定名字 (as可省略)
![]()

3.去重:distinct
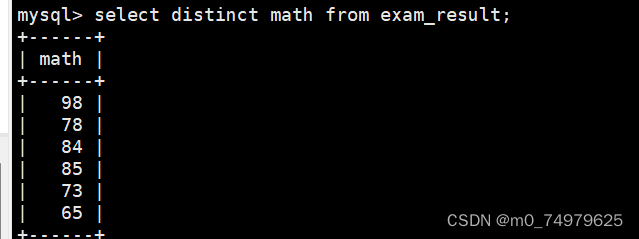
4.where:条件查询
除了常见:运算符
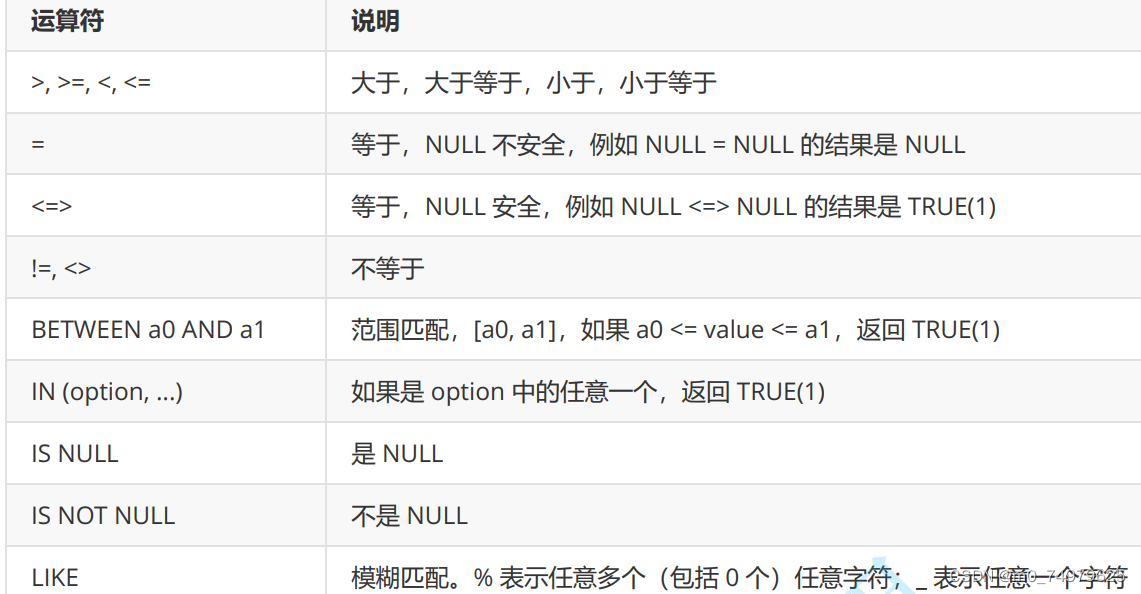 逻辑运算符:and, or, not.
逻辑运算符:and, or, not.
排序:
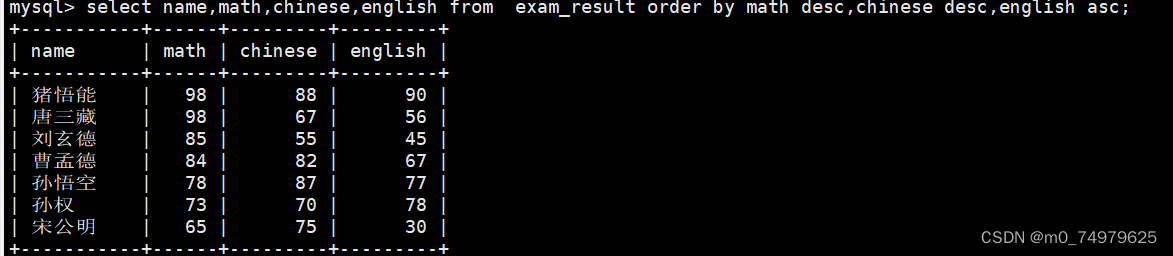
1.升序:asc 降序:desc 默认是升序。
例子:数学降序,语文降序,英语升序
注意:如果是数据是NULL,怎么排序。NULL比任何值都小,按降序是在最前面的。
例子:在order中可以使用表达式,也可以使用我们定义的列别名total,
在where中我们不可以使用,这是因为执行顺序的不同,where是先执行的,这时表里面并没有total.而order by 中可以使用,因为order by 是筛选完后的结果,进行排序显示,靠后执行的。
![]()
![]()
例子:![]()

筛选分页查询
为什么要筛选分页查询:如果表中的数据过大,全部查询就会造成数据库卡死。
用法:它们的执行顺序是 where----order by-----limit/limit offset
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n -- 从 0 开始,筛选 n 条结果 SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n; -- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
1.limit m,n.这个代表从m行开始,显示n行。没有写m,默认从第一行开始
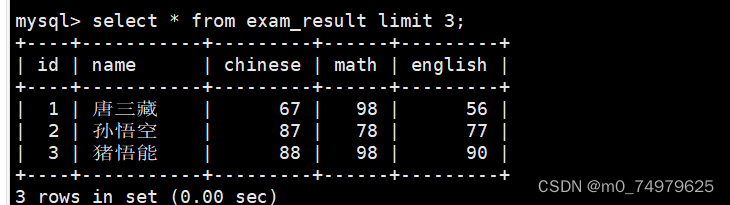
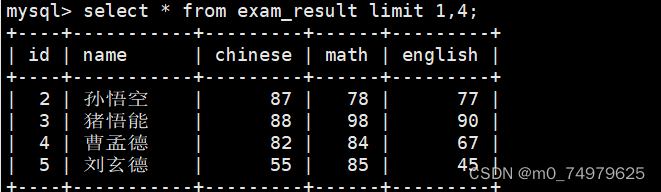
2.limit n offset m。这代表,从m行开始显示n行。第三行开始显示一行,就是第四行

四,修改:Update:
语法:
UPDATE table_name SET column = expr [, column = expr ...][WHERE ...] [ORDER BY ...] [LIMIT ...]
注意:update 后面跟的是表名。
(1)修改表的一部分
修改孙悟空的数学成绩,带上where条件筛选,不然所有的数学成绩都被修改了。需要注意的是等号的右边是表达式,不支持c语言:math+=1000这样的。
![]()
也可以更改多个 。

(2)修改全表
这个要小心使用:

五,删除:delete
1.删除表行数据:
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
2 删除整张表数据:
delete from +表名