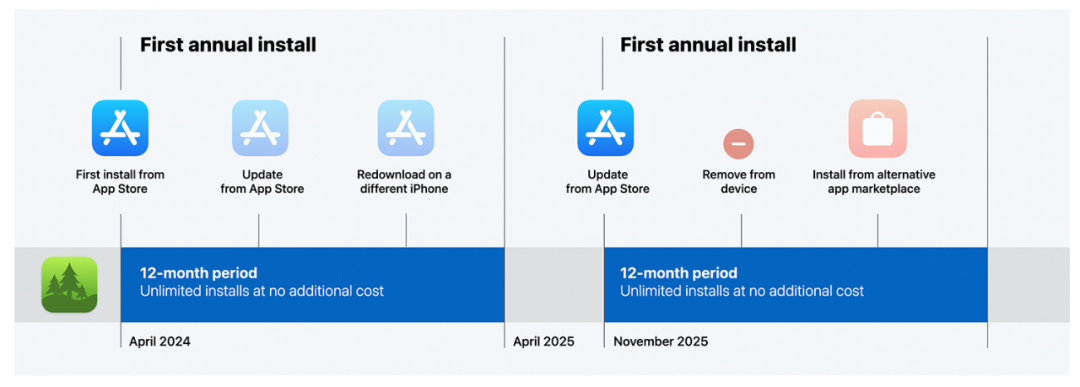
MoE技术揭秘——混合专家模型的计算
MoE技术的类比
- 你可以把MoE技术比作一个“智能团队”,团队中的每个成员(专家)都有自己擅长的领域。
- 当面对一个问题时,只有擅长此问题的成员才会参与解答,这样既提高了效率,又保证了专业性。

MoE技术的核心作用
| 组件/步骤 | 描述 |
|---|---|
| 专家(Experts) | 模型的不同部分,专注于处理不同的任务或数据的不同方面。 |
| 门控机制(Gating Mechanism) | 根据输入数据,决定哪些专家应该参与处理,以此控制计算成本。 |
| 混合输出(Mixture Output) | 专家的输出会被混合在一起,形成最终的模型输出。 |
其基本关联可通过以下公式体现:
y
=
∑
i
=
1
n
g
i
(
x
)
⋅
e
i
(
x
)
y = \sum_{i=1}^{n} g_i(x) \cdot e_i(x)
y=i=1∑ngi(x)⋅ei(x)
其中,
y
是模型输出,
g
i
(
x
)
是门控机制,决定第
i
个专家的权重,
e
i
(
x
)
是第
i
个专家的输出。
\text{其中,} y \text{ 是模型输出,} g_i(x) \text{ 是门控机制,决定第 } i \text{ 个专家的权重,} e_i(x) \text{ 是第 } i \text{ 个专家的输出。}
其中,y 是模型输出,gi(x) 是门控机制,决定第 i 个专家的权重,ei(x) 是第 i 个专家的输出。
| 项目 | 描述 |
|---|---|
| 模型输出 | y y y,表示模型对于输入 x x x的最终预测或响应。 |
| 门控机制 | g i ( x ) g_i(x) gi(x),决定每个专家对于当前输入的贡献度或权重。 |
| 专家输出 | e i ( x ) e_i(x) ei(x),表示第 i i i个专家对于输入 x x x的处理结果。 |

通俗解释与案例
-
MoE技术的核心思想
- 想象一下,你是一家大型医院的院长,面对各种复杂的病例,你会让擅长不同领域的医生(专家)组成团队。
- 当一个病例来临时,只有擅长此病例的医生(专家)才会参与诊断和治疗,这样既提高了效率,又保证了专业性。
-
MoE技术的应用
- 在大型语言模型中,MoE技术允许模型的不同部分(专家)专注于处理不同的语言任务或数据方面。
- 对于一个输入句子,只有与之相关的专家才会被激活,参与处理,这样既控制了计算成本,又提高了模型的专业性。
-
MoE技术的优势
- 结合多个专家,MoE技术能够处理更复杂、更多样化的任务和数据。
- 通过门控机制,MoE技术能够在不大幅提升计算需求的前提下,提高模型的整体性能。
-
MoE技术的类比
- 你可以把MoE技术比作一个“智能团队”,团队中的每个成员(专家)都有自己擅长的领域。
- 当面对一个问题时,只有擅长此问题的成员才会参与解答,这样既提高了效率,又保证了专业性。
具体来说:
| 项目 | 描述 |
|---|---|
| 模型输出 | y y y,就像是医院的诊断报告,综合了各专家的意见。 |
| 门控机制 | g i ( x ) g_i(x) gi(x),就像是医院的挂号系统,决定哪个医生(专家)应该接诊。 |
| 专家输出 | e i ( x ) e_i(x) ei(x),就像是医生(专家)的诊断建议,针对自己的擅长领域给出。 |
公式探索与推演运算
-
基本公式:
- y = ∑ i = 1 n g i ( x ) ⋅ e i ( x ) y = \sum_{i=1}^{n} g_i(x) \cdot e_i(x) y=∑i=1ngi(x)⋅ei(x):表示模型的最终输出是各个专家输出的加权和。
-
具体计算:
- 假设有3个专家,分别擅长处理情感分析、实体识别和语法检查。
- 对于一个输入句子“我爱北京天安门”,门控机制可能决定情感分析专家和实体识别专家应该参与处理。
- 这两个专家的输出会被加权求和,形成最终的模型输出,例如:“这是一个表达爱国情感的句子,提到了‘北京天安门’这个实体”。
-
与大型语言模型的关系:
- 在大型语言模型中,由于数据和任务的复杂性,使用MoE技术可以更有效地利用模型资源,提高处理效率和专业性。
关键词提炼
#MoE技术
#混合专家模型
#门控机制
#专家输出
#模型效率
#专业性