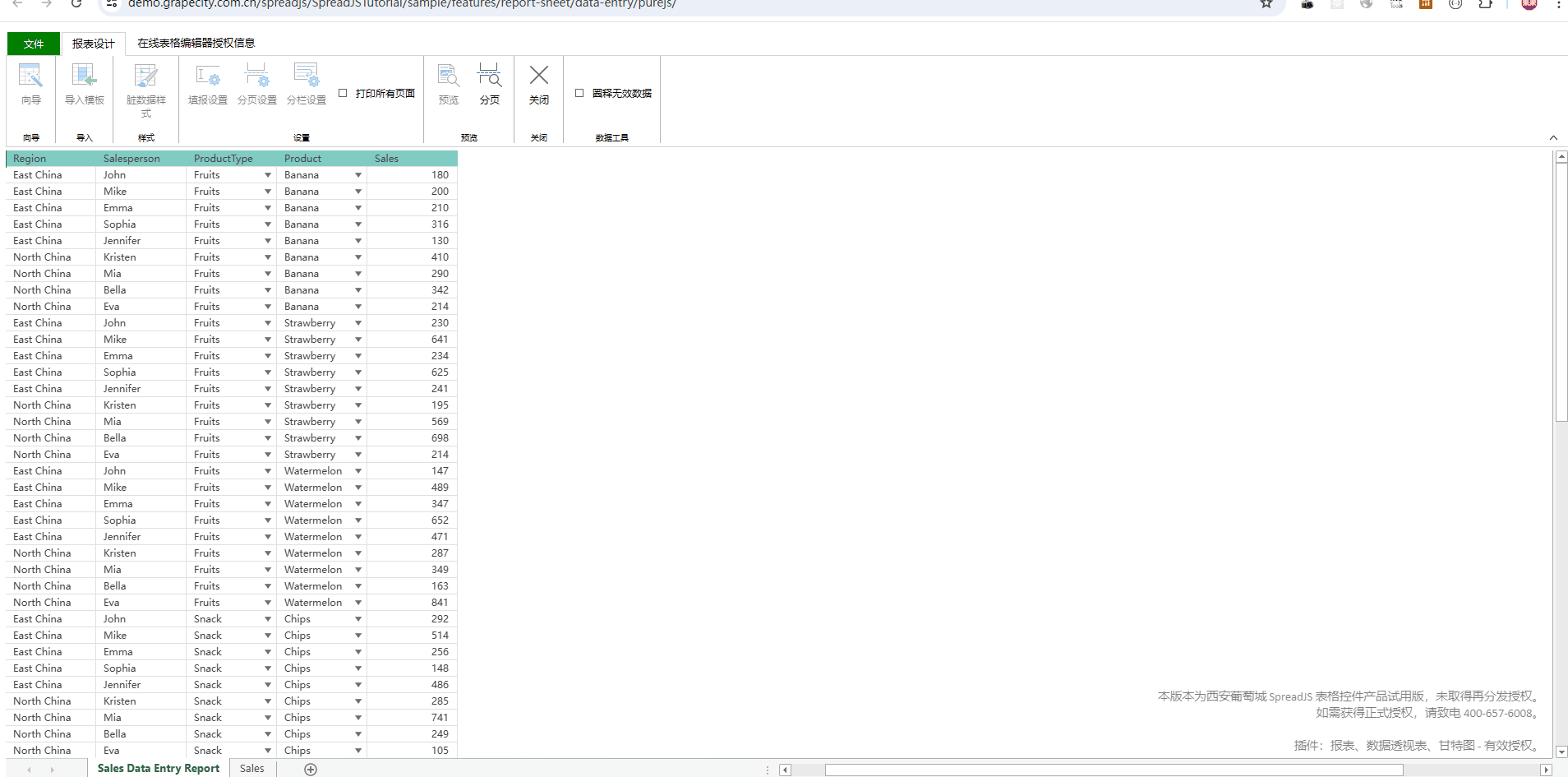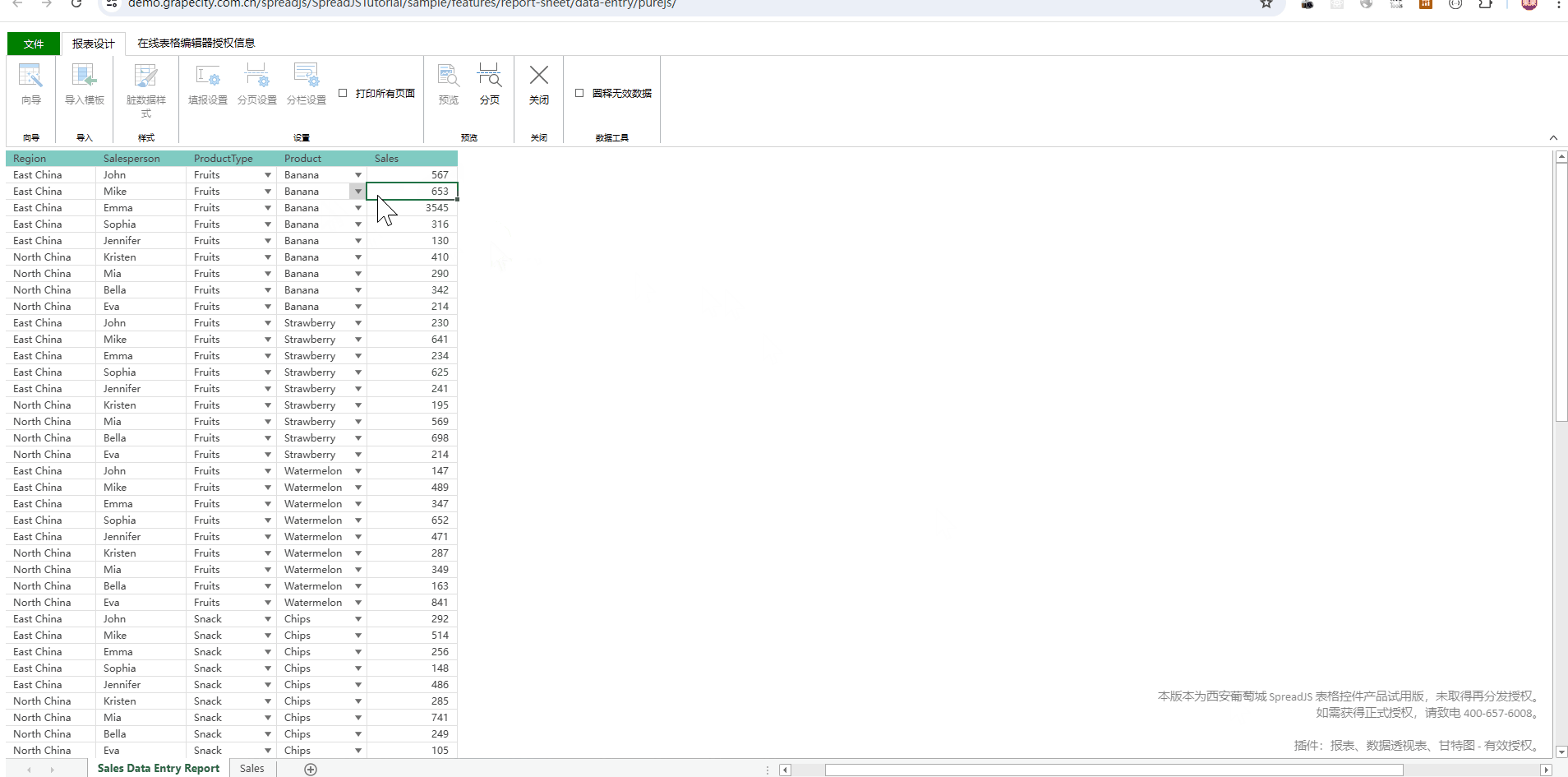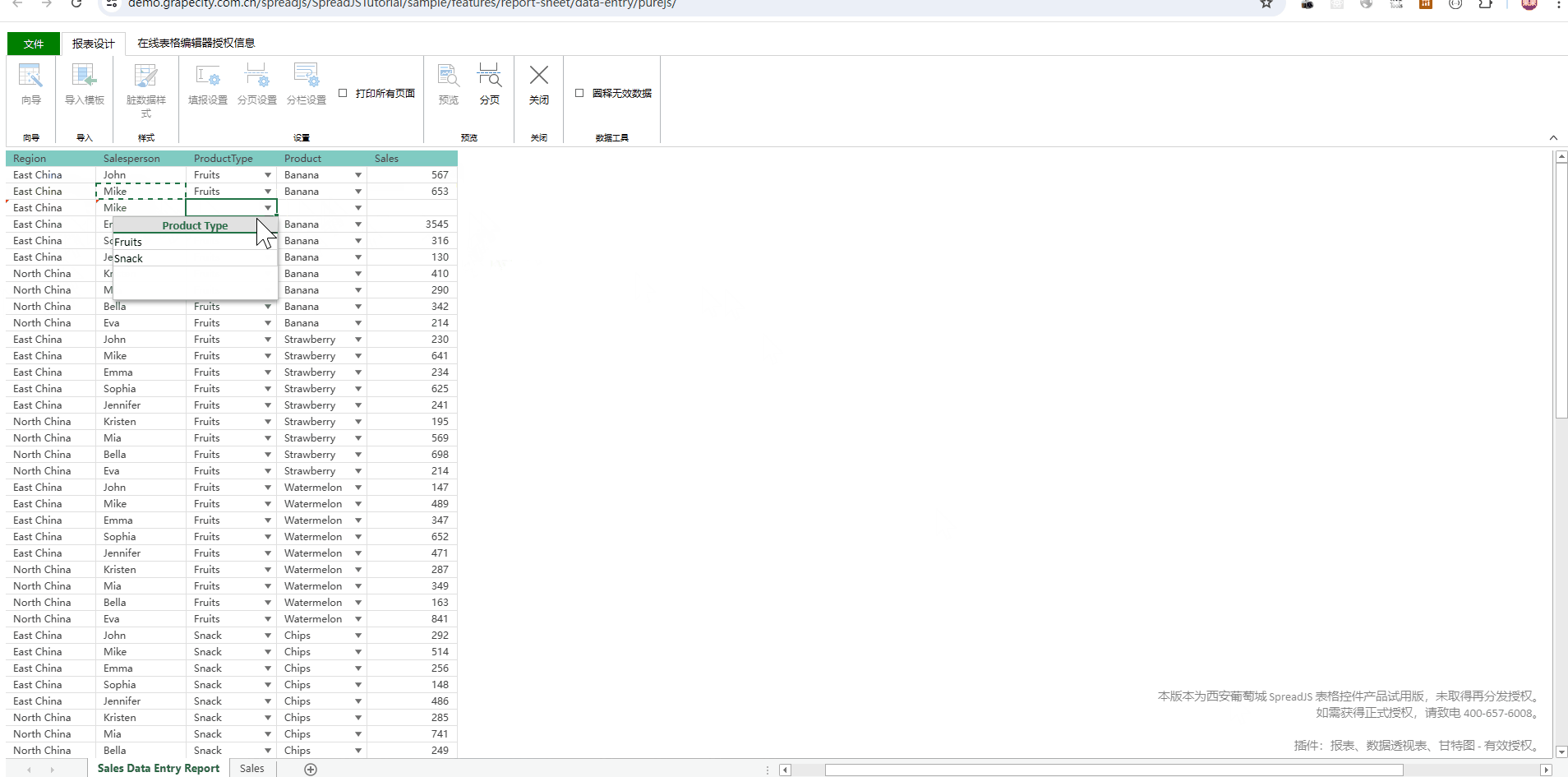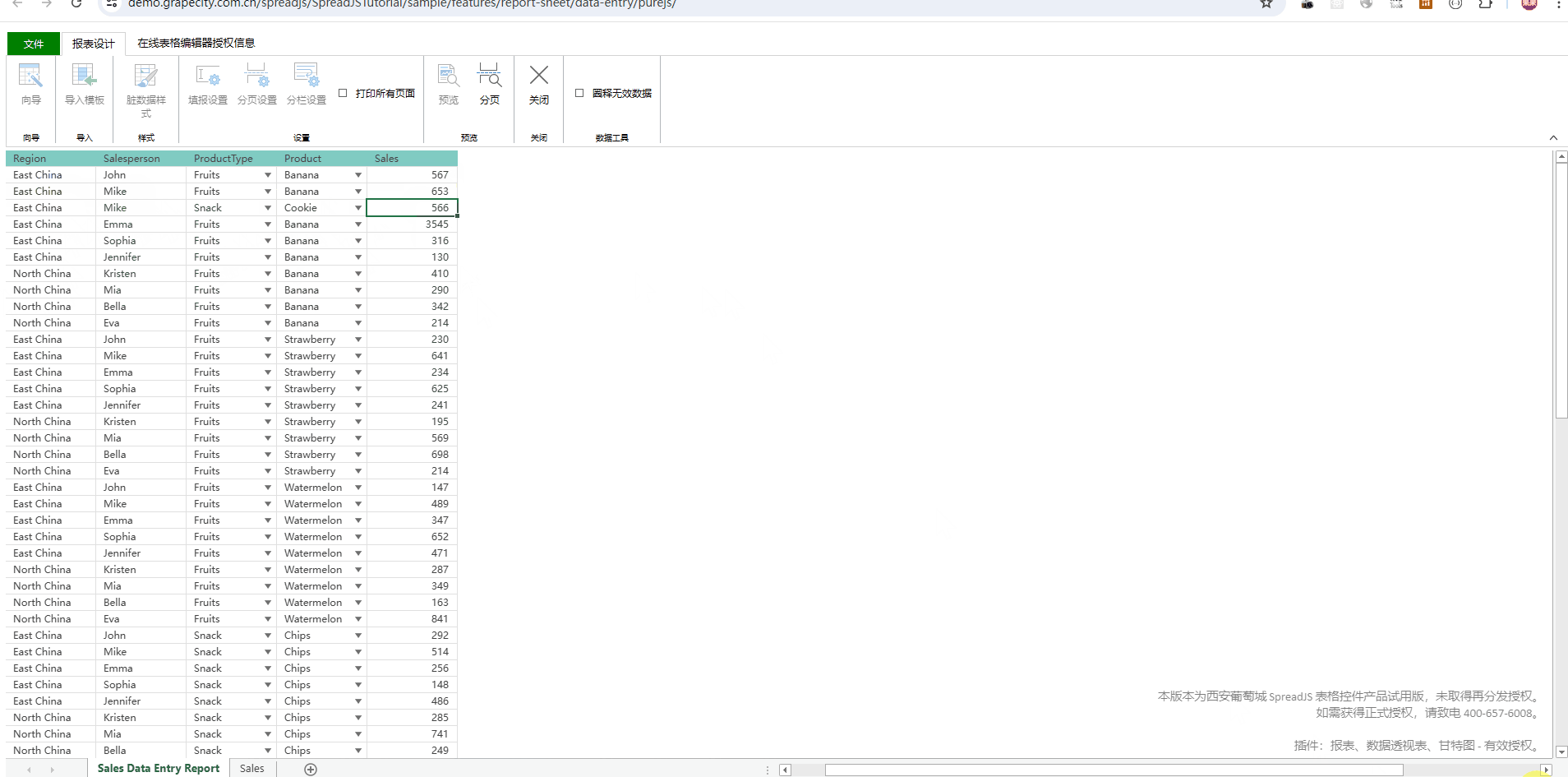
目录
1 综述
1.1 BERT的核心思想
1.2 BERT的关键技术:预训练阶段
1.3 微调阶段
2 BERT的架构
2.1 输入处理
3. 特征选择/学习模块
BERT 的自注意力过程
4. 预训练任务:同时进行
4.1 Next Sentence Prediction (NSP)
4.2 Masked Language Model (MLM)
4.3 模型的输出以及使用
4.3.1 序列级别的输出
4.3.2 词级别的输出
前面介绍了transformer模型,本篇开始介绍BERT;
BERT 模型的核心思想是通过大规模的无监督预训练来学习通用的语言表示,然后在特定任务上进行微调。相比传统的基于词的语言模型,BERT 引入了双向 Transformer 编码器,使得模型能够同时利用上下文信息,从而更好地理解词语在不同上下文中的含义。
BERT 模型的预训练阶段包含两个任务:Masked Language Model (MLM) 和 Next Sentence Prediction (NSP)。在 MLM 任务中,模型会随机遮盖输入序列的一部分单词,然后预测这些被遮盖的单词。这样的训练方式使得模型能够学习到单词之间的上下文关系。在 NSP 任务中,模型会输入两个句子,并预测这两个句子是否是连续的。这个任务有助于模型理解句子之间的关联性。
在预训练完成后,BERT 模型可以通过微调在各种下游任务上进行应用,如文本分类、命名实体识别、问答系统等。通过微调,BERT 模型能够根据具体任务的数据进行特定领域的学习,从而提高模型在特定任务上的性能。
BERT 模型的优势在于它能够捕捉词语之间的上下文信息,从而更好地理解自然语言。它在多项自然语言处理任务中取得了领先的性能,并推动了该领域的发展。
任务类型:
BERT模型的输出包括序列级别的输出和词级别的输出。序列级别的输出通常用于文本分类等任务,而词级别的输出则用于词级别的任务,如命名实体识别。这些输出是通过模型的前向传播得到的,并且可以用于各种下游任务。
- Bert最擅长信息提取任务,如文本分类、名词识别等。
- 大模型如LLaMA、ChatGLM性能更强在自然对话、问答等生成型任务。
1 综述
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer架构的预训练语言模型,BERT模型是一个双向、基于上下文的嵌入模型。由Google的研究人员在2018年提出。BERT模型的主要贡献在于它能够理解文本中词语的上下文含义,并且能够双向地处理这些上下文信息,这使得它在许多自然语言处理任务中表现出色。
BERT模型:
- BERT-large:L=24,A=16,H=1024
- BERT-base:L=12,A=12,H=768
- BERT-medium:L=8,A=8,H=512
- BERT-small:L=4,A=8,H=512
- BERT-mini:L=4,A=4,H=256
- BERT-tiny:L=2,A=2,H=128
1.1 BERT的核心思想
-
双向性:与之前大多数语言模型仅能从左到右(单向)处理句子不同,BERT能够同时考虑给定词前面和后面的上下文,这使得它能够更好地理解词语的多义性和上下文敏感性。
-
预训练:BERT首先在大量未标记文本上进行预训练,学习到通用的语言表示,然后再针对特定任务进行微调(fine-tuning),这样可以显著提高下游任务的表现。
1.2 BERT的关键技术:预训练阶段
-
Masked Language Model (MLM):在预训练过程中,BERT会随机遮盖掉输入文本中的一部分单词(大约15%),然后尝试根据剩余的上下文预测这些被遮盖的单词。这种方法能够使模型学习到单词之间的双向关系。
-
Next Sentence Prediction (NSP):除了MLM外,BERT还采用了另一个预训练目标,即预测两个句子是否连续。这对于理解文本段落的结构非常有用。
1.3 微调阶段
在预训练完成后,BERT模型可以根据具体的任务需求进行微调。对于不同的任务,如文本分类、问答系统等,只需要添加一个简单的输出层,并使用少量标注数据进行训练即可。
2 BERT的架构
transformer是基于机器翻译任务提出的,采用了主流的encoder-decoder框架。而做为后来者的BERT,其核心特征提取模块延用了transformer中的encoder,继而又把此模块应用到了一个(两个子任务)新的任务上。个人看法,BERT在算法上并没有做很多的改进,但在算法的应用上,取得了很大的成功,奠定了预训练模型在NLP领域的主导地位。
为了适用新的任务,BERT构建了自己的输入处理模块与输出处理模块。整体结构如下图:

如上图所示模块1为输入模块,其作用是对原始的文字输入进行信息提取,分别提取了字信息,位置信息与句信息(文字是属于前一句还是后一句。)。模块2为特征提取模块,结构采用了transformer中的encoder结构,之前在transfor的文章里讲过,这里不在赘述。模块3为任务处理模块,主要是对模块2的输出做了相应的转换,以支持不同的子任务。后面的两个小节会详细讲解第1和第3个模块。
2.1 输入处理
INPUT: token vector + 位置编码 + 句子特征;
- Token Embeddings:每个单词的嵌入向量。
- Segment Embeddings:用于区分句子A和句子B的嵌入向量,例如在问答任务中,问题和答案可能分别属于句子A和句子B。
- Position Embeddings:表示单词在句子中的位置。
BERT的输入与transformer的输入相比,多了一项句子特征,即当前字符是属于第一句话,还是属于第二句话。之所以增加这个特征,是因为BERT在训练时有个预测句子关系的任务。


3. 特征选择/学习模块

BERT 的自注意力过程
输入嵌入:
- 输入文本被分词并转换为词嵌入向量。
- 词嵌入向量与位置编码向量相加,以提供位置信息。
- 对于句子对任务,还需要添加段落嵌入向量以区分不同的句子。
多头自注意力:
- BERT 使用多头自注意力机制来处理输入序列。
- 在每个注意力头中,输入嵌入向量通过三个不同的线性变换得到Query (Q)、Key (K) 和 Value (V) 向量。
计算注意力分数:
- 对于每个位置 𝑖i,计算该位置与其他所有位置 𝑗j 之间的注意力分数。
- 注意力分数通过计算Query向量 𝑄𝑖 与Key向量 𝐾𝑗 的点积来得到,然后除以缩放因子
(其中 𝑑𝑘 是Key向量的维度)。
- 注意力分数通过Softmax函数进行归一化,得到最终的注意力权重。
加权求和:
- 使用注意力权重对Value向量进行加权求和,得到每个位置的新表示。
- 新的表示向量是通过加权求和得到的,即
,其中 𝛼𝑖j 是位置 𝑖关注位置 𝑗的注意力权重。
头的拼接:
- 多个注意力头的输出被拼接到一起形成一个更大的向量。
- 拼接后的向量通过一个线性变换映射回原来的维度。
前馈神经网络:
- 拼接后的向量通过一个位置前馈网络(Position-wise Feed-Forward Network)进行进一步处理。
- 前馈网络由两个线性层组成,中间夹着一个激活函数(如ReLU)。
残差连接与层归一化:
- 在每个子层前后添加残差连接。
- 在每个子层输出后进行层归一化。
4. 预训练任务:同时进行
Bert的训练有两个子任务,一个任务(NSP, Next Sentence Prediction)是预测输入中的A和B是不是上下句。另一个是预测随机mask掉的字符的任务(MLM, Masked LM)。两个子任务的输入均来自特征抽取模块,不同的是NSP任务的输入只选取了CLS对应的输出,而序列预测任务的输入则是除CLS对应位置的其它位置的数据。模型最终的损失是这两个子任务损失的加和。整体如下图。

4.1 Next Sentence Prediction (NSP)
Next Sentence Prediction是BERT原始版本中的一个任务,其目的是让模型学会理解句子之间的关系。这个任务后来在RoBERTa中被移除,因为研究发现它对最终性能的影响有限。
- 构造样本:在训练过程中,对于每一个句子A,会随机选择一个句子B作为下一个句子。50%的情况下,句子B确实是句子A在原文本中的下一个句子;另外50%的情况下,句子B是从语料库中随机抽取的一个不相关的句子。
- 训练目标:模型需要判断句子B是否是句子A的下一个句子。这是一个二分类问题,即模型需要学习一个分类器来预测句子A和句子B是否连续。
- 损失函数: MLM的损失函数通常采用交叉熵损失(Cross-Entropy Loss);
4.2 Masked Language Model (MLM)
Masked Language Model是BERT的一个核心组成部分。它的目的是让模型学习如何预测被随机遮蔽掉的单词。具体步骤如下:
- 遮蔽策略:在输入的句子中,大约15%的token会被随机遮蔽。这15%中,80%的token被替换成特殊标记
[MASK],10%保持不变,另外10%随机替换成其他token。这样的设计有助于模型学习更复杂的上下文关系。 - 训练目标:模型的任务是基于未被遮蔽的token预测被遮蔽的token。也就是说,模型要从输入的序列中预测出哪些token被遮蔽掉了,并尽可能准确地预测出它们的真实值。
- 损失函数: MLM的损失函数通常采用交叉熵损失(Cross-Entropy Loss);
4.3 模型的输出以及使用
4.3.1 序列级别的输出
序列级别的输出通常指的是第一个token([CLS]标记)的输出向量。这个向量通常用于文本分类等任务,因为它综合了整个输入序列的信息。
特点
- 维度固定:序列级别的输出向量的维度是固定的,通常与模型的隐藏层大小相同。
- 全局信息:这个向量包含了整个输入序列的信息,可用于分类等任务。
- 用于分类任务:在下游任务中,序列级别的输出通常用于文本分类任务,通过一个线性层和softmax函数转换为类别概率分布。
输出大小
- 维度:序列级别的输出向量的维度是固定的,通常与模型的隐藏层大小相同。
- 具体大小:例如,在BERT-base模型中,隐藏层大小为768,所以序列级别的输出向量的大小是768。
4.3.2 词级别的输出
词级别的输出是指每个词(token)的输出向量。这些向量可以用于词级别的任务,如命名实体识别、词性标注等。
特点
- 维度固定:每个词级别的输出向量的维度也是固定的,通常与模型的隐藏层大小相同。
- 词级信息:每个输出向量包含了该词的信息及其上下文信息。
- 用于词级别任务:词级别的输出可以用于词级别的任务,如通过一个线性层转换为每个词的标签概率分布。
输出大小
- 维度:每个词级别的输出向量的维度也是固定的,通常与模型的隐藏层大小相同。
- 具体大小:例如,在BERT-base模型中,隐藏层大小为768,所以每个词级别的输出向量的大小也是768。
- 输出形状:如果输入序列长度为N,那么词级别的输出形状是 𝑁×768N×768。
输出的使用
下游任务
- 文本分类:使用序列级别的输出,通过一个线性层和softmax函数转换为类别概率分布。
- 命名实体识别:使用词级别的输出,通过一个线性层转换为每个词的标签概率分布。
- 问答系统:使用序列级别的输出或词级别的输出来定位答案的起始和结束位置
ref:
https://blog.csdn.net/nocml/article/details/124951994
https://zhuanlan.zhihu.com/p/681208726