文章目录
- vector介绍
- **vector iterator 的使用**
- `vector`迭代器失效问题
- 由扩容或改变数据引起的迭代器失效
- `reserve`的实现(野指针)
- `insert`实现(迭代器位置意义改变)
- `insert`修改后失效的迭代器
- `it`迭代器失效
- `erase`后的问题
- 总结:`std::vector` 中的迭代器失效和避免方法
- **插入操作**
- **解决方法**
- **删除操作及解决方法**
- 一定要注意迭代器的更新!!!
- 其他问题
- 依赖名称
- 模板与依赖名称
- typename关键字
- 具体示例分析
- 类外定义成员函数
- 类内定义函数模板
- 函数模板的应用
- 使用的注意事项
- **使用memcpy拷贝问题**
- 问题引出
- 调试分析
- 解决措施
- 理解使用 `vector` 构造动态二维数组
- 什么是二维数组?
- 使用 `std::vector` 构造动态二维数组
- 构造方法
- 解析
- 定义二维数组
- 初始化二维数组
- 打印二维数组
- 动态调整大小

vector介绍
使用模版指针作为迭代器的方式使用
vector
typedef T* iterator;
typedef const T* const_iterator;
成员变量:
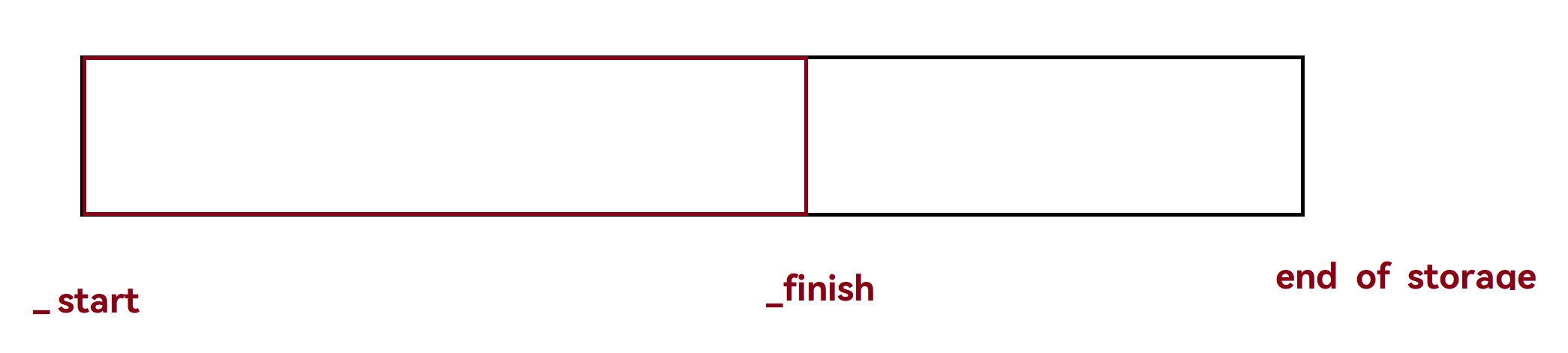
iterator _start = nullptr; // 容器的头
iterator _finish = nullptr; // 容器内最后一个数据
iterator _end_of_storage = nullptr; // 容器的最大容量处
_start:通常表示容器的开始位置,即指向容器中第一个元素的指针或迭代器。在某些实现中,这可能不是实际存储数据的地址,而是一个指向存储开始的指针。_finish:通常表示容器中最后一个有效元素的下一个位置。这意味着_finish指向的位置是容器中最后一个元素之后的位置,但它本身并不指向一个有效的元素。在C++的std::vector中,finish可能用来表示容器的结束,但实际使用时应该使用end()成员函数(end()和_finish指向相同)。_end_of_storage:表示容器分配的内存的末尾。这通常比_finish要远,因为它包括了容器当前使用的所有元素以及可能预留的额外空间,以便于将来的元素扩展,而不需要重新分配内存。
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}
const_iterator begin() const
{
return _start;
}
const_iterator end() const
{
return _finish;
}
vector iterator 的使用
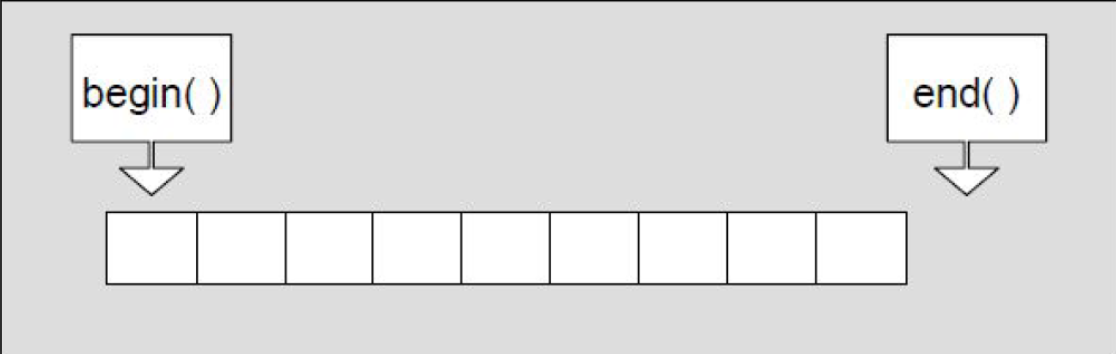
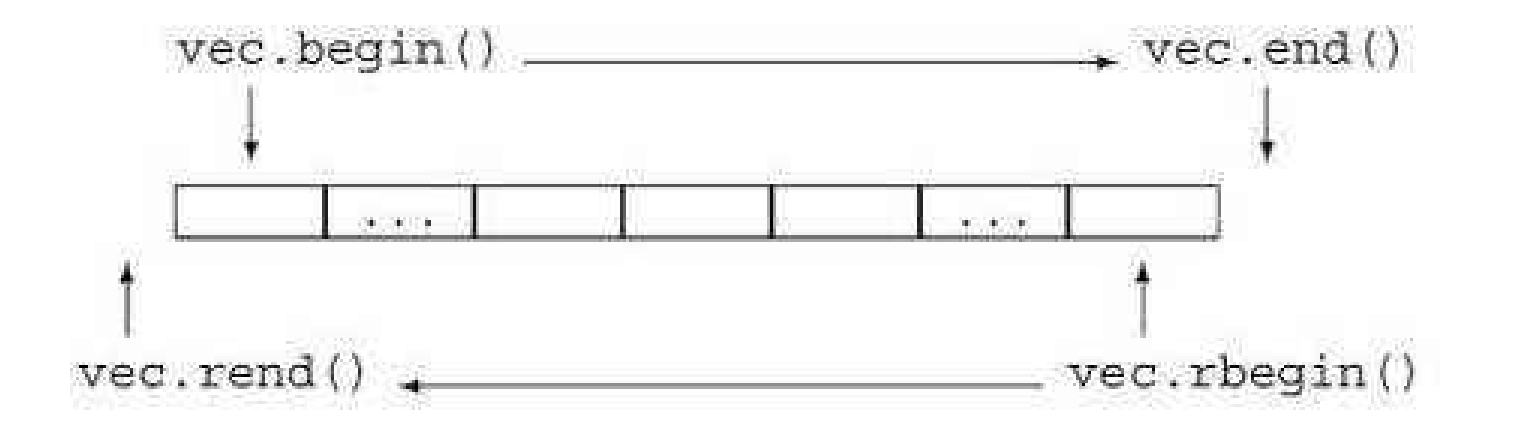
| iterator的使用 | 接口说明 |
|---|---|
begin + end (重点) | 获取第一个数据位置的iterator/const_iterator,获取最后一个数据的下一个位置的iterator/const_iterator |
rbegin + rend | 获取最后一个数据位置的reverse_iterator,获取第一个数据前一个位置的reverse_iterator |

vector迭代器失效问题
迭代器失效主要是由于 vector 在执行某些操作时会重新分配内存或改变数据的位置,导致原有的迭代器指向的内存地址不再有效。以下是一些常见的会导致迭代器失效的操作:
由扩容或改变数据引起的迭代器失效
reserve的实现(野指针)
例如在模拟实现vector中的reserve时:
void reserve(size_t n)
{
if (n > capacity())
{
size_t old_size = size();
T* tmp = new T[n];
memcpy(tmp, _start, size() * sizeof(T));
delete[] _start;
_start = tmp;
_finish = tmp + old_size;
_end_of_storage = tmp + n;
}
}
可能出现迭代器失效具体代码为:
_start = tmp;
_finish = tmp + old_size;
_end_of_storage = tmp + n;
内部扩容的时候直接申请一块新的tmp空间,此时如果改为以下:
_start = tmp;
_finish = _start + size();
_end_of_storage = _start + n;
由于size()接口实现如下:
size_t size()
{
return _finish - _start;
}
当调用sizeof()接口时,此时里面的_finish还是曾经未使用memcpy(tmp, _start, size() * sizeof(T));时原来的_finish指向的位置,所以此时使用_finish = _start + size();来计算_finish时就会出现迭代器失效的问题。
insert实现(迭代器位置意义改变)
模拟实现insert()时,pos会出现失效问题:
由于数据挪动,已经不是指向2,所以
insert以后我们认为迭代器失效,不要访问
iterator insert(iterator pos, const T& x)
{
// 扩容
if (_finish == _end_of_storage)
{
size_t len = pos - _start;
reserve(capacity() == 0 ? 4 : capacity() * 2);
pos = _start + len;
}
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
--end;
}
*pos = x;
++_finish;
return pos;
}
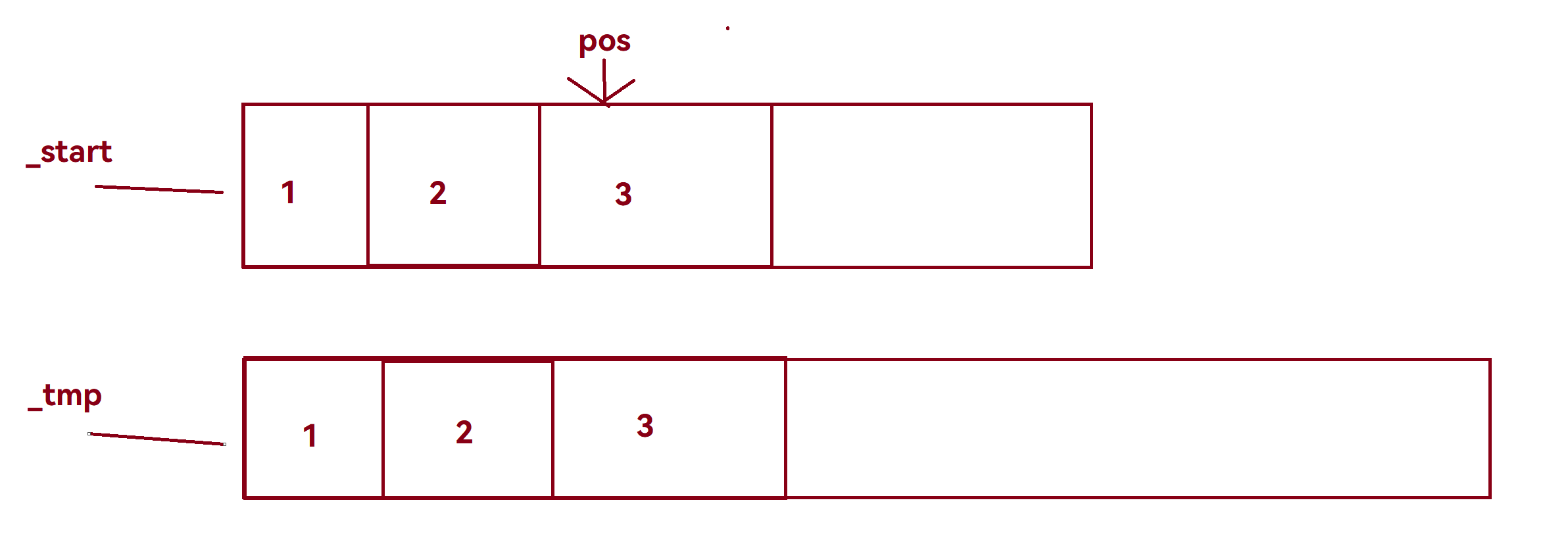
在扩容部分,通过
reserve后,此时的pos指向依然是未交换空间前空间中指向的位置。所以在以上代码中使用size_t len = pos - _start来保存交换空间前pos位置距离_start的距离len,在交换后再通过pos = _start + len;将失效的迭代器重新指向正确。
**推荐:每次使用完进行更新(用返回值接受) | ****insert**使用会返回插入后新的数据的位置
图示:
交换前
交换后
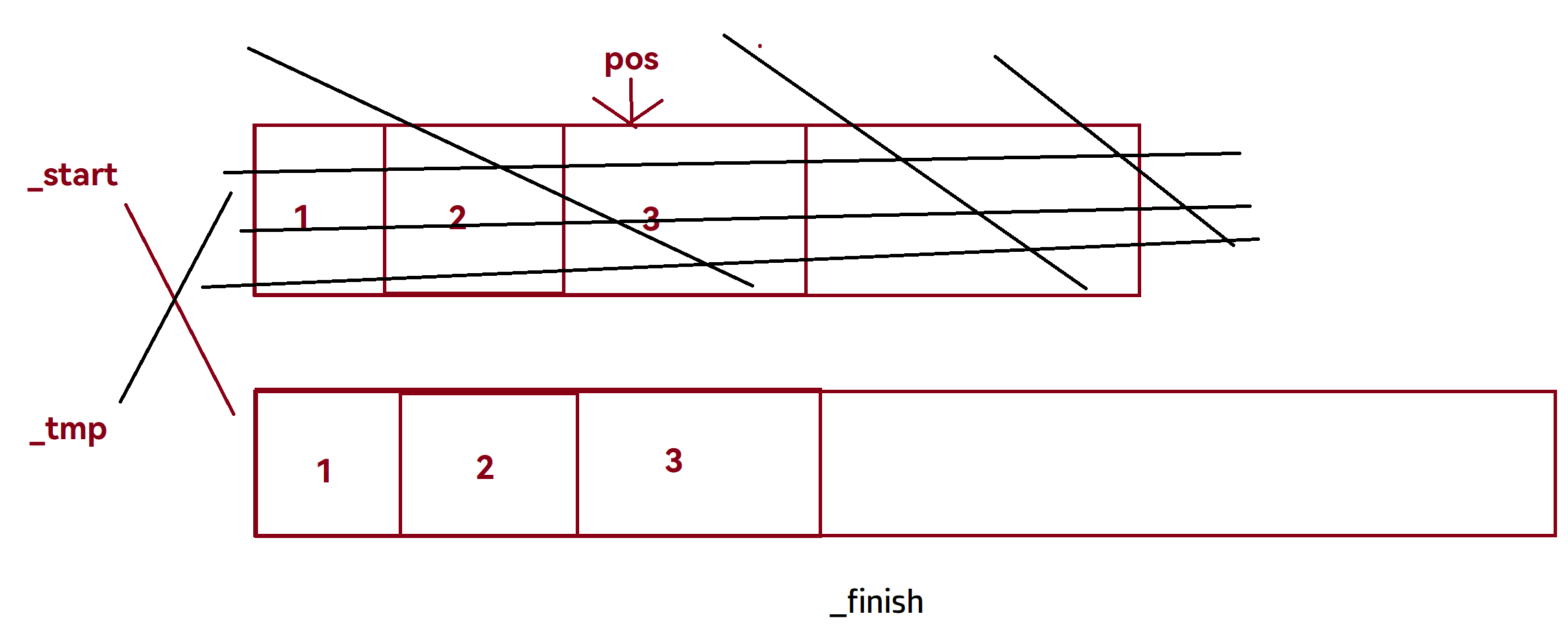
insert修改后失效的迭代器
int main() {
std::vector<int> v = {1, 2, 3, 4, 5};
int x;
std::cin >> x;
auto p = std::find(v.begin(), v.end(), x);
if (p != v.end())
{
// insert以后p就是失效,不要直接访问,要访问就要更新这个失效的迭代器的值
//v.insert(p, 40);
//(*p) *= 10;
// 插入新元素并更新迭代器
p = v.insert(p, 40);
// 修改插入位置之后的元素
(*(p + 1)) *= 10;
}
print_vector(v);
return 0;
}
v.insert(p, 40);后,p指向的依旧是原来空间的p,所以最好使用p = v.insert(p, 40);,在每一次使用可能修改或者转移新空间的成员函数时都对迭代器进行更新,这样就会避免了迭代器的失效。
it迭代器失效
有以下程序:
vector<int> v{1,2,3,4,5,6}; //
auto it = v.begin();
v.assign(100, 8); // 改变容器内容,如果内容数量大于原本数量,会扩容,交换空间,迭代器失效
while(it != v.end())
{
cout<< *it << " " ;
++it;
}
cout<<endl;
// 将有效元素个数增加到100个,多出的位置使用8填充,操作期间底层会扩容
// v.resize(100, 8);
// reserve的作用就是改变扩容大小但不改变有效元素个数,操作期间可能会引起底层容量改变
// v.reserve(100);
// 插入元素期间,可能会引起扩容,而导致原空间被释放
// v.insert(v.begin(), 0);
// v.push_back(8);
// 给vector重新赋值,可能会引起底层容量改变
// v.assign(100, 8)
出错原因:
- 以上操作,都有可能会导致
vector扩容,也就是说vector底层原理旧空间被释放掉,而在打印时,it还使用的是释放之间的旧空间,在对it迭代器操作时,实际操作的是一块已经被释放的空间,而引起代码运行时崩溃。- **解决方式:**在以上操作完成之后,如果想要继续通过迭代器操作
vector中的元素,只需给it重新赋值即可
erase后的问题
void erase(iterator pos)
{
assert(pos >= _start);
assert(pos < _finish);
iterator it = pos + 1;
while (it != end())
{
*(it - 1) = *it;
++it;
}
--_finish;
}
例如删除pos位置的数据:
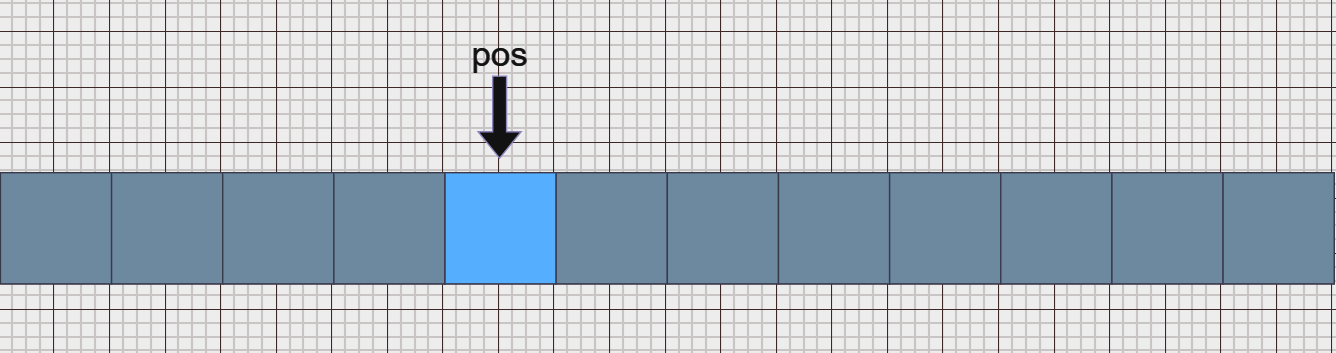
当执行代码逻辑删除,pos后的所有元素向前覆盖,删除后的pos指向依然是之前的位置,只是后面的数据覆盖在了之前pos上数据的位置上:
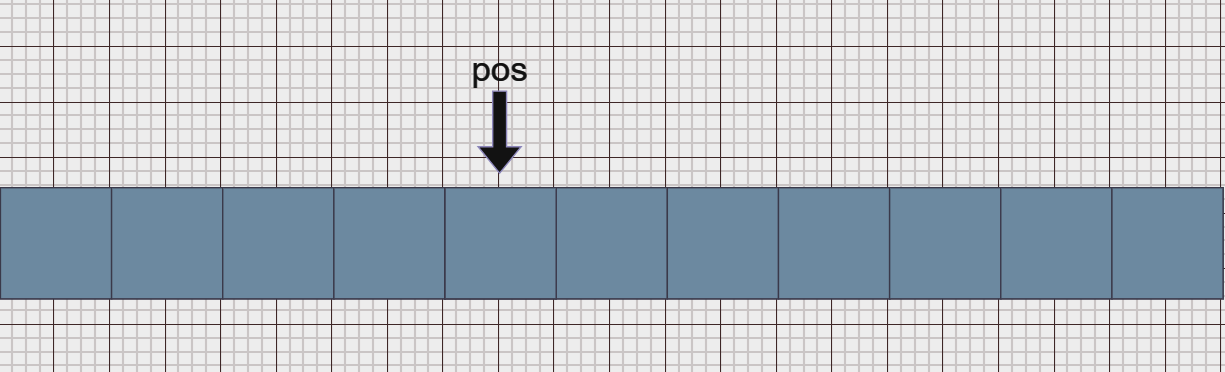
注意:
正是因为删除后的
pos位置指向的是覆盖后的数据,所以在使用erase的时候需要注意注意迭代问题,也就是说在erase过后注意当前pos指向的位置再决定是否迭代pos。如果直接迭代可能造成数据检查的遗失。
示例:
// 删除所有的偶数
auto it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
{
it = v.erase(it);
}
++it;
}
上示代码就是滥用迭代器造成迭代器失效的例子,在每一次使用erase后都会进行迭代,如此就会将覆盖在pos位置上的未迭代的数据给跳过,导致了数据的遍历遗失,迭代器失效。
// 删除所有的偶数
auto it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
{
it = v.erase(it);
}
else
{
++it;
}
}
通过以上修改即可解决问题。
总结:std::vector 中的迭代器失效和避免方法
插入操作
- 当向
std::vector中插入元素时,如果插入操作导致重新分配内存(即容量不够,需要扩展),所有的迭代器都会失效。 - 如果插入操作没有导致重新分配内存,则插入点之后的所有迭代器都会失效
解决方法
在插入元素后,更新所有受影响的迭代器
std::vector<int> vec = {1, 2, 3, 4, 5};
auto it = vec.begin() + 2; // it 指向 vec[2]
vec.insert(it, 10); // 插入后 it 失效,需要重新获取 it
it = vec.begin() + 2; // 更新 it
删除操作及解决方法
当从std::vector中删除元素时,被删除元素之后的所有迭代器都会失效。
std::vector<int> vec = {1, 2, 3, 4, 5};
auto it = vec.begin() + 2; // it 指向 vec[2]
vec.erase(it); // 删除后 it 失效,需要重新获取 it
it = vec.begin() + 2; // 更新 it
在插入元素后,更新所有受影响的迭代器。
一定要注意迭代器的更新!!!

其他问题
依赖名称
模板与依赖名称
在类模板中,某些名称的解析依赖于模板参数。例如,在
vector<T>中,T是一个模板参数,而vector<T>::const_iterator则是依赖于T的名称。这种名称被称为“依赖名称”。
typename关键字
在模板中,编译器在解析依赖名称时可能会产生歧义,特别是在编译器不知道某个依赖名称是类型还是变量的情况下。例如,在
vector<T>::const_iterator这个名称中,如果T是一个模板参数,编译器需要知道const_iterator是一个类型而不是一个静态成员变量。
为了解决这种歧义,C++引入了**typename**关键字,用来显式地告诉编译器某个依赖名称是一个类型。
具体示例分析
假设我们有一个模板类,它使用了std::vector。在这个类中,我们需要声明一个const_iterator类型的变量:
template <typename T>
class MyClass {
public:
void myFunction() {
std::vector<T> v;
typename std::vector<T>::const_iterator it = v.begin(); // 使用typename关键字
// ... 其他代码 ...
}
};
在上面的代码中,如果我们没有使用typename关键字:
std::vector<T>::const_iterator it = v.begin(); // 消除编译器的歧义
编译器会报错,因为在模板的上下文中,编译器无法确定std::vector<T>::const_iterator是一个类型还是一个静态成员变量。为了消除这种歧义,我们需要在类型前面加上typename关键字:
typename std::vector<T>::const_iterator it = v.begin();
这样,编译器就能够正确地解析const_iterator为一个类型。
类外定义成员函数
长的成员函数可以在类外定义,需要重新声明模板参数。
类内定义函数模板
在C++中,类模板允许我们定义一个通用的类,而这个类可以操作任意类型的数据。此外,类模板的成员函数也可以是模板函数。这使得我们可以编写更加灵活和通用的代码。
// 类模板的成员函数,还可以继续是函数模版
template <class InputIterator>
vector(InputIterator first, InputIterator last)
{
while (first != last)
{
push_back(*first);
++first;
}
}
函数模板的应用
很多时候会使用一种容器来初始化另一种容器,以此来弥补该种容器在性能上的问题,例如,将list数据用来初始化vector:
//template <typename Container> void print_container(const Container& container)
//是一个函数模板,用于打印任何容器的内容。
std::list<int> myList = {10, 20, 30, 40, 50};
print_container(myList); // 输出:10 20 30 40 50
// 使用 std::list 的迭代器范围初始化 MyVector
MyVector<int> myVector(myList.begin(), myList.end());
myVector.print(); // 输出:10 20 30 40 50
// 创建一个 std::vector 并初始化
std::vector<int> myVec = {1, 2, 3, 4, 5};
print_container(myVec); // 输出:1 2 3 4 5
// 使用 std::vector 的迭代器范围初始化 MyVector
MyVector<int> anotherVector(myVec.begin(), myVec.end());
anotherVector.print(); // 输出:1 2 3 4 5
使用的注意事项
注意调用的优先级匹配机制:
// 类模板的成员函数,还可以继续是函数模版
template <class InputIterator>
vector(InputIterator first, InputIterator last)
{
while (first != last)
{
push_back(*first);
++first;
}
}
vector(size_t n, const T& val = T())
{
reserve(n);
for (size_t i = 0; i < n; i++)
{
push_back(val);
}
}
vector<int> v2(v1.begin(), v1.begin() + 3);
vector<int> v3(lt.begin(), lt.end());
vector<string> v4(10, "1111111");
vector<int> v5(10);
vector<int> v6(10, 1);
vector<int> v7(10, 1);
当使用以上函数模板来构造对象的时候,当遇到vector<int> v6(10, 1);或vector<int> v7(10, 1);这种构造时编译器会对进入的模板函数产生异常,会优先进入vector(InputIterator first, InputIterator last),当解引用int类型的时候程序就会异常。
所以在写函数模板的是需要注意注意构造时的匹配机制,应该写的更准确一些,这样才能避免被不属于该类型构造的构造函数模板调用:
vector(int n, const T& val = T())
{
reserve(n);
for (int i = 0; i < n; i++)
{
push_back(val);
}
}
当有一个更明确的构造函数的时候,当编译vector<int> v6(10, 1);的时候就会进入该函数模板实例化的函数进行构造,正常运行。

使用memcpy拷贝问题
问题引出
以下是push_back和resereve的逻辑代码:
void push_back(const T& x)
{
// 扩容
if (_finish == _end_of_storage)
{
reserve(capacity() == 0 ? 4 : capacity() * 2);
}
*_finish = x;
++_finish;
}
void reserve(size_t n)
{
if (n > capacity())
{
size_t old_size = size();
T* tmp = new T[n];
memcpy(tmp, _start, old_size * sizeof(T));
delete[] _start;
_start = tmp;
_finish = tmp + old_size;
_end_of_storage = tmp + n;
}
}
执行以下测试代码:
void test_vector()
{
vector<string> v;
v.push_back("11111111111111111111");
v.push_back("11111111111111111111");
v.push_back("11111111111111111111");
v.push_back("11111111111111111111");
print_container(v);
v.push_back("11111111111111111111");
print_container(v);
}
程序崩溃:
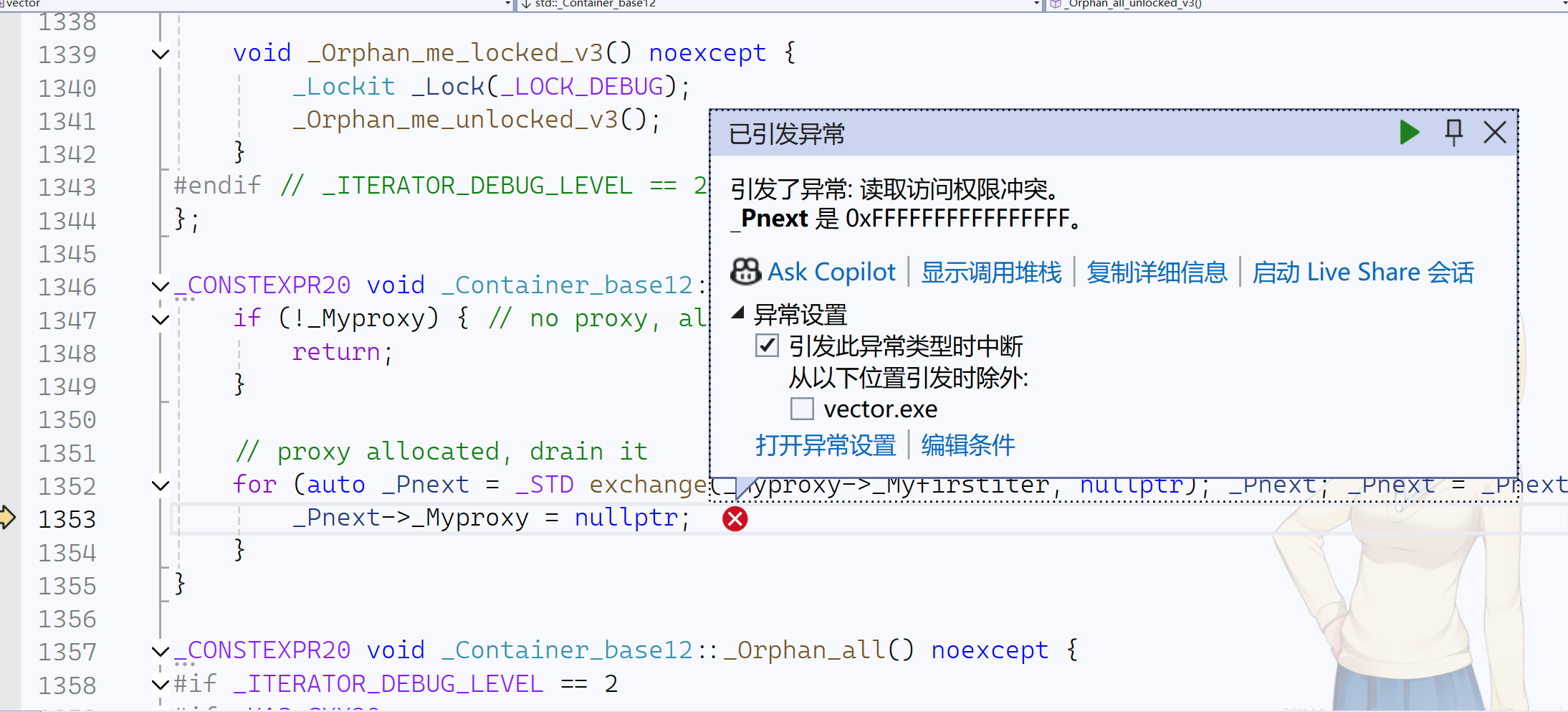
调试分析
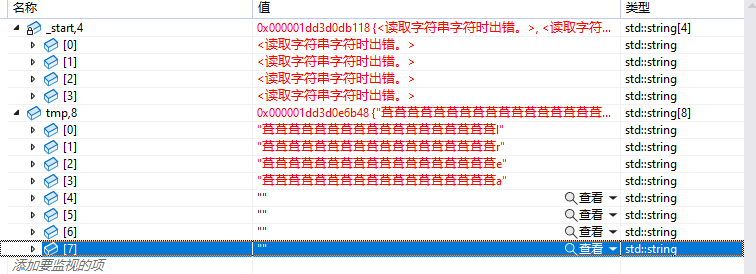
前四个string的push_back正常执行,当调试到第五个string时:
- 此时
tmp空间已经申请成功
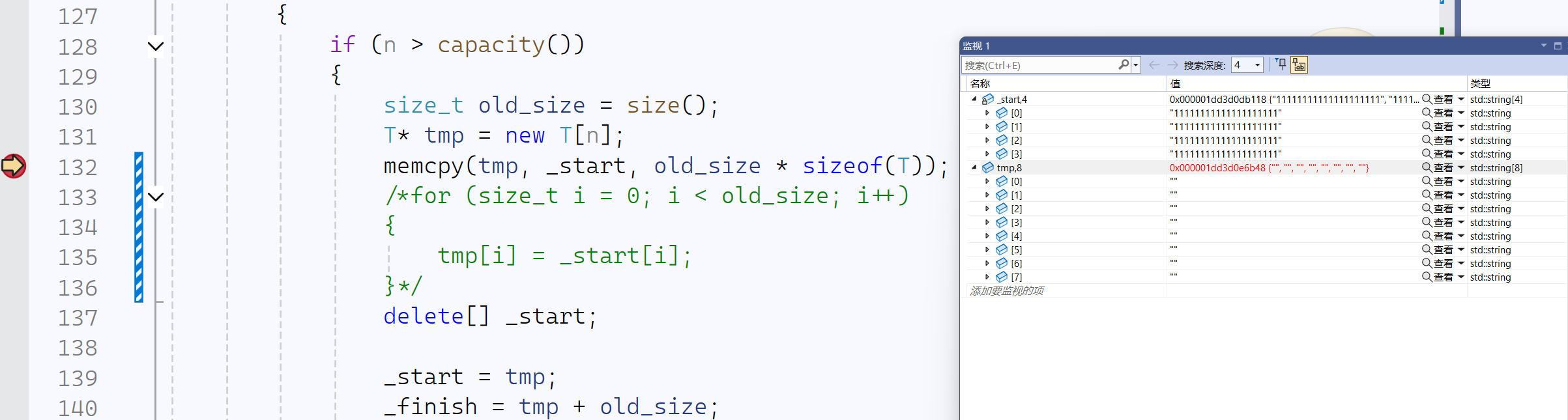
- 当执行完delete后,发生异常
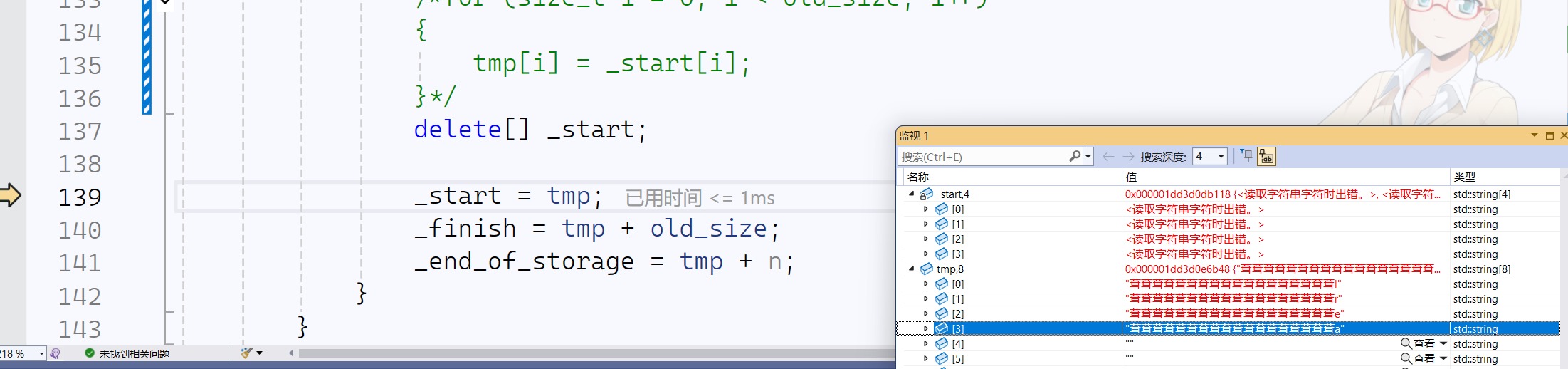
当
_start被delete释放空间后,监视到tmp空间也被释放,由此可得,_start与tmp可能指向同一块空间
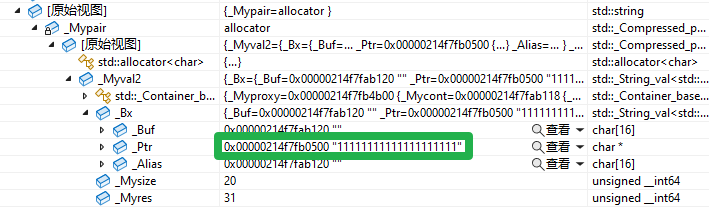
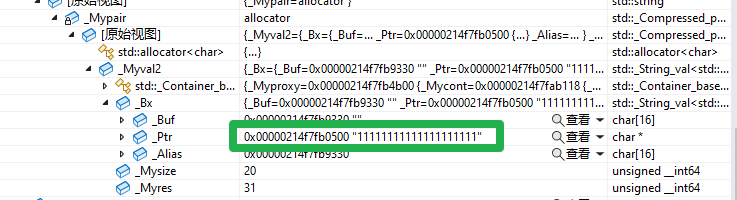
有原始视图_Ptr地址观察可得,在memcpy时,执行的是浅拷贝,会直接令tmp指向_start的那块空间,所以才会导致执行delete[],调用析构函数,将vector中存放的string数据全部析构,程序崩溃,_start指向的空间被销毁,tmp也就没有数据了。
解决措施
该问题由memcpy的浅拷贝引出,所以需要手动进行深拷贝来解决空间释放问题:
void reserve(size_t n)
{
if (n > capacity())
{
size_t old_size = size();
T* tmp = new T[n];
// 避免memcpy的浅拷贝问题
for (size_t i = 0; i < old_size; i++)
{
tmp[i] = _start[i];
}
delete[] _start;
_start = tmp;
_finish = tmp + old_size;
_end_of_storage = tmp + n;
}
}

当使用深拷贝进行拷贝数据后,就不会出问题了
注意:在涉及空间扩容时用深拷贝进行,避免空间的重复指向。(深拷贝的数据类型都不行:vector<string>,vector<vector<string>>…)

理解使用 vector 构造动态二维数组
什么是二维数组?
一个二维数组可以被看作是一个数组的数组。例如,一个 3x3 的二维数组可以表示为:
1 2 3
4 5 6
7 8 9
使用 std::vector 构造动态二维数组
std::vector 是C++标准模板库(STL)中的一个动态数组类模板。与静态数组不同,std::vector 可以在运行时动态调整其大小。我们可以使用 std::vector 来构造一个动态的二维数组。
构造方法
#include <iostream>
#include <vector>
int main() {
int m = 3; // 行数
int n = 4; // 列数
// 创建一个 m 行 n 列的二维数组
std::vector<std::vector<int>> matrix(m, std::vector<int>(n));
// 初始化数组
int value = 1;
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
matrix[i][j] = value++;
}
}
// 打印数组
for (const auto& row : matrix) {
for (int elem : row) {
std::cout << elem << " ";
}
std::cout << std::endl;
}
return 0;
}
解析
定义二维数组
std::vector<std::vector<int>> matrix(m, std::vector<int>(n));
std::vector<int>(n)创建了一个包含n个int元素的向量。std::vector<std::vector<int>> matrix(m, ...)创建了一个包含m个向量的向量,即一个m x n的二维数组。
初始化二维数组
int value = 1;
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
matrix[i][j] = value++;
}
}
使用双重循环遍历二维数组,并将每个元素初始化为一个递增的值。
打印二维数组
for (const auto& row : matrix) {
for (int elem : row) {
std::cout << elem << " ";
}
std::cout << std::endl;
}
使用范围 for 循环遍历并打印二维数组的内容。
动态调整大小
使用 std::vector 构造的二维数组可以在运行时动态调整大小。我们可以使用 resize 方法调整二维数组的行和列。例如,增加行和列:
// 增加行
matrix.resize(new_m);
// 增加列
for (auto& row : matrix) {
row.resize(new_n);
}
范围for中row就是一维数组,然后通过改变一维数组中每一个对应的二维空间的大小来改变列的大小。
使用
std::vector构造动态二维数组为我们提供了极大的灵活性。与静态数组不同,std::vector可以在运行时动态调整大小,使其更适合处理动态数据集。