说明
该项目为小视科技的静默活体检测项目。开源地址在 https://github.com/minivision-ai/Silent-Face-Anti-Spoofing。
由于不是论文衍生项目,所以只有一个公众号文章的介绍:https://mp.weixin.qq.com/s/IoWxF5cbi32Gya1O25DhRQ
方案详情
该方案是一个静默单帧RGB活体识别方案,基于成像介质种类的不同,小视科技团队将样本分为真脸、2D 成像(打印照片,电子屏幕)以及 3D 人脸模具三类,根据上述的准则整理和收集训练数据。
根据公众号的介绍,主要网络就是用MoboileFaceNet 剪枝得到的。在精度没有明显损失的情况下,模型前向运行的速度提升了 40%。
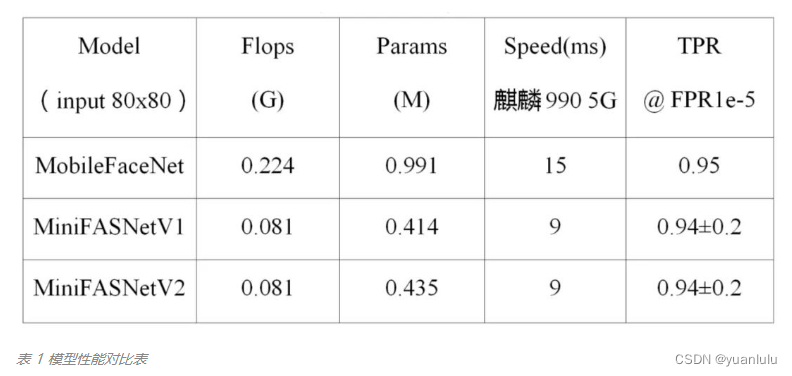
网络结构上增加了SE(Squeeze-and-Excitation)的注意力模块, 并且引入了基于傅里叶频谱图进行辅助网络监督。因为它们发现,真脸和假脸的傅里叶频谱存在差异,假脸的高频信息分布比较单一,仅沿着水平和垂直方向延伸,而真脸的高频信息从图像的中心向外呈发散状,如下图所示。

输入图片的尺寸为 3x80x80,从主干网络中提取尺寸为 128x10x10 特征图,经过 FTGenerator 分支生成 1x10x10 的预测频谱图 F_P 。通过傅里叶变换,将输入图片转化成频谱图,再进行归一化,最后 resize 成 1x10x10 尺寸得到 F_G ,使用 L2 Loss 计算F_P和F_G征图之间差异。改造后的网络结构如下。
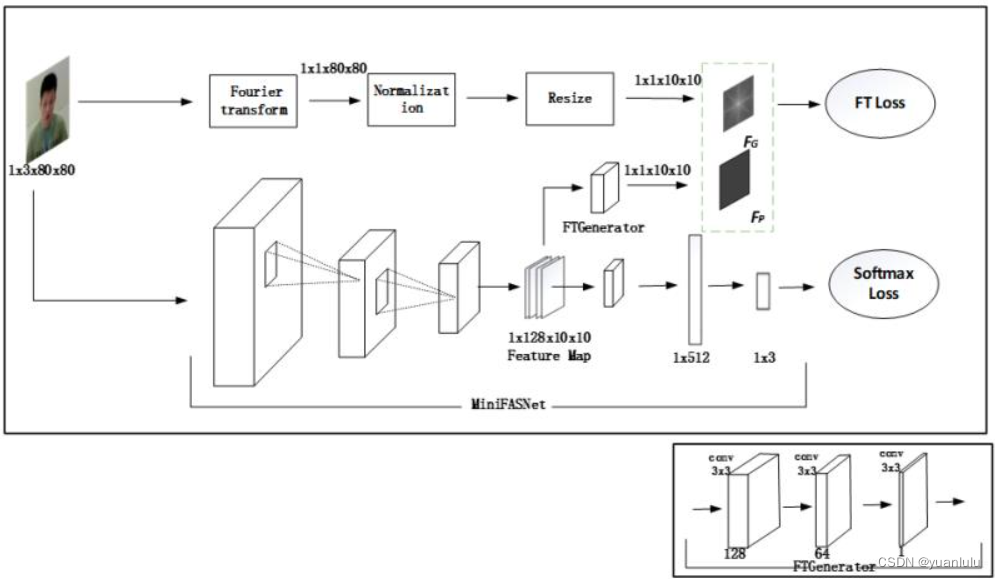
这样网络的前半部分就强制学习提取傅里叶拼频谱的能力。推理的时候, FTGenerator 分支被删除,只保留SoftMaxLoss的那个分支。
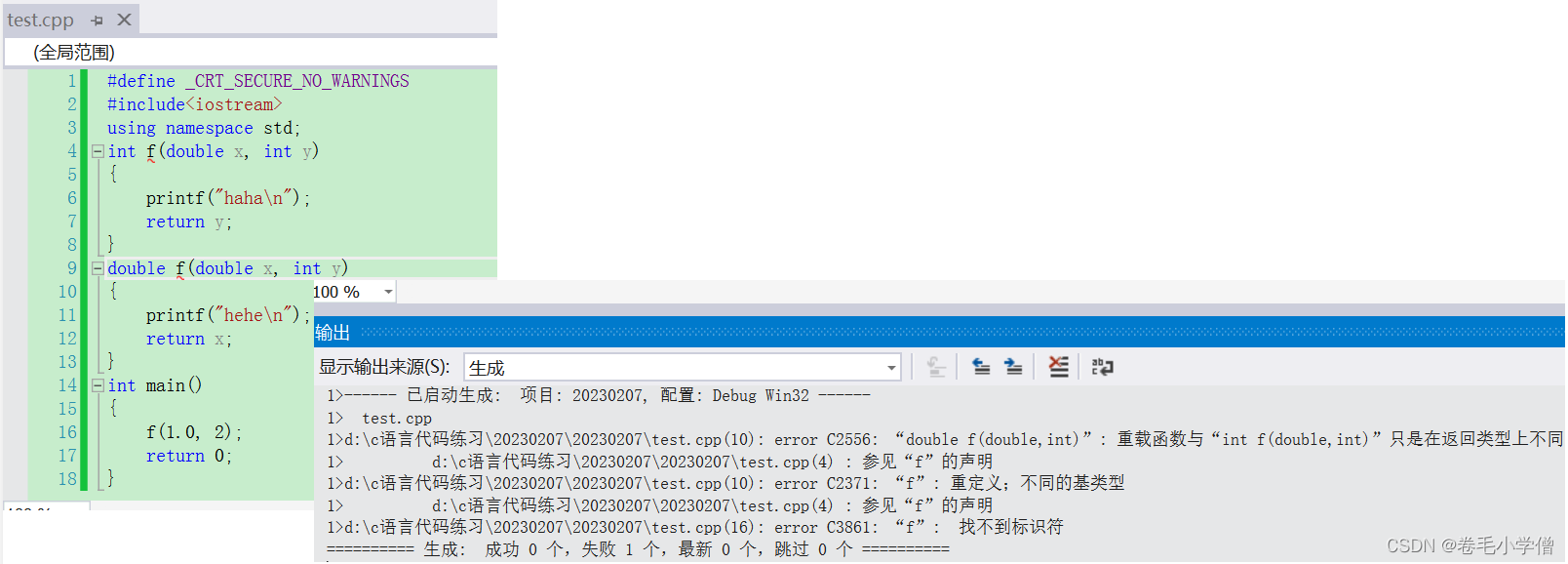
该新项目提供了两个网络:MiniFASNetV1 和 MiniFASNetV2。这两个网络的迭代次数不一样,网络结构也有差异(一个有SE模块一个没有,其它差异我也没仔细看),最终将两个模块的检测结果合并起来判别活体。(我猜这俩网络对不同的攻击类型有不同的表现,所以才会用两个。或者一个有傅里叶频谱监督,一个没有)。
小视科技开源的模型精度稍低,它们还有闭源的模型,精度更高。
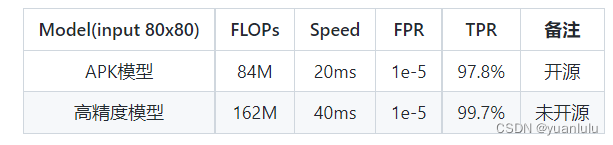
最后
按照官方的说明,该方案是一个集成了俩小模型的方案,就是不知道俩小模型的侧重点。总的来说,开源这么一个可用的RGB单帧模型,很值得欣赏。






![[Flink] 容错机制与状态一致性机制](https://img-blog.csdnimg.cn/4b519fa17c0c41c99237898f1c970725.png)