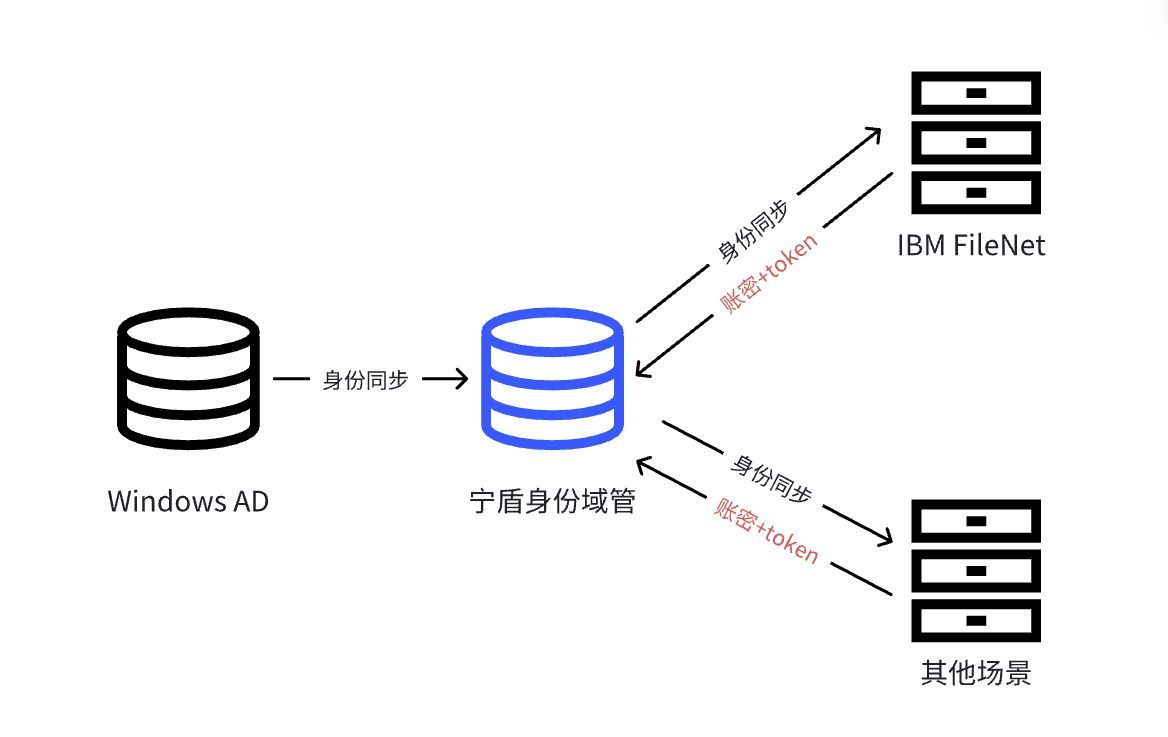
一、概述
在数据库系统中,索引是一种用于加快数据检索的数据结构。不同的索引结构适用于不同的查询场景和数据特性。索引按照不同角度可以划分不同类型的索引。按照数据结构可以划分B+Tree索引、Hash索引、FULL TEXT(全文)索引、R-Tree(空间)索引
二、索引结构
mysql的索引是作用于存储引擎上的,不同的存储引擎支持不同数据结构的索引。mysql中按照索引结构可以划分B+树索引、Hash索引、FULL TEXT索引(全文索引)、R-Tree索引四种索引结构。
| 索引结构 | 描述 | InnoDB | MsylSAM | Memory |
| B+Tree索引 | 最常用的索引类型,是一种自平衡树的数据结构。大多数引擎都支持,适用于大数据的排序和搜索 | 支持 | 支持 | 支持 |
| Hash索引 | 基于hash表实现,通过hash函数计算键值的hash值快速精准定位数据,不支持范围和排序查询 | 不支持 | 不支持 | 支持 |
| Full Text(全文)索引 | 是一种通过建立倒序排序,快速检索文本的方式,适用于文本密集性的查询。很少使用 | 5.6版本后支持 | 支持 | 不支持 |
| R-tree(空间)索引 | 是B树像多维空间发展的一种方式,是一种特殊的索引类型,主要用于地理空间类型的查询 | 不支持 | 支持 | 不支持 |
在mysql中支持Hash索引的是Memory引擎;而InnoDB引擎具有自适应Hash索引的功能,根据B+树索引在指定条件下自动构建的。
1、B+Tree索引
1.1 原理
B+Tree
B+树是由二叉树 —> 红黑树(自平衡二叉树)—> B-Tree树(多路平衡查找树)演化而来的。B+树也是多路平衡查找树,相对于B-Tree,所有数据都存储在叶子节点上,根节点只起到索引作用。所有叶子节点形成了一个单向链表。叶子节点将数据按照大小排列,且相邻叶子节点按照大小排列。非叶子节点只起到索引作用。

Mysql的B+Tree索引
mysql的索引结构对经典的B+Tree进行了优化,在原来B+tree基础上,增加了一个指向相邻叶子节点的链表指针,所有叶子节点形成了双向循环链表,提高查询效率。

1.2 特点
a. B+Tree是一种多路自平衡树的数据结构,它能够保持数据排序、搜索、插入和删除操作的时间复杂度都为O(logn)。
b. 所有值都存储在叶子节点上,每个节点可以有多个叶子节点,使得B+Tree的高度较低,从而减少磁盘的IO操作。
1.3 优缺点
优点
a. 高效数据检索:由于B+Tree层级较低,查询速度快。
b. 支持范围查询:由于叶子节点通过指针相互链接,形成双向链表,可以快速进行范围查询。
c. 减少IO操作:每个节点有多个叶子节点存储多个键值对,可以减少IO操作次数。
缺点
a. 消耗资源:在频繁的更新操作下,B+Tree需进行分裂和合并操作保持平衡,这会大幅消耗资源。
1.4 使用场景
B+Tree索引是数据库常见的索引类型之一,特别适用于大量数据的排序和查询场景。
2、Hash索引
2.1 原理
Hash索引是基于hash表实现,通过hash函数计算键值对的hash值,映射到一个桶中,桶中存储了所有hash值相同的数据行的指针,然后hash值和数据行指针存储在hash表中。查询时,mysql通过hash函数计算出查询条件的hash值,在hash表中找到hash值对应的桶,在桶中找到对应数据行的指针。
哈希冲突
当两个或多个键值映射到的同一个桶中的槽位时,则就发生hash冲突。hash冲突时 通过链表解决

2.2 特点
a. hash索引的查询效率理论比B+Tree索引快,因为可以通过hash值直接定位数据,无需B+Tree逐层查找。
b. hash索引只能用于对等比较(=、in),不支持范围查询(between、<、>、…)。
c. 对于联合索引,hash索引不能使用部分索引键查询(要么全部使用、要么全部不使用)。
d. 无法避免全表扫描,即每次都要全表扫描。
2.3 优缺点
优点
a. 查询速度快:只需一次hash运算就能定位到数据。
缺点
a. 不支持范围查询:由于hash索引是基于hash值定位的,因此无法直接用于范围查询。
b. 不支持排序操作:hash索引无法利用索引进行查询。
c. 稳定性差:在hash冲突严重情况下,性能下降厉害。
2.4 使用场景
hash索引适用于等值查询场景,如查询某个特定用户的记录。
3、Full-Text索引
3.1 原理
通过建立倒排索引(Inverted Index)构建Full-Text索引,提高数据的检索效率。
倒排索引是一种将文档中的单词或汉字映射到其出现位置的数据结构,主要用来解决判断字段的值中是否包含某字符或汉字的问题。
对于简单的业务或数据量小的业务,可以通过Like关键字判断,对于大数据量的业务,使用like效率大大降低,可以使用Full-Text索引。
InnoDB在5.6之后只支持英文的全文索引,不支持中文索引。可以通过内置分词器(ngram)来支持中文索引。
ngram分词器在建立索引时会对字段中的值进行分词,在进行查询时也会对要查询的内容分词。
中文检索执行过程:输入的查询内容 ——> SQL执行引擎 ——> ngram对内容分词 ——> 把分词后的词依次的去倒排索引中查找 ——> 将查询的记录返回。
3.2 特点
a. Full-Text索引是为了更快的进行文本搜索而设计的特殊类型索引。
b. 适用于包含大量文本的列,如文章、评论或描述性字段的查询。
3.3 优缺点
优点
a. 支持全文检索:可以搜索文本中的词汇而非整个字符串的匹配。
b. 灵活的搜索方式:支持自然语言搜索和布尔搜索。
缺点
a. 占用磁盘空间:Full Text索引会占用一定的索引空间。
b. 数据插入开销大:在创建索引时需对文本进行分词处理。
3.4 使用场景
在搜索引擎、内容管理系统等文本密集性应用场景中非常实用。
4、R-Tree(树)索引
4.1 原理
R-树是B-树在高维度空间的扩展,也是一颗平衡树。每个R树的叶子结点包含了多个指向不同数据的指针,这些数据可以是存放在硬盘中的,也可以是存在内存中。根据R树的这种数据结构,当我们需要进行一个高维空间查询时,我们只需要遍历少数几个叶子结点所包含的指针,查看这些指针指向的数据是否满足要求即可。这种方式使我们不必遍历所有数据即可获得答案,效率显著提高。如图:

R-树运用了空间分割的理念,采用一种MBR(Minimal Bounding Rectangle)的方法将空间数据分割成多个矩形区域。每个节点可以表示一个矩形区域,同时可以包含其他节点或数据项。这种层级结构允许Mysql在空间查询中更快的定位到所需的数据,减少搜索范围,从而提高查询速度。
4.2 特点
a. R-树是B-树向多维空间发展的一种方式,用于处理多维数据。
b. 将对象空间进行矩形划分,每个节点都对应一个矩形区域。
4.3 优缺点
优点
a. 高效的空间查询:通过空间划分和索引,可以快速定位空间对象。
b. 支持多维数据:R-树可以处理二位或多维数据。
缺点
a. 在数据密集或重叠较多的情况下,索引使用效率会降低。
4.4 使用场景
R-树索引特别适用于地理空间数据的索引,如点、线、面等空间对象的索引。
三、总结
以上四种索引结构各有其特点和适用场景。B+树索引是数据库中最常用的索引类型之一,适用于大量数据的排序和搜索;Hash索引适用于等值查询且查询速度快;R-树索引特别适用于地理空间数据的索引;Full Text索引则适用于文本密集型应用的全文搜索。在选择索引类型时,需要根据具体的应用场景和数据特点来决定。
参考:
从B树、B+树、B*树谈到R 树-CSDN博客
MySQL索引1——索引基本概念与索引结构(B树、R树、Hash等)_mysql索引b树和hash-CSDN博客






![[Bugku] web-CTF靶场详解!!!](https://i-blog.csdnimg.cn/direct/8c9b7abb9ede4055804bb15b787e0e75.png)