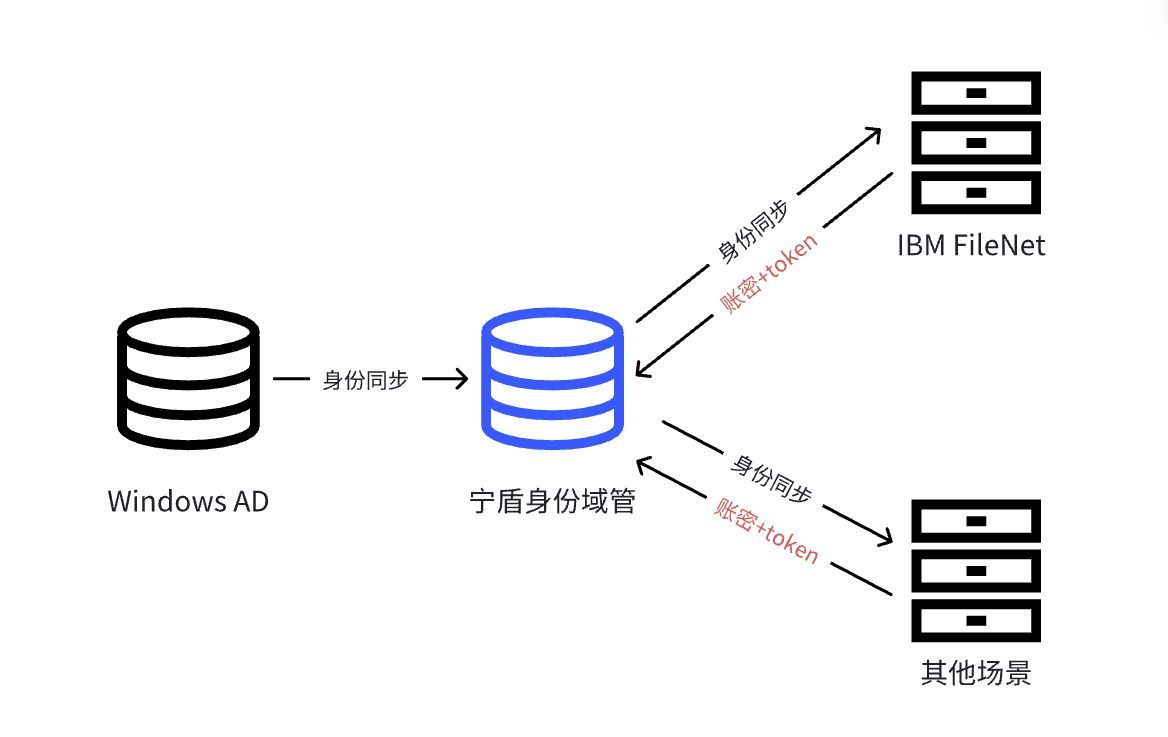
背景介绍
前两天我自己玩玩搞搞一个音频转文字服务,基于 faster-whisper,本想着这个已经是很快的了,没想到还有比它更快的,今天就来介绍使用一下。
FunClip,是阿里巴巴推出的一个智能视频剪辑工具,它结合了人工智能技术,特别是语音识别和自然语言处理,提供了一种全新的视频剪辑体验。通过集成阿里巴巴通义实验室的 FunASR Paraformer 系列模型,FunClip 能够对视频中的语音内容进行自动识别,并根据识别结果进行视频剪辑。
我们就是利用它的语音识别和自然语言处理的一部分功能,快速实现对音频,以及视频进行文字转录
注意:目前仅支持中文,后续有可能会迭代加入英文或者其他更多语言
GitHub项目地址:https://github.com/alibaba-damo-academy/FunClip
功能特点
1:语音识别与转录:FunClip 利用 FunASR Paraformer 系列模型进行视频语音的自动识别,并将语音转换为文字,支持热词定制化和说话人识别,提升了特定词汇的识别准确率,并能自动生成 SRT 字幕文件。
2:视频剪辑:用户可以根据识别结果中的文本片段或说话人,快速裁剪出所需视频片段。FunClip 支持多段剪辑,并提供了灵活的编辑能力,用户可以在剪辑过程中自由组合多个视频片段。
3:用户界面:FunClip 提供了简洁明了的用户界面,操作简单易懂,支持在服务端搭建服务,并通过浏览器进行视频剪辑。
4:部署方式:FunClip 支持本地部署,用户可以通过简单的命令行操作进行安装和启动。
本地部署
1:利用 git 或者 直接下载代码到本地,推荐使用git
git clone https://github.com/alibaba-damo-academy/FunClip.git
2:安装依赖,需要本地有python环境,推荐python>=3.10
cd FunClip
pip install -r ./requirements.txt
3:启动项目服务,会自动下载所需模型以及依赖,集成了操作页面,可以访问返回的地址链接进行浏览器访问
python funclip/launch.py
4:不依赖界面,使用命令行进行操作 -------------- 识别语音
python funclip/videoclipper.py --stage 1 --file /data/sese.mp4 --output_dir ./output
---------------------------------------------
--file:你要识别的音视频文件目录地址
--output_dir:生成的srt文件放到的文件夹
测试
使用一个233秒的音乐视频,从开始识别到输出结果,用了大概5秒钟,加上加载一些依赖,共用了14秒左右
(我的GPU服务器有点拉,配置好点的会更快)

这是生成的srt文件内容,会自动打点每句话的开始和结束时间

其他功能
1:识别说话人,可快速提取说话人的内容以及剪切说话人的所有镜头或者音频
2:自动加字幕
3:AI总结推理
结语
我是个开发者,比较喜欢用命令的方式调用,也粗读了一下项目代码,从入口文件 funclip/launch.py,里面有我觉得比较实用的定义的功能方法:
1:mix_recog:简单识别成文字
2:mix_recog_speaker : 识别成文字,并添加每句话是哪个说话人说的,带说话人的识别,srt里会有个spaker 的标识
3:mix_clip :剪切音视频的入口,可以根据说话内容和说话人进行定向剪切
4:llm_inference:用AI模型给你自动总结的,根据srt里的内容,你可以定义prompt,让AI给你提取内容剪切,推荐使用阿里的qwen系列,在阿里云百炼平台开通并拿到apikey,就能使用
5:AI_clip:智能剪切
😄😄😄😄😄😄😄😄😄😄😄😄😄😄其他更多功能自行发觉吧😄😄😄😄😄😄😄😄😄😄😄

![[Bugku] web-CTF靶场详解!!!](https://i-blog.csdnimg.cn/direct/8c9b7abb9ede4055804bb15b787e0e75.png)