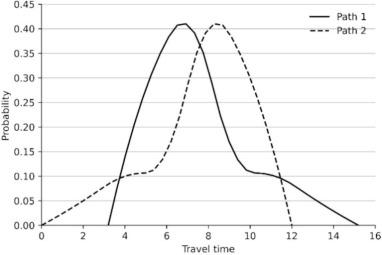
以下代码的每个函数功能都做了注释,分别用python和c++代码做了具体的实现,不是最终效果,后续会继续优化。以下代码中,python代码在每个步骤处理完数据后都画了散点图显示了处理后的数据效果,c++代码是从python代码翻译过来的,没有显示数据处理后的散点图效果。
1.python代码
import pandas as pd
# coding=utf-8
import matplotlib.pyplot as plt
import numpy as np
ss = [[0.03419, -89.31, 118.5], [0.05676, -67.16, 118.5], [0.07927, -44.99, 118.5],
[0.10172, -22.84, 118.5], [0.12393, 0.0, 118.5], [0.14626, 21.5, 118.5],
[0.1683, 43.66, 118.5], [0.19008, 65.81, 118.5], [0.212, 87.97, 118.5],
[0.03801, -89.32, 118.5], [0.06058, -67.16, 118.5], [0.08309, -45.0, 118.5],
[0.10551, -22.84, 118.5], [0.12773, 0.0, 118.5], [0.15002, 21.49, 118.5],
[0.17206, 43.65, 118.5], [0.19395, 65.82, 118.5], [0.21562, 87.97, 118.5],
[0.04185, -89.32, 118.5], [0.06441, -67.16, 118.5], [0.08692, -44.99, 118.5],
[0.10931, -22.83, 118.5], [0.1315, 0.0, 118.5], [0.15376, 21.49, 118.5],
[0.17581, 43.65, 118.5], [0.19769, 65.81, 118.5], [0.21932, 87.96, 118.5],
[0.04569, -89.32, 118.5], [0.06825, -67.16, 118.5], [0.09073, -45.0, 118.5],
[0.11312, -22.84, 118.5], [0.1353, 0.0, 118.5], [0.15755, 21.49, 118.5],
[0.17953, 43.65, 118.5], [0.20137, 65.81, 118.5], [0.2229, 87.97, 118.5],
[0.04953, -89.32, 118.5], [0.07206, -67.16, 118.5], [0.09452, -44.99, 118.5],
[0.11692, -22.83, 118.5], [0.13905, 0.0, 118.5], [0.16129, 21.49, 118.5],
[0.18325, 43.65, 118.5], [0.20504, 65.81, 118.5], [0.22667, 87.97, 118.5],
[0.05336, -89.32, 118.5], [0.0759, -67.16, 118.5], [0.09835, -45.0, 118.5],
[0.1207, -22.84, 118.5], [0.14282, 0.0, 118.5], [0.16502, 21.49, 118.5],
[0.18697, 43.66, 118.5], [0.20875, 65.81, 118.5], [0.23025, 87.96, 118.5],
[0.05718, -89.32, 118.5], [0.07971, -67.16, 118.5], [0.10214, -44.99, 118.5],
[0.1245, -22.83, 118.5], [0.14656, 0.0, 118.5], [0.16878, 21.49, 118.5],
[0.19066, 43.65, 118.5], [0.21238, 65.82, 118.5], [0.2339, 87.97, 118.5],]
# 0~63的数据对齐,投影成直线
classes_index = {
"0": 0, "9": 1, "18": 2, "27": 3, "36": 4, "45": 5, "54": 6,
"1": 7, "10": 8, "19": 9, "28": 10, "37": 11, "46": 12, "55": 13,
"2": 14, "11": 15, "20": 16, "29": 17, "38": 18, "47": 19, "56": 20,
"3": 21, "12": 22, "21": 23, "30": 24, "39": 25, "48": 26, "57": 27,
"4": 28, "13": 29, "22": 30, "31": 31, "40": 32, "49": 33, "58": 34,
"5": 35, "14": 36, "23": 37, "32": 38, "41": 39, "50": 40, "59": 41,
"6": 42, "15": 43, "24": 44, "33": 45, "42": 46, "51": 47, "60": 48,
"7": 49, "16": 50, "25": 51, "34": 52, "43": 53, "52": 54, "61": 55,
"8": 56, "17": 57, "26": 58, "35": 59, "44": 60, "53": 61, "62": 62,
}
colors = ['black', 'green', 'red', 'fuchsia', 'aqua', 'orange', 'pink', 'green','red', 'yellow', 'green',
'aqua', 'orange', 'red', 'fuchsia', 'yellow', 'aqua', 'orange', 'green', 'red', 'yellow']
# 1. 读取数据,提取出需要计算的数据
def read_datas(filepath):
with open(filepath, "r", encoding='utf-8') as f: # 打开文件
data = f.readlines() # 读取文件
datas = []
for item in data[16:]: # [16:]
items = item.split("\t")[:63]
items.append(item.split("\t")[70])
items.append(item.split("\t")[66])
items.append(item.split("\t")[67])
items.append(item.split("\t")[69])
items.append(item.split("\t")[68])
datas.append(items)
datas = np.asarray(datas)
# 每组数据的不为0的值
oneCircle = []
print(datas.shape)
# (1. 显示x坐标
for j in range(datas.shape[0]):
s = []
for i in range(datas.shape[1] - 5):
if float(datas[j][i]) != 0:
alpha = float(datas[j][-5]) / 100
alphas = float(datas[j][-5]) / 100
alpha = alpha * 3.14 / 180
x = float(datas[j][i]) * np.sin(base_datas[i][0])#+ base_datas[i][1] * np.cos(alpha) + base_datas[i][2] * np.sin(alpha)
z = float(datas[j][i]) * np.cos(base_datas[i][0])
# #倾角补偿
x = x * np.cos(alpha) - z * np.sin(alpha) + base_datas[i][1] * np.cos(alpha) + base_datas[i][2] * np.sin(alpha)
z = x * np.sin(alpha) + z * np.cos(alpha) + base_datas[i][1] * np.sin(alpha) + base_datas[i][2] * np.cos(alpha)
# # 加平移的修正
front = float(datas[j][-3]) - float(datas[j][-4])
back = float(datas[j][-1]) - float(datas[j][-2])
translate = (front + back) / 400 # 平移
baijiao = np.arctan((front - back) / (2 * 313.64)) # 摆角
# x = x * np.cos(baijiao) + z * np.sin(baijiao)
# z = z * np.cos(baijiao) - x * np.sin(baijiao)
# x = x - base_datas[i][-1] * np.sin(baijiao)
if z < 6800:
if z > 5700:
s.append([classes_index[str(i)], x - 712.5, z, datas[j][i], alphas])
oneCircle.append(s)
return oneCircle
# 2. 画图
def all_scatter_plot(oneCircle):
nums = 0
x1 = []
y1 = []
z1 = []
for item in oneCircle:
# print(item)
if len(item) > 0:
for items in item:
y1.append(nums)
z1.append(items[2])
x1.append(items[1])
nums += 1
plt.scatter(y1, x1, s=2, c="navy")
plt.scatter(y1, z1, s=2, c="blue")
plt.show()
# 3. 去掉数据空格,将数据按照行的接收的前后顺序排序
def rows_sort(oneCircle):
datas_count = [] # 存放计算用的数据
y_ins = 0
for item in oneCircle:
if len(item) > 0:
ss = []
for items in item:
ss.append([y_ins, items[1], items[2]])
datas_count.append(ss)
y_ins += 1
print("显示数值的长度: ", y_ins)
return datas_count
# 4. 将长度大于2的行和小于等于2的行分开,后续要对大于3的行的值进行精简
def two_three(batch_datas):
ths = {} # 单个的大于等于3个的类
cls = {} # 小于3个的类
for j in range(len(batch_datas)):
if len(batch_datas[j]) < 3:
cls[str(j)] = batch_datas[j]
else:
cls[str(j)] = []
ths[str(j)] = batch_datas[j]
key1 = list(cls.keys())
key2 = list(ths.keys())
return key1, key2, cls, ths
# 5.取最小值
def two_min(cls, ths, tt):
if str(int(tt[0]) - 1) in cls:
print("====> ", cls[str(int(tt[0]) - 1)])
for item in tt:
sss = ths[item][:2] # 存放最小差值时的类,开始是赋值最小差值时的类为多个值的前两个值
L = [1000, 1000] # 存放最小的差值,开始时假设最小差值为1000,这个值不能太小,否则后面的比较就没有意义了
for ts in range(2):
for cs in cls[str(int(tt[0]) - 1)]:
if abs(sss[ts][1] - cs[1]) < L[ts]:
L[ts] = abs(sss[ts][1] - cs[1])
for k in range(2, len(ths[item])): # 其他数据
for cs in cls[str(int(tt[0]) - 1)]:
for hh in range(2):
if abs(ths[item][k][1] - cs[1]) < L[hh]:
L[hh] = abs(ths[item][k][1] - cs[1])
sss[hh] = cs
cls[item] = sss
print("最小值: ", cls[item])
return cls
# 6.保存最长为2个数据的列表
def two_saves(key2, cls, ths):
ll = 0
tt = []
if len(key2) > 0:
ll = int(key2[0])
tt.append(key2[0])
for j in range(1, len(key2)):
if int(key2[j]) - ll == 1:
ll = int(key2[j])
tt.append(key2[j])
if j == len(key2) - 1:
cls = two_min(cls, ths, tt)
else:
ll = int(key2[j])
print(" ", tt)
# 根据tt处理数据 找tt[0]-1 和tt[-1]+1 的cls的值,然后作比较加入cls[j][1]
cls = two_min(cls, ths, tt)
tt.clear()
tt.append(key2[j])
batches = []
for items in cls:
batches.append(cls[items])
return batches
# 7. 求均值
def data_means(batches):
x_mean = 0
z_mean = 0
mean_nums = 0
yy = 0
for bd in batches:
for bds in bd:
x_mean += bds[1]
z_mean += bds[2]
yy += bds[0]
mean_nums += 1
x_mean /= mean_nums
z_mean /= mean_nums
yy = yy // mean_nums
return x_mean, z_mean, yy
# 8. 根据均值将数据分为两大类
def two_classes(batches, x_mean, z_mean):
up_classes = [] # 存上面的类
down_classes = [] # 存下面的类
up_limit_x, down_limit_x = x_mean + 50, x_mean - 50
up_limit_z, down_limit_z = z_mean + 50, z_mean - 50
for bd in batches:
for bds in bd:
if abs(bds[1] - up_limit_x) < abs(bds[1] - down_limit_x):
up_classes.append(bds)
else:
down_classes.append(bds)
return up_classes, down_classes
# 9. 对两大类数据再分类,分成一个类、两个类再加上其他类
def second_classes(up_classes, down_classes):
others1 = []
others2 = []
# 转换为np数据再进行处理数据,求均值
up_classes = np.asarray(up_classes)
down_classes = np.asarray(down_classes)
u1, u2 = up_classes[:, 1].mean(), down_classes[:, 1].mean() # 两个类的均值
# 根据u1,u2判断up_classes与down_classes的上下是不是同一个类
up_classes = list(up_classes)
if abs(u1 - u2) < 150:
for ud in down_classes:
up_classes.append(ud)
down_classes = []
# 根据up_classes[-1][0] 、 down_classes[-1][0] 、 up_classes[0][0] 、 down_classes[0][0]判断左右是不是同一类
if len(down_classes) != 0:
if abs(up_classes[-1][0] - down_classes[0][0]) < 20 or abs(up_classes[0][0] - down_classes[-1][0]) < 20:
for ud in down_classes:
up_classes.append(ud)
down_classes = []
# 根据up_classes[-1][0] 、 up_classes[0][0]判断能不作为一个类
if abs(up_classes[-1][0] - up_classes[0][0]) < 60:
for uc in up_classes:
others1.append(uc)
up_classes = []
if len(down_classes) != 0:
if abs(down_classes[-1][0] - down_classes[0][0]) < 60:
for uc in down_classes:
others2.append(uc)
down_classes = []
return up_classes, down_classes, others1, others2
# 10. 对分好的类构造直线 y = k1*x + b1
def line_bn(up_classes):
up_class1 = [] # 存放正态分布满足小于1的值
down_class1 = [] # 存放正态分布满足小于1的值
other_class1 = [] # 存放正态分布不满足小于1的值
other_class2 = [] # 存放正态分布不满足小于1的值
if len(up_classes) != 0:
up_classes = np.asarray(up_classes)
up_cl = np.zeros((up_classes.shape[0], up_classes.shape[1] + 2))
lens1 = up_classes.shape[0] // 2 # 将数据从中间分割成两部分,分别求均值
xx1, yy1 = up_classes[:lens1, 0].mean(), up_classes[:lens1, 1].mean()
xx2, yy2 = up_classes[-lens1:, 0].mean(), up_classes[-lens1:, 1].mean()
k1 = (yy2 - yy1) / (xx2 - xx1 + 0.000000001) # 两点求斜率,为了防止分母为0,加0.000000001
b1 = yy2 - k1 * xx2
# 则直线方程为 k1 * x - y + b1 = 0 ====>AX + BY + C = 0, A = k1, B= -1, C = b1,接下来求各点到直线的距离
# 点到直线的距离公式为|AX + By + C| / (A ** 2 + B ** 2) ** 0.5
up_cl[:, :-2] = up_classes
up_cl[:, -1] = (up_cl[:, 0] * k1 - up_cl[:, 1] + b1) / ((k1 ** 2 + 1) ** 0.5)
# print(up_cl[:5,:])
# 根据距离求up_cl的均值u_mean和方差vars1
u_mean = up_cl[:, -1].mean()
vars1 = 0
for uc in up_cl:
vars1 += (uc[-1] - u_mean) ** 2
vars1 = (vars1 / max(len(up_cl), 1)) ** 0.5
for j in range(len(up_cl)):
if abs((up_cl[j][-1] - u_mean) / (vars1 + 0.00001)) < 1:
up_class1.append(up_classes[j])
else:
other_class1.append(up_classes[j])
return up_class1, other_class1
if __name__ == '__main__':
# 基础数据处理: 共63行(63个传感器),每行3个数据:每个传感器的弧度制角度、距离中线的距离、距离车底的距离
base_datas = np.asarray(ss)
print(base_datas.shape)
# 1. 读取63个传感器获取到的值,63列,第64列为倾角,前左、前右、后左、后右,然后对其做倾角补偿
filepath = 'ones.txt'#ones
oneCircle = read_datas(filepath)
# 2. 画图
all_scatter_plot(oneCircle)
# 3. 去掉数据空格,将数据按照行的接收的前后顺序排序
datas_count = rows_sort(oneCircle)
# ##########################################################################################
# >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> 接收数据到算法实现 <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
# ##########################################################################################
# 4. 计算
indexs = 1 #每个批次计数
pre_batch_count = 101 #表示每个批次处理200行数据
nums_count = 0 # 计算总共有多少批次
batch_datas = []#每个批次的数据,按照行排序
# 总共有3个类,"line1"和"line2"表示有两条线时的两个类,"other3"表示其他类
temporary_class = {} # 存放临时的大类,对temporary_class1再次聚类,该大类最多有3个小类,两条直线和其他类
temporary_class["line1"] = []
temporary_class["line2"] = []
temporary_class["other3"] = []
for i in range(len(datas_count)):
if indexs % pre_batch_count != 0: # ==================================> 取200个数据
batch_datas.append(datas_count[i])
indexs += 1
else:
print(".................................................................................")
# (1. 记大于等于3个的类
key1, key2, cls, ths = two_three(batch_datas) # ths = {}: 单个的大于等于3个的类 cls = {}: 小于3个的类 , key1, key2分别是两个字典的键
# (2. 将同一行大于3个的值去除成2个值
batches = two_saves(key2, cls, ths)
#对batch_datas的200行数据进行计算,实际数据可能大于200个
# (1. 求均值
# (2. 根据均值将数据分为两大类
# (3. 对两大类数据再分类,分成一个类、两个类再加上其他类
# (4. 对分好的类构造直线 y = k*x + b
# (5. 求类中各点到直线的距离
# (6. 求距离的正态分布
# (7. 根据正态分布去掉噪点,剩下的点即为分好类的点
# (1. 求均值
x_mean, z_mean, yy = data_means(batches)
# (2. 根据均值将数据分为两大类
up_classes, down_classes = two_classes(batches, x_mean, z_mean)
# (3 对两大类数据再分类,分成一个类、两个类再加上其他类
up_classes, down_classes, others1, others2 = second_classes(up_classes, down_classes)
# 画图
for uc in up_classes:
plt.scatter(uc[0], uc[1], s=2, c=colors[2])
for uc in down_classes:
plt.scatter(uc[0], uc[1], s=2, c=colors[1])
for uc in others1:
plt.scatter(uc[0], uc[1], s=2, c=colors[0])
for uc in others2:
plt.scatter(uc[0], uc[1], s=2, c=colors[0])
plt.scatter(yy, x_mean, s=20, c=colors[0])
plt.show()
# (4. 对分好的类构造直线 y = k1*x + b1,并返回满足正态分布小于1的数据
up_class1, other_class1 = line_bn(up_classes)
down_class1, other_class2 = line_bn(down_classes)
# 画图
for uc in up_class1:
plt.scatter(uc[0], uc[1], s=2, c=colors[2])
for uc in down_class1:
plt.scatter(uc[0], uc[1], s=2, c=colors[1])
for uc in other_class2:
plt.scatter(uc[0], uc[1], s=2, c=colors[0])
for uc in other_class1:
plt.scatter(uc[0], uc[1], s=2, c=colors[3])
plt.show()
# 初始值归0,重新开始计算
indexs = 1
nums_count += 1
batch_datas = []
2.c++代码
#include<iostream>
#include<fstream> //ifstream
#include<string> //包含getline()
#include<vector>
#include<list>
#include <array>
#include <unordered_map>
#include <math.h>
using namespace std;
// ...........................................................................................................................
// ----------------------------------------------------> 数据初始化 <----------------------------------------------------
// ...........................................................................................................................
// 63个传感器的基础数据初始化
float base_datas[63][3] =
{ {0.03419, -89.31, 118.5},{0.05676, -67.16, 118.5},{0.07927, -44.99, 118.5},
{0.10172, -22.84, 118.5 },{0.12393, 0.0, 118.5 },{0.14626, 21.5, 118.5 },
{0.1683, 43.66, 118.5 },{0.19008, 65.81, 118.5 },{0.212, 87.97, 118.5 },
{0.03801, -89.32, 118.5 },{0.06058, -67.16, 118.5 },{0.08309, -45.0, 118.5 },
{0.10551, -22.84, 118.5 },{0.12773, 0.0, 118.5 },{0.15002, 21.49, 118.5 },
{0.17206, 43.65, 118.5 },{0.19395, 65.82, 118.5 },{0.21562, 87.97, 118.5 },
{0.04185, -89.32, 118.5 },{0.06441, -67.16, 118.5 },{0.08692, -44.99, 118.5 },
{0.10931, -22.83, 118.5 },{0.1315, 0.0, 118.5 },{0.15376, 21.49, 118.5 },
{0.17581, 43.65, 118.5 },{0.19769, 65.81, 118.5 },{0.21932, 87.96, 118.5 },
{0.04569, -89.32, 118.5 },{0.06825, -67.16, 118.5 },{0.09073, -45.0, 118.5 },
{0.11312, -22.84, 118.5 },{0.1353, 0.0, 118.5 },{0.15755, 21.49, 118.5 },
{0.17953, 43.65, 118.5 },{0.20137, 65.81, 118.5 },{0.2229, 87.97, 118.5 },
{0.04953, -89.32, 118.5 },{0.07206, -67.16, 118.5 },{0.09452, -44.99, 118.5 },
{0.11692, -22.83, 118.5 },{0.13905, 0.0, 118.5 },{0.16129, 21.49, 118.5 },
{0.18325, 43.65, 118.5 },{0.20504, 65.81, 118.5 },{0.22667, 87.97, 118.5 },
{0.05336, -89.32, 118.5 },{0.0759, -67.16, 118.5 },{0.09835, -45.0, 118.5 },
{0.1207, -22.84, 118.5 },{0.14282, 0.0, 118.5 },{0.16502, 21.49, 118.5 },
{0.18697, 43.66, 118.5 },{0.20875, 65.81, 118.5 },{0.23025, 87.96, 118.5 },
{0.05718, -89.32, 118.5 },{0.07971, -67.16, 118.5 },{0.10214, -44.99, 118.5 },
{0.1245, -22.83, 118.5 },{0.14656, 0.0, 118.5 },{0.16878, 21.49, 118.5 },
{0.19066, 43.65, 118.5 },{0.21238, 65.82, 118.5 },{0.2339, 87.97, 118.5 } };
// 63个传感器重新排序的字典初始化,将63个传感器的点映射到一条直线上
unordered_map<string, int> classes_index{
{"0", 0}, {"9" , 1}, {"18" , 2}, {"27" , 3}, {"36" , 4}, {"45" , 5}, {"54" , 6},
{"1" , 7}, {"10" , 8}, {"19", 9}, {"28" , 10}, {"37" , 11}, {"46" , 12}, {"55" , 13},
{"2" , 14}, {"11" , 15}, {"20" , 16}, {"29" , 17}, {"38" , 18}, {"47" , 19}, {"56" , 20},
{"3" , 21}, {"12" , 22}, {"21" , 23}, {"30" , 24}, {"39" , 25}, {"48" , 26}, {"57" , 27},
{"4" , 28}, {"13" , 29}, {"22" , 30}, {"31" , 31}, {"41" , 39}, {"50" , 40}, {"59" , 41},
{"6" , 42}, {"15" , 43}, {"24" , 44}, {"33" , 45}, {"42" , 46}, {"51" , 47}, {"60" , 48},
{"7" , 49}, {"16" , 50}, {"25" , 51}, {"34" , 52}, {"43" , 53}, {"52" , 54}, {"61" , 55},
{"8" , 56}, {"17" , 57}, {"26" , 58}, {"35" , 59}, {"44" , 60}, {"53" , 61}, {"62" , 62},
};
// 根据长度输出不同的颜色
vector<string> colors = { "black", "green", "red","fuchsia", "aqua", "orange", "pink", "green", "red", "yellow", "green",
"aqua", "orange", "red", "fuchsia", "yellow", "aqua", "orange", "green", "red", "yellow" };
// ...........................................................................................................................
// ----------------------------------------------------> 函数功能的实现 <----------------------------------------------------
// ...........................................................................................................................
//1.字符串的分割
vector <string> splits(string s)
{
vector<string> lists;
string t = "";
char m = '\t';
for (int i = 0; i < s.size(); i++)
{
if (s[i] != m)
{
t += s[i];
}
else
{
if (t.size() != 0)
{
lists.push_back(t);
t = "";
}
}
}
return lists;
}
// 2.读取txt文件,返回需要的数据
vector <vector<string>> data_back(string filepath)
{
cout << ".......读取txt文件!!!......." << endl;
vector<string> v1;//存放数据
vector<vector<string>> savedatas;
ifstream infile;
infile.open("ones.txt", ios::in);//"ones.txt"
if (!infile.is_open())
{
cout << "读取文件失败" << endl;
v1.push_back("0");
}
string s;
while (getline(infile, s))
{
v1.push_back(s);
}
// 获取可用的数据
for (int i = 1; i < v1.size(); i++)
{
vector <string> tt = splits(v1[i]);
savedatas.push_back(tt);
}
infile.close();
return savedatas;
}
//3. 获取63个传感器数据和前后左右加倾角的5个数据,并将其转换为浮点型
vector<vector<float>> apply_datas(vector<vector<string>> savedatas)
{
vector<vector<float>> onecircles;//对x和z校正
for (int i = 0; i < savedatas.size(); i++)
{
// 取出每行需要计算的数据,并转换为浮点型
vector<float> ss;//对x和z校正
for (int j = 0; j < 63; j++)
ss.push_back(stof(savedatas[i][j]));
ss.push_back(stof(savedatas[i][70]));//倾角
ss.push_back(stof(savedatas[i][66]));
ss.push_back(stof(savedatas[i][67]));
ss.push_back(stof(savedatas[i][69]));
ss.push_back(stof(savedatas[i][68]));
onecircles.push_back(ss);
}
return onecircles;
}
// 4. 倾角、平移补偿,去掉空格,返回的数据类型为: vector<vector<vector<float>>>
vector <vector<vector<float>>> angle_dispose(vector<vector<vector<float>>> denoise, vector<float> onecircles,int indexes)
{
//传入的数据为onecircles[i]
vector<vector<float>> oc;//每一行存取的数据
//cout << "每行的长度: " << onecircles.size() << endl;
for (int j = 0; j < 63; j++)
{
if (onecircles[j] != 0)
{
//cout << onecircles[i][j] <<" " << base_datas[j][0] << endl;
float alpha = onecircles[63] / 100;
alpha = alpha * 3.1416 / 180;
float x = onecircles[j] * sin(base_datas[j][0]);
float z = onecircles[j] * cos(base_datas[j][0]);
// 倾角补偿
x = x * cos(alpha) - z * sin(alpha) + base_datas[j][1] * cos(alpha) + base_datas[j][2] * sin(alpha);
z = x * sin(alpha) + z * cos(alpha) + base_datas[j][1] * sin(alpha) + base_datas[j][2] * cos(alpha);
// 平移补偿
//float front = onecircles[i][-3] - onecircles[i][-4];
//float back = onecircles[i][-1] - onecircles[i][-2];
//float translate = (front + back) / 400; // 平移
//float baijiao = atan((front - back) / (2 * 313.64)); // # 摆角
//x = x * cos(baijiao) + z * sin(baijiao);
//z = z * cos(baijiao) - x * sin(baijiao);
//x = x - base_datas[j][-1] * sin(baijiao);
if (z < 6800)
{
if (z > 5700)
{
vector<float> tt;
//cout << x << " " << z << " " << classes_index[to_string(j)] << endl;
float indexs = classes_index[to_string(j)];
x = x - 712.5;
//tt.push_back(indexs);
tt.push_back(indexes);
tt.push_back(x);
tt.push_back(z);
tt.push_back(onecircles[j]);
tt.push_back(alpha);
oc.push_back(tt);
}
}
}
}
/*cout << "====> " << oc.size() << endl;*/
if (oc.size() > 0)
{
denoise.push_back(oc);
}
return denoise;
}
// 5.取最小值
unordered_map<string, vector<vector<float>>> two_min(unordered_map<string, vector<vector<float>>> cls, unordered_map<string, vector<vector<float>>> ths, vector<string> tt)
{
string keys = to_string(stoi(tt[0]) - 1);
if (cls.count(keys) != 0)
{
for (int t1 = 0; t1 < tt.size(); t1++)
{//item=tt[t1]
vector<vector<float>> sss;
sss.push_back(ths[tt[t1]][0]);
sss.push_back(ths[tt[t1]][1]);// 存放最小差值时的类,开始是赋值最小差值时的类为多个值的前两个值
vector<float> L = { 1000,1000 };// 存放最小的差值,开始时假设最小差值为1000,这个值不能太小,否则后面的比较就没有意义了
for (int k = 0; k < 2; k++)
{
for (int t2 = 0; t2 < cls[to_string(stoi(tt[0]) - 1)].size(); t2++)
{
if (abs(sss[k][1] - cls[to_string(stoi(tt[0]) - 1)][t2][1]) < L[k])
{
L[k] = abs(sss[k][1] - cls[to_string(stoi(tt[0]) - 1)][t2][1]);
}
}
}
for (int kk = 2; kk < ths[tt[t1]].size(); kk++)
{
for (int t2 = 0; t2 < cls[to_string(stoi(tt[0]) - 1)].size(); t2++)
{
for (int hh = 0; hh < 2; hh++)
{
if (abs(ths[tt[t1]][kk][1] - cls[to_string(stoi(tt[0]) - 1)][t2][1]) < L[hh])
{
L[hh] = abs(ths[tt[t1]][kk][1] - cls[to_string(stoi(tt[0]) - 1)][t2][1]);
sss[hh] = cls[to_string(stoi(tt[0]) - 1)][t2];
}
}
}
}
cls[tt[t1]] = sss;
//cout << "最小值: " << cls[tt[t1]][0][1] <<" " << cls[tt[t1]][0][2] << endl;
}
}
return cls;
}
//(2. 将同一行大于3个的值去除成2个值
vector<vector<vector<float>>> two_saves(vector<string> key1, vector<string> key2, unordered_map<string, vector<vector<float>>> cls, unordered_map<string, vector<vector<float>>> ths)
{
int ll = 0;
vector<string> tt;
if (key2.size() > 0)
{
ll = stoi(key2[0]);
tt.push_back(key2[0]);
}
for (int j = 0; j < key2.size(); j++)
{
if (stoi(key2[j]) - ll == 1)
{
ll = stoi(key2[j]);
tt.push_back(key2[j]);
if (j == key2.size() - 1)//倒数第二个值时取最小值
{
//5.取最小值
cls = two_min(cls, ths, tt);
}
}
else
{
ll = stoi(key2[j]);
//5.取最小值
cls = two_min(cls, ths, tt);
tt.clear();
tt.push_back(key2[j]);
}
}
vector<vector<vector<float>>> batchs;
for (int j = 0; j < key1.size(); j++)
{
batchs.push_back(cls[key1[j]]);
}
//cout << ": " << batchs[0][0][0] << " " << batchs[0][0][1] << endl;
return batchs;
}
// (1. 求均值
vector<float> data_means(vector<vector<vector<float>>> batches)
{
float x_mean = 0;
float z_mean = 0;
float mean_nums = 0;
float yy = 0;
for (int j = 0; j < batches.size(); j++)
{
//cout <<":::::::::::::::: " << batches[j].size() << endl;
for (int k = 0; k < batches[j].size(); k++)
{
//cout << batches[j][k].size() <<" " << batches[j][k][1]<< " " << batches[j][k][2] << endl;
x_mean += batches[j][k][1];
z_mean += batches[j][k][2];
mean_nums += 1;
yy += batches[j][k][0];
}
}
x_mean = x_mean / mean_nums;
z_mean = z_mean / mean_nums;
yy = yy / mean_nums;
vector<float> ss={ x_mean ,z_mean ,yy };
//cout << "......: " << ss[0] << " " << ss[1] << " " << ss[2] << endl;
return ss;
}
// (2. 根据均值将数据分为两大类
vector<vector<vector<float>>> two_classes(float x_mean, float z_mean, vector<vector<vector<float>>> batchs)
{
vector<vector<float>> up_classes;
vector<vector<float>> down_classes;
float up_limit_x = x_mean + 50;
float down_limit_x = x_mean - 50;
float up_limit_z = z_mean + 50;
float down_limit_z = z_mean - 50;
for (int j = 0; j < batchs.size(); j++)
{
for (int k = 0; k < batchs[j].size(); k++)
{
if (abs(batchs[j][k][1] - up_limit_x) < abs(batchs[j][k][1] - down_limit_x))
{
up_classes.push_back(batchs[j][k]);
}
else
{
down_classes.push_back(batchs[j][k]);
}
}
}
vector<vector<vector<float>>> hh = { up_classes ,down_classes };
return hh;
}
//求均值
float means(vector<vector<float>> up_classes)
{
float u1 = 0;
float nums = 0;
for (int j = 0; j < up_classes.size(); j++)
{
u1 += up_classes[j][1];
nums += 1;
}
u1 = u1 / nums;
return u1;
}
// (3 对两大类数据再分类,分成一个类、两个类再加上其他类
vector<vector<vector<float>>> second_classes(vector<vector<float>> up_classes, vector<vector<float>> down_classes)
{
vector<vector<float>> others1;
vector<vector<float>> others2;
float u1 = means(up_classes);//两个类的均值
float u2 = means(down_classes);
// # 根据u1,u2判断up_classes与down_classes的上下是不是同一个类
if (abs(u1 - u2) < 150)
{
for (int j = 0; j < down_classes.size(); j++)
{
up_classes.push_back(down_classes[j]);
}
down_classes.clear();
}
// # 根据up_classes[-1][0] 、 down_classes[-1][0] 、 up_classes[0][0] 、 down_classes[0][0]判断左右是不是同一类
if (down_classes.size() > 0)
{
int l1 = up_classes.size() - 1;
int l2 = down_classes.size() - 1;
float v1 = abs(up_classes[l1][0] - down_classes[0][0]);
float v2 = abs(up_classes[0][0] - down_classes[l2][0]);
//cout << "====> " << up_classes.size() << " " << v1 << " " << v2 << endl;
if (v1 < 20 || v2 < 20)
{
for (int j = 0; j < down_classes.size(); j++)
{
up_classes.push_back(down_classes[j]);
}
down_classes.clear();
}
}
// # 根据up_classes[-1][0] 、 up_classes[0][0]判断能不作为一个类
int l1 = up_classes.size() - 1;
if (abs(up_classes[l1][0] - up_classes[0][0]) < 30)
{
for (int j = 0; j < up_classes.size(); j++)
{
others1.push_back(up_classes[j]);
}
up_classes.clear();
}
if (down_classes.size() > 0)
{
int l2 = down_classes.size() - 1;
if (abs(down_classes[l2][0] - down_classes[0][0]) < 30)
{
for (int j = 0; j < down_classes.size(); j++)
{
others2.push_back(down_classes[j]);
}
down_classes.clear();
}
}
vector<vector<vector<float>>> backs = { up_classes, down_classes, others1, others2 };
return backs;
}
// # (4. 对分好的类构造直线 y = k1*x + b1
vector<vector<vector<float>>> line_bn(vector<vector<float>> up_classes)
{
vector<vector<float>> up_class1;
vector<vector<float>> other_class1;
if (up_classes.size() > 0)
{
int lens = up_classes.size() / 2; // # 将数据从中间分割成两部分,分别求均值
float xx1 = 0;
float yy1 = 0;
for (int j = 0; j < lens; j++)
{
xx1 += up_classes[j][0];
yy1 += up_classes[j][1];
}
xx1 = xx1 / lens;
yy1 = yy1 / lens;
float xx2 = 0;
float yy2 = 0;
for (int j = lens; j < up_classes.size(); j++)
{
xx2 += up_classes[j][0];
yy2 += up_classes[j][1];
}
xx2 = xx2 / (up_classes.size() - lens + 0.01);
yy2 = yy2 / (up_classes.size() - lens + 0.01);
float k1 = (yy2 - yy1) / (xx2 - xx1 + 0.000000001); //# 两点求斜率,为了防止分母为0,加0.000000001
float b1 = yy2 - k1 * xx2;
//# 则直线方程为 k1 * x - y + b1 = 0 ====>AX + BY + C = 0, A = k1, B = -1, C = b1, 接下来求各点到直线的距离
//# 点到直线的距离公式为 | AX + By + C| / (A * *2 + B * *2) * *0.5
float u_mean = 0; //# 根据距离求up_cl的均值u_mean和方差vars1
for (int j = 0; j < up_classes.size(); j++)
{
float distance = (up_classes[j][0] * k1 - up_classes[j][1] + b1) / (pow(pow(k1, 2) + 1, 0.5));
up_classes[j].push_back(distance);
u_mean += distance;
}
u_mean = u_mean / (up_classes.size() + 0.0001);
float vars1 = 0; // 方差
for (int j = 0; j < up_classes.size(); j++)
{
vars1 += pow(up_classes[j][5] - u_mean, 2);
}
vars1 = pow(vars1 / (up_classes.size() + 0.00001), 0.5);
for (int j = 0; j < up_classes.size(); j++)
{
if (abs(up_classes[j][5] - u_mean) / (vars1 + 0.00001) < 1)
{
up_class1.push_back(up_classes[j]);
}
else
{
other_class1.push_back(up_classes[j]);
}
}
}
vector<vector<vector<float>>> ff = { up_class1 ,other_class1 };
return ff;
}
float analysi()
{
cout << "................... 1.数据处理 ........................" << endl;
// 1.读取txt文件
string filepath = "ones.txt";
vector<vector<string>> savedatas = data_back(filepath);
//3. 获取63个传感器数据和前后左右加倾角的5个数据,并将其转换为浮点型
vector<vector<float>> onecircles = apply_datas(savedatas);
cout << "................... 2.数据修正 ........................" << endl;
int pre_batch_count = 101; // #表示每个批次处理200行数据
int indexs = 1; // 每批次计数
int nums_count = 0; // 计算总共有多少批次
vector<vector<vector<float>>> denoise;//[ row1[[gan1],[gan1]], row2[[gan1]], row3[[gan1],[gan2],[gan3]] ]
for (int i = 0; i < onecircles.size(); i++)//i < onecircles.size()
{
//
// 3. 倾角、平移补偿,去掉空格,返回的数据类型为: vector<vector<vector<float>>>
if (indexs % pre_batch_count != 0)
{
int num1 = denoise.size();
denoise = angle_dispose(denoise, onecircles[i], indexs);
if (denoise.size() - num1 > 0)
{
indexs += 1;
}
}
else
{
cout << "...................." << nums_count<< "...................." << endl;
//(1. 记大于等于3个的类
unordered_map<string, vector<vector<float>>> ths;
unordered_map<string, vector<vector<float>>> cls;
vector<string>key1;
vector<string>key2;
for (int j = 0; j < denoise.size(); j++)
{
//cout << "元素长度====>: " << denoise.size() << endl;
if (denoise[j].size() < 3)
{
//cout << "元素个数: " << denoise[j].size() << endl;
cls[to_string(j)]=(denoise[j]);
//cls[to_string(j)].push_back(denoise[j]);
key1.push_back(to_string(j));
}
else
{
//cout << "元素个数ss: " << denoise[j].size() << endl;
cls[to_string(j)] = {};
ths[to_string(j)]=(denoise[j]);
key1.push_back(to_string(j));
key2.push_back(to_string(j));
}
}
//(2. 将同一行大于3个的值去除成2个值
vector<vector<vector<float>>> batchs = two_saves(key1,key2, cls, ths);
/*#对batch_datas的200行数据进行计算,实际数据可能大于200个
# (1. 求均值
# (2. 根据均值将数据分为两大类
# (3. 对两大类数据再分类,分成一个类、两个类再加上其他类
# (4. 对分好的类构造直线 y = k*x + b
# (5. 求类中各点到直线的距离
# (6. 求距离的正态分布
# (7. 根据正态分布去掉噪点,剩下的点即为分好类的点
# (1. 求均值*/
vector<float> ss = data_means(batchs);
float x_mean = ss[0];
float z_mean = ss[1];
float yy = ss[2];
cout <<"均值: " <<x_mean << " " << z_mean << endl;
//# (2. 根据均值将数据分为两大类
vector<vector<vector<float>>> hh =two_classes(x_mean, z_mean, batchs);
vector<vector<float>> up_classes = hh[0];
vector<vector<float>> down_classes = hh[1];
// # (3 对两大类数据再分类,分成一个类、两个类再加上其他类
vector<vector<vector<float>>> backs = second_classes(up_classes, down_classes);
cout << "====> " << backs[0].size() << " " << backs[1].size() << " " << backs[2].size() << " " << backs[3].size() << endl;
up_classes = backs[0];
down_classes = backs[1];
vector<vector<float>> others1 = backs[2];
vector<vector<float>> others2 = backs[3];
// # (4. 对分好的类构造直线 y = k1*x + b1
vector<vector<vector<float>>> ff = line_bn(up_classes);
vector<vector<float>> up_class1 = ff[0]; // 其中一个类的点
vector<vector<float>> other_class1 = ff[1];
cout << "1.---> " << up_class1.size() << endl;
vector<vector<vector<float>>> dd = line_bn(down_classes);
vector<vector<float>> down_class1 = dd[0]; // 另一个类的点
vector<vector<float>> other_class2 = dd[1];
cout << "2.---> " << down_class1.size() << endl;
// 初始值归0,重新开始计算
indexs = 1;
denoise.clear();
nums_count += 1;
}
}
cout << "正弦值======> " << sin(30 * 3.1415926 / 180) << endl;
//cout << denoise.size() << endl;
return 0;
}
3.数据处理的散点图效果
(1)所有数据的散点图

(2)将上面的数据每200列作为一组处理,以下是第200列到第400列的数据的散点图,图中的黑点是所有点的均值,并根据均值的竖直方向的距离将所有数据分为上下两类(红色类和绿色类)

(3)以下红色类和绿色类各多出一种颜色,多出的颜色是进一步去除的数据,这一步是计数两个类的数据根据点到直线的距离转换为各自的正态分布数据,然后去除掉距离的正态分布数据大于1的点,最后剩下红色和绿色两个类。

(4)以下是其他几组长度为200的数据的分好类的散点图效果(还可以):
总数据:

分类结果:


















![[Linux安全运维] iptables包过滤](https://i-blog.csdnimg.cn/direct/3d65f55951b64654a0f41d565adfff4c.png#pic_center)