🎯 这里我们使用,百度飞浆产品进行操作
- 至少需要提供一分钟的原声视频,越清晰越好,用于分析人物音色、声纹等特点。
- 预防针:这块稍微有点难度,涉及代码,不过不用担心,照着操作即可。
- 官网链接:飞桨AI Studio星河社区-人工智能学习与实训社区
3.2.1 选择项目并运行 GPU 环境
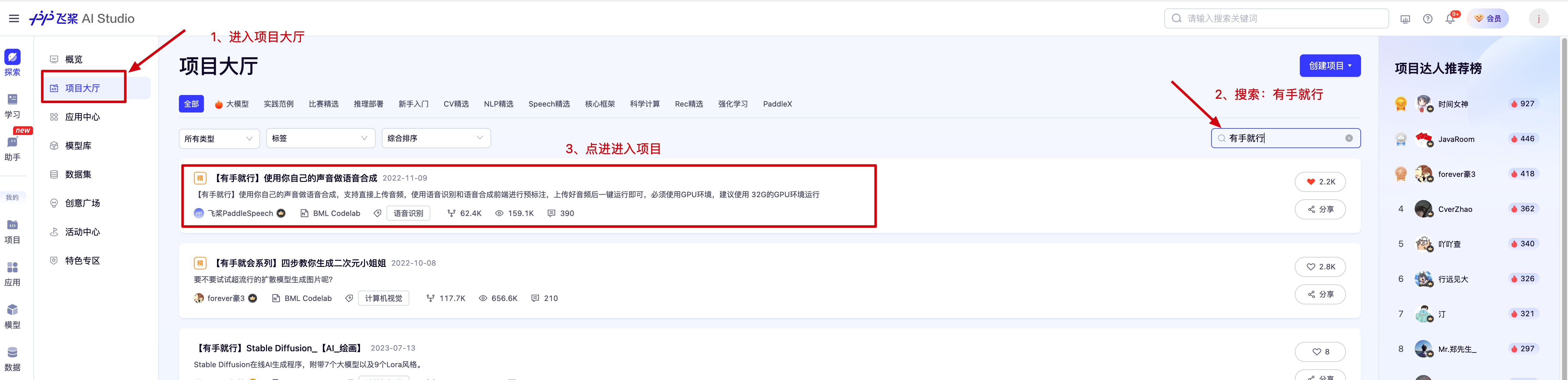
1、进入项目大厅,进入【有手就行】项目
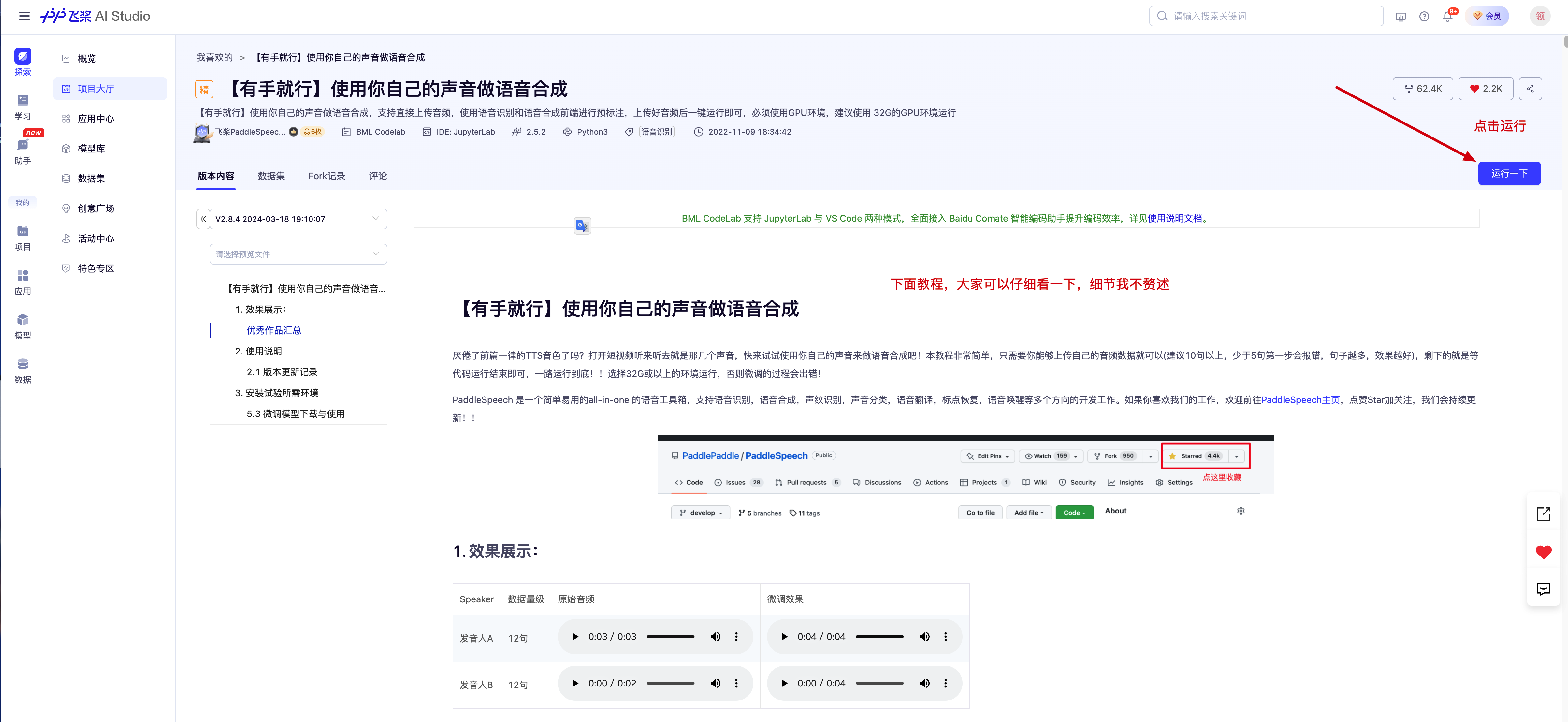
2、点击运行,大家也可以看看项目说明,里面教程也很详细
3、进入环境时,一定要选择 32G或以上的GPU环境运行,CPU环境无法运行
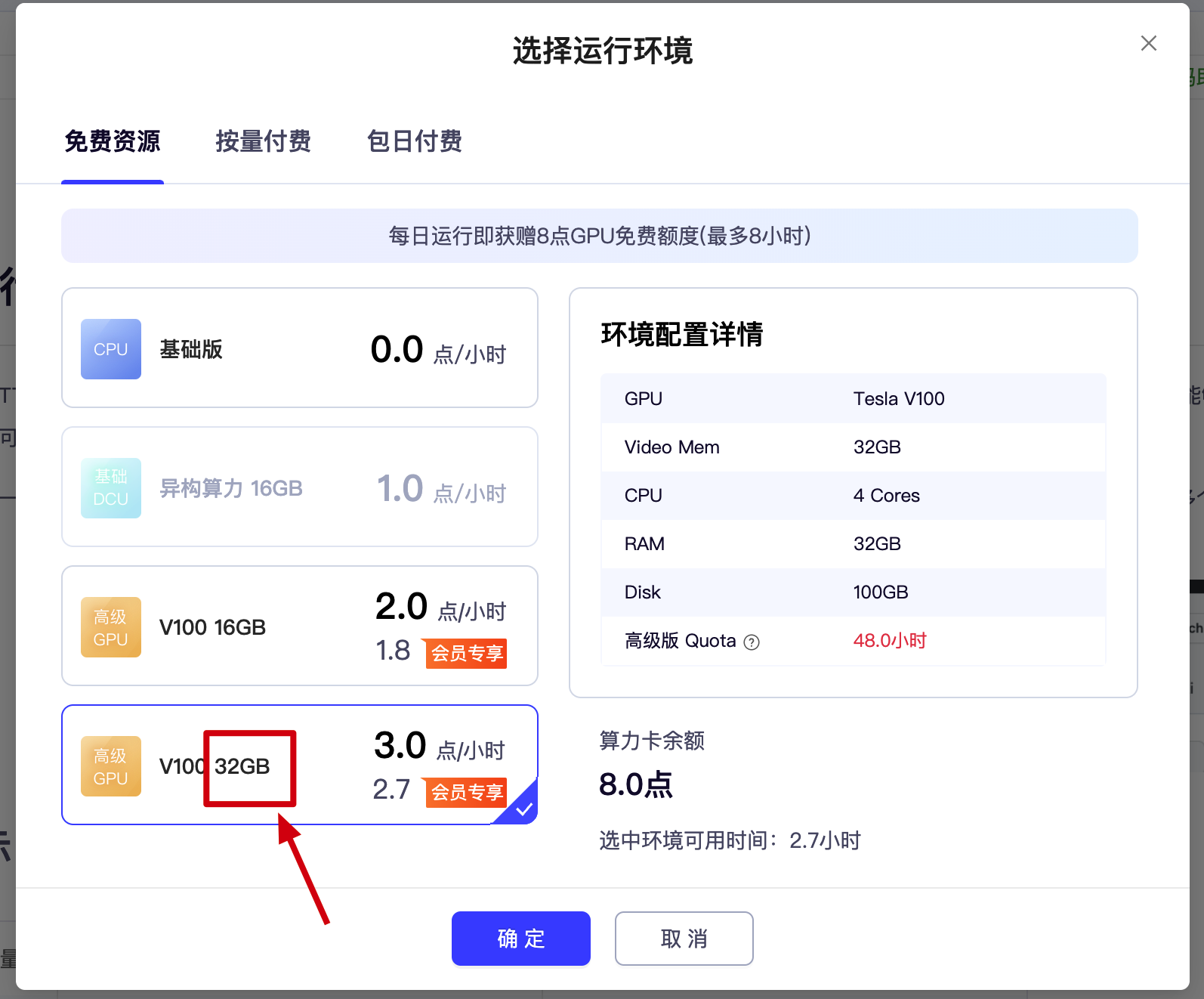
等待启动
点击进入

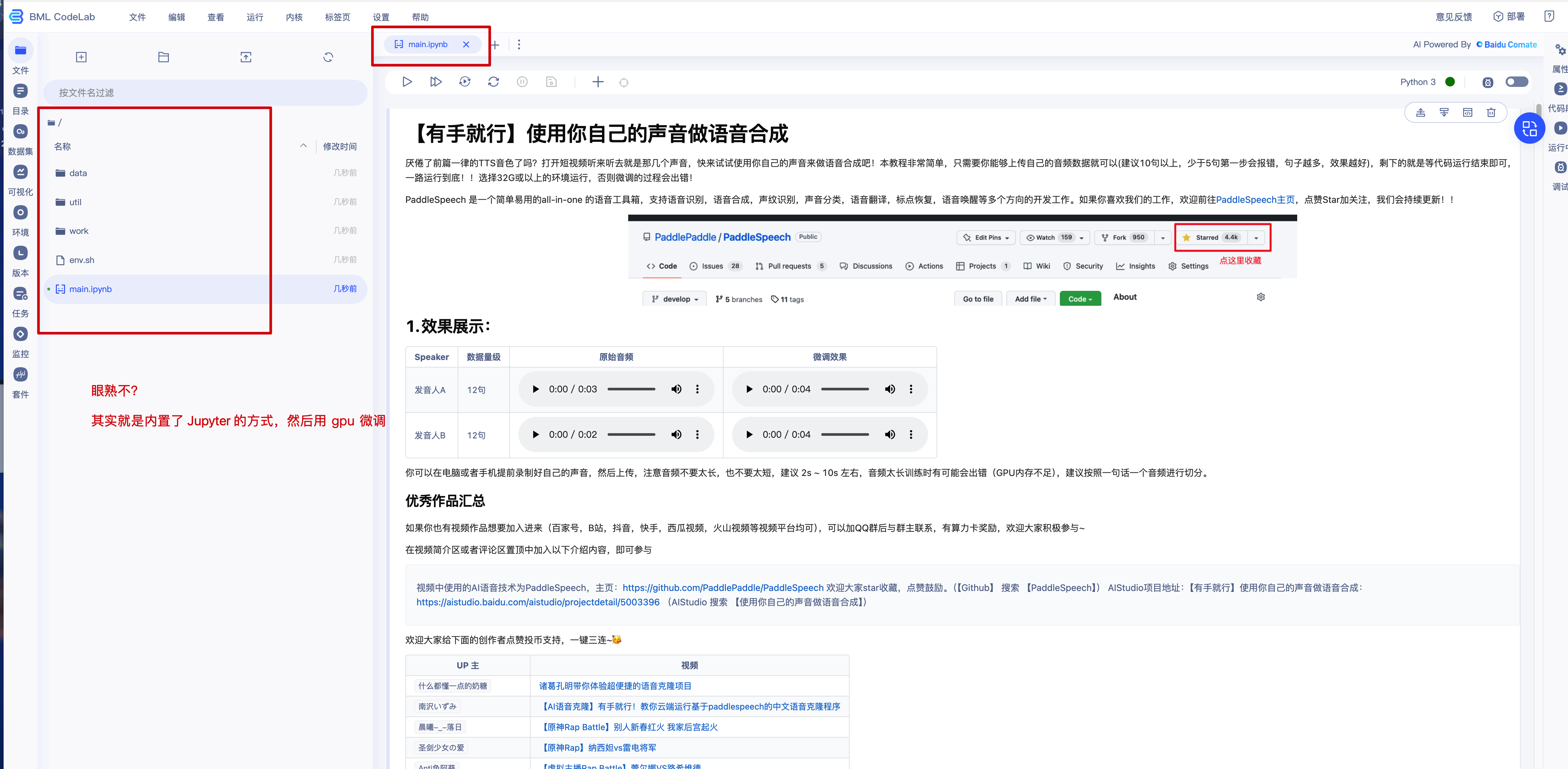
3.2.2 开始微调【慢慢来】
🎯 注意:
- 这是一个 python 文件,前面买的 CPU 就是作微调用的。
- 大家需要挨个代码段点击▶️按钮运行程序,一定要按顺序运行,并且要保证前面的代码运行成功再运行后面的代码,运行前请看好如下说明。
- 如果跳着运行,会出错。
点击红框处的 ▶️ 按钮运行

运行完,重启一下内核(同一个文件,往下滑就看到了)

然后开始挨个运行下面的代码段(不需要重启内核了)
下载依赖,这步骤时间较长,耐心等待
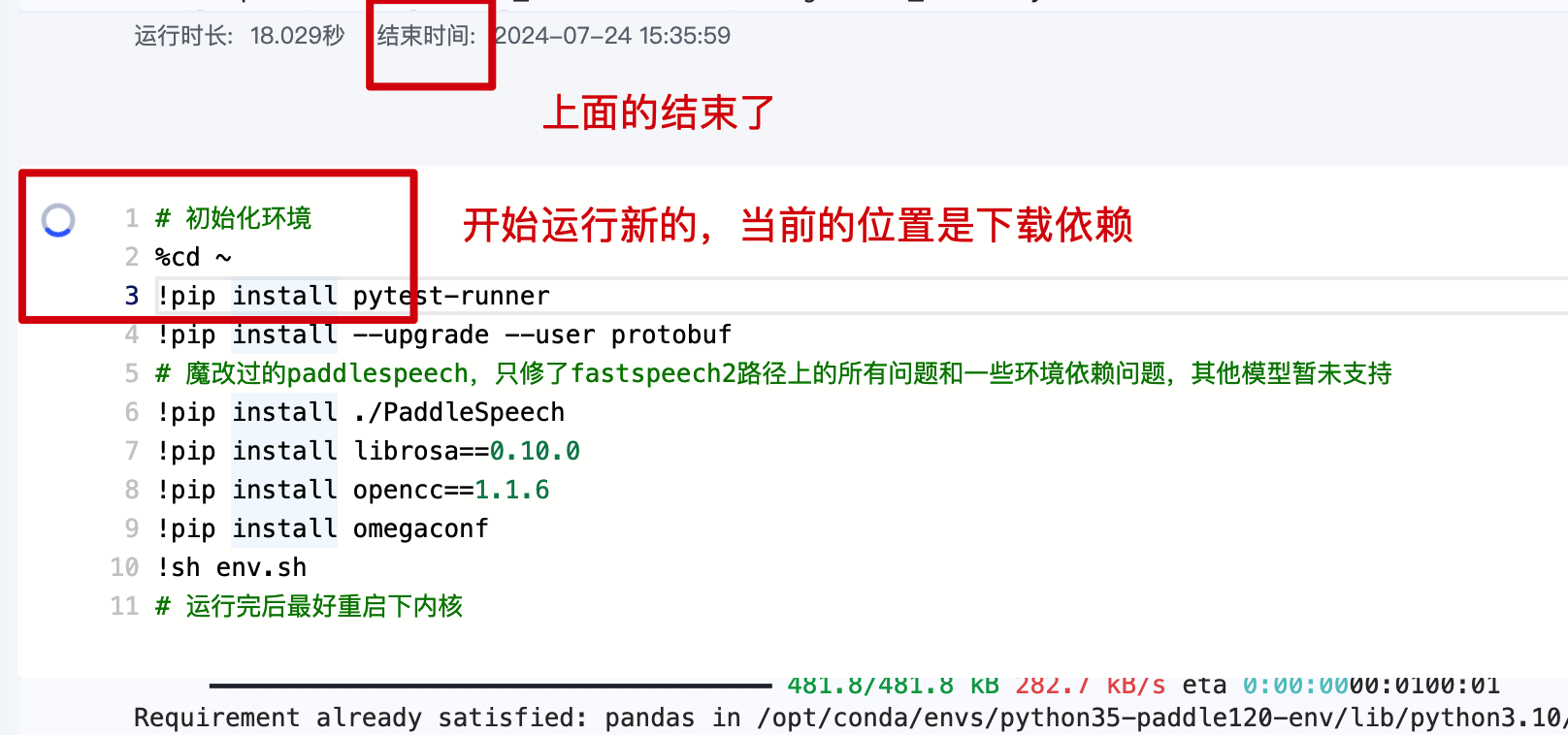

中间几个同样操作,挨个运行,省略...
当运行到下图位置时,修改文件路径上传音频文件后,再运行
修改文件路径(同一个文件,往下滑就看到了)
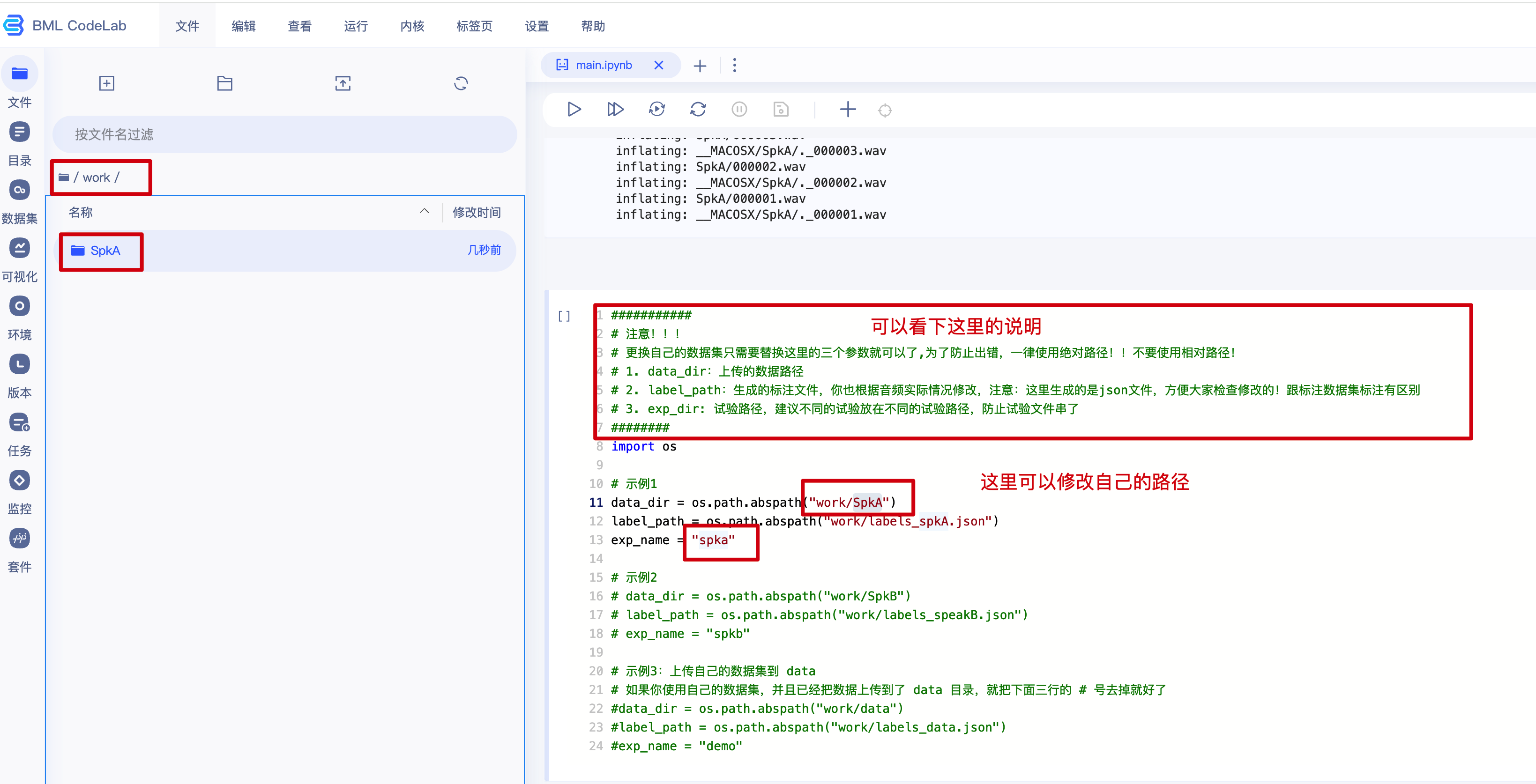
将准备好的音频上传到刚刚的文件夹(音频切割工具可以使用 slicer-gui)
🎯 上传的音频数据说明:
- 对于语音合成任务,对数据是有一定要求的,尽可能上传干净的人声数据,比如像示例中的人声数据,在安静环境下录制,录制设备无论是手机,电脑,还是别的设备都可以,注意一定要控制噪音,或者提前使用音频剪辑软件进行降噪。
-
- 音频不要太长,也不要太短,建议2s~10s之间
- 音频尽量是干净人声,不要有BGM,不要有比较大的杂音,不要有一些奇奇怪怪的声效,比如回声等
- 声音的情绪尽量稳定,以说话的语料为主,不要是『嗯』『啊』『哈』之类的语气词
- 关于录音工具
-
- 你可以使用一些在线运行的录音工具或者 【Adobe Audition】,【Cool Edit Pro】, 【Audacity】 等录音软件录制音频,保存为 24000采样率的 Wav 格式
- 这里方便大家联系,给大家提供一组音频如下👇
- 📎SpkA.zip
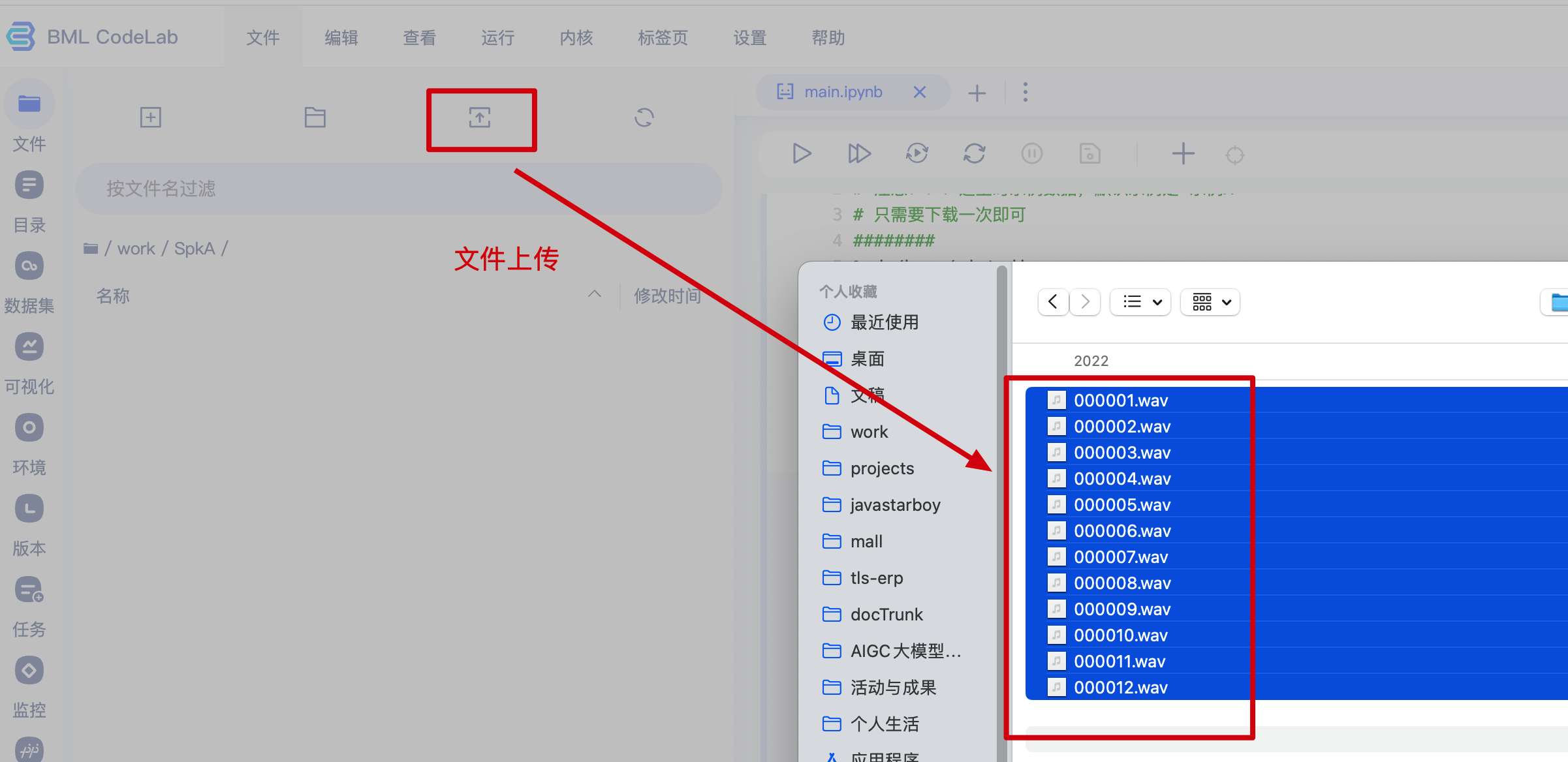
记得点击▶️按钮运行哦

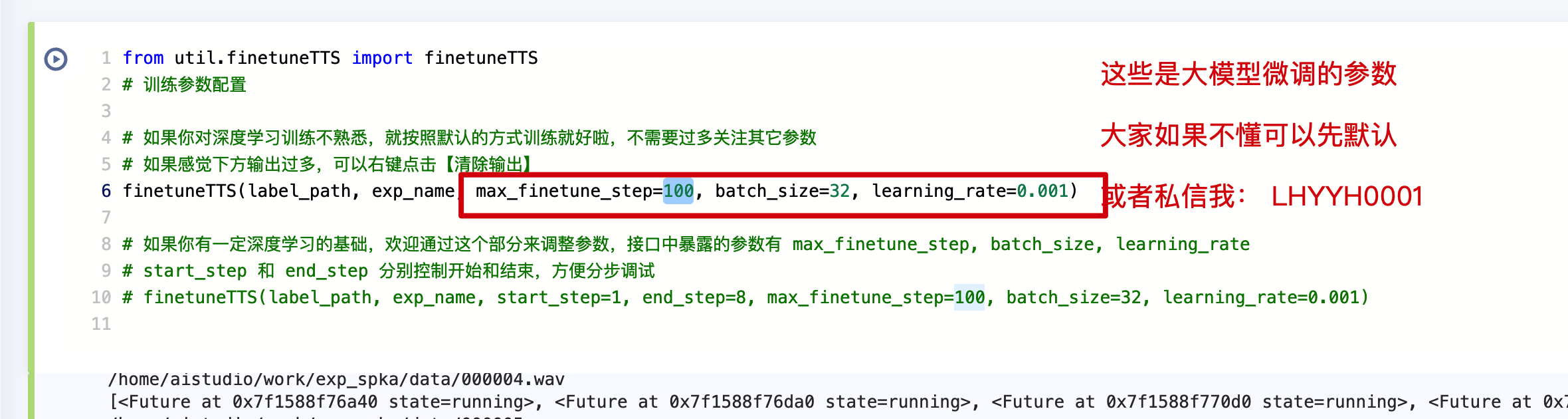
微调参数调整
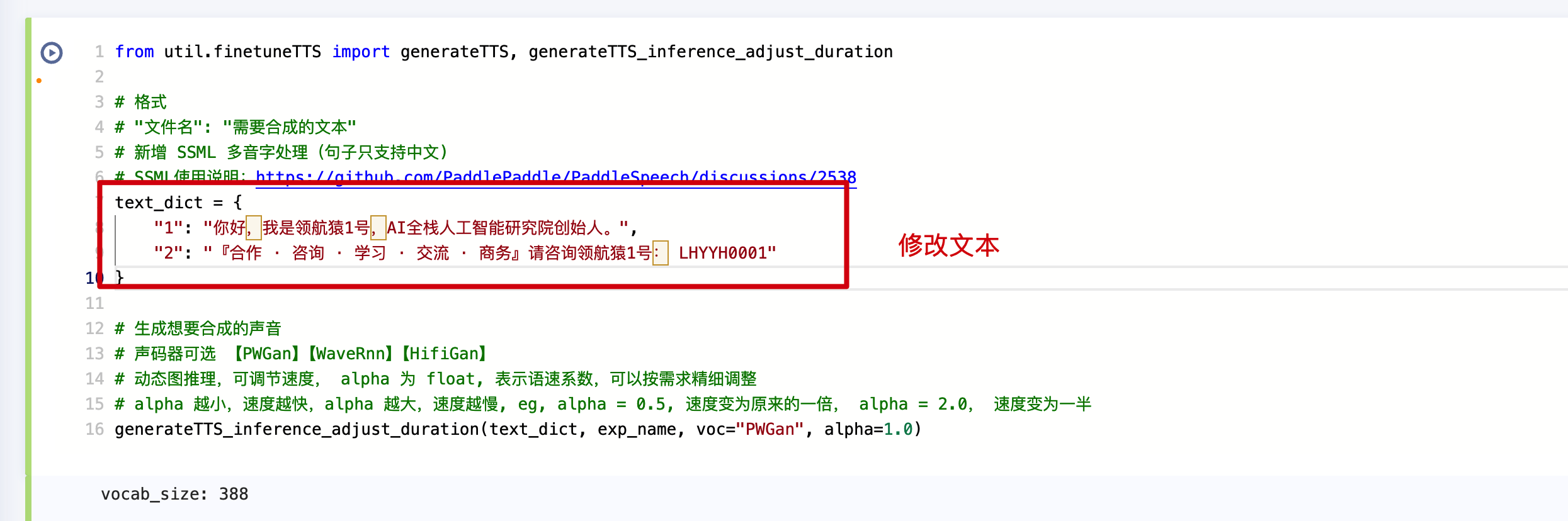
修改文本
全部运行完成后

下载音频:上面代码块运行后,按下面的方式下载音频

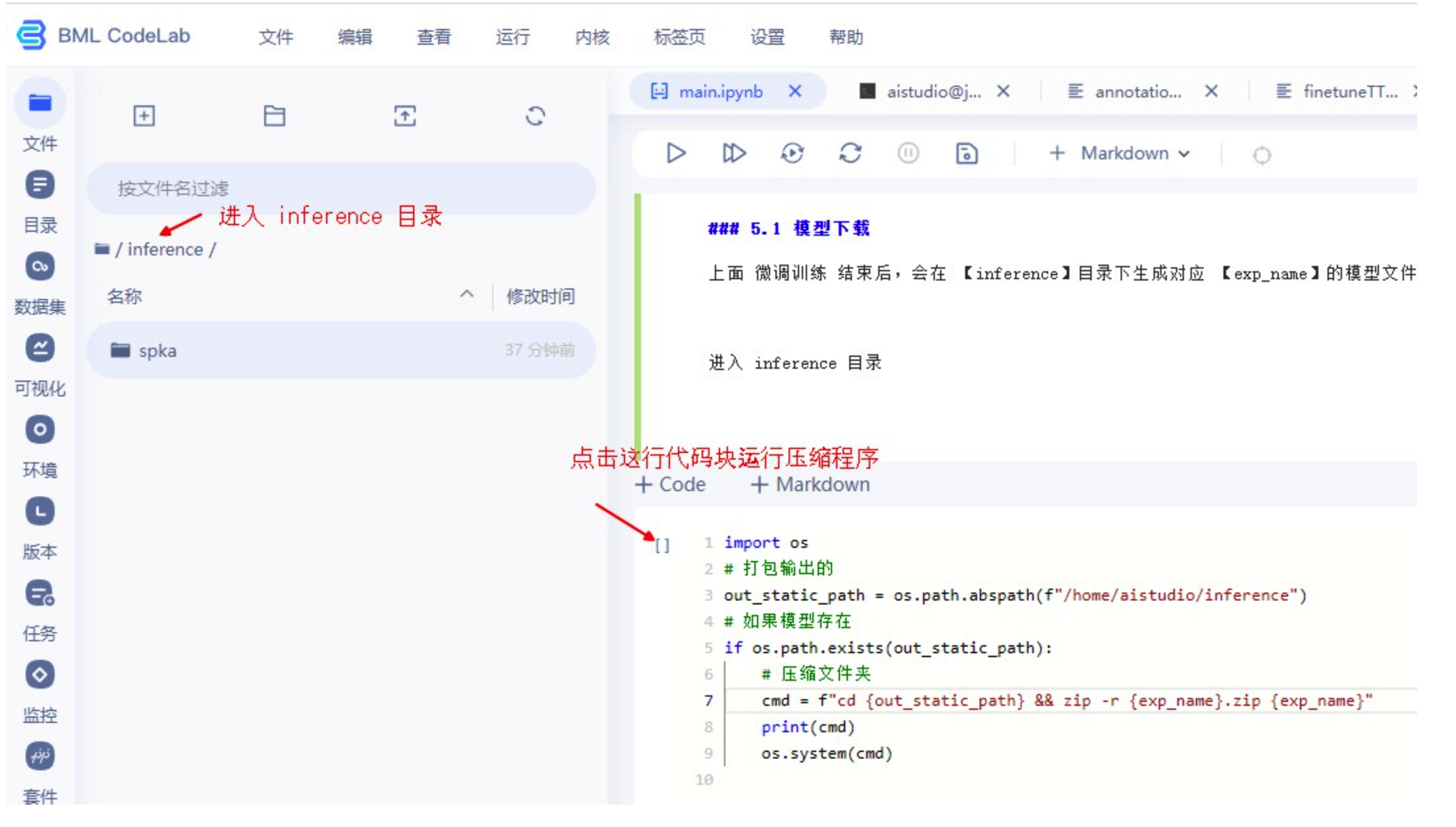
3.3.3 微调模型下载与使用
模型下载
上面 微调训练 结束后,会在 【inference】目录下生成对应 【exp_name】的模型文件夹,使用下面的代码块生成对应压缩文件,右键点击下载即可

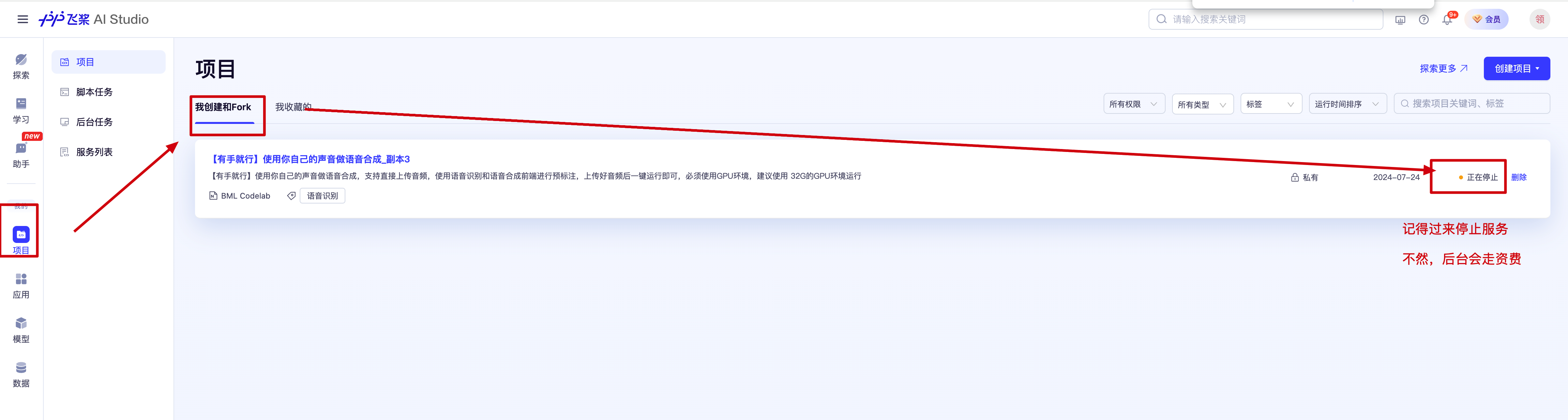
3.2.4 停止服务
一般人不会告诉你这一步,服务记得停掉,因为前面的 GPU 是按小时收费的。
不过刚刚用的这会,不用担心,新人有免费额度。
查看自己剩余算力卡







![[CISCN2019 华东南赛区]Web11](https://i-blog.csdnimg.cn/direct/82de5bd4f77f4d218d74c63d1823a0cd.png)