文章目录
一、决策边界(Decision Boundary)基本概念与用途 1. 决策边界基本概念与绘制方法 2. 通过决策边界观察模型性能 3. 逻辑回归决策边界与模型可解释性 二、逻辑回归决策边界绘制与使用方法 1. 定义决策边界绘制函数 2. 决策边界绘制 3. 逻辑回归决策边界与特征可解释性探索 三、验证逻辑回归参数和决策边界直线系数之间关系
我们需要学习一些关于分类模型的基础知识,包括观察分类模型判别性能的决策边界基本的概念与实现方法,同时也包括对于分类模型的一系列模型评估指标的基本解释与使用场景。
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib. pyplot as plt
from ML_basic_function import *
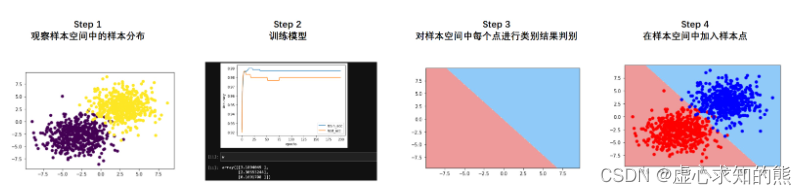
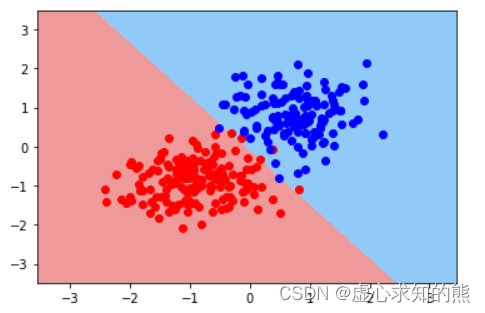
关于分类模型的模型性能判别,我们可以从模型基本理论出发来进行判别,当然也可以根据长期的实践经验来进行判断。 不过除此以外,还有一种常见的、用于辅助判别分类模型的模型性能的方法,那就是绘制模型决策边界。 决策边界本质上是一种可视化分类效果的方法,其基本思路也非常简单——利用训练好的模型对样本空间所有的坐标点进行预测,然后观察样本空间所有点的不同类别之间的边界,最终就是模型的决策边界。 例如,假设现在样本空间是二维空间,即数据总共只有两个特征,我们采用某个二分类数据集训练了一个逻辑回归模型,然后我们我们借助该模型对样本空间中所有点进行预测,并且对模型判别的不同类别的点进行不同着色,最终不同颜色(也就是不同类别)的点之间的分界线,其实就是决策边界。 一般来说,我们会在决策边界图像上添加参与模型训练的样本点。相关过程如下图所示:
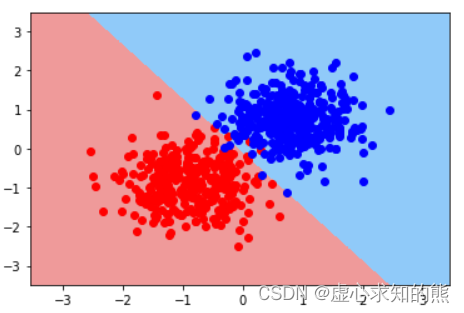
另外,如果从决策边界角度出发,决策边界实际上就是模型判别样本点属于哪一类的边界,而不同颜色区域其实就是不同类别样本点所在的区域。 根据决策边界图像,其实我们就能看出模型的分类性能和对于当前样本的分类结果。 例如对于上图来说,首先我们能够发现,实际上逻辑回归在二维样本空间中的决策边界是一条直线,而这种决策边界的呈现直线的特性,会直接影响模型对于复杂样本的分类性能。 在上述图四中能够清楚的看到,无论是红色区域的蓝色点,还是蓝色区域中红色的点,实际上都是模型错判的样本。 受此限制,逻辑回归无法处理更加复杂的判别类问题,由此我们也能看到逻辑回归本身的性能瓶颈。
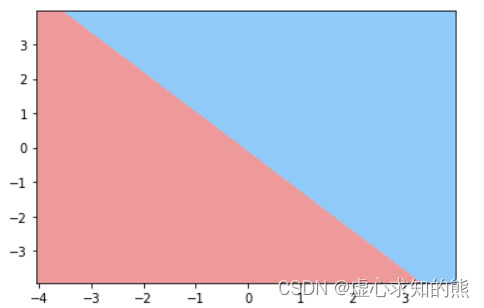
当然,并非所有模型的决策边界都呈现出线性的状态,甚至对于大多数模型来说,其决策边界都不是单独一条直线。 例如,对于 KNN 模型来说,其决策边界实际上是一个个圆圈叠加而成的拥有一定幅度的边界,而对于决策树模型来说,其决策边界实际上是一条条折线:
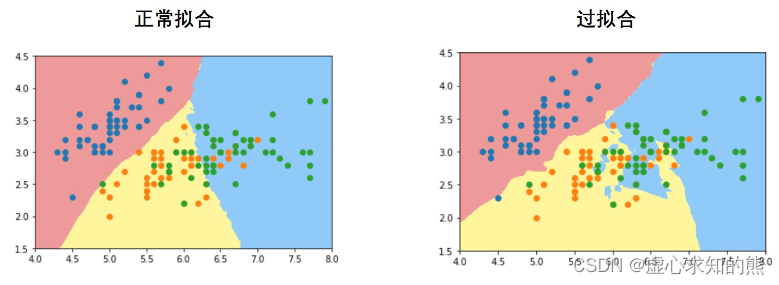
很明显,从决策边界所呈现出来的不同形状,我们也能大致看出分类模型的判别效力,类似树模型甚至是树模型的集成模型,由于其是借助折线的决策边界来进行来进行样本类别划分,因此具备比逻辑回归更强的判别效力。 此外,有时我们还能借助决策边界观察模型过拟合倾向,一般来说,模型决策边界越不规则、越是出现不同颜色区域彼此交错的情况,则说明模型越是存在过拟合倾向。
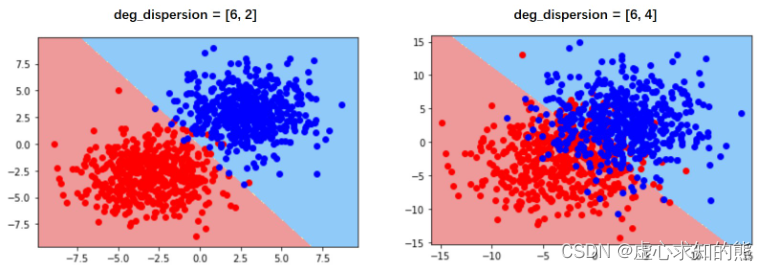
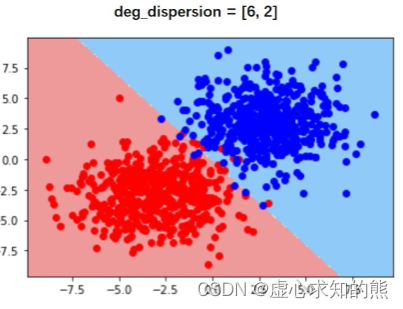
受到平面图像呈现维度的约束,一般来说我们只能观察二维或者三维样本空间的决策边界或者决策平面,对于更高维度样本空间尽管在建模时也同样存在决策边界,但无法可视化展示。 尽管逻辑回归的线性决策边界一定程度约束了模型的分类效能,但线性决策边界实际上也为逻辑回归的模型可解释性提供了一个新的解释角度。 例如,对于上述 dispersion=[6,2] 的逻辑回归决策边界来说,第一个特征(X 轴)取值越大、或者第二个特征(Y 轴)取值越大,则越有可能蓝色一类,或者说样本为蓝色类的概率就更大。
而该现象也为解释特征之于样本类别判别的作用提供了一个新的角度。只有当决策边界是线性时才能够进行如此解释。 逻辑回归线性方程系数的解释角度:假设逻辑回归方程为
y
=
S
i
g
m
o
i
d
(
x
1
−
2
x
2
)
y=Sigmoid(x_1-2x_2)
y = S i g m o i d ( x 1 − 2 x 2 )
x
1
x_1
x 1
x
2
x_2
x 2
l
n
y
1
−
y
ln\frac{y}{1-y}
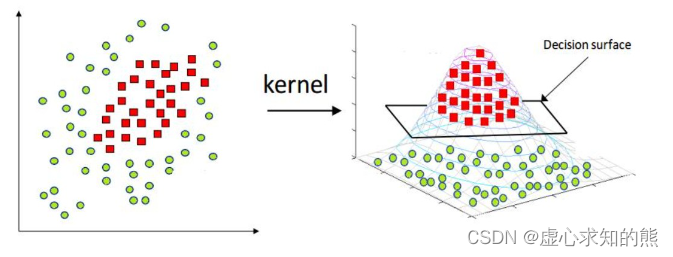
l n 1 − y y 值得一提的是,对于大多数模型来说都是试图找到一条更有效的决策边界去对样本进行类别划分,但也有些模型并不会在决策边界上下功夫,而是试图去改变样本空间。 例如支持向量机 SVM,就能够通过某种映射关系改变数据分布(包括数据维度),然后在新的数据分布中利用简单的决策平面或者超平面来对数据集进行切分。
决策边界的绘制函数其实和 Lesson 4.3 中介绍的损失函数的等高线图绘制方法类似,只是将等高线的绘制改成了分片区的着色。 首先还是利用 meshgrid 函数创建区域点图 x1, x2 = np. meshgrid( np. arange( 3 ) , np. arange( 1 , 4 ) )
[ x1, x2]
回顾 Lesson 4.3 中所介绍内容,对于 meshgrid 函数生成结果,我们可以理解为第一个返回的结果为三排点的横坐标,而第二个返回结果为每个点纵坐标。 所有的点是逐层排布的,每一排的点具有相同的纵坐标。实际绘图时,我们需要将这些点铺满整张画布。然后,我们需要带入画布中的所有点进行模型预测结果输出,即需要预测画布中的每个点所属类别。 虽然我们知道上述 meshgrid 结果实际表示的点为 (0,1)、(1,1)、(2,1)…,但只有将这些点转化为二维数组才能带入模型进行训练,我们可以借助 reshape 方法和 concatenate 函数来进行相应的形变。 同时,需要添加一列全是 1 的列在数据集的末尾,才能顺利进行逻辑回归建模预测。 np. concatenate( [ x1. reshape( - 1 , 1 ) , x2. reshape( - 1 , 1 ) , np. ones( shape= ( 9 , 1 ) ) ] , 1 )
接下来,将数据带入模型,即可输出预测结果。试想一下,当这些点密集的铺满画布时,我们就能够清楚的找出一条不同着色的边界。我们将上述过程封装为一个函数: def logit_DB ( X, w, y) :
"""
逻辑回归决策边界绘制函数
"""
x1, x2 = np. meshgrid( np. linspace( X[ : , 0 ] . min ( ) - 1 , X[ : , 0 ] . max ( ) + 1 , 1000 ) . reshape( - 1 , 1 ) ,
np. linspace( X[ : , 1 ] . min ( ) - 1 , X[ : , 1 ] . max ( ) + 1 , 1000 ) . reshape( - 1 , 1 ) )
X_temp = np. concatenate( [ x1. reshape( - 1 , 1 ) , x2. reshape( - 1 , 1 ) , np. ones( shape= ( 1000000 , 1 ) ) ] , 1 )
y_hat_temp = logit_cla( sigmoid( X_temp. dot( w) ) )
yhat = y_hat_temp. reshape( x1. shape)
from matplotlib. colors import ListedColormap
custom_cmap = ListedColormap( [ '#EF9A9A' , '#90CAF9' ] )
plt. contourf( x1, x2, yhat, cmap= custom_cmap)
关于图像绘制部分,此处采用了 plt.contourf 函数。该函数和此前介绍的等高线绘制函数 plt.contour 函数略有区别,该函数不会标注不同区域之间的边界,取而代之的是将不同区域进行着色处理。 此外,ListedColormap 函数可通过输入十六进制颜色信息创建一个 colormap 对象,该对象可以作为 plt.contourf 函数中的 cmap 参数,用于指定不同区域的着色。
np. random. seed( 24 )
f, l = arrayGenCla( num_class = 2 , deg_dispersion = [ 6 , 2 ] , bias = True )
np. random. seed( 24 )
Xtrain, Xtest, ytrain, ytest = array_split( f, l)
mean_ = Xtrain[ : , : - 1 ] . mean( axis= 0 )
std_ = Xtrain[ : , : - 1 ] . std( axis= 0 )
Xtrain[ : , : - 1 ] = ( Xtrain[ : , : - 1 ] - mean_) / std_
Xtest[ : , : - 1 ] = ( Xtest[ : , : - 1 ] - mean_) / std_
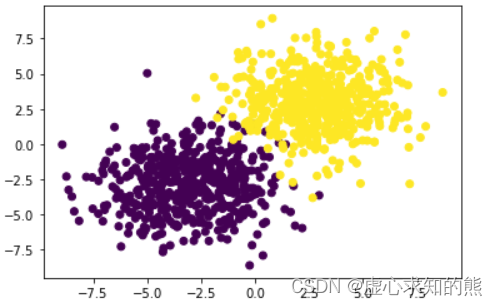
plt. scatter( f[ : , 0 ] , f[ : , 1 ] , c= l)
np. random. seed( 24 )
batch_size = 50
num_epoch = 200
lr_init = 0.2
n = f. shape[ 1 ]
w = np. random. randn( n, 1 )
train_acc = [ ]
test_acc = [ ]
lr_lambda = lambda epoch: 0.95 ** epoch
for i in range ( num_epoch) :
w = sgd_cal( Xtrain, w, ytrain, logit_gd, batch_size= batch_size, epoch= 1 , lr= lr_init* lr_lambda( i) )
train_acc. append( logit_acc( Xtrain, w, ytrain, thr= 0.5 ) )
test_acc. append( logit_acc( Xtest, w, ytest, thr= 0.5 ) )
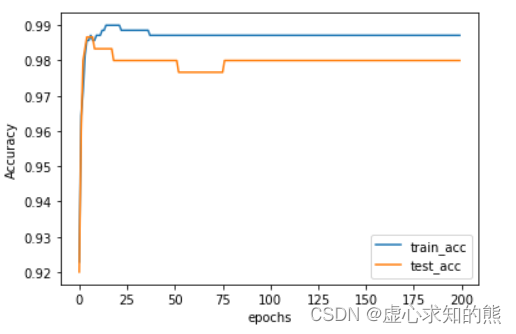
plt. plot( list ( range ( num_epoch) ) , np. array( train_acc) . flatten( ) , label= 'train_acc' )
plt. plot( list ( range ( num_epoch) ) , np. array( test_acc) . flatten( ) , label= 'test_acc' )
plt. xlabel( 'epochs' )
plt. ylabel( 'Accuracy' )
plt. legend( loc = 4 )
绘制决策边界 接下来,利用上述模型训练结果,来进行决策边界的图像绘制。 w
logit_DB( Xtrain, w, ytrain)
当然,更为一般的情况是,我们会同时将样本点也绘制在包含决策边界的图像上
logit_DB( Xtrain, w, ytrain)
plt. scatter( Xtrain[ ( ytrain == 0 ) . flatten( ) , 0 ] , Xtrain[ ( ytrain == 0 ) . flatten( ) , 1 ] , color= 'red' )
plt. scatter( Xtrain[ ( ytrain == 1 ) . flatten( ) , 0 ] , Xtrain[ ( ytrain == 1 ) . flatten( ) , 1 ] , color= 'blue' )
由于此处采用了一种布尔索引的方式分别筛选出两类点并对其进行不同的着色处理。 ( ytrain == 0 ) [ : 10 ]
( ytrain == 0 ) . sum ( )
Xtrain[ ( ytrain == 0 ) . flatten( ) , : ] [ : 10 ]
Xtrain[ ( ytrain == 0 ) . flatten( ) , : ] . shape
logit_DB( Xtrain, w, ytrain)
plt. scatter( Xtest[ ( ytest == 0 ) . flatten( ) , 0 ] , Xtest[ ( ytest == 0 ) . flatten( ) , 1 ] , color= 'red' )
plt. scatter( Xtest[ ( ytest == 1 ) . flatten( ) , 0 ] , Xtest[ ( ytest == 1 ) . flatten( ) , 1 ] , color= 'blue' )
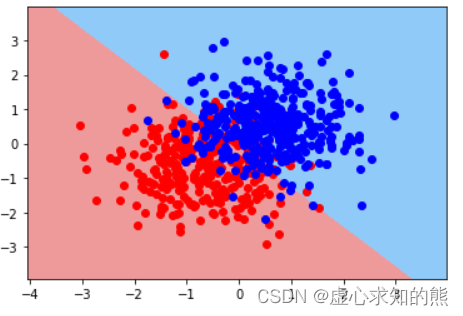
当然,我们也可以提升数据难度再观察逻辑回归的决策边界。
np. random. seed( 24 )
f, l = arrayGenCla( num_class = 2 , deg_dispersion = [ 6 , 4 ] , bias = True )
np. random. seed( 24 )
Xtrain, Xtest, ytrain, ytest = array_split( f, l)
mean_ = Xtrain[ : , : - 1 ] . mean( axis= 0 )
std_ = Xtrain[ : , : - 1 ] . std( axis= 0 )
Xtrain[ : , : - 1 ] = ( Xtrain[ : , : - 1 ] - mean_) / std_
Xtest[ : , : - 1 ] = ( Xtest[ : , : - 1 ] - mean_) / std_
np. random. seed( 24 )
batch_size = 50
num_epoch = 200
lr_init = 0.2
n = f. shape[ 1 ]
w = np. random. randn( n, 1 )
lr_lambda = lambda epoch: 0.95 ** epoch
for i in range ( num_epoch) :
w = sgd_cal( Xtrain, w, ytrain, logit_gd, batch_size= batch_size, epoch= 1 , lr= lr_init* lr_lambda( i) )
w
logit_DB( Xtrain, w, ytrain)
logit_DB( Xtrain, w, ytrain)
plt. scatter( Xtrain[ ( ytrain == 0 ) . flatten( ) , 0 ] , Xtrain[ ( ytrain == 0 ) . flatten( ) , 1 ] , color= 'red' )
plt. scatter( Xtrain[ ( ytrain == 1 ) . flatten( ) , 0 ] , Xtrain[ ( ytrain == 1 ) . flatten( ) , 1 ] , color= 'blue' )
logit_DB( Xtrain, w, ytrain)
plt. scatter( Xtest[ ( ytest == 0 ) . flatten( ) , 0 ] , Xtest[ ( ytest == 0 ) . flatten( ) , 1 ] , color= 'red' )
plt. scatter( Xtest[ ( ytest == 1 ) . flatten( ) , 0 ] , Xtest[ ( ytest == 1 ) . flatten( ) , 1 ] , color= 'blue' )
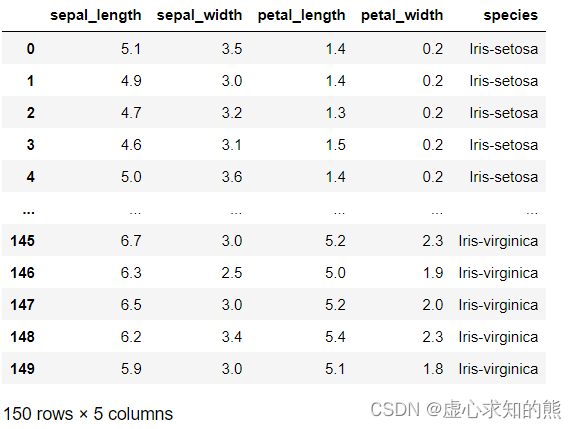
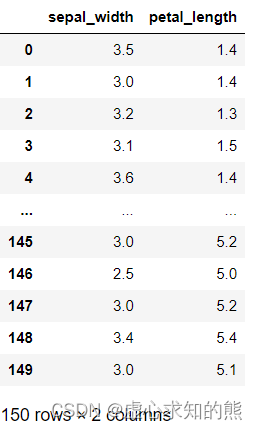
接下来,我们以鸢尾花数据集为例,来探讨为何逻辑回归的方程系数和决策边界其实都无法判别特征强弱。 此处我们选取花萼宽 sepal_width 和花瓣长 petal_length 作为特征,进行是否是 setosa 鸢尾花的判别,即令 setosa 鸢尾花为类别 1,其他鸢尾花为类别 0。 首先进行数据的读取。 pd. read_csv( 'iris.csv' )
pd. read_csv( 'iris.csv' ) . iloc[ : , 1 : 3 ]
features_temp = pd. read_csv( 'iris.csv' ) . iloc[ : , 1 : 3 ] . values
features_temp[ : 10 ]
labels_temp = pd. read_csv( 'iris.csv' ) . iloc[ : , - 1 ] . values
labels_temp
labels_temp[ labels_temp != 'Iris-setosa' ] = 0
labels_temp[ labels_temp == 'Iris-setosa' ] = 1
labels_temp
labels = labels_temp. astype( float ) . reshape( - 1 , 1 )
labels
features = np. concatenate( [ features_temp, np. ones( shape= labels. shape) ] , 1 )
features[ : 10 ]
labels[ : 10 ]
np. random. seed( 24 )
batch_size = 10
num_epoch = 200
lr_init = 0.5
n = features. shape[ 1 ]
w = np. random. randn( n, 1 )
lr_lambda = lambda epoch: 0.95 ** epoch
for i in range ( num_epoch) :
w = sgd_cal( features, w, labels, logit_gd, batch_size= batch_size, epoch= 1 , lr= lr_init* lr_lambda( i) )
w
logit_acc( features, w, labels, thr= 0.5 )
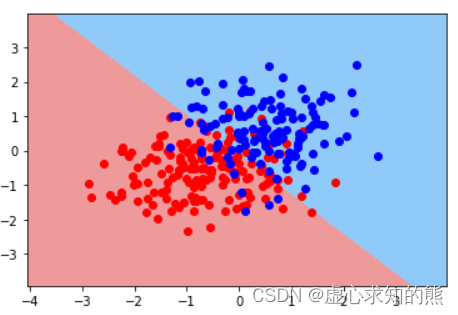
logit_DB( features, w, labels)
plt. scatter( features[ ( labels == 0 ) . flatten( ) , 0 ] , features[ ( labels == 0 ) . flatten( ) , 1 ] , color= 'red' )
plt. scatter( features[ ( labels == 1 ) . flatten( ) , 0 ] , features[ ( labels == 1 ) . flatten( ) , 1 ] , color= 'blue' )
plt. xlabel( 'sepal_width' )
plt. ylabel( 'petal_length' )
plt. title( 'Iris-setosa or not' )
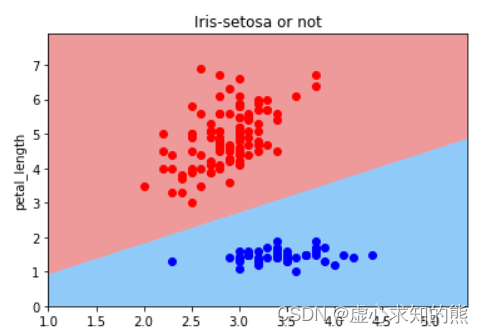
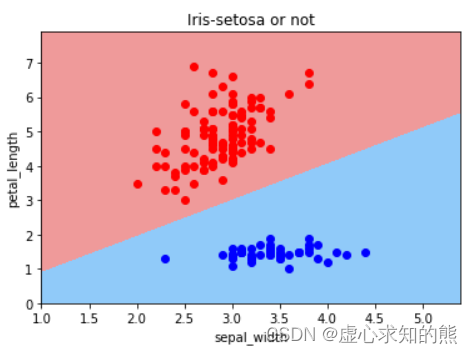
根据决策边界的判别结果,我们能够得出,鸢尾花花萼越宽(sepal_width)取值越大,则越有可能是setosa鸢尾花,而鸢尾花花瓣越长(petal_length),则越有可能不是 setosa 鸢尾花。 从逻辑回归方程系数来看,第一个特征系数取值为正值,也说明第一个特征对样本概率判别为 1 有正向促进作用,第二个特征系数取值为负值,也说明第二个特征对样本概率判别为 1 有负向促进作用。 我们无法根据决策边界斜率基本是 1,逻辑回归的线性方程中两个特征系数绝对值类似,就判断两个特征对类别判别的贡献度类似、两个特征强弱类似。 其实从样本空间中的样本分布我们不难看出,对于 setosa 类鸢尾花的识别来说,其实只需要 petal_length 一个特征即可,也就是说如果需要判别特征重要性的话,petal_length 的特征重要性远比 sepal_width 更加重要。 当然,针对上述实验,我们可以通过简单调整参数的初始取值,就能够获得一个分类准确率仍然是 100%,但第二个特征的系数绝对值小于第一个特征的实验结果:
batch_size = 10
num_epoch = 200
lr_init = 0.5
w = np. array( [ [ 10.0 ] , [ - 1 ] , [ 0 ] ] )
lr_lambda = lambda epoch: 0.95 ** epoch
np. random. seed( 24 )
for i in range ( num_epoch) :
w = sgd_cal( features, w, labels, logit_gd, batch_size= batch_size, epoch= 1 , lr= lr_init* lr_lambda( i) )
w
logit_acc( features, w, labels, thr= 0.5 )
logit_DB( features, w, labels)
plt. scatter( features[ ( labels == 0 ) . flatten( ) , 0 ] , features[ ( labels == 0 ) . flatten( ) , 1 ] , color= 'red' )
plt. scatter( features[ ( labels == 1 ) . flatten( ) , 0 ] , features[ ( labels == 1 ) . flatten( ) , 1 ] , color= 'blue' )
plt. xlabel( 'sepal_width' )
plt. ylabel( 'petal_length' )
plt. title( 'Iris-setosa or not' )
从单一特征就能识别 setosa 类,其实也是鸢尾花数据集本身分类难度不大的重要原因。 其实对于逻辑回归来说,我们也可以直接通过得到的逻辑回归线性方程来换算决策边界的直线系数,首先回到第一个例子当中,次数我们计算的 w 结果如下:
np. random. seed( 24 )
f, l = arrayGenCla( num_class = 2 , deg_dispersion = [ 6 , 2 ] , bias = True )
np. random. seed( 24 )
Xtrain, Xtest, ytrain, ytest = array_split( f, l)
mean_ = Xtrain[ : , : - 1 ] . mean( axis= 0 )
std_ = Xtrain[ : , : - 1 ] . std( axis= 0 )
Xtrain[ : , : - 1 ] = ( Xtrain[ : , : - 1 ] - mean_) / std_
Xtest[ : , : - 1 ] = ( Xtest[ : , : - 1 ] - mean_) / std_
np. random. seed( 24 )
batch_size = 50
num_epoch = 200
lr_init = 0.2
n = f. shape[ 1 ]
w = np. random. randn( n, 1 )
train_acc = [ ]
test_acc = [ ]
lr_lambda = lambda epoch: 0.95 ** epoch
for i in range ( num_epoch) :
w = sgd_cal( Xtrain, w, ytrain, logit_gd, batch_size= batch_size, epoch= 1 , lr= lr_init* lr_lambda( i) )
train_acc. append( logit_acc( Xtrain, w, ytrain, thr= 0.5 ) )
test_acc. append( logit_acc( Xtest, w, ytest, thr= 0.5 ) )
w
logit_DB( Xtrain, w, ytrain)
此时逻辑回归方程为:
y
=
s
i
g
m
o
i
d
(
w
1
x
1
+
w
2
x
2
+
b
)
y = sigmoid(w_1x_1+w_2x_2+b)
y = s i g m o i d ( w 1 x 1 + w 2 x 2 + b ) w 中三个参数分别对应
w
1
,
w
2
,
b
w_1,w_2,b
w 1 , w 2 , b 此时决策边界的直线方程即为:
y
=
−
b
w
2
−
w
1
w
2
⋅
x
y=-\frac{b}{w_2}-\frac{w_1}{w_2}\cdot x
y = − w 2 b − w 2 w 1 ⋅ x 我们可以通过如下方式来进行验证: Xtrain[ : , 0 ] . max ( ) + 1
Xtrain[ : , 0 ] . min ( ) - 1
Xtrain[ : , 1 ] . max ( ) + 1
Xtrain[ : , 1 ] . min ( ) - 1
f1 = np. concatenate( [ np. linspace( 2 , 3 , 100 ) . reshape( - 1 , 1 ) ,
np. full_like( np. linspace( 2 , 3 , 100 ) . reshape( - 1 , 1 ) , Xtrain[ : , 1 ] . min ( ) - 1 ) ,
np. ones( 100 ) . reshape( - 1 , 1 ) ] , 1 )
logit_cla( sigmoid( f1. dot( w) ) ) . sum ( )
logit_cla( sigmoid( f1. dot( w) ) ) [ 46 ]
x1 = f1[ 46 ]
f2 = np. concatenate( [ np. linspace( - 3 , - 2 , 100 ) . reshape( - 1 , 1 ) ,
np. full_like( np. linspace( - 3 , - 2 , 100 ) . reshape( - 1 , 1 ) , Xtrain[ : , 1 ] . max ( ) + 1 ) ,
np. ones( 100 ) . reshape( - 1 , 1 ) ] , 1 )
logit_cla( sigmoid( f2. dot( w) ) ) . sum ( )
logit_cla( sigmoid( f2. dot( w) ) ) [ 43 ]
x2 = f2[ 43 ]
f3 = np. array( [ x1, x2] )
f3
f3[ : , [ 0 , 2 ] ]
f3[ : , 1 : 2 ]
np. linalg. lstsq( f3[ : , [ 0 , 2 ] ] , f3[ : , 1 : 2 ] , rcond= - 1 ) [ 0 ]
等价于
y
=
−
b
w
2
−
w
1
w
2
⋅
x
y=-\frac{b}{w_2}-\frac{w_1}{w_2}\cdot x
y = − w 2 b − w 2 w 1 ⋅ x w
- w[ 0 ] / w[ 1 ]
- w[ 2 ] / w[ 1 ]