《汇编语言 基于x86处理器》- 读书笔记 - 第3章-汇编语言基础
- 3.1 基本语言元素
- 3.1.1 第一个汇编语言程序
- 常见汇编语言调用规范
- 3.1.2 整数常量(基数、字面量)
- 3.1.3 整型常量表达式
- 3.1.4 实数常量
- 十进制实数
- 十六进制实数(编码实数)
- 3.1.5 字符常量
- 3.1.6 字符串常量
- 3.1.7 保留字
- 3.1.8 标识符
- 3.1.9 伪指令
- 3.1.10 指令 instruction
- 1. 标号(Label)
- 2. 指令助记符(instruction mnemonic)
- 3. 操作数
- 4. 注释
- 5. NOP(空操作)指令
- 3.1.11 本节回顾
- 3.2 示例: 整数加减法
- 3.3 汇编、链接和运行程序
- 3.3.1 汇编-链接-执行周期
- 3.3.2 列表文件
- 让 Visual Studio 生成列表文件
- 3.3.3 本节回顾
- 3.4 定义数据
- 3.4.1 内部数据类型
- 表3-2 内部数据类型
- 表3-3 传统数据伪指令
- 3.4.2 数据定义语句
- 补充介绍:变量信息
- 声明变量(以字节类型举例)
- 1.多初始值
- 2. 定义字符串
- 3. DUP 运算符
- 3.4.4 定义8位: BYTE(字节) 和 SBYTE(有符号字节) 数据、DB 伪指令
- 3.4.5 定义16位: WORD(字) 和 SWORD(有符号字)数据。DW伪指令
- 3.4.6 定义32位: DWORD(双字) 和 SDWORD(有符号双字)数据。DD伪指令
- 3.4.7 定义64位: QWORD(四字) 数据。DQ伪指令
- 3.4.8 定义压缩 BCD(TBYTE)数据
- 3.4.9 定义浮点类型
- 3.4.10 变量加法程序
- 3.4.11 小端顺序
- 3.4.12 声明未初始化数据
- .DATA? 伪指令
- 代码与数据混合
- 3.4.13 本节回顾
- 3.5 符号常量 symbolic constant
- 3.5.1 = 伪指令 (equal-sign directive)
- 3.5.2 当前地址计数器 $ 计算数组和字符串的大小
- 3.5.3 EQU 伪指令
- 3.5.4 TEXTEQU 伪指令
- 3.5.5 本节回顾
- 3.6 64位编程
- 3.7 本章小结
- 3.8 关键术语
- 参考资料
本章主要介绍 Microsoft MASM 汇编程序的基础知识。特别推荐使用 Visual Studio 调试器。
3.1 基本语言元素
3.1.1 第一个汇编语言程序
- AddTwoSum.asm - 两个32位整数相加,结果存入第三个变量
.386 ; .386伪指令,声明32位程序,能访问32位寄存器和地址。
.model flat,stdcall ; 伪指令 .MODEL 指定存内存模式为 flat 子程序调用规范 stdcall
.stack 4096 ; 声明栈空间4096字节
ExitProcess proto,dwExitCode:dword ; 声明 ExitProcess 函数原型
; proto 伪指令,用于描述一个外部过程(函数)的原型
; dwExitCode 是函数的参数,代表进程退出时的状态码。
; dw前缀是MS WinAPI 常用的命名约定(32位无符号整数)
; :dword 则表示 dwExitCode 参数为一个32位的无符号整数
.data ; 伪指令 .data 定义数据段
sum DWORD 0 ; 定义名为 sum 的变量,关键字 DWORD 表示双字占32位
.code ; 伪指令 .code 定义代码段
main proc ; 程序入口。伪指令 PROC 用于定义一个子程序
mov eax,5 ; 将整数常量 5 送入eax 寄存器
add eax,6 ; eax += 6
mov sum,eax ; sum = eax
invoke ExitProcess,0 ; 调用 ExitProcess 结束子程序,返回 0 给操作系统
main endp ; ENDP 与 PROC 成对出现,表示子程序结束
end main ; 程序入口地址指向 main


常见汇编语言调用规范
以下是几种常见的汇编语言调用规范 :
1. stdcall(标准调用):
- 参数传递:参数从右向左依次压入堆栈。
- 堆栈清理:函数自身负责清理堆栈(在返回前会根据参数的字节数修正堆栈指针)。
- 函数名修饰:函数名自动加前导的下划线,后面紧跟一个@符号,再紧跟参数的字节数。例如函数
int myfunc(int a, int b)编译后函数名可能是_myfunc@8。 - 常用于Windows API中一些由C语言编写的函数。
2. cdecl(C 语言调用):
- 参数传递:参数也是从右向左压入堆栈。
- 堆栈清理:调用者负责清理堆栈。
- 函数名修饰:在微软的编译器中,函数名前自动加前导下划线(不同编译器可能有略微差异)。
- 特点:允许函数的参数个数不固定(因为调用者清理堆栈,所以可以根据实际情况来压栈和清理),例如C语言中的
printf等函数采用这种约定 。
3. fastcall(快速调用):
- 参数传递:前两个双字(DWORD ,4字节 )参数(或尺寸更小的)分别通过寄存器ECX和EDX传递,后续参数从右向左压栈。
- 堆栈清理:被调用函数清理堆栈。
- 函数名修饰:类似stdcall 。
4. thiscall(C++类成员函数调用) :
- 参数传递:参数从右向左入栈。
- 对于this指针:如果参数个数确定,this指针通过ECX传递给被调用者;如果参数个数不确定,this指针在所有参数压栈后被压入堆栈。
- 堆栈清理:如果参数个数确定,函数自身清理堆栈;如果参数个数不确定,调用者清理堆栈。
- 它是C++类成员函数默认的调用规范,并且通常只能由C++编译器处理,不是一个明确可在汇编中用关键字声明的规范 。
5. nakedcall(裸调用,在一些编译器环境下存在):
- 当使用这个调用规范声明函数时,编译器几乎不产生任何额外的代码来进行常规的函数调用前和调用后的处理(如保存寄存器、建立堆栈框架等常规操作)。
- 程序员可以完全手动控制函数执行的所有细节包括参数传递、寄存器使用、堆栈管理等。但这也极大增加了编程难度和出错风险。
在不同的操作系统(如Windows、Linux等)和不同的编程场景下(如不同编程语言混合编程等),调用规范的重要性更加凸显,需要根据具体情况来正确处理函数调用和参数传递等相关事宜。
3.1.2 整数常量(基数、字面量)
本书使用 Microsoft 语法符号。
[方括号] 内的元素是可选的;
{大括号} 内的元素用|符号分隔,表示必选其一;
斜体字 标识的是有明确定义或说明的元素。
整数常量构成:[ {+|-} ] 数字[ 基数]
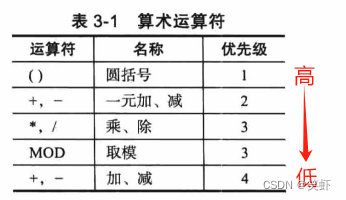
可能的基数值:
| - | 基数值 | 示例 | 备注 |
|---|---|---|---|
| 十进制 (DEC) | 无 | t | d | 25 | 25T | 25D | 十进制一般直接写数字不加后缀 |
| 二进制 (BIN) | b | y | 00011001B | 00011001Y | 一般用 B |
| 八进制 (OCT) | o | q | 31O | 31Q | 代码中很少会用到8进制常量,一定要的话Q好认点 |
| 十六进制 (HEX) | h | 19H | 0A3H | 以字母开头的十六进制数必须加上前置0。 |
| 编码实数 | r |
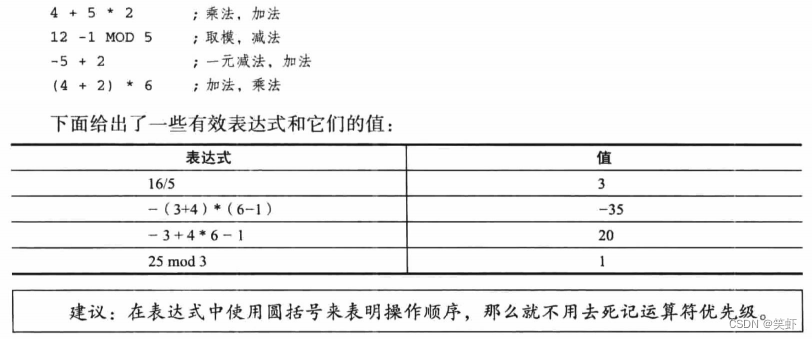
3.1.3 整型常量表达式
整型常量表达式是一种算术表达式,它包含了整数常量,符号常量和算术运算符。- 每个表达式的计算
结果必须是一个整数,并可用32位(从0到FFFFFFFFh)来存放。 - 它们在
编译阶段计算出结果。
- 关于优先级示例:
3.1.4 实数常量
十进制实数
[符号]整数.[整数][指数]
- 符号:
{ +, -} - 指数:
E[{+,-}]整数 - 数字和小数点是必须的
- 举例:

十六进制实数(编码实数)
编码实数用IEEE浮点数格式表示短实数(参见第12章)。
- 举例:
| 进制 | 数值 |
|---|---|
| 十进制 | +1.0 |
| 二进制 | 0011 1111 1000 0000 0000 0000 0000 0000 |
| 十六进制 | 3F800000r |
3.1.5 字符常量
字符常量是单引号或双引号括起来的单个字符,内存中保存的是对应 ASCII 码的二进制值。
- 举例:
| 字符 | ASCII(十进制) | 内存中存的二进制值 |
|---|---|---|
'A' | 65 | 0100 0001 |
'd' | 100 | 0110 0100 |
'A'.charCodeAt(0); // 65
A'.charCodeAt(0).toString(2); // 100 0001
'd'.charCodeAt(0); // 100
'd'.charCodeAt(0).toString(2); // 110 0100
3.1.6 字符串常量
-
字符串常量就是
一串字符常量。 -
在内存中表示为连续存放的 ASCII 码的二进制值。
(一般将2进制转为16进制显示便于人类阅读) -
单引号与双引号可以互相嵌套。
- 举例:
| 字符 | ASCII (十进制) | 十六进制值 |
|---|---|---|
'ABC' | 65, 66, 67 | 41h, 42h, 43h |
'X' | 88 | 58h |
"Good night,Gracie" | 略 | 47h, 6Fh, 6Fh, 64h, 20h, 6Eh, 69h, 67h, 68h, 74h, 2Ch, 47h, 72h, 61h, 63h, 69h, 65h |
'4096' | 略 | 34h, 30h, 39h, 36h |
'Say "Good night," Gracie' | 略 | 53h, 61h, 79h, 20h, 22h, 47h, 6Fh, 6Fh, 64h, 20h, 6Eh, 69h, 67h, 68h, 74h, 2Ch, 22h, 20h, 47h, 72h, 61h, 63h, 69h, 65h |
[...'ABC'].map(s => `${s.charCodeAt(0).toString(10)}`).join(', ') // 10进制 ASCII
[...'ABC'].map(s => `${s.charCodeAt(0).toString(16).toUpperCase()}h`).join(', ') // 16进制
3.1.7 保留字
保留字是对编译器有特定含义的词,程序员定义 标识符 时不能用这些词,不然编译器懵逼了就会报错。
- 无大小写区分:默认情况下,保留字不区分大小写,例如,“MOV”、“mov”、"MoV"都被视为相同指令。
- 保留字类型:
- 指令助记符:如 MOV(移动)、ADD(加法)和 MUL(乘法),这些是执行基本操作的命令。
- 寄存器名称:指处理器中的特定存储位置,用于临时存储数据或指令结果。
- 伪指令:指导汇编器如何处理源代码的特殊指令,不直接生成机器码,而是控制编译过程。
- 属性:定义变量和操作数的大小及使用方式,例如 BYTE(字节)和 WORD(字)指定数据的大小。
- 运算符:在表达式中使用的符号,如加、减、乘、除等,用于计算值。
- 预定义符号:如 @data,编译时会替换为具体数值,帮助定位数据段或其他地址。
3.1.8 标识符
标识符定义:
- 标识符是由程序员自定义的
名称,用于给变量、常量、子程序及代码标号命名。 - 它们可以由
1到247个字符组成。 默认情况下,不区分大小写,但可通过编译器选项(如-Cp)使标识符大小写敏感。首字符必须是字母(A-Z,a-z)、下划线_、@、?或$,后续字符可包含数字。
规则与限制:
- 标识符不能与汇编器的保留字重名,以避免冲突。
- 建议
避免首字符使用@和_,因为这些字符在某些上下文中有特殊用途。
命名建议:
- 别怕长,最好见文知意。
- 在同一个项目中,不要混用多种规范。
3.1.9 伪指令
伪指令是专门设计给汇编器在编译阶段使用的命令,用以组织代码结构、分配内存、定义变量类型及尺寸、创建宏等任务。
它们在源代码编译过程中起到配置和辅助作用,是编译阶段的辅助工具,但不会直接转换为机器码本身,对程序的实际运行时行为没有直接影响。
简单的说:每一条指令都有对应的机器码,而伪指令没有对应的机器码。
- 举例:
| 伪指令 | 功能 |
|---|---|
| .code | 定义代码段 |
| .data | 定义数据段 |
| .stack | 定义栈段 |
详见:附录A-伪指令和运算符
3.1.10 指令 instruction
指令语句包含:[标号:] 指令助记符 [操作数][;注释]
1. 标号(Label)
- 标号作为
指令或数据在内存中的地址标记。标号分为数据标号和代码标号两大类。 - 需遵循
标识符的命名规则,确保名称的有效性。 - 标号的
唯一性是基于其所在的子程序来判断的。在不同子程序中两个标号同名互不影响。(局部变量) 代码标号定义结束时需以冒号:作为分隔,数据标号通常直接跟随着数据定义指令。- 标号可以与指令在
同一行,也可以独占一行。
-
数据标号: 用于标识
变量或数据结构的起始地址,允许程序轻松引用这些存储位置。- 定义一个
DWORD类型的变量count值为100count DWORD 100 - 定义一个
DWORD类型数组array。标号指向第一个元素的地址,标号 + 偏移就可以遍历数组了。array DWORD 1024, 2048 DWORD 4096, 8192
- 定义一个
-
代码标号: 则标记指令的地址,常用于控制流管理。
- 如循环和条件跳转。通过在跳转指令(如
JMP)中引用代码标号,可以实现程序流程的定向转移。target: mov ax,bx ... jmp target
- 如循环和条件跳转。通过在跳转指令(如
2. 指令助记符(instruction mnemonic)
指令助记符是以人类可读的形式表示机器码,便于编程与理解。
(指令助记符与机器码并非严格的一对一,一些复杂的汇编指令可能对应多条机器码)
- 举例:

3. 操作数
操作数类型分为:寄存器操作数、内存操作数、整数表达式操作数和输入输出端口操作数

-
寄存器操作数 - 如
eax, ebx, ecx等,寄存器操作数直接参与计算或作为数据源/目标。 -
内存操作数 - 内存操作数指的是存储在主内存中的数据。访问这些数据可以通过变量名、寄存器间接寻址(如 [eax] 表示 eax 寄存器内容作为地址)或直接给出地址来实现。内存操作数允许程序动态读取或写入数据存储位置。
-
整数表达式操作数 - 这类操作数包含基本的数学运算,如加减乘除、位操作等,形成一个计算结果作为指令的一部分。整数表达式可以在指令中直接编码,支持更复杂的操作逻辑而不必先将结果存入寄存器或内存。
-
输入输出端口操作数 - 特指与外部设备交互的数据传输。在某些低级编程或硬件控制场景中,直接读取或写入I/O端口是必要的。这类操作数允许程序与硬件外设如键盘、显示器或自定义硬件组件通信。
- 操作数个数
- 汇编语言指令操作数的个数范围是
0 ~ 3个 - 当指令有多个操作数时:
2.1. 通常第一个操作数被称为目的操作数,
2.2.第二个操作数被称为源操作数(source operand)
- 汇编语言指令操作数的个数范围是
| 操作数个数 | 指令举例 | 说明 |
|---|---|---|
| 0 | stc | 进位标志位置1 |
| 1 | inc eax | eax 自增1 |
| 2 | mov count,ebx | 将 ebx 中的值传给变量 count ( count 相当于C的指针。这句相当于 *count = ebx;) |
| 3 | imul eax,ebx,5 | eax = ebx * 5 |
4. 注释
-
单行注释: 以
:开始。mov ebx, abx ; 这里是注释 -
多行注释: 以伪指令
COMMENT+用户自定义符号开始。COMMENT ! 这里是多行注释 ... 这里是多行注释的第N行 !COMMENT & 这里是多行注释 ... 这里是多行注释的第N行 &
5. NOP(空操作)指令
占用一个字节而不执行任何操作,常被用于代码对齐。
- 通过添加
NOP指令把第三条指令的地址对齐到双字边界(4的偶数倍):
00000000 66 8B C3 mov ax,bx
00000003 90 nop ; 对齐下条指令
00000004 8BD1 mov edx, ecx
-
对齐目的:
x86 架构的处理器为了提高效率,设计为在双字(4字节)边界上加载代码和数据更为高效。这意味着指令或数据的起始地址最好是4的倍数。在上述代码中,mov ax,bx指令后面的指令没有落在双字边界上,这可能会影响CPU的加载效率。 -
如何对齐:
通过在mov ax,bx和mov edx, ecx之间插入一个字节的nop指令,确保了mov edx, ecx指令的起始地址是4的倍数(即双字边界)。这样做虽然消耗了一点额外的存储空间,但提升了潜在的执行效率,尤其是在那些依赖于对齐来加速数据访问的处理器上。
3.1.11 本节回顾
- 使用数值 -35,按照 MASM语法,写出该数值的十进制、十六进制、八进制和二进制格式的整数常量。
解:
| 十进制 | 十六进制 | 八进制 | 二进制 |
|---|---|---|---|
| -35 | DDh | 335o | 11011101b |
不写基数默认为十进制d
-
(是/否):A5h是一个有效的十六进制常量吗?
解: 否。因为以字母开头的的十六进制数,前面要加 0。如:0A5h -
(是/否):整数表达式中,乘法运算符(*)是否比除法运算符(/)具有更高优先级?
解: 否. -
编写一个整数表达式,要求用到 3.1.3 节中的所有运算符。计算该表达式的值。
解:
= ( − 1 + 2 ) ∗ 2 / 2 + 5 m o d 2 = 1 ∗ 2 / 2 + 5 m o d 2 = 2 / 2 + 5 m o d 2 = 1 + 5 m o d 2 = 1 + 1 = 2 \begin{align*} &= (-1+2) * 2\;/\;2 + 5\;mod\;2 \\ &= 1 * 2\;/\;2 + 5\;mod\; 2 \\ &= 2\;/\;2 + 5\;mod\; 2 \\ &= 1 + 5\;mod\; 2 \\ &= 1 + 1 \\ &= 2 \end{align*} =(−1+2)∗2/2+5mod2=1∗2/2+5mod2=2/2+5mod2=1+5mod2=1+1=2 -
按照 MASM 语法,写出实数 − 6.2 × 1 0 4 \color{red}-6.2 \times 10^4 −6.2×104 的实数常量。
解:-6.2E+04 -
(是/否):字符串常量必须被包含在单引号中吗?
解:还可以用双引号。 -
保留字可以用作指令助记符、属性、运算符、预定义符号,和_______?
解: 寄存器名称、伪指令 -
标识符的最大长度是多少?
解:标识符可以由1到247个字符组成。
3.2 示例: 整数加减法
- AddTwo.asm - 两个32位整数相加
.386 ; .386伪指令,声明32位程序,能访问32位寄存器和地址。
.model flat,stdcall ; 伪指令 .MODEL 指定存内存模式为 flat 子程序调用规范 stdcall
.stack 4096 ; 声明栈空间4096字节
ExitProcess proto,dwExitCode:dword ; 声明 ExitProcess 函数原型
; proto 伪指令,用于描述一个外部过程(函数)的原型
; dwExitCode 是函数的参数,代表进程退出时的状态码。
; dw前缀是MS WinAPI 常用的命名约定(32位无符号整数)
; :dword 则表示 dwExitCode 参数为一个32位的无符号整数
.code ; 代码段
main proc ; 子程序 main 开始
mov eax,5 ; eax = 5
add eax,6 ; eax += 6
invoke ExitProcess,0 ; 调用 ExitProcess 结束子程序,返回 0 给操作系统
main endp ; 子程序 main 结束
end main ; 程序入口地址指向 main
执行结果:
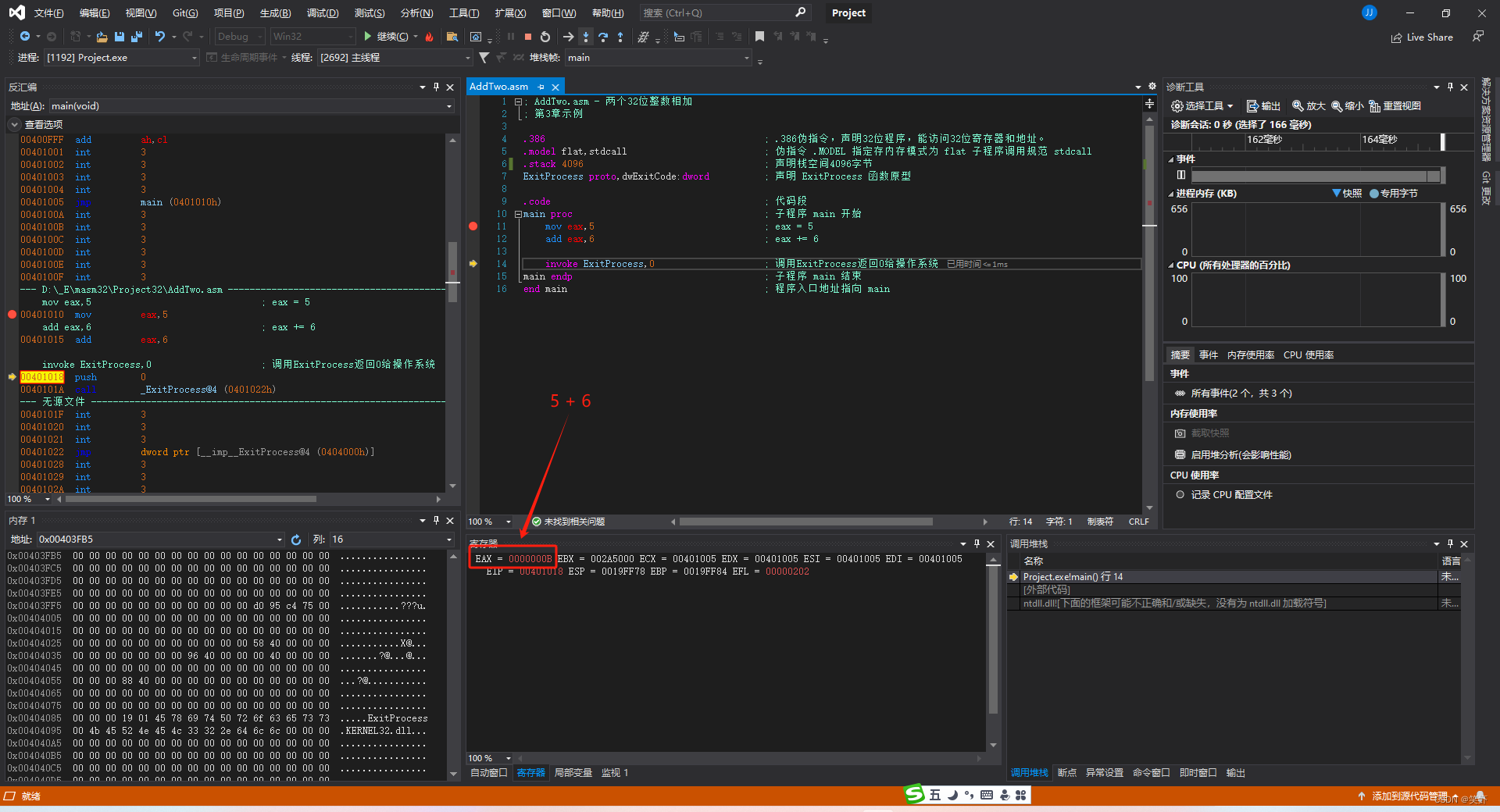
查看:反汇编、内存、寄存器
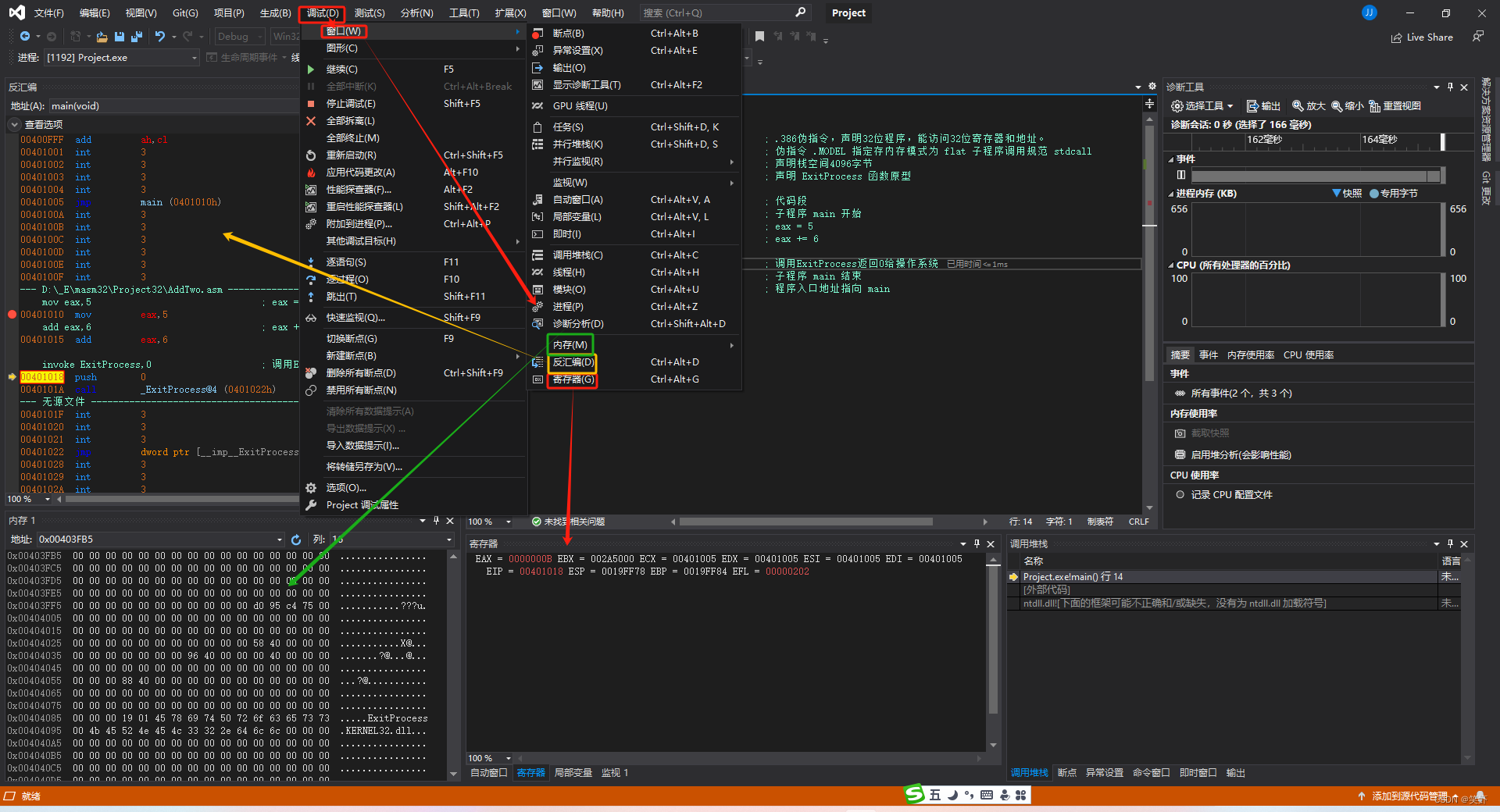
3.3 汇编、链接和运行程序
- 汇编器: 将汇编语言
代码转换为目标文件(机器码)。 - 链接器: 将一个或多个
目标文件与任何必要的外部库、运行时库、系统API以及可执行程序头信息等合并成一个完整的可执行程序。
3.3.1 汇编-链接-执行周期
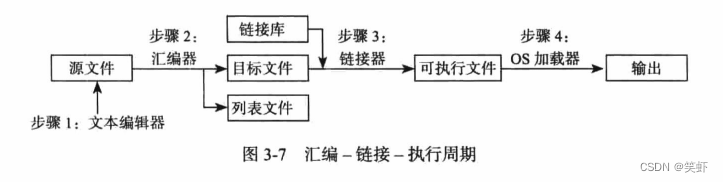
-
步骤1:源代码编写
编程者使用文本编辑器创建源代码文件,这是用高级语言(如C、C++、Python等)或汇编语言编写的文本文件。 -
步骤2:编译/汇编
- 对于高级语言,源代码通过编译器转换为目标代码(机器语言形式),同时可能生成包含警告和错误信息的列表文件。如果发现错误,编程者需要返回编辑源代码。
- 对于汇编语言,汇编器将其转换为目标代码。同样,任何错误都需要修正后重新汇编。
-
步骤3:链接
链接器接手处理目标文件,解决其中的符号引用,将各个模块(包括目标代码和必要的库文件)合并成一个完整的可执行文件。此步骤确保了所有外部函数调用和库函数都被正确地包含进来。
链接过程包括地址重定位,确保所有代码和数据在内存中的正确位置。 -
步骤4:加载与执行
- 操作系统中的加载程序(Loader)将生成的可执行文件加载到内存中,配置好运行环境,包括分配内存空间、设置堆栈等。
- CPU随后开始从程序的入口点执行指令,程序正式运行。
这个流程覆盖了从源代码到程序执行的主要阶段,是软件开发中的核心部分。
3.3.2 列表文件
-
内容组成:列表文件是程序源代码的增强版副本,包含:
- 行号
- 每条指令对应的内存地址(以十六进制形式)
- 每条指令的机器代码(字节形式)
- 符号表,记录所有标识符的名称、所在段及其相关信息
-
用途:对高级程序员而言,列表文件是获取程序详细执行信息的重要资源,有助于调试和优化代码。
-
其他内容:列表文件还可能包含结构、联合、过程、参数及局部变量的详细信息,虽然本例未展示,但这些内容会在后续学习中深入探讨。
让 Visual Studio 生成列表文件
菜单栏 》项目 》项目属性 》
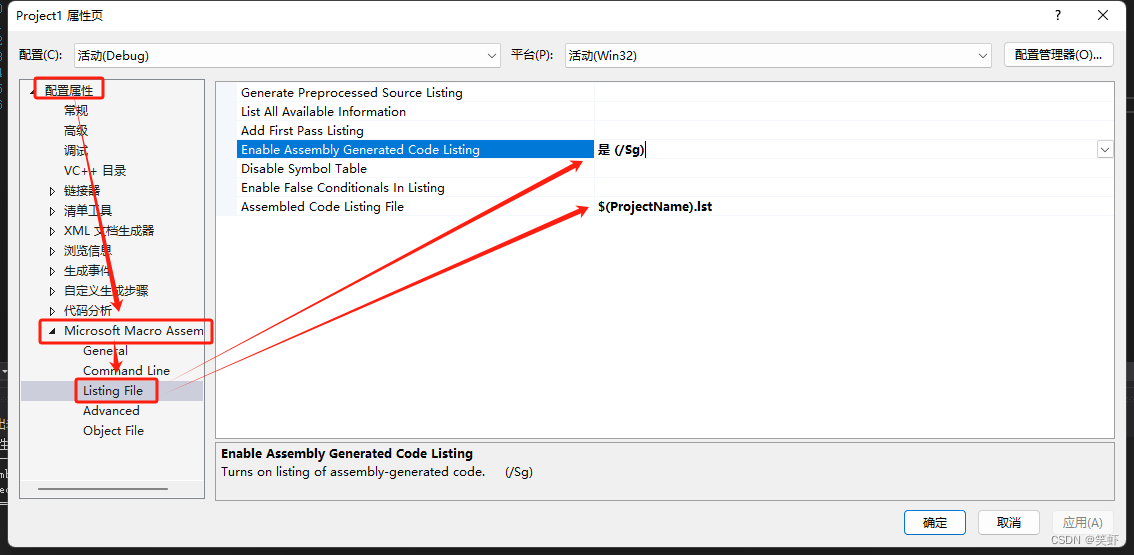
- Project.lst 内容如下:
Microsoft (R) Macro Assembler Version 14.29.30154.0 06/29/24 12:22:21
AddTwo.asm Page 1 - 1
; AddTwo.asm - 两个32位整数相加
; 第3章示例
.386 ; .386伪指令,声明32位程序,能访问32位寄存器和地址。
.model flat,stdcall ; 伪指令 .MODEL 指定存内存模式为 flat 子程序调用规范 stdcall
.stack 4096 ; 声明栈空间4096字节
ExitProcess proto,dwExitCode:dword ; 声明 ExitProcess 函数原型
00000000 .code ; 代码段
00000000 main proc ; 子程序 main 开始
00000000 B8 00000005 mov eax,5 ; eax = 5
00000005 83 C0 06 add eax,6 ; eax += 6
invoke ExitProcess,0 ; 调用ExitProcess返回0给操作系统
00000008 6A 00 * push +000000000h
0000000A E8 00000000 E * call ExitProcess
0000000F main endp ; 子程序 main 结束
end main ; 程序入口地址指向 main
Microsoft (R) Macro Assembler Version 14.29.30154.0 06/29/24 12:22:21
AddTwo.asm Symbols 2 - 1
Segments and Groups:
N a m e Size Length Align Combine Class
FLAT . . . . . . . . . . . . . . GROUP
STACK . . . . . . . . . . . . . 32 Bit 00001000 DWord Stack 'STACK'
_DATA . . . . . . . . . . . . . 32 Bit 00000000 DWord Public 'DATA'
_TEXT . . . . . . . . . . . . . 32 Bit 0000000F DWord Public 'CODE'
Procedures, parameters, and locals:
N a m e Type Value Attr
ExitProcess . . . . . . . . . . P Near 00000000 FLAT Length= 00000000 External STDCALL
main . . . . . . . . . . . . . . P Near 00000000 _TEXT Length= 0000000F Public STDCALL
Symbols:
N a m e Type Value Attr
@CodeSize . . . . . . . . . . . Number 00000000h
@DataSize . . . . . . . . . . . Number 00000000h
@Interface . . . . . . . . . . . Number 00000003h
@Model . . . . . . . . . . . . . Number 00000007h
@code . . . . . . . . . . . . . Text _TEXT
@data . . . . . . . . . . . . . Text FLAT
@fardata? . . . . . . . . . . . Text FLAT
@fardata . . . . . . . . . . . . Text FLAT
@stack . . . . . . . . . . . . . Text FLAT
0 Warnings
0 Errors
3.3.3 本节回顾
- 汇编器生成什么类型的文件?
解: 目标文件.obj,列表文件.lst - (真/假):链接器从链接库中抽取已汇编程序,并将其插入到可执行程序中。
解: 真 - (真/假):程序源代码修改后,它必须再次进行汇编和链接才能按照修改内容执行。
解: 真 - 操作系统的哪一部分来读取和执行程序?
解: 操作系统中的加载程序(Loader) - 链接器生成什么类型的文件?
解: 可执行文件。windows 中.exe
3.4 定义数据
3.4.1 内部数据类型
在汇编语言中,数据类型的区分主要通过:
- 数据的
大小 - 是否有
符号 - 是
整数还是浮点数
汇编器在处理数据类型时只关心数据的大小,
而是否是有符号和整数还是浮点数 需要程序员自己把控。
如果程序员不将32位整数指定为DWORD、SDWORD或REAL4类型,而是尝试使用一个不符合数据大小预期的类型,这将导致几个潜在的问题:
- 类型不匹配:如果试图将一个32位整数放入一个16位的变量中(如
WORD或SWORD),那么数据将被截断,丢失高位的部分信息。相反,如果将它放入一个更大的类型中,如64位的QWORD,虽然不会丢失信息,但这可能不是最优的内存使用方式,并可能导致不必要的性能开销。 - 溢出和截断:当数据是有符号的但被当作无符号处理,或者反过来,这可能导致意外的结果。例如,一个负的
SDWORD值在被当作DWORD处理时会被解释为一个非常大的正数,反之亦然。 - 运算错误:在进行算术运算时,有符号和无符号整数的运算规则是不同的。例如,
SDWORD支持负数,而DWORD不支持。如果不正确地指定类型,可能会导致溢出或错误的运算结果。 - 编译错误或警告:大多数现代编译器和汇编器会检查类型不匹配的情况,并可能发出警告或错误,阻止编译直到类型问题得到解决。
- 总之,在实际编程中,类型错误可能导致难以追踪的bug,因此类型安全是编写健壮代码的关键部分:
- 数据类型之间的
转换需谨慎,特别是涉及有符号和无符号、整型与浮点型之间的转换,以避免逻辑错误和精度损失。 - 遵循IEEE标准的实数类型(如
REAL4和REAL8)保证了跨平台的一致性,但使用时应考虑到其对性能和内存的影响。 - 正确选择数据类型至关重要,它直接影响程序的
效率、资源消耗及数据的正确性。
- 数据类型之间的
表3-2 内部数据类型
| 类型 | 用途 |
|---|---|
| BYTE | 8位无符号整数。B代表字节(byte)。 |
| SBYTE | 8位有符号整数。S代表有符号(signed)。 |
| WORD | 16位无符号整数。 |
| SWORD | 16位有符号整数。 |
| DWORD | 32位无符号整数。D代表双倍(double),相对于字(word)。 |
| SDWORD | 32位有符号整数。SD代表有符号双倍(signed double)。 |
| FWORD | 48位整数(保护模式下的远指针)。 |
| QWORD | 64位整数。Q代表四倍(quad)。 |
| TBYTE | 80位(10字节)整数。是对BCD编码的一种应用(0-9)。T代表十字节(Ten-byte)。最高字节为00h=正数,为80h=负数 其余 9字节存18个10进制数(4位一个,刚好对应) |
| REAL4 | 32位(4字节)IEEE短浮点数。 |
| REAL8 | 64位(8字节)IEEE长浮点数。 |
| REAL10 | 80位(10字节)IEEE扩展浮点数。 |
表3-3 传统数据伪指令
| 伪指令 | 用法 |
|---|---|
| DB | 8 位整数(无符号或有符号) |
| DW | 16 位整数 |
| DD | 32 位整数 或 实数 |
| DQ | 64位整数 或 实数 |
| DT | 定义80位(10字节)整数 |
3.4.2 数据定义语句
语法: [变量名] 指令 初始值 [,初始值]...
举列: count DWORD 12345
-
数据定义语句:用于在内存中
分配一定大小存储区域来保存数据。这些存储区域通常用于存放变量的值。 -
变量:变量是在程序中存储数据的标识符。
变量名是程序员赋予存储位置的名字,以便可以在代码中引用这个位置。 -
内在数据类型:这些是编程语言直接支持的基本数据类型,如整数、浮点数、字符等。在汇编语言中,这些类型通常与机器的字长和数据表示相关联。
-
指令:在数据定义语句中,指令指示汇编器如何处理数据,例如,
DB(定义字节)、DW(定义字)、DD(定义双字)等。每个指令对应于特定的数据类型和大小。 -
初始化值:是在
创建变量时立即赋予变量的值。它可以是一个常数,也可以是另一个表达式的结果。
补充介绍:变量信息
-
变量名与数据标号:
变量名在汇编语言中可以被视为数据标号,它们指向数据在内存中的位置。这些标号允许你在代码中引用数据,而不必直接使用内存地址。 -
偏移量:
在数据段中,每个变量都有一个相对于段起点的偏移量。这个偏移量是变量在内存中的确切位置,它由前一个变量的结束位置(考虑数据类型大小)加上任何必要的对齐填充确定。 -
连续分配:
当你连续定义多个变量时,它们会连续地分配在内存中。如果对齐规则要求,可能会插入填充字节。 -
段基址与偏移量的组合:
变量的完整地址由其所在段的基地址和变量的偏移量共同决定。在运行时,CPU通过将段基地址与偏移量相加来计算变量的确切位置。 -
访问变量:
我们可以在代码中直接使用变量名访问变量的内容,汇编器会将这些名称转换为相应的内存地址,从而然后加载或存储数据。
声明变量(以字节类型举例)
1.多初始值
- 同一次数据定义中的多个值将顺序存储。
list指向第1个值的偏移量。
list BYTE 10, 20, 30, 40
- 使用不同的基数(进制)
list1 BYTE 10, 32, 41h, 00100010b
- 字符和字符串常量可以自由组合
list2 BYTE 0Ah, 20h, 'A', 22h
2. 定义字符串
- 使用
单引号或双引号包围的字符序列来定义字符串,通常以空字节结束。
greeting1 BYTE "Good afternoon",0
greeting2 BYTE 'Good night',0
- 字符串可以跨越多行而不需要每行都有标签。0dh,0ah = CR/LF(回车换行)
greeting1 BYTE "Welcome to the Encryption Demo program "
BYTE "created by Kip Irvine.",0dh,0ah
BYTE "If you wish to modify this program, please "
BYTE "send me a copy.",0dh,0ah,0
- 行延续字符
\用于将两行代码合并为单个语句,且必须位于行尾。以下语句是等效的:
greeting1 BYTE "Welcome to the Encryption Demo program "
greeting1 \
BYTE "Welcome to the Encryption Demo program "
3. DUP 运算符
DUP 操作符用常量表达式作为计数器(通常就是一个非负整数)为多个数据项分配内存,特别适合字符串或数组的初始化或预留空间。
BYTE 20 DUP(0) ; 20个字节,都设置为零
BYTE 20 DUP(?) ; 20个字节,未初始化
BYTE 4 DUP("STACK") ; 20个字节,重复"STACK"
my_array BYTE 20 DUP(3) ; 声明数组 "my_array" 长度 20个字节,初始用 3 填充
- 3.4.3 向 AddTwo 程序添加一个变量(略)
见:3.1.1第一个汇编语言程序
3.4.4 定义8位: BYTE(字节) 和 SBYTE(有符号字节) 数据、DB 伪指令
| 示例 | 描述 |
|---|---|
value1 BYTE 'A' | 存储字符’A’到无符号字节中。 |
value2 BYTE 0 | 最小的无符号字节值。 |
value3 BYTE 255 | 最大的无符号字节值。 |
value4 SBYTE -128 | 最小的有符号字节值。 |
value5 SBYTE +127 | 最大的有符号字节值。 |
value6 BYTE ? | 问号初始化器:只声明空间,未初变量(此时它的值是不确定的) |
val1 DB 255 | 无符号字节 |
val2 DB -128 | 有符号字节 |
3.4.5 定义16位: WORD(字) 和 SWORD(有符号字)数据。DW伪指令
| 变量名 类型 初始值 | 含义 |
|---|---|
word1 WORD 65535 | 最大无符号数 |
word2 SWORD -32768 | 最小有符号数 |
word3 WORD ? | 未初始化,无符号 |
val1 DW 65535 | 无符号 |
val2 DW -32768 | 有符号 |
array WORD 5 DUP(?) | 字数组,5个元素,未初始化 |
myList WORD 1,2,3,4,5 | 字数组(16位) |
假设 myList 起始偏移为 0000:
| 偏移量 | 0000 | 0002 | 0004 | 0006 | 0008 |
|---|---|---|---|---|---|
| 数值 | 1 | 2 | 3 | 4 | 5 |
3.4.6 定义32位: DWORD(双字) 和 SDWORD(有符号双字)数据。DD伪指令
| 变量名 类型 初始值 | 含义 |
|---|---|
val1 DWORD 12345678h | 无符号 |
val2 SDWORD −2147483648 | 有符号 |
val3 DWORD 20 DUP(?) | 无符号 数组 |
val1 DD 12345678h | 无符号 |
val2 DD −2147483648 | 有符号 |
pVal DWORD val3 | 保存另一个变量的32位地址(偏移量) |
myList DWORD 1,2,3,4,5 | 双字数组(32位) |
3.4.7 定义64位: QWORD(四字) 数据。DQ伪指令
| 变量名 类型 初始值 | 含义 |
|---|---|
quad1 QWORD 1234567812345678h | 用 QWORD 定义64位变量 |
quad1 DQ 1234567812345678h | 用 DQ伪指令 定义64位变量 |
3.4.8 定义压缩 BCD(TBYTE)数据
| 变量名 类型 初始值 | 含义 |
|---|---|
intVal TBYTE 800000000000001234h | 正常 |
intVal TBYTE -1234 | 无效 |
3.4.9 定义浮点类型
| 变量名 类型 初始值 | 含义 |
|---|---|
rVal1 REAL4 -1.2 | 声明4字节单精度浮点变量 |
rVal2 REAL8 3.2E-260 | 声明8字节双精度数值 |
rVal3 REAL10 4.6E+4096 | 声明10字节扩展精度数值 |
ShortArray REAL4 20 DUP(0.0) | 声明一个由20个初始化为零的单精度浮点数(各占4字节)组成的数组 |
rVal1 DD -1.2 | 短实数 |
rVal2 DQ 3.2E-260 | 长实数 |
rVal3 DT 4.6E+4096 | 扩展精度实数 |


3.4.10 变量加法程序
- AddVariables.asm - 三整数相加,结果存入第4个变量
.386 ; .386伪指令,声明32位程序,能访问32位寄存器和地址。
.model flat,stdcall ; 伪指令 .MODEL 指定存内存模式为 flat 子程序调用规范 stdcall
.stack 4096 ; 声明栈空间4096字节
ExitProcess proto,dwExitCode:dword ; 声明 ExitProcess 函数原型
.data
firstval dword 20002000h ; 第一个变量
secondval dword 11111111h ; 第二个变量
thirdval dword 22222222h ; 第三个变量
sum dword 0 ; 第四个变量,用来存放前三个整数相加之和
.code
main proc
mov eax,firstval ; eax = firstval
add eax,secondval ; eax += secondval
add eax,thirdval ; eax += thirdval
mov sum,eax ; sum = eax
invoke ExitProcess,0 ; 调用ExitProcess返回0给操作系统
main endp ; 子程序 main 结束
end main ; 程序入口地址指向 main

3.4.11 小端顺序
x86 架构通常采用小端顺序
以数据 12345678h 为例:
| 内存地址(偏移量) | 0000 | 0001 | 0002 | 0003 | 说明 |
|---|---|---|---|---|---|
| 小端序 | 78h | 56h | 34h | 12h | 将数据的:低位字节存在低地址,高位字节存在高地址 |
| 大端序 | 12h | 34h | 56h | 78h | 将数据的:高位字节存在低地址,低位字节存在高地址 |
3.4.12 声明未初始化数据
.DATA? 伪指令
-
.DATA?伪指令:是一个可选数据段指令,通常用于定义未初始化的数据。这意味着这些数据在程序编译时不会被初始化,而是在程序运行时由操作系统或程序本身进行初始化。 -
减少编译程序的大小:当定义大量未初始化数据时,使用
.DATA?指令可以减少生成的可执行文件的大小。这是因为这些数据不会在可执行文件中预先分配空间和初始化,从而节省了存储空间。 -
动态内存分配:在程序运行时,这些未初始化的数据可以通过动态内存分配的方式(如使用
malloc或HeapAlloc等函数)来分配内存。这样做的好处是:- 节省空间:在可执行文件中不包含这些数据,从而减少文件大小。
- 灵活性:在程序运行时根据需要动态分配内存,可以根据实际使用情况调整内存分配策略。
-
适用场景:这种技术特别适用于那些数据量很大,但在程序启动时不需要立即使用的场景。例如,某些大型数据集或资源文件可能只在用户请求时才需要加载。
使用 .DATA? 伪指令声明未初始化数据:
.data
smallArray DWORD 10 DUP(0) ; 40 个字节
.data?
bigArray DWORD 5000 DUP(?) ; 20,000 个字节, 未初始化
如果不使用 .DATA? 编译出来的程序将会多 20,000 个字节
.data
smallArray DWORD 10 DUP(0) ; 40 个字节
bigArray DWORD 5000 DUP(?) ; 20,000 个字节

代码与数据混合
在汇编语言编程中,虽然可以交替编写代码段和数据段,但这样可读性差,不是一个好习惯。比如:
.code
mov eax,ebx
.data
temp DWORD ?
.code
mov temp,eax
. . .
3.4.13 本节回顾
-
为一个16位有符号整数创建未初始化数据声明。
解:word1 SWORD ? -
为一个8位无符号整数创建未初始化数据声明。
解:byte1 BYTE ? -
为一个8位有符号整数创建未初始化数据声明。
解:sbyte1 SBYTE ? -
为一个64 位整数创建未初始化数据声明。
解:qword1 QWORD ? -
哪种数据类型能容纳32位有符号整数?
解:SDWORD
3.5 符号常量 symbolic constant
符号常量 (也叫符号定义 symbolic definition) 就是给数字或文本指定一个名字,这些名字在程序运行时不会改变,并且不占用实际的存储空间。
- 下表总结了
符号与变量之间的不同:

3.5.1 = 伪指令 (equal-sign directive)
= 伪指令用于定义符号与整数表达式的关联。
符号名称起一个占位符的作用,在汇编阶段会被替换为表达式的结果`。- 对于多次使用的数值,使用
符号名称表示便于统一修改。 - 定义的符号常量不占用存储空间(只是起到一个在汇编期间的关联和替换作用)
- 用
=定义的符号,在同一程序内可以被重新定义。
语法:符号名称=表达式
-
以定义键盘代码为例:
- 使用
=定义符号Esc_key = 27 - 使用
符号mov al,Esc_key - 以上代码在汇编时会被替换为:
mov al,27
- 使用
-
用于 DUP 操作符
- 使用
=定义符号COUNT = 500 - 使用
符号array dword COUNT DUP(0) - 以上代码在汇编时会被替换为:
array dword 500 DUP(0)
- 使用
-
可重定义
COUNT = 5 mov al,COUNT ; AL = 5 COUNT = 10 mov al,COUNT ; AL = 10 COUNT = 100 mov al,COUNT ; AL = 100
3.5.2 当前地址计数器 $ 计算数组和字符串的大小
当前地址计数器 $(current location counter)
代表它所在行的(在当前段内的)偏移地址
-
计算
数组长度list BYTE 10,20,30,40 ; 定义 list 数组 ListSize =($ - list) ; 用本行偏移量 - list偏移量,得出数组大小赋给 ListSize地址是按字节算的,如果元素是
字则总长度需要除以2list WORD 1000h,2000h,3000h,4000h ListSize =($ - list) / 2同理
双字总长度则需要除以4list DWORD 10000000h,20000000h,30000000h,40000000h ListSize =($ - list) / 4 -
计算
字符串长度myString BYTE "This is a long string, containing" BYTE "any number of characters" myString_len = ($ - myString)
3.5.3 EQU 伪指令
EQU 伪指令用于在程序中为标识符赋予常量值或表达式的值,以便在后续的代码中使用。
- 与
=相比,EQU除了能关联整数表达式还能关联任意文本。 - 与
=相比,EQU不能重复定义。(在同一源代码文件中) - 与
=相比,EQU定义的符号在整个程序中可见,而=通常在定义它的段或模块内可见。
语法:
符号名称EQU整数表达式
符号名称EQU已存在的符号名称(之前通过 = 或 EQU 定义的)
符号名称EQU<文本>
-
定义实数常量
PI EQU <3.1416> -
定义符号
pressKey再用其声明变量promptpressKey EQU <"Press any key to continue...",0>.data prompt BYTE pressKey -
表达式与文本的区别matrix1 EQU 10 * 10 matrix2 EQU <10 * 10> .data M1 WORD matrix1 M2 WORD matrix2替换后
M1 WORD 100 ; 表达式会算出结果,再替换 M2 WORD 10 * 10 ; 文本则直接原样替换
3.5.4 TEXTEQU 伪指令
TEXTEQU 与 EQU 类似,但:
TEXTEQU主要用于定义复杂的文本宏,它可以将一段文本或表达式定义为一个符号。TEXTEQU定义的符号随时可以被重新定义。
语法:
符号名称TEXTEQU<文本>
符号名称TEXTEQU文本宏(之前通过 TEXTEQU 定义的符号)
符号名称TEXTEQU%整数表达式
-
prompt1使用文本宏continueMsgcontinueMsg TEXTEQU <"Do you wish to continue (Y/N)?"> .data prompt1 BYTE continueMsg -
文本宏可以相互构建
rowSize = 5 count TEXTEQU %(rowSize * 2) move TEXTEQU <mov> setupAL TEXTEQU <move al,count>最终
setupAL会被汇编为mov al,10打个断点跑起来看一下,
反汇编窗口中列出了每条语句的汇编前后对比。
可见,汇编后宏文本成功替换,符合预期:

3.5.5 本节回顾
-
用等号伪指令定义一个符号常量,使其包含 Backspace 键的ASCII码(08h)。
解:Backspace = 08h -
用等号伪指令定义符号常量 SecondsInDay,并为其分配一个算术表达式计算 24小时包含的秒数。
解:SecondsInDay = 24 * 60 * 60 -
编写一条语句使汇编器计算下列数组的字节数,并将结果赋给符号常量 ArraySize:
解:myArray WORD 20 DUP(?) ArraySize = ($ - myArray) -
说明如何计算下列数组的元素个数,并将结果赋给符号常量 ArraySize:
解:myArray DWORD 30 DUP(?) ArraySize = ($ - myArray) / 4 -
使用 TEXTEQU 表达式将 “proc” 重定义为 “procedure”
解:procedure TEXTEQU <proc> -
使用 TEXTEQU 将一个字符串常量定义为符号 Sample,再使用该符号定义字符串变量 MyString。
解:Sample TEXTEQU <"大家好,我是笨笨,笨笨的笨,笨笨的笨,谢谢!"> .data MyString byte Sample -
使用 TEXTEQU 将下面的代码行赋给符号 SetupESl:
解:SetupESl TEXTEQU <mov esi,OFFSET myArray>
3.6 64位编程
VS2012开始带64位版本的汇编器。
配置64位项目见:这里

3.7 本章小结
略
3.8 关键术语
略
参考资料
笑虾:《汇编语言 基于x86处理器》- 读书笔记 - Visual Studio 2019 配置 MASM环境 - 配置项目 64位汇编
Getting Started with MASM and Visual Studio 2019
Tutorial: 构建和运行64位程序