请阅读【嵌入式及芯片开发学必备专栏】
文章目录
- NVIDIA H100 和 H200 的算力
- NVIDIA H100 芯片的算力
- NVIDIA H100 算力参数
- NVIDIA H100 举例
- NVIDIA H200 芯片的算力
- NVIDIA H200 算力参数
- H200 的内存和带宽提升
- H200 推理吞吐量提高
- H200 性能提升
- NVIDIA H200 举例
- Summary

NVIDIA H100 和 H200 的算力

NVIDIA H100 芯片的算力
英伟达 H100 是基于 Hopper 架构的新一代数据中心 GPU,其算力在多个方面显著提升。
NVIDIA H100 算力参数
- 单精度浮点性能 (FP32):超过 60 TFLOPS。
- 半精度浮点性能 (FP16):超过 120 TFLOPS。
- 混合精度 (Tensor Core):超过 600 TFLOPS。
- INT8 性能:超过 1200 TOPS(每秒万亿次操作)。
- 内存带宽:使用 HBM3 内存,带宽超过 3 TB/s。
NVIDIA H100 举例
- 深度学习模型训练:
- GPT-3:假设在训练 GPT-3 这样的复杂自然语言处理模型,每一步的计算量巨大。使用 H100,可以显著缩短训练时间,并提高模型的精度。
- ResNet-50:在图像分类任务中,使用 H100 训练 ResNet-50,可以在短时间内完成数百万张图像的数据处理。
NVIDIA H200 芯片的算力
英伟达 H200 是 H100 的升级版本,基于同样的 Hopper 架构,但在性能和效率上进一步提升。
NVIDIA H200 算力参数
- 单精度浮点性能 (FP32):高达 80 TFLOPS。
- 半精度浮点性能 (FP16):超过 160 TFLOPS。
- 混合精度 (Tensor Core):超过 800 TFLOPS。
- INT8 性能:超过 1600 TOPS。
- 内存带宽:使用优化的 HBM3 内存,带宽超过 4 TB/s。
H200 的内存和带宽提升
与 H100 相比,H200 的内存更大(141GB),带宽更高(4.8 TB/s),分别约为 H100 的 1.8 倍和 1.4 倍。这有助于 H200 比 H100 容纳更大的数据量,从而减少不断从较慢的外部内存中获取数据的需要。更高的带宽允许内存和 GPU 之间更快地传输数据。
H200 推理吞吐量提高
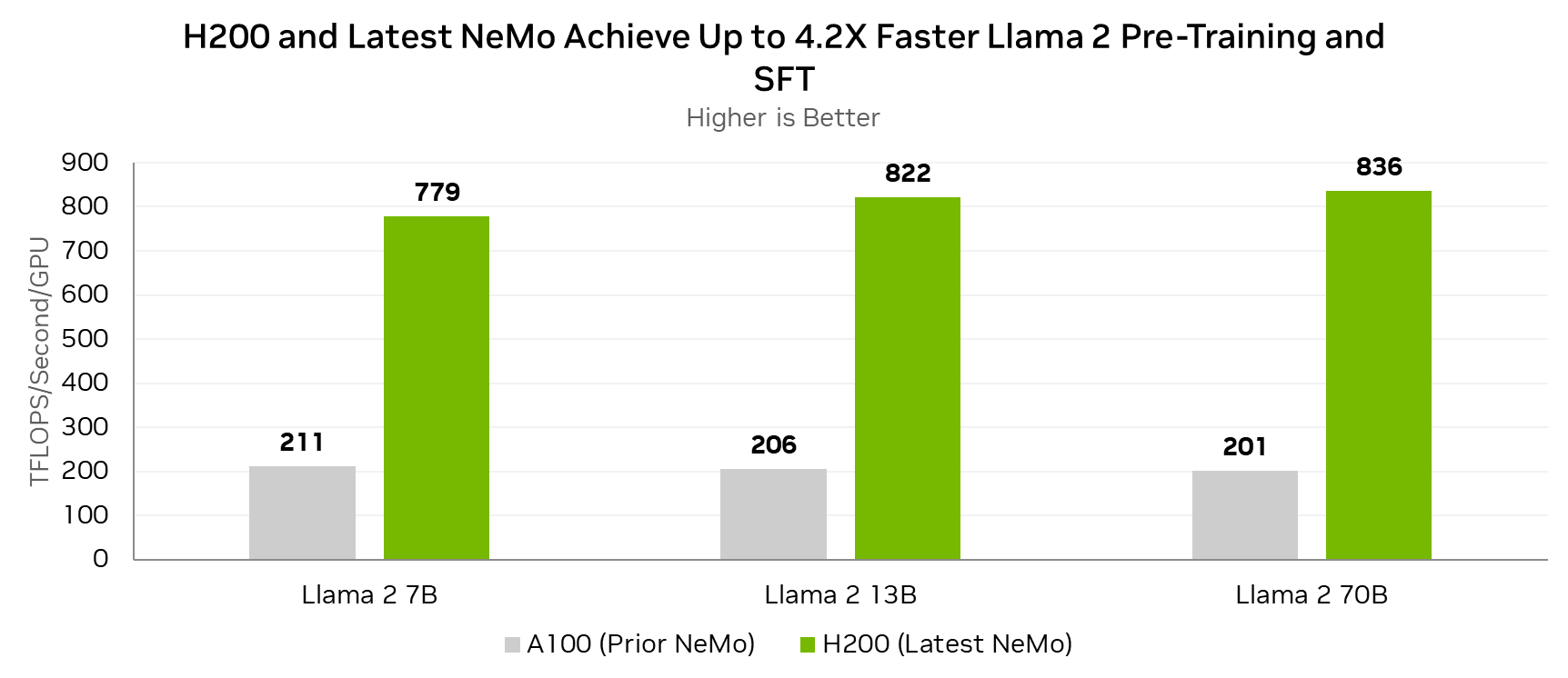
由于没有内存和通信瓶颈,H200 可以将更多的处理能力用于计算,从而加快推理速度。Llama 测试的基准测试证明了这一优势,即使在与 H100 相同的功率水平 (700W TDP) 下,H200 也能实现高达 28% 的提升。
有了这些,H200 可以处理大型任务,而无需张量并行(拆分数据)或管道并行(分阶段处理)等复杂技术。
H200 性能提升
基准测试显示,当功耗配置为 1000W 时,H200 在 Llama 测试中的表现比 H100 提高了 45%。
这些比较凸显了 H200 GPU 相对于 H100 所取得的技术进步和性能增强,特别是在通过更大的内存容量、更高的内存带宽和改进的热管理来处理像 Llama 2 70B 这样的生成式 AI 推理工作负载的需求方面。
NVIDIA H200 举例
- 大规模语言模型训练:
- GPT-4:假设在训练 GPT-4 这样更大规模的语言模型,H200 提供的更高算力可以极大地缩短模型训练时间,同时提升模型的规模和复杂度。
- BERT:在自然语言理解任务中,使用 H200 训练 BERT 模型,可以处理更大规模的数据集,并提高模型的准确性和效率。
Summary
英伟达 H100 和 H200 芯片在计算性能方面都表现出色,尤其在深度学习训练和高性能计算中具有显著优势。通过以下几个例子可以更好地理解它们的应用场景:
- 深度学习模型训练:如 GPT-3、GPT-4 和 BERT 等大型模型。
- 图像分类:如 ResNet-50,在图像识别与分类任务中展示出卓越的算力。
- 科学计算:如气候模拟、基因组学分析等,H100 和 H200 都可以显著加快计算速度,提升研究效率。
- 金融建模:在金融风险评估和建模中,H100 和 H200 可以处理复杂的数据,进行快速的计算和分析。
无论是在研究机构还是在企业应用中,英伟达 H100 和 H200 都是加速计算任务、提升工作效率的重要工具。