文章目录
- 一、本次学习重点内容:
- 二、详细知识点介绍:
- 1、高质量编程简介
- 什么是高质量?
- 编程原则:
- 2、编码规范
- 注释:
- 代码格式:
- 命名规范
- 变量:
- 函数:
- package:
- 错误和异常处理:
- 错误的Wrap和 Unwrap:
- 错误判定:
- 3、性能优化简介
- 简介
- 4、性能优化建议
- BenchMark——性能测试
- Slice——预分配内存
- 切片:
- 陷阱——大内存为释放
- map——预分配内存
- 字符串处理
- 1、string拼接
- 2、strings.Builder
- 3、byteBuffer
- 性能测试:
- 空结构体
- 测试:
- 结果:
- Atomic包
- 测试:
- 结果:
- 三、个人总结:
一、本次学习重点内容:
-
本次学习的知识要点有哪些?
1、高质量编程
高质量编程简介
编码规范
性能优化建议2、性能调优实战
性能调优简介
性能优化基础指南
二、详细知识点介绍:
1、高质量编程简介
什么是高质量?
编写的代码能够达到正确可靠、简洁清晰的目标可称之为高质量代码。
各种边界条件是否考虑完备
异常情况处理
稳定性保证易读易维护
编程原则:
1、简单性
消除“多余的复杂性”,以简单清晰的逻辑编写代码。不理解的代码无法修复改进。
2、可读性
代码是写给人看的,而不是机器。编写可维护代码的第一步是确保代码可读。
3、生产力
团队整体工作效率非常重要。
2、编码规范
注释:
公共符号始终要注释
包中声明的每个公共的符号:变量、常量、函数以及结构都需要添加注释。
任何既不明显也不简短的公共功能必须予以注释。
无论长度或复杂程度如何,对库中的任何函数都必须进行注释。
代码格式:
推荐使用gofmt自动格式化代码
1、gofmt
Go语言官方提供的工具,能自动格式化Go语言代码为官方统一风格,常见IDE都支持方便的配置。
2、goimports
也是Go语言官方提供的工具,实际等于gofmt 加上依赖包管理。
自动增删依赖的包引用、将依赖包按字母序排序并分类。
命名规范
变量:
1、简洁胜于冗长
2、缩略词全大写,但当其位于变量开头且不需要导出时,使用全小写。
例如使用ServeHTTP而不是 ServeHttp
使用XMLHTTPRequest 或者xmlHTTPRequest
2、变量距离其被使用的地方越远,则需要携带越多的上下文信息。
全局变量在其名字中需要更多的上下文信息,使得在不同地方可以轻易辨认出其含义
函数:
1、函数名不携带包名的上下文信息,因为包名和函数名总是成对出现的
2、函数名尽量简短
3、当名为foo 的包某个函数返回类型Foo时,可以省略类型信息而不导致歧义
4、当名为foo的包某个函数返回类型T时(T并不是Foo),可以在函数名中加入类型信息
package:
1、只由小写字母组成。
2、不包含大写字母和下划线等字符简短并包含一定的上下文信息。例如schema、task等。
3、不要与标准库同名。例如不要使用sync或者strings。
以下规则尽量满足,以标准库包名为例:
不使用常用变量名作为包名。例如使用bufio而不是buf
使用单数而不是复数。例如使用encoding而不是encodings
谨慎地使用缩写。例如使用fmt在不破坏上下文的情况下比 format更加简短
错误和异常处理:
简单错误:
1、简单的错误指的是仅出现一次的错误,且在其他地方不需要捕获该错误。
2、优先使用errors.New 来创建匿名变量来直接表示简单错误。
3、如果有格式化的需求,使用 fmt.Errorf。
错误的Wrap和 Unwrap:
1、错误的Wrap 实际上是提供了一个error 嵌套另一个error的能力,从而生成一个 error的跟踪链。
2、在fmt.Errorf中使用: %w关键字来将一个错误关联至错误链中。
错误判定:
1、判定一个错误是否为特定错误,使用errors.ls
2、不同于使用==,使用该方法可以判定错误链上的所有错误是否含有特定的错误
3、在错误链上获取特定种类的错误,使用errors.As
3、性能优化简介
简介
1、性能优化的前提是满足正确可靠、简洁清晰等质量因素
2、性能优化是综合评估,有时候时间效率和空间效率可能对立
3、针对 Go语言特性,介绍Go相关的性能优化建议
4、性能优化建议
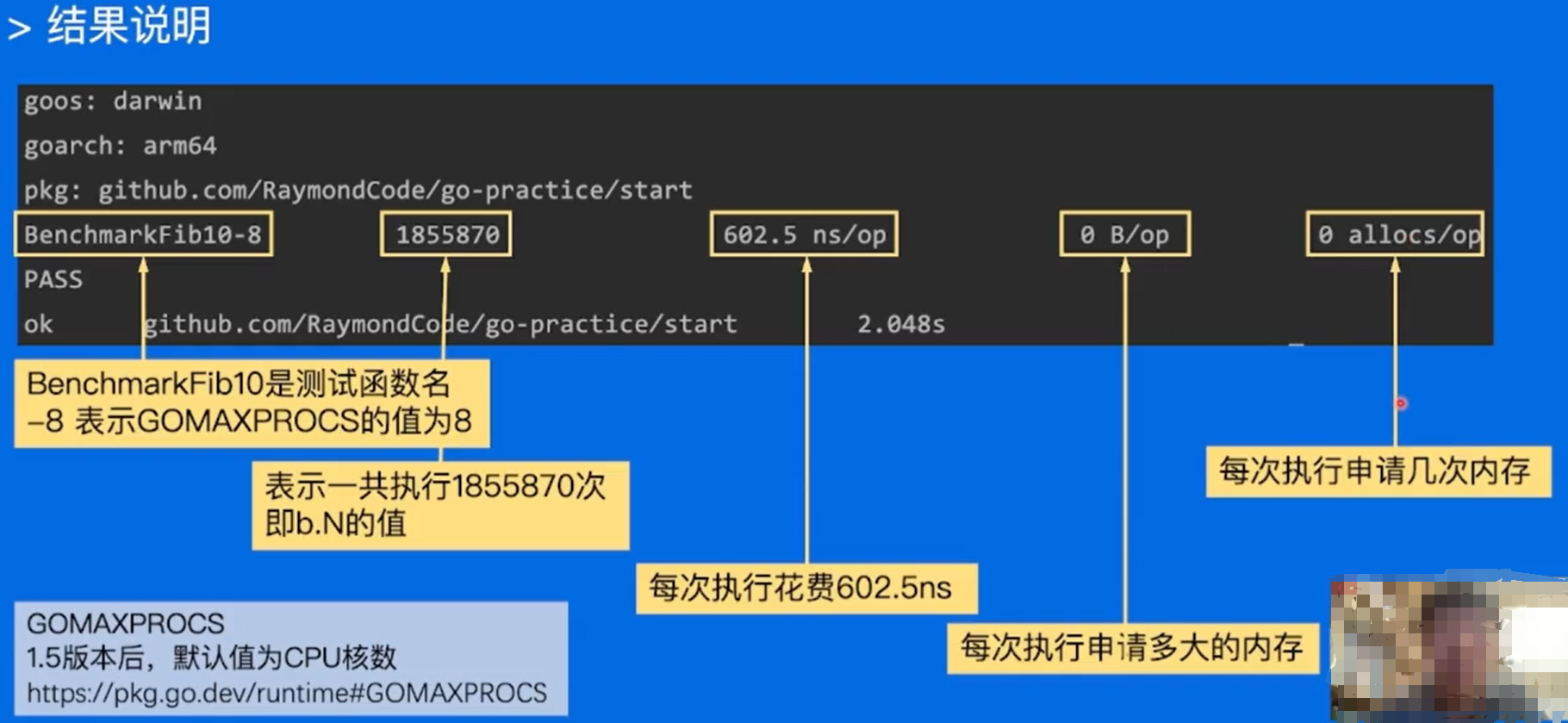
BenchMark——性能测试
性能表现需要实际数据衡量
Go语言提供了支持基准性能测试的benchmark工具
使用方式:
go test -bench=.-benchmem
测试函数:
func BenchmarkPlus(b *testing.B) {
b.ReportAllocs()
for i := 0; i < b.N; i++ {
//Plus(10, "ok")
}
}
结果:
Slice——预分配内存
尽可能使用make()初始化切片时的容量信息。(扩容需要消耗性能)
切片:

切片本质是一个数组片段的描述。
包括数组指针
片段的长度
片段的容量(不改变内存分配情况下的最大长度)
切片操作并不复制切片指向的元素,而是创建一个新的切片会复用原来切片的底层数组。
陷阱——大内存为释放
在已有切片基础上创建切片,不会创建新的底层数组场景。(会创建引用)
·原切片较大,代码在原切片基础上新建小切片
·原底层数组在内存中有引用,得不到释放
可使用copy替代re-slice。
map——预分配内存
原因:
1、不断向map中添加元素的操作会触发map 的扩容
2、提前分配好空间可以减少内存拷贝和 Rehash的消耗
3、建议根据实际需求提前预估好需要的空间
字符串处理
1、string拼接
func Plus(n int, str string) string {
s := ""
for i := 0; i < n; i++ {
s += str
}
return s
}
2、strings.Builder
func StrBuilder(n int, str string) string {
var builder strings.Builder
for i := 0; i < n; i++ {
builder.WriteString(str)
}
return builder.String()
}
3、byteBuffer
func ByteBuffer(n int, str string) string {
buf := new(bytes.Buffer)
for i := 0; i < n; i++ {
buf.WriteString(str)
}
return buf.String()
}
性能测试:
package 性能测试
import "testing"
func BenchmarkPlus(b *testing.B) {
b.ReportAllocs()
for i := 0; i < b.N; i++ {
Plus(10, "ok")
}
}
func BenchmarkStrBuilder(b *testing.B) {
b.ReportAllocs()
for i := 0; i < b.N; i++ {
StrBuilder(10, "ok")
}
}
func BenchmarkByteBuffer(b *testing.B) {
b.ReportAllocs()
for i := 0; i < b.N; i++ {
ByteBuffer(10, "ok")
}
}
结果:
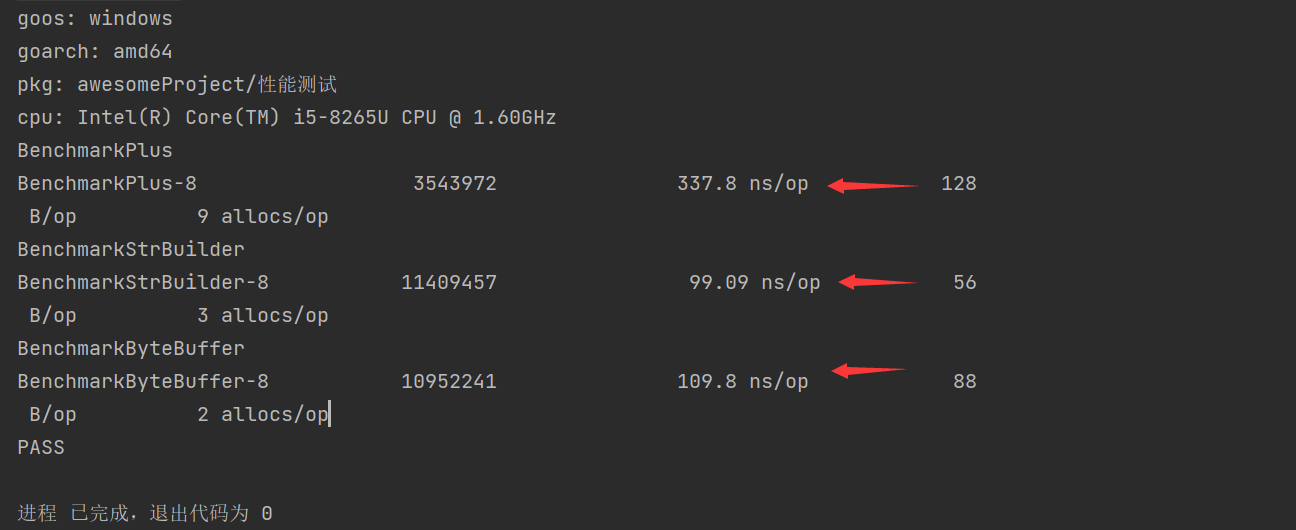
运行时间和内存占用上strings.Builder明显优于其他两个。
使用+拼接性能最差,strings.Builder,bytes.Buffer相近,strings.Buffer更快
分析:
字符串在Go语言中是不可变类型,占用内存大小是固定的,使用+每次都会重新分配内存。
strings.Builder,bytes.Buffer底层都是[]byte数组,内存扩容策略,不需要每次拼接重新分配内存。
空结构体
使用空结构体节省内存
空结构体struct实例不占据任何的内存空间可作为各种场景下的占位符使用
1、节省资源
2、空结构体本身具备很强的语义,即这里不需要任何值,仅作为占位符
测试:
Demo.go:
package 性能测试
func EmptyStructMap(n int) {
m := make(map[int]struct{})
for i := 0; i < n; i++ {
m[i] = struct{}{}
}
}
func BoolMap(n int) {
m := make(map[int]bool)
for i := 0; i < n; i++ {
m[i] = false
}
}
Demo_test.go:
package 性能测试
import "testing"
func BenchmarkEmptyStructMap(b *testing.B) {
b.ReportAllocs()
for i := 0; i < b.N; i++ {
EmptyStructMap(10)
}
}
func BenchmarkBoolMap(b *testing.B) {
b.ReportAllocs()
for i := 0; i < b.N; i++ {
BoolMap(10)
}
}
结果:
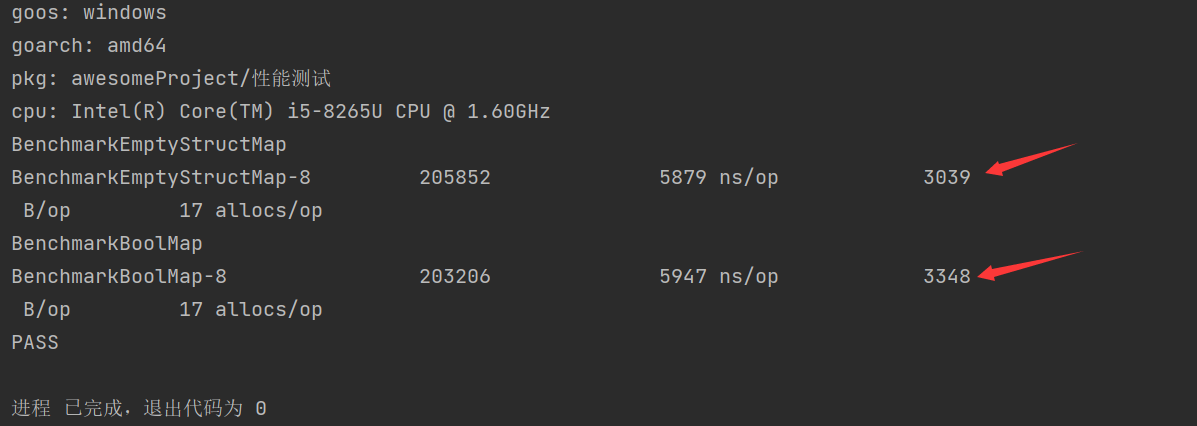
可以看到空就结构体更节省内存
Atomic包
测试:
Demo.go
package 性能测试
import (
"sync"
"sync/atomic"
)
type atomicCounter struct {
i int32
}
func AtomicAddOne(c *atomicCounter) {
atomic.AddInt32(&c.i, 1)
}
type mutexCounter struct {
i int32
m sync.Mutex
}
func MutexAddOne(c *mutexCounter) {
c.m.Lock()
c.i++
c.m.Unlock()
}
Demo_test.go
package 性能测试
import "testing"
func BenchmarkAtomicAddOne(b *testing.B) {
b.ReportAllocs()
a := atomicCounter{0}
for i := 0; i < b.N; i++ {
AtomicAddOne(&a)
}
b.Log(a.i)
}
func BenchmarkMutexAddOne(b *testing.B) {
b.ReportAllocs()
a := mutexCounter{}
for i := 0; i < b.N; i++ {
MutexAddOne(&a)
}
b.Log(a.i)
}
结果:
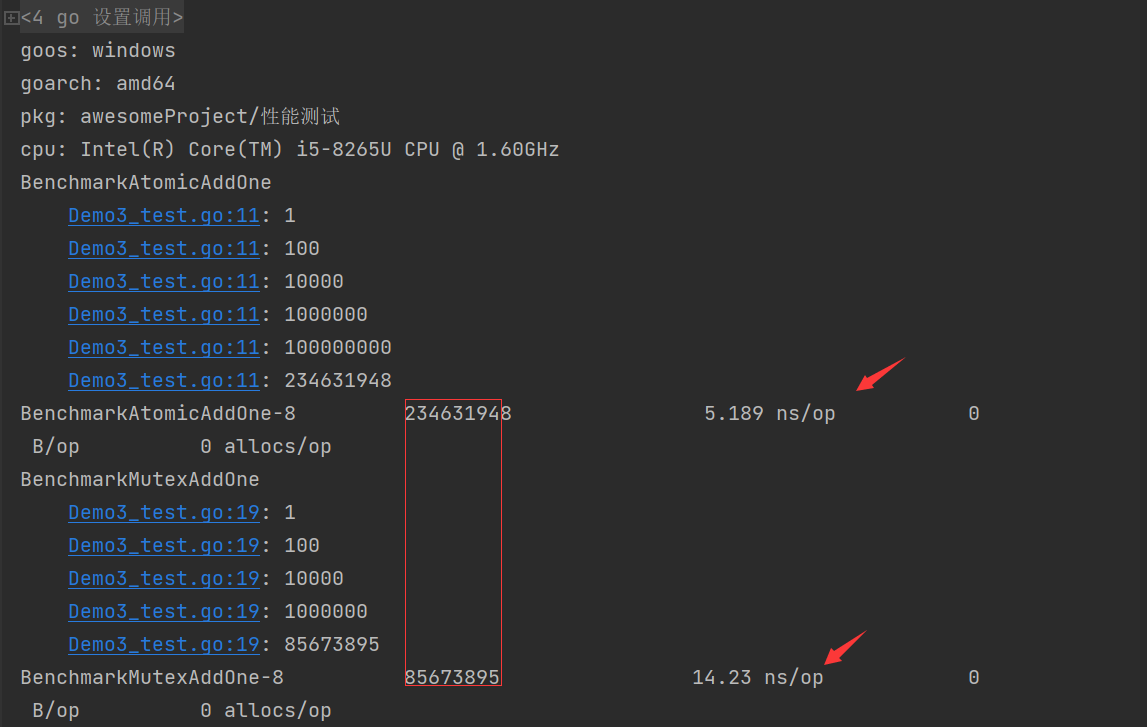
可以看到使用了Atomic包比使用锁快了8倍左右。
原因:
锁的实现是通过操作系统来实现,属于系统调用
atomic操作是通过硬件实现,效率比锁高
建议:
sync.Mutex应该用来保护一段逻辑,不仅仅用于保护一个变量
对于非数值操作,可以使用atomic.Value,能承载一个interface
三、个人总结:
本次学习内存包括go中的编码规范和基础性能优化。编码规范很重要,好的修改才能写出通俗易懂的代码,才能更好的构建一个个大型项目。性能优化方面避免常见的性能陷阱可以保证大部分程序的性能普通应用代码,不要一味地追求程序的性能越高级的性能优化手段越容易出现问题在满足正确可靠、简洁清晰的质量要求的前提下提高程序性能。