使用 Artifact Registry、Cloud Composer、GitHub Actions 和 dbt-airflow 容器化并运行 dbt 项目
欢迎来到雲闪世界。,大规模管理数据模型是使用dbt(数据构建工具)的数据团队面临的常见挑战。最初,团队通常从易于管理和部署的简单模型开始。然而,随着数据量的增长和业务 需求的 发展,这些模型的复杂性也随之增加。
这种发展通常会导致一个庞大的 存储库,其中所有依赖关系都交织在一起,这使得不同的团队难以有效协作。为了解决这个问题,数据团队可能会发现将他们的数据模型分布在多个 dbt 项目中是有益的。这种方法不仅可以促进更好的组织和模块化,还可以增强整个数据基础设施的可扩展性和可维护性。
处理多个 dbt 项目带来的一个重大复杂性是它们的执行和部署方式。管理库依赖关系成为一个关键问题,尤其是当不同的项目需要不同版本的 dbt 时。虽然 dbt Cloud 为调度和执行多存储库 dbt 项目提供了强大的解决方案,但它需要大量投资,并非每个组织都能负担得起或认为合理。一种常见的替代方案是使用Cloud Composer(Google Cloud 的托管Apache Airflow服务)运行 dbt 项目。
Cloud Composer 提供了一个托管环境,其中包含大量预定义依赖项。但是,根据我的经验,这种设置带来了重大挑战。安装任何 Python 库而不遇到未解决的依赖项通常都很困难。在使用时,我发现由于版本依赖项冲突,dbt-core在 Cloud Composer 环境中安装特定版本的 dbt 几乎是不可能的。这次经历凸显了在 Cloud Composer 上直接运行任何 dbt 版本的难度。
容器化 提供了一种有效的解决方案。您无需在 Cloud Composer 环境中安装库,而是可以使用 Docker 镜像容器化 dbt 项目并通过 Cloud Composer 在 Kubernetes 上运行它们。这种方法可让您的 Cloud Composer 环境保持干净,同时允许您在Docker镜像中包含任何所需的库。它还提供了在各种 dbt 版本上运行不同 dbt 项目的灵活性,解决了依赖冲突并确保无缝执行和部署。
在解决了管理多个 dbt 项目的复杂性之后,我们现在开始在 Google Cloud 上大规模部署这些项目的技术实现。下图概述了容器化 dbt 项目、将 Docker 镜像存储在Artifact Registry中以及使用GitHub Actions自动部署的过程。此外,它还说明了如何使用开源 Python 包在 Cloud Composer 上执行这些项目dbt-airflow,该包将 dbt 项目呈现为 Airflow DAG。以下部分将指导您完成每个步骤,提供有效扩展 dbt 工作流程的全面方法。
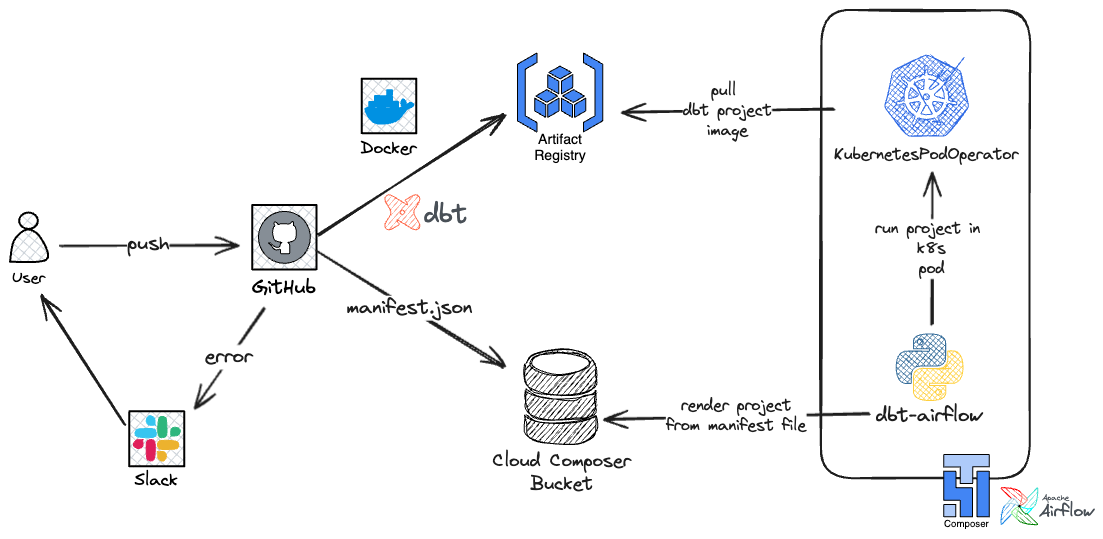
Google Cloud 上 dbt 项目部署流程概述 — 来源:作者
使用 GitHub Actions 在 Artifact Registry 上部署容器化的 dbt 项目
在本节中,我们将使用 GitHub Actions 定义 CI/CD 管道,以自动将 dbt 项目作为 Docker 映像部署到 Google Artifact Registry。此管道将简化流程,确保您的 dbt 项目被容器化并一致地部署在 Docker 存储库上,然后 Cloud Composer 就可以拾取它们。
首先,让我们从高层概述开始,了解 dbt 项目在存储库中的结构。这将帮助您遵循 CI/CD 管道的定义,因为我们将在某些子目录中工作以完成工作。请注意,Python 依赖项是通过Poetry管理的,因此存在pyproject.toml和poetry.lock文件。如果您过去曾使用过 dbt,那么下面分享的其余结构应该很容易理解。
.
├── README.md
├── dbt_project.yml
├── macros
├── models
├── packages.yml
├── poetry.lock
├── profiles
├── pyproject.toml
├── seeds
├── snapshots
└── tests项目结构确定后,我们现在可以开始定义 CI/CD 管道。为了确保每个人都能跟上,我们将介绍 GitHub Action 工作流程中的每个步骤并解释每个步骤的目的。此详细分解将帮助您了解如何为自己的项目实施和自定义管道。让我们开始吧!
步骤 1:为 GitHub Action 工作流创建触发器
我们的 GitHub Action 工作流程的上部定义了将激活管道的触发器。
name: dbt project deployment
on:
push:
branches:
- main
paths:
- 'projects/my_dbt_project/**'
- '.github/workflows/my_dbt_project_deployment.yml'main本质上,每当目录发生更改或 GitHub Action 工作流文件发生修改时,都会通过推送事件触发管道到分支projects/my_dbt_project/**。此设置可确保部署过程仅在进行相关更改时运行,从而保持工作流高效且最新。
第 2 步:定义一些环境变量
GitHub Action 工作流程的下一部分设置环境变量,这些变量将在后续步骤中使用:
env:
ARTIFACT_REPOSITORY: europe-west2-docker.pkg.dev/my-gcp-project-name/my-af-repo
COMPOSER_DAG_BUCKET: composer-env-c1234567-bucket
DOCKER_IMAGE_NAME: my-dbt-project
GCP_WORKLOAD_IDENTITY_PROVIDER: projects/11111111111/locations/global/workloadIdentityPools/github-actions/providers/github-actions-provider
GOOGLE_SERVICE_ACCOUNT: my-service-account@my-gcp-project-name.iam.gserviceaccount.com
PYTHON_VERSION: '3.8.12'这些环境变量存储部署过程所需的关键信息,例如 Artifact Registry 存储库、Cloud Composer DAG 存储桶、Docker 镜像名称、服务帐户详细信息和工作负载身份联合。
💡 从高层次来看,Google Cloud 的 Workload Identity 允许在 Google Cloud 上运行的应用程序以安全且可扩展的方式验证和授权其身份。
有关更多详细信息,请参阅Google Cloud 文档。
步骤 3:检出存储库
GitHub Action 工作流程的下一步是检出存储库:
- uses: actions/checkout@v4.1.6此步骤使用actions/checkout操作从存储库中提取最新代码。这可确保工作流能够访问构建和部署 Docker 映像所需的最新版本的 dbt 项目文件和配置。
步骤 4:向 Google Cloud 和 Artifact Registry 进行身份验证
工作流程的下一步涉及 Google Cloud 身份验证
- name: Authenticate to Google Cloud
id: google_auth
uses: google-github-actions/auth@v2.1.3
with:
token_format: access_token
workload_identity_provider: ${{ env.GCP_WORKLOAD_IDENTITY_PROVIDER }}
service_account: ${{ env.GOOGLE_SERVICE_ACCOUNT }}
- name: Login to Google Artifact Registry
uses: docker/login-action@v3.2.0
with:
registry: europe-west2-docker.pkg.dev
username: oauth2accesstoken
password: ${{ steps.google_auth.outputs.access_token }}首先,工作流使用该google-github-actions/auth操作向 Google Cloud 进行身份验证。此步骤利用提供的工作负载身份提供商和服务帐号检索访问令牌。
上一个身份验证步骤中的访问令牌用于europe-west2-docker.pkg.dev使用 中的指定注册表 ( ) 对 Docker 进行身份验证。此登录使工作流能够在后续步骤中将 dbt 项目的 Docker 映像推送到 Artifact Registry。
步骤 5:创建 Python 环境
下一组步骤涉及设置 Python 环境、安装 Poetry 和管理依赖项。
- name: Install poetry
uses: snok/install-poetry@v1.3.4
with:
version: 1.7.1
virtualenvs-in-project: true
- name: Set up Python ${{ env.PYTHON_VERSION }}
uses: actions/setup-python@v5.1.0
with:
python-version: ${{ env.PYTHON_VERSION }}
cache: 'poetry'
- name: Load cached venv
id: cached-poetry-dependencies
uses: actions/cache@v4.0.2
with:
path: projects/my_dbt_project/.venv
key: venv-${{ runner.os }}-${{ env.PYTHON_VERSION }}-${{ hashFiles('projects/my_dbt_project/poetry.lock') }}
- name: Install dependencies
if: steps.cached-poetry-dependencies.outputs.cache-hit != 'true'
working-directory: './projects/my_dbt_project/'
run: poetry install --no-ansi --no-interaction --sync我们首先安装poetry依赖管理工具,我们将使用它来安装 Python 依赖项。然后我们安装指定的 Python 版本,并最终从缓存中加载虚拟环境。如果缓存未命中(即自上次执行工作流以来对诗歌锁定文件进行了一些更改),则将从头开始安装 Python 依赖项。或者,如果缓存命中,则将从缓存中加载依赖项。
步骤 6:编译 dbt 项目
以下步骤涉及清理 dbt 环境、安装 dbt 依赖项以及编译 dbt 项目。
- name: Clean dbt, install deps and compile
working-directory: './projects/my_dbt_priject/'
run: |
echo "Cleaning dbt"
poetry run dbt clean --profiles-dir profiles --target prod
echo "Installing dbt deps"
poetry run dbt deps
echo "Compiling dbt"
poetry run dbt compile --profiles-dir profiles --target prod此步骤还将生成manifest.json文件,即 dbt 项目的元数据文件。此文件对于dbt-airflow包至关重要,Cloud Composer 将使用该文件自动将 dbt 项目渲染为 Airflow DAG。
步骤 7:在 Artifact Registry 上构建并推送 Docker 镜像
工作流程的下一步是构建 dbt 项目的 Docker 镜像并将其推送到 Google Artifact Registry。
- name: Build and Push Docker Image
run: |
FULL_ARTIFACT_PATH="${ARTIFACT_REPOSITORY}/${DOCKER_IMAGE_NAME}"
echo "Building image"
docker build --build-arg project_name=my_dbt_project --tag ${FULL_ARTIFACT_PATH}:latest --tag ${FULL_ARTIFACT_PATH}:${GITHUB_SHA::7} -f Dockerfile .
echo "Pushing image to artifact"
docker push ${FULL_ARTIFACT_PATH} --all-tags请注意我们如何使用两个标签(即以及简短提交 SHA)构建镜像latest。这种方法有两个目的:一是能够识别哪个 docker 镜像版本是最新版本,二是能够识别哪个提交与每个 docker 镜像相关联。当出于某种原因需要进行调试时,后者非常有用。
步骤 8:将清单文件与 Cloud Composer GCS 存储桶同步
最后一步是将编译后的 dbt 项目(特别是文件manifest.json)同步到 Cloud Composer DAG 存储桶。
- name: Synchronize compiled dbt
uses: docker://rclone/rclone:1.62
with:
args: >-
sync -v --gcs-bucket-policy-only
--include="target/manifest.json"
projects/my_dbt_project/ :googlecloudstorage:${{ env.COMPOSER_DAG_BUCKET }}/dags/dbt/my_dbt_project此步骤使用rcloneDocker 镜像将manifest.json文件与 Cloud Composer 的存储桶同步。这对于确保 Cloud Composer 具有最新的元数据至关重要,以便随后可以通过包获取它dbt-airflow并呈现对 dbt 项目所做的最新更改。
步骤 9:发生故障时发送 Slack 警报
最后一步是,如果部署失败,则发送 Slack 警报。要复制此步骤,您需要做的就是按照文档SLACK_WEBHOOK中所述发出令牌 ( ) 。
- name: Slack Alert (on failure)
if: failure()
uses: rtCamp/action-slack-notify@v2.3.0
env:
SLACK_CHANNEL: alerts-slack-channel
SLACK_COLOR: ${{ job.status }}
SLACK_TITLE: 'dbt project deployment failed'
SLACK_MESSAGE: |
Your message with more details with regards to
the deployment failure goes here.
SLACK_WEBHOOK: ${{ secrets.SLACK_WEBHOOK }}GitHub 操作的完整定义如下。如果您在运行过程中遇到任何问题,请在评论中告诉我,我会尽力帮助您!
name: dbt project deployment
on:
push:
branches:
- main
paths:
- 'projects/my_dbt_project/**'
- '.github/workflows/my_dbt_project_deployment.yml'
env:
ARTIFACT_REPOSITORY: europe-west2-docker.pkg.dev/my-gcp-project-name/my-af-repo
COMPOSER_DAG_BUCKET: composer-env-c1234567-bucket
DOCKER_IMAGE_NAME: my-dbt-project
GCP_WORKLOAD_IDENTITY_PROVIDER: projects/11111111111/locations/global/workloadIdentityPools/github-actions/providers/github-actions-provider
GOOGLE_SERVICE_ACCOUNT: my-service-account@my-gcp-project-name.iam.gserviceaccount.com
PYTHON_VERSION: '3.8.12'
jobs:
deploy-dbt:
runs-on: ubuntu-22.04
permissions:
contents: 'read'
id-token: 'write'
steps:
- uses: actions/checkout@v4.1.6
- name: Authenticate to Google Cloud
id: google_auth
uses: google-github-actions/auth@v2.1.3
with:
token_format: access_token
workload_identity_provider: ${{ env.GCP_WORKLOAD_IDENTITY_PROVIDER }}
service_account: ${{ env.GOOGLE_SERVICE_ACCOUNT }}
- name: Login to Google Artifact Registry
uses: docker/login-action@v3.2.0
with:
registry: europe-west2-docker.pkg.dev
username: oauth2accesstoken
password: ${{ steps.google_auth.outputs.access_token }}
- name: Install poetry
uses: snok/install-poetry@v1.3.4
with:
version: 1.7.1
virtualenvs-in-project: true
- name: Set up Python ${{ env.PYTHON_VERSION }}
uses: actions/setup-python@v5.1.0
with:
python-version: ${{ env.PYTHON_VERSION }}
cache: 'poetry'
- name: Load cached venv
id: cached-poetry-dependencies
uses: actions/cache@v4.0.2
with:
path: projects/my_dbt_project/.venv
key: venv-${{ runner.os }}-${{ env.PYTHON_VERSION }}-${{ hashFiles('projects/my_dbt_project/poetry.lock') }}
- name: Install dependencies
if: steps.cached-poetry-dependencies.outputs.cache-hit != 'true'
working-directory: './projects/my_dbt_project/'
run: poetry install --no-ansi --no-interaction --sync
- name: Clean dbt, install deps and compile
working-directory: './projects/my_dbt_priject/'
run: |
echo "Cleaning dbt"
poetry run dbt clean --profiles-dir profiles --target prod
echo "Installing dbt deps"
poetry run dbt deps
echo "Compiling dbt"
poetry run dbt compile --profiles-dir profiles --target prod
- name: Build and Push Docker Image
run: |
FULL_ARTIFACT_PATH="${ARTIFACT_REPOSITORY}/${DOCKER_IMAGE_NAME}"
echo "Building image"
docker build --build-arg project_name=my_dbt_project --tag ${FULL_ARTIFACT_PATH}:latest --tag ${FULL_ARTIFACT_PATH}:${GITHUB_SHA::7} -f Dockerfile .
echo "Pushing image to artifact"
docker push ${FULL_ARTIFACT_PATH} --all-tags
- name: Synchronize compiled dbt
uses: docker://rclone/rclone:1.62
with:
args: >-
sync -v --gcs-bucket-policy-only
--include="target/manifest.json"
projects/my_dbt_project/ :googlecloudstorage:${{ env.COMPOSER_DAG_BUCKET }}/dags/dbt/my_dbt_project
- name: Slack Alert (on failure)
if: failure()
uses: rtCamp/action-slack-notify@v2.3.0
env:
SLACK_CHANNEL: alerts-slack-channel
SLACK_COLOR: ${{ job.status }}
SLACK_TITLE: 'dbt project deployment failed'
SLACK_MESSAGE: |
Your message with more details with regards to
the deployment failure goes here.
SLACK_WEBHOOK: ${{ secrets.SLACK_WEBHOOK }}使用 Cloud Composer 和 dbt-airflow 运行 dbt 项目
在上一节中,我们讨论并演示了如何使用 GitHub Actions 在 Google Artifact Registry 上部署 dbt 项目 Docker 镜像。在我们的 dbt 项目容器化并安全存储后,下一个关键步骤是确保 Cloud Composer 可以无缝获取这些 Docker 镜像并将 dbt 项目作为 Airflow DAG 执行。这就是软件包dbt-airflow发挥作用的地方。
在本节中,我们将探讨如何配置和使用 Cloud Composer 以及软件包dbt-airflow来自动运行 dbt 项目。通过集成这些工具,我们可以利用 Apache Airflow 的强大功能进行编排,同时保持容器化部署提供的灵活性和可扩展性。
为了确保该dbt-airflow包可以在 Cloud Composer 上呈现和执行我们的容器化 dbt 项目,我们需要提供以下内容:
- 清单文件的路径:文件在 Google Cloud Storage (GCS) 存储桶中的位置
manifest.json,该文件由我们的 GitHub Action 在 CI/CD 过程中推送 - Docker 镜像详细信息:Artifact Registry 上驻留的 Docker 镜像的相关详细信息,可
dbt-airflow使用KubernetesPodOperator
以下是 Airflow DAG 的完整定义:
import functools
from datetime import datetime
from datetime import timedelta
from pathlib import Path
from airflow import DAG
from airflow.operators.empty import EmptyOperator
from airflow.operators.python import PythonOperator
from dbt_airflow.core.config import DbtAirflowConfig
from dbt_airflow.core.config import DbtProfileConfig
from dbt_airflow.core.config import DbtProjectConfig
from dbt_airflow.core.task_group import DbtTaskGroup
from dbt_airflow.operators.execution import ExecutionOperator
with DAG(
dag_id='test_dag',
start_date=datetime(2021, 1, 1),
catchup=False,
tags=['example'],
default_args={
'owner': 'airflow',
'retries': 1,
'retry_delay': timedelta(minutes=2),
},
'on_failure_callback': functools.partial(
our_callback_function_to_send_slack_alerts
),
) as dag:
t1 = EmptyOperator(task_id='extract')
t2 = EmptyOperator(task_id='load')
tg = DbtTaskGroup(
group_id='transform',
dbt_airflow_config=DbtAirflowConfig(
create_sub_task_groups=True,
execution_operator=ExecutionOperator.KUBERNETES,
operator_kwargs={
'name': f'dbt-project-1-dev',
'namespace': 'composer-user-workloads',
'image': 'gcp-region-docker.pkg.dev/gcp-project-name/ar-repo/my-dbt-project:latest',
'kubernetes_conn_id': 'kubernetes_default',
'config_file': '/home/airflow/composer_kube_config',
'image_pull_policy': 'Always',
},
),
dbt_project_config=DbtProjectConfig(
project_path=Path('/home/my_dbt_project/'), # path within docker container
manifest_path=Path('/home/airflow/gcs/dags/dbt/my_dbt_project/target/manifest.json'), # path on Cloud Composer GCS bucket
),
dbt_profile_config=DbtProfileConfig(
profiles_path=Path('/home/my_dbt_project/profiles/'), # path within docker container
target=dbt_profile_target,
),
)
t1 >> t2 >> tg一旦 Airflow 调度程序拾取文件,您的 dbt 项目将无缝转换为 Airflow DAG。此自动化过程将您的项目转换为一系列任务,并在 Airflow UI 中直观呈现。
如下面的屏幕截图所示,DAG 已构建并准备按照定义的时间表执行。此可视化不仅可以清晰地了解 dbt 任务的流程和依赖关系,还可以方便地进行监控和管理,确保您的数据转换顺利高效地运行。
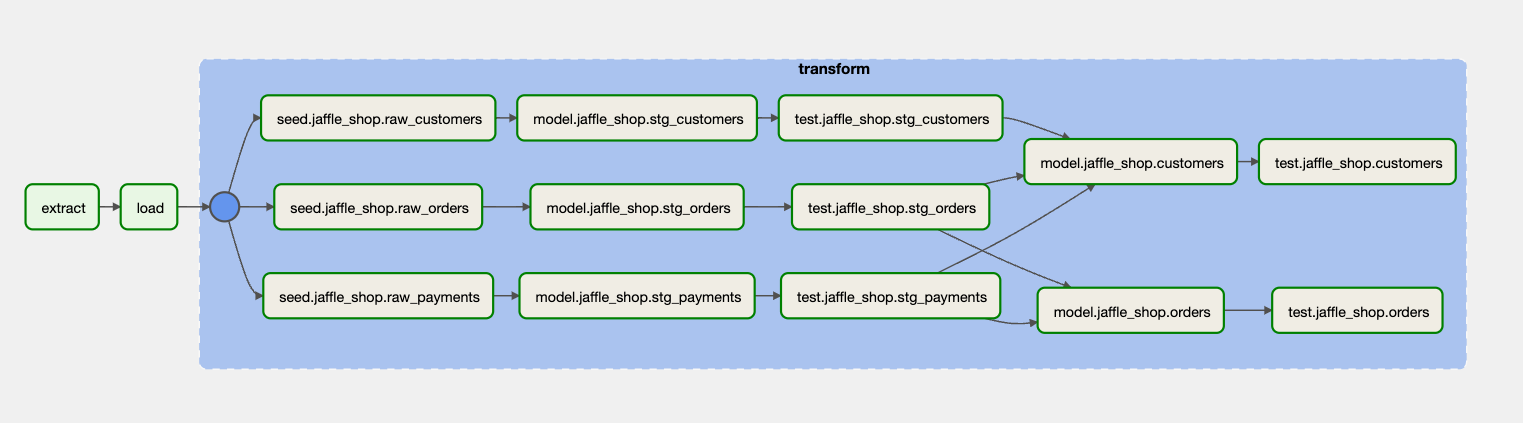
使用 dbt-airflow 自动渲染的 dbt 项目
虽然这个概述为您提供了基础性的了解,但涵盖该dbt-airflow软件包的全部功能和配置选项超出了本文的范围。
感谢关注雲闪世界。(亚马逊aws和谷歌GCP服务协助解决云计算及产业相关解决方案)
订阅频道(https://t.me/awsgoogvps_Host)
TG交流群(t.me/awsgoogvpsHost)