如何评价Alexey Bochkovskiy团队提出的YoloV7? - 知乎
1, Selective Search,RCNN和FasterRCNN
机器视觉(CV) 超简指南 选择性搜索 Selective Search_哔哩哔哩_bilibili
【精读RCNN】03选择性搜索,selective search_哔哩哔哩_bilibili
3.selective search算法_哔哩哔哩_bilibili
1.1Faster RCNN理论合集_哔哩哔哩_bilibili
https://blog.csdn.net/qq_37541097/category_9394276.html
目标检测mAP计算以及coco评价标准_哔哩哔哩_bilibili
目标检测(1)-Selective Search - 知乎
Object Detection - handong1587
BEV - handong1587
李立宗cv的个人空间-李立宗cv个人主页-哔哩哔哩视频
一文读懂Faster RCNN - 知乎
Selective Search for Object Recognition
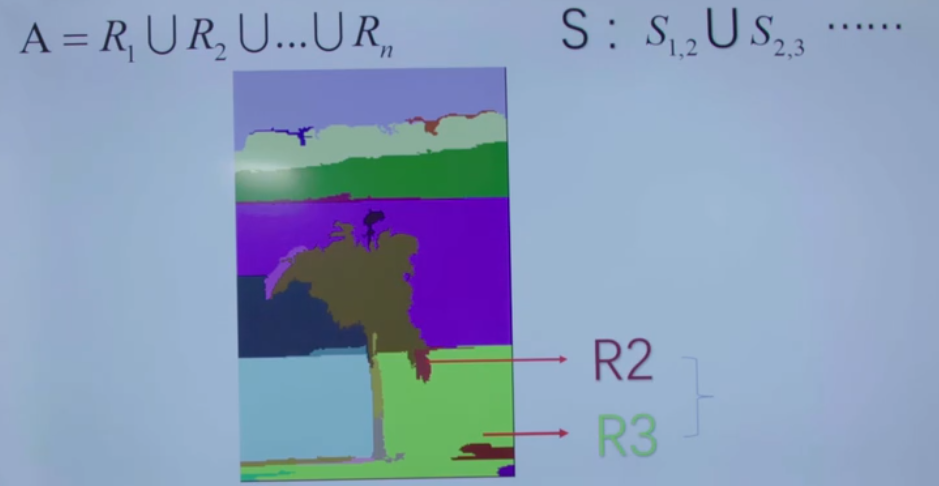
selective search的策略是,既然是不知道尺度是怎样的,那我们就尽可能遍历所有的尺度好了,但是不同于暴力穷举,我们可以先得到小尺度的区域,然后一次次合并得到大的尺寸就好了,这样也符合人类的视觉认知。既然特征很多,那就把我们知道的特征都用上,但是同时也要照顾下计算复杂度,不然和穷举法也没啥区别了。最后还要做的是能够对每个区域进行排序,这样你想要多少个候选我就产生多少个,不然总是产生那么多你也用不完不是吗?好了这就是整篇文章的思路了,那我们一点点去看。
















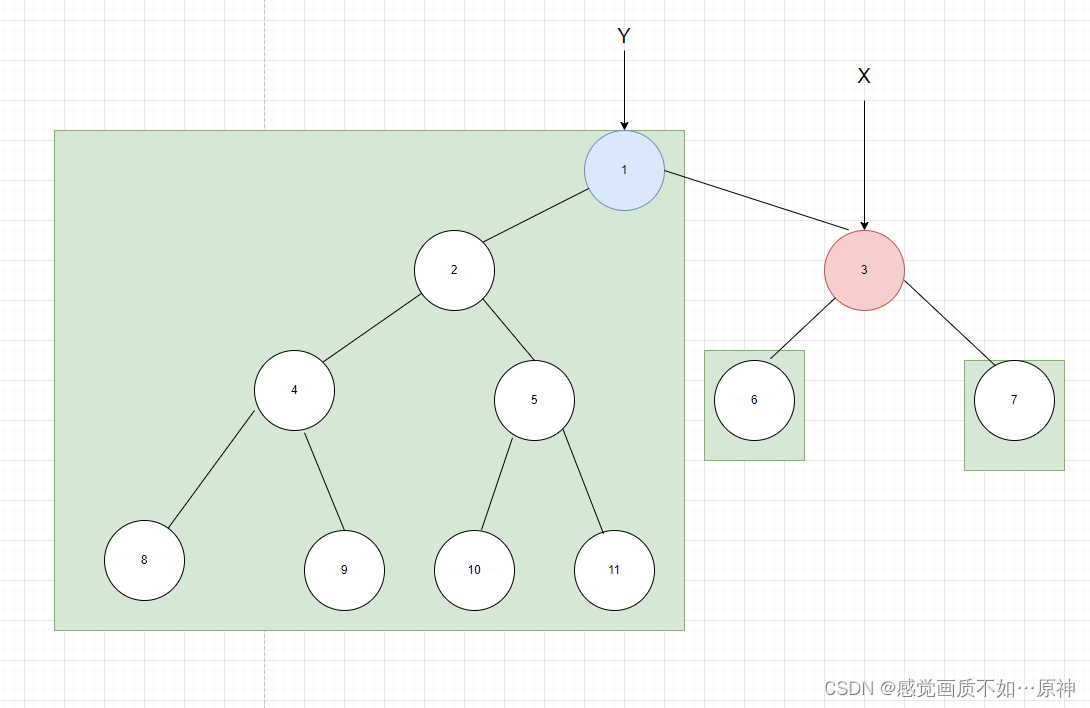
Region Proposal Networks 

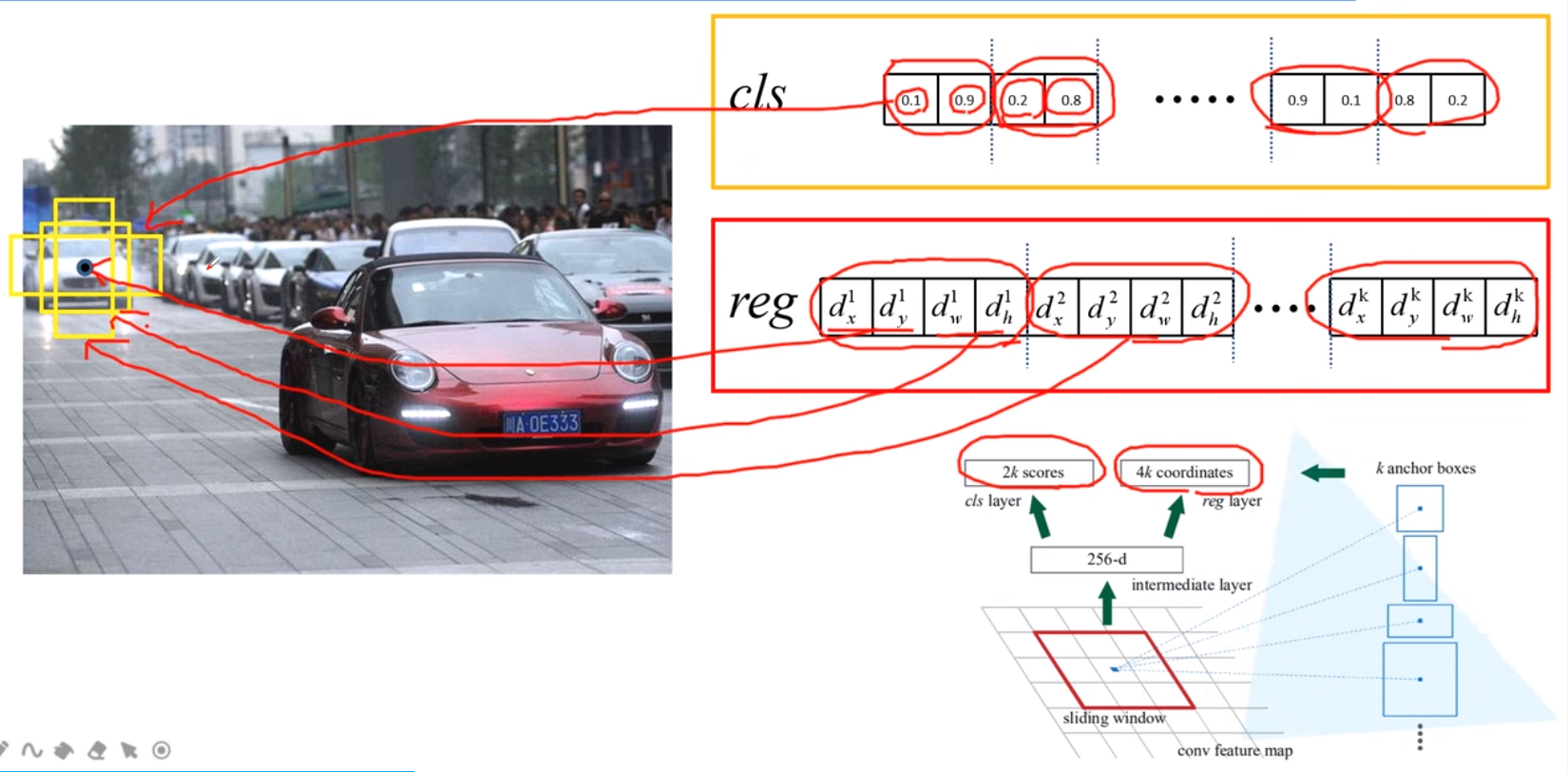




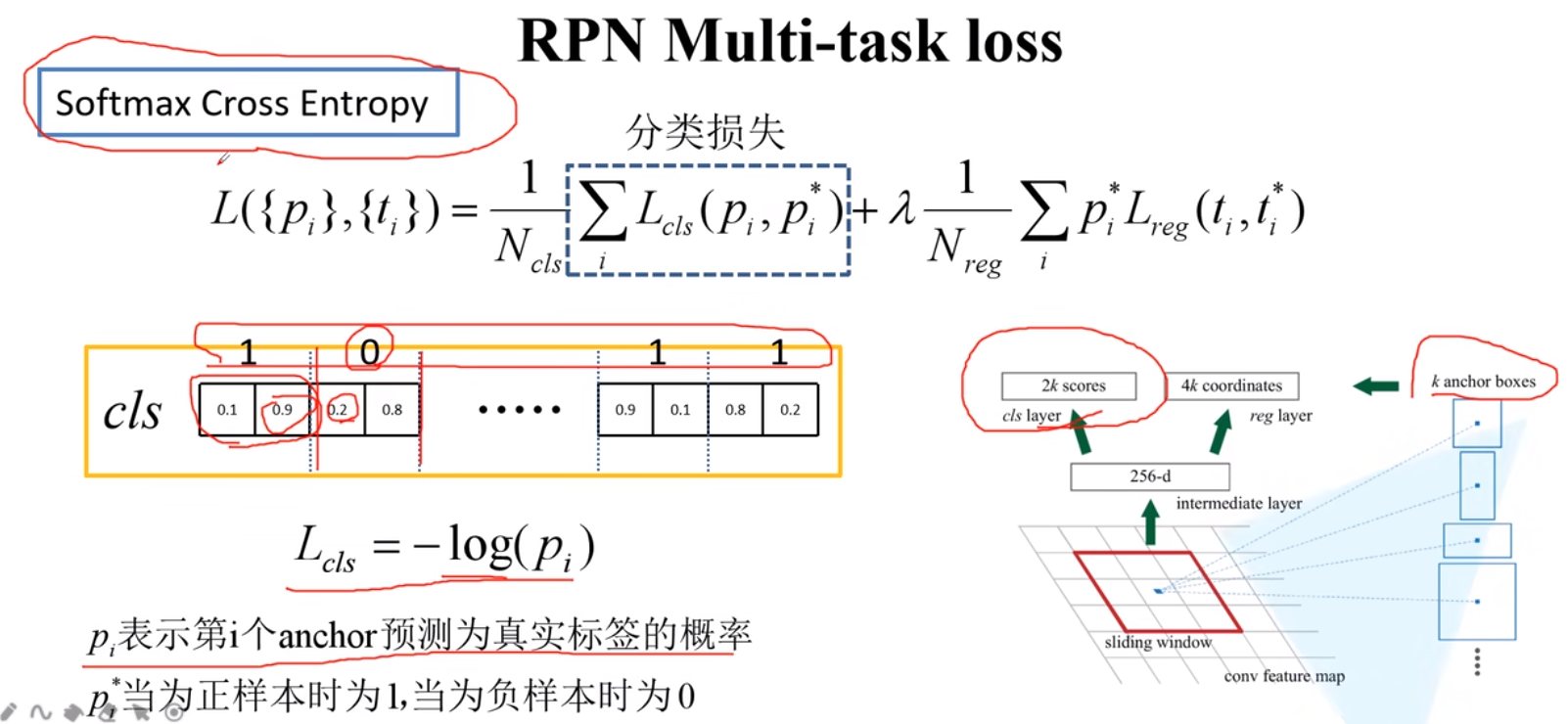

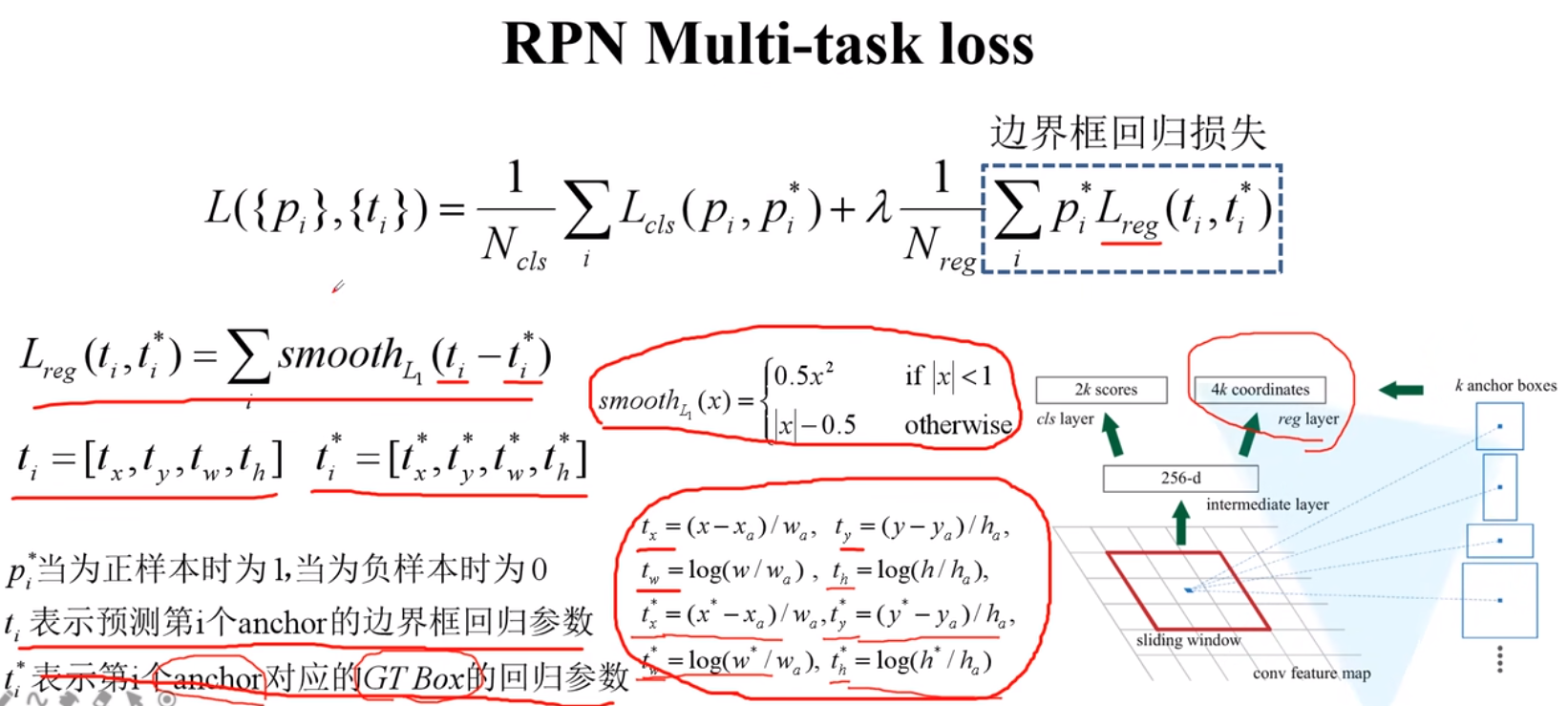

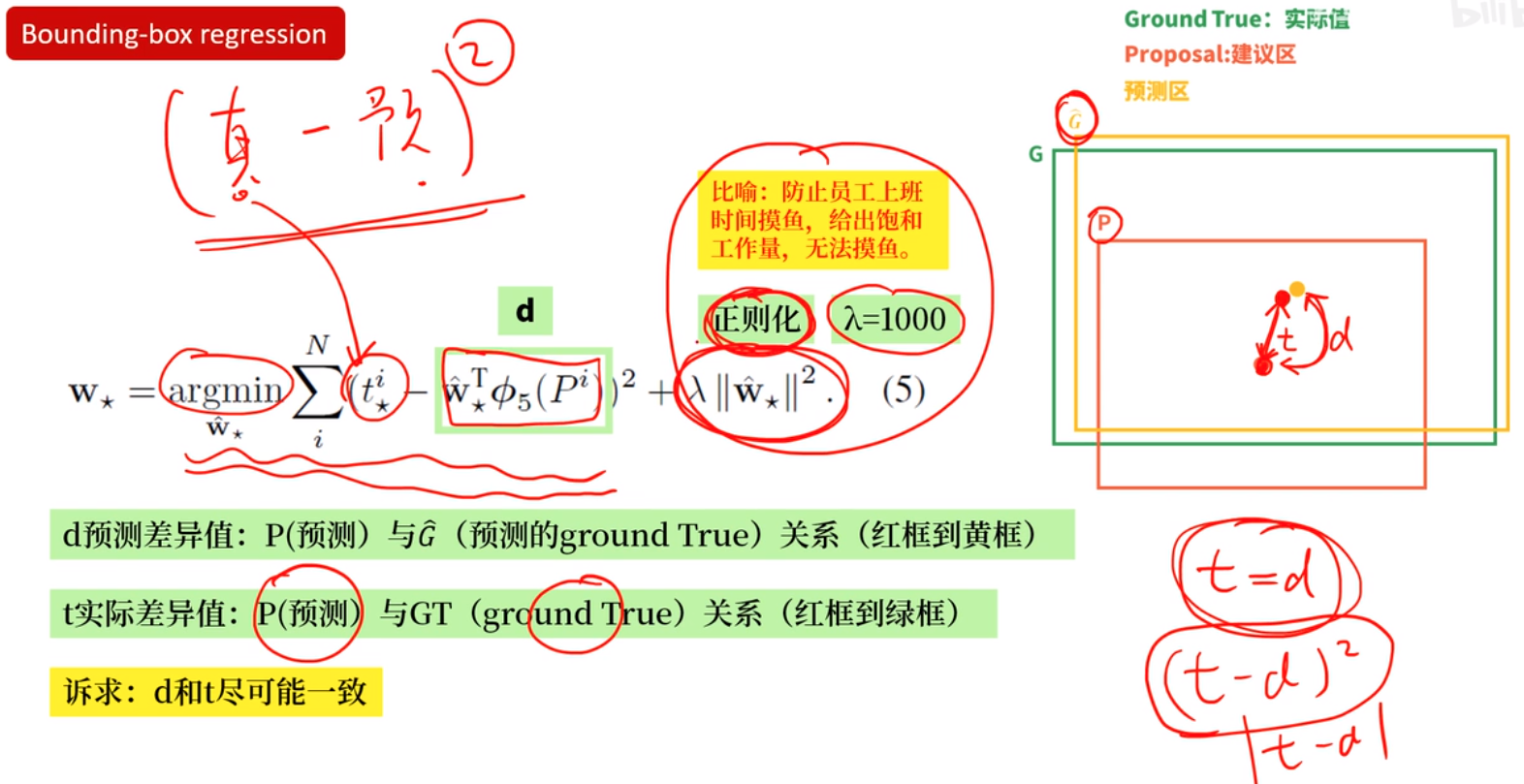
边框回归
42 锚框【动手学深度学习v2】_哔哩哔哩_bilibili
【精读RCNN】05边框回归,bounding box regression_哔哩哔哩_bilibili
边框回归(Bounding Box Regression)详解_南有乔木NTU的博客-CSDN博客_bounding box regression
【边框回归】边框回归(Bounding Box Regression)详解 - 知乎
【目标检测】什么是边框回归 - 简书
目标检测anchor based 边框回归(Bounding Boxes Regression)策略总结 - 知乎
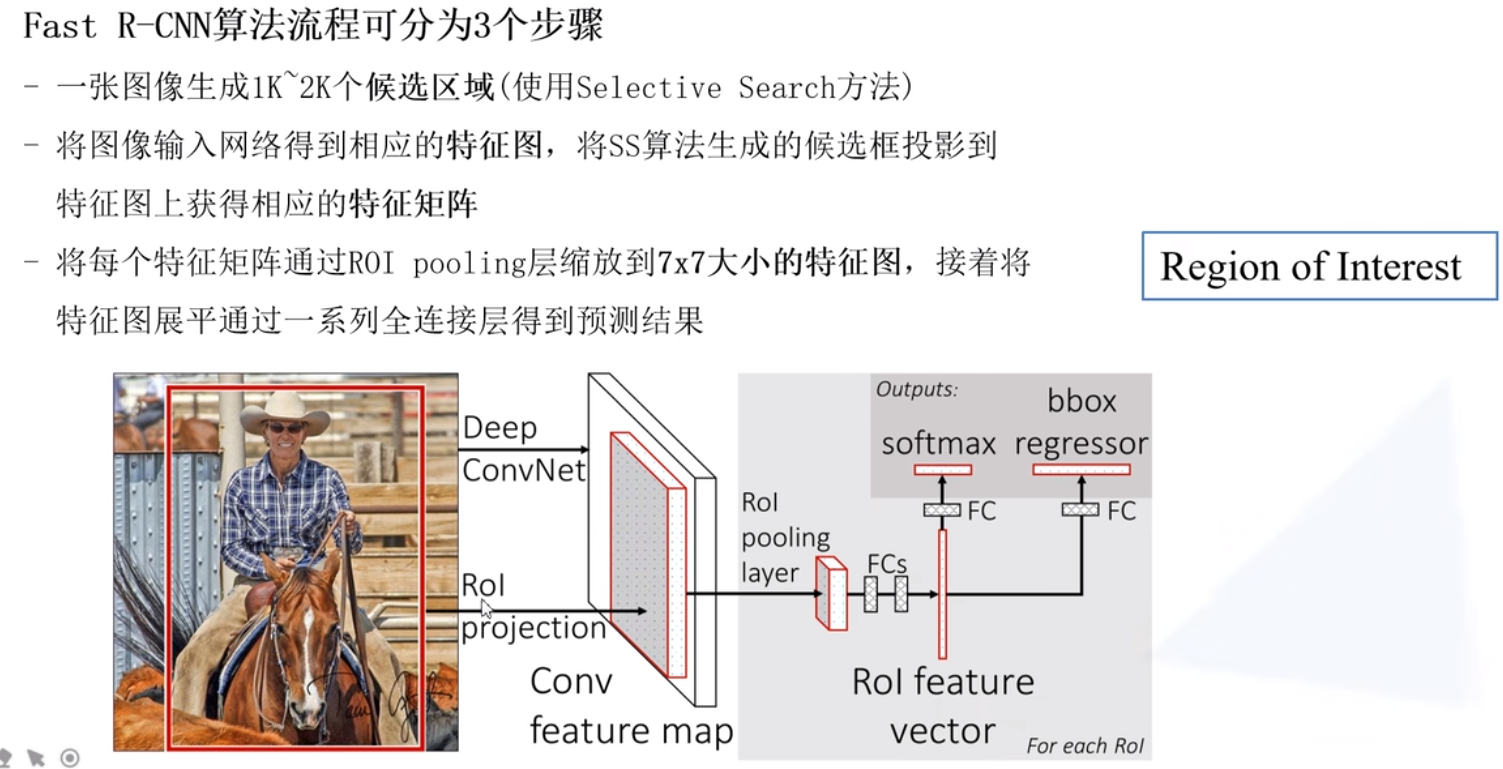
【目标检测】RoI Pooling及其改进 - 简书
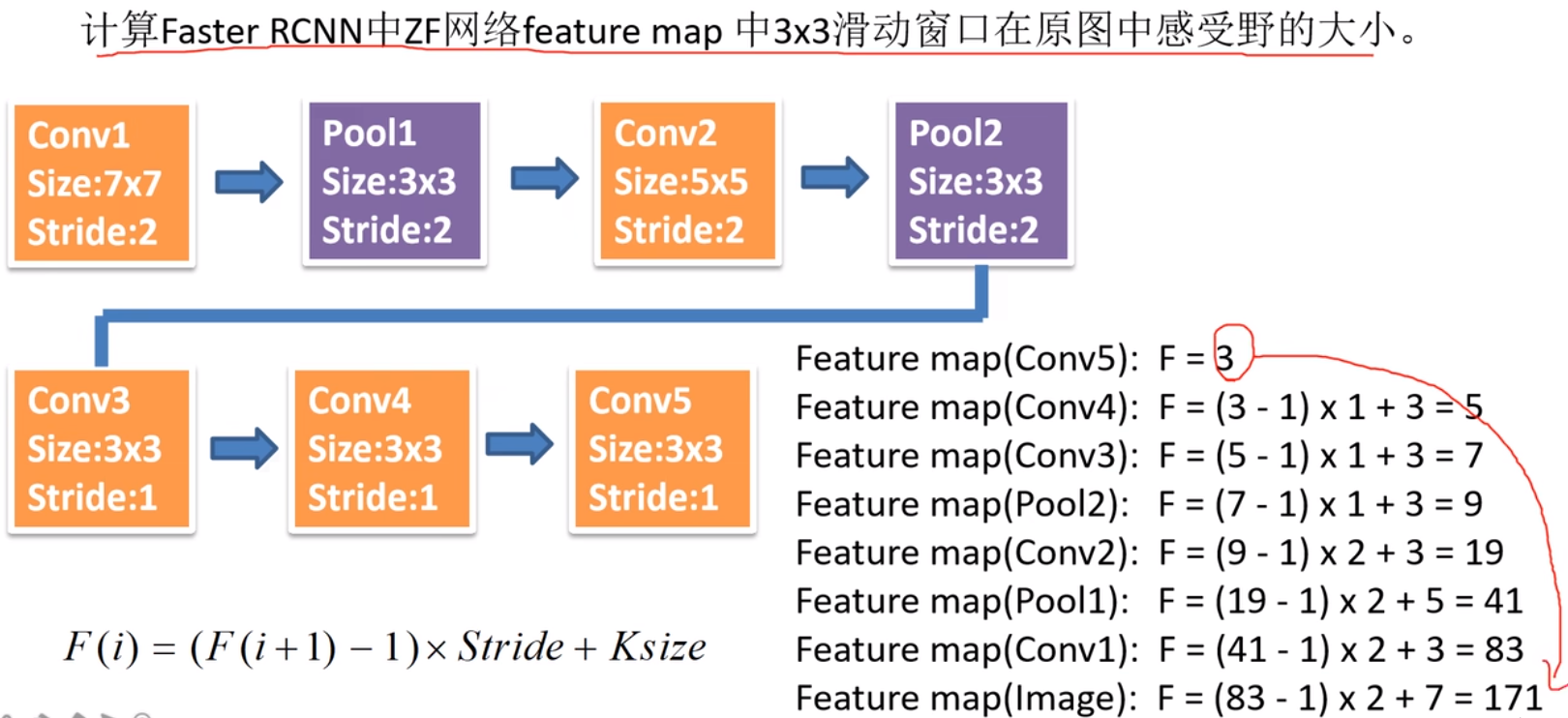
【目标检测】不同结构的感受野对CNN网络的影响_牧世的博客-CSDN博客
目标检测中的 Anchor 是什么?新手应该如何搞懂 Anchor? - 知乎
《目标检测》系列之三:目标检测Anchor的What/Where/When/Why/How - 知乎
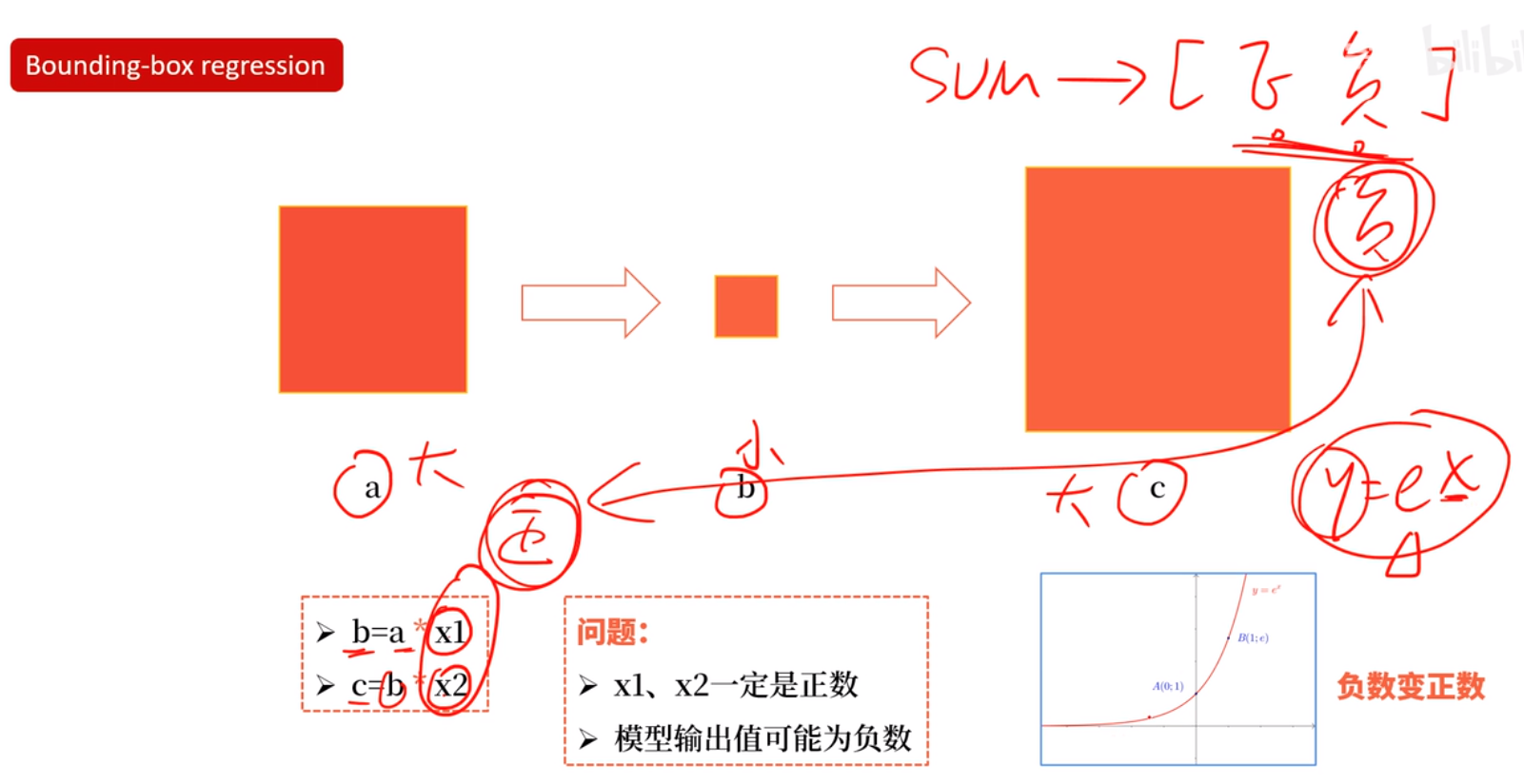
怎么回归呢,能不能直接回归呢?比如上图中cat的框左上角坐标为(100,60),右下角坐标为(600,640),能不能直接学习回归到这两个坐标上呢,答案当然是不能的,不然也不至于兜兜转转。主要原因在我们信息提取使用的是CNN卷积,卷积具有平移不变性和旋转不变性。
如上图,这里默认CNN提取特征为两只猫的特征是一样的,边框回归同函数求解一样,输入一个值,给出一个解,现在输入两个相同的特征,输出的坐标值应该是一样的,无法满足输出两个坐标框的要求,那怎样基于两个相同的特征输出相同的值,怎么对应到两个坐标上呢?通过相对坐标,相对于候选框。候选框的位置和大小不一样所以对应的相对坐标的位置和大小也就不一样了,完美解决了基于相同特征虽然输出相同的值,但是最后回归到不同位置和长宽的问题。
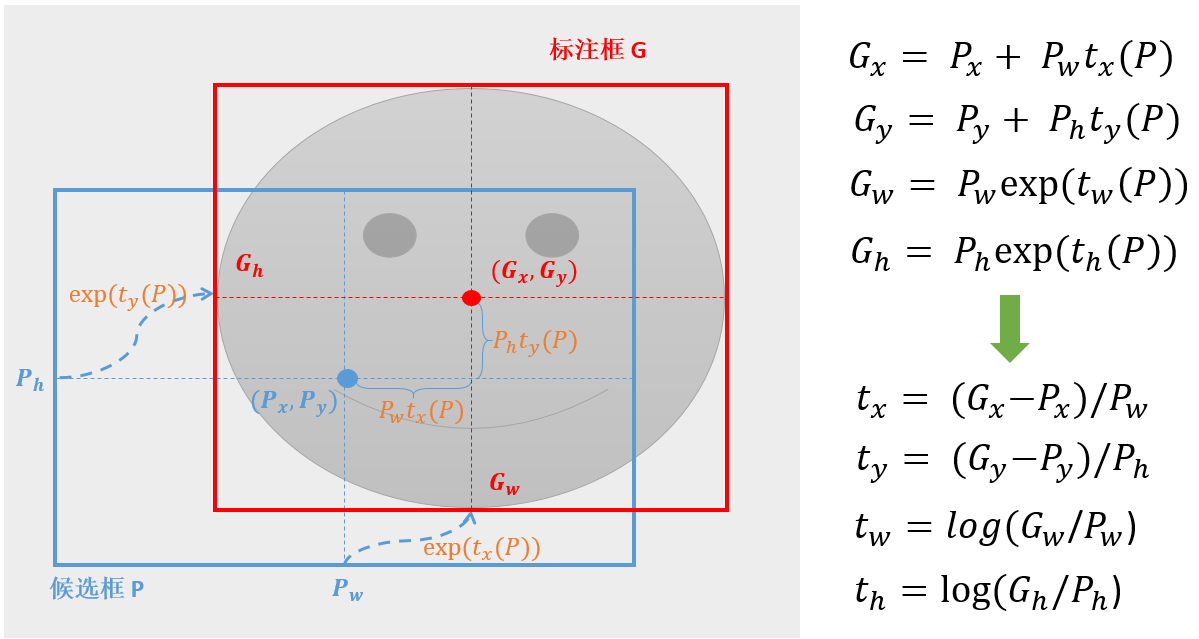
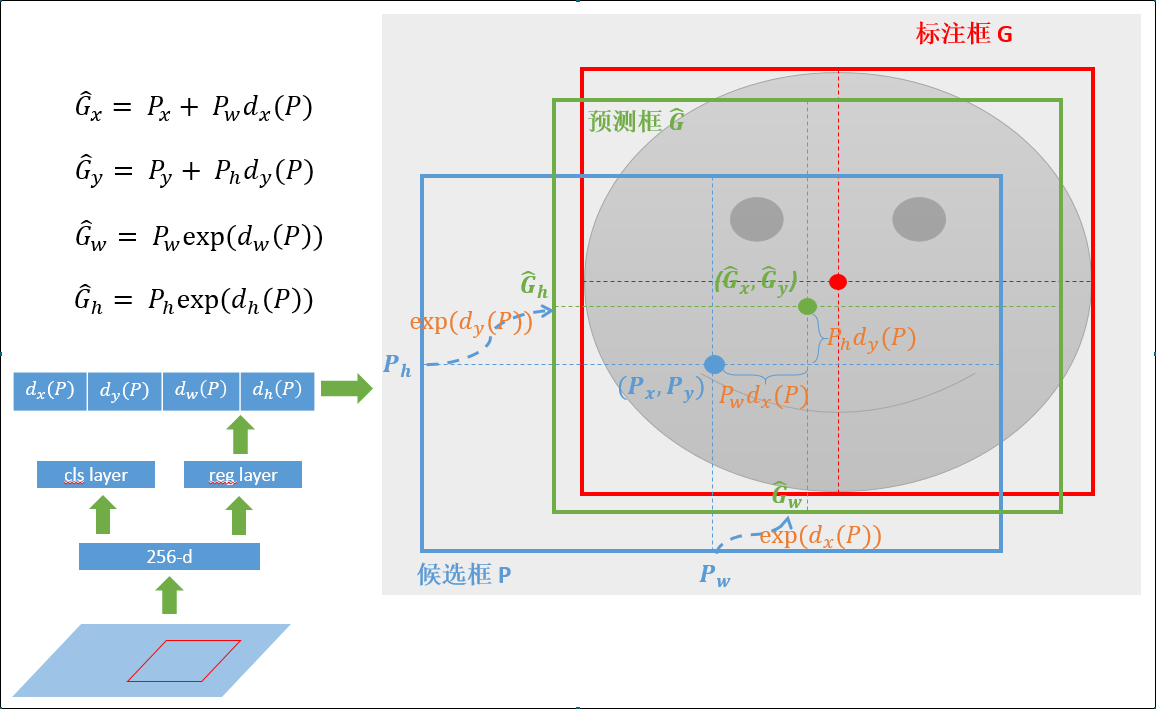
怎么基于候选框学习相对坐标?faster RCNN中,基于anchor框先做中心点的平移再做长宽的缩放。坐标乘以宽高是为了以平移的比例来计算,而宽高使用指数形式是为了保证缩放比例为正数。







2,SSD
睿智的目标检测3——SSD算法预测部分源码详解(亲测可用)_Bubbliiiing的博客-CSDN博客_ssd预测过程
科普:什么是SSD目标检测网络(Bubbliiiing 深度学习 教程)_哔哩哔哩_bilibili
损失函数解读 之 Focal Loss_一颗小树x的博客-CSDN博客_focal loss
- SSD是一种非常优秀的one-stage方法,one-stage算法就是目标检测和分类是同时完成的,其主要思路是均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,然后利用CNN提取特征后直接进行分类与回归,整个过程只需要一步,所以其优势是速度快。
- 但是均匀的密集采样的一个重要缺点是训练比较困难,这主要是因为正样本与负样本(背景)极其不均衡(参见Focal Loss),导致模型准确度稍低。
- SSD的英文全名是Single Shot MultiBox Detector,Single shot说明SSD算法属于one-stage方法,MultiBox说明SSD算法基于多框预测。
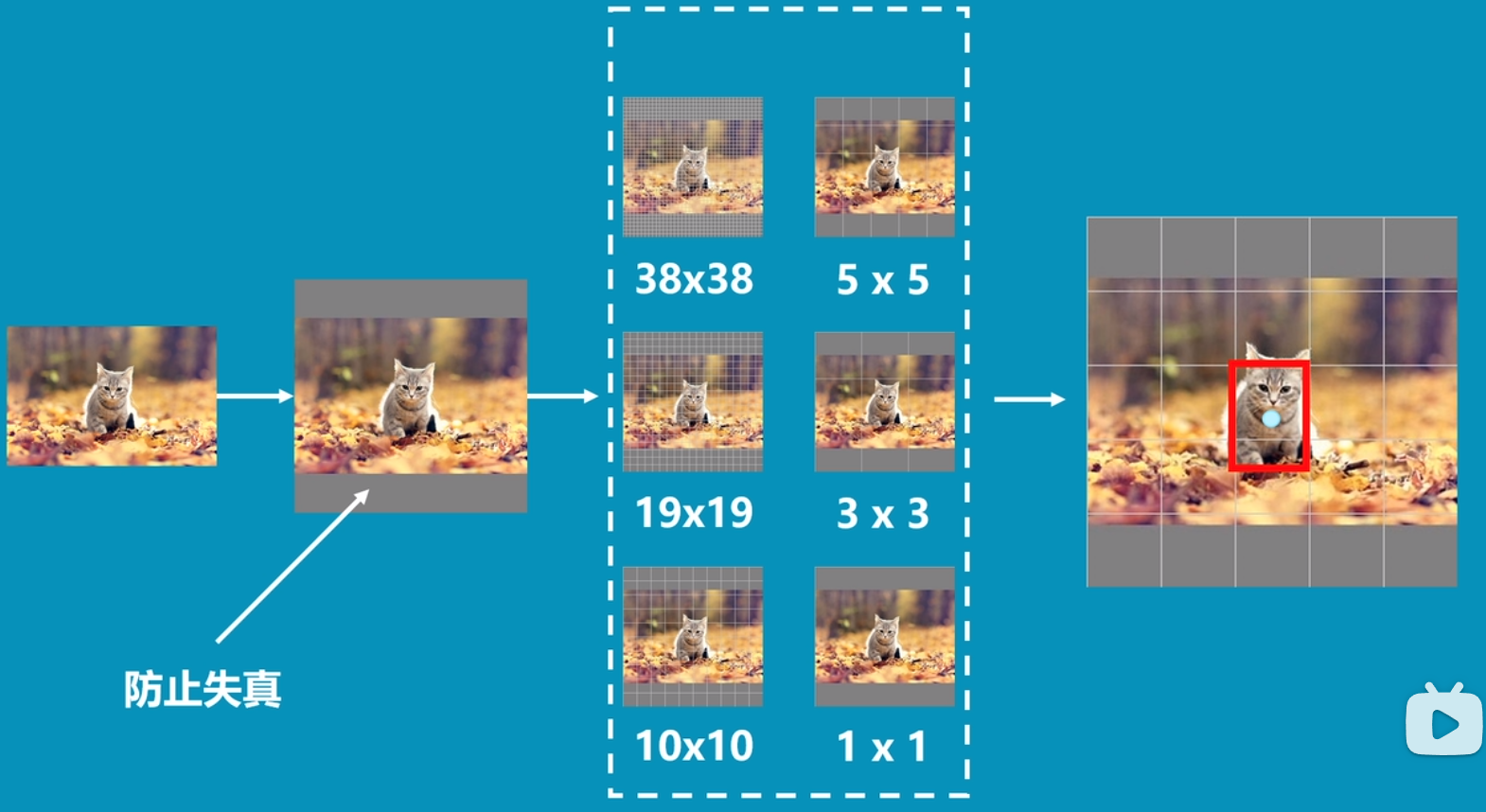
- 多次卷积后大目标的特征保存的更好,小目标特征会消失,需要在比较靠前的层提取小目标特征
- 我们选择其中的[‘block4’, ‘block7’, ‘block8’, ‘block9’, ‘block10’, ‘block11’]。
这里我们放出论文中的网络结构层。feat_layers=[‘block4’, ‘block7’, ‘block8’, ‘block9’, ‘block10’, ‘block11’]。
feat_shapes=[(38, 38), (19, 19), (10, 10), (5, 5), (3, 3), (1, 1)]。

2、为什么要抛弃anchor,做anchor free
1)Anchor的设置需要手动去设计(长宽比,尺度大小,以及anchor的数量),对不同数据集也需要不同的设计,相当麻烦。
2)Anchor的匹配机制使得极端尺度(特别大和特别小的object)被匹配到的频率相对于大小适中的object被匹配到的频率更低,DNN在学习的时候不太容易学习好这些极端样本。
3)Anchor的庞大数量使得存在严重的不平衡问题,这里就涉及到一个采样的过程,实际上,类似于Focal loss的策略并不稳定,而且采样中有很多坑。
4)Anchor数量巨多,需要每一个都进行IOU计算,耗费巨大的算力,降低了效率。
3、anchor free 的方向
最早可以追溯到YOLO算法,这应该是最早的anchor-free模型,而最近的anchor-free方法主要分为 基于密集预测 和 基于关键点估计两种。
4、anchor free 的局限性
目前paper 为了达到更好看的结果,在实验上隐藏了一些细节或者有一些不公平的比较(比如骨干网络使用hourglass 对比别人的resnet等)。
5、anchor free 工程推荐
由于YOLOV5的推出,主要了解anchor free 的思想,工程应用主要可以尝试:
1)centerNet(object as point 的版本)
2)extremeNet(将回归边界框改为极值点)
目标检测算法——anchor free_TigerZ*的博客-CSDN博客_anchor free