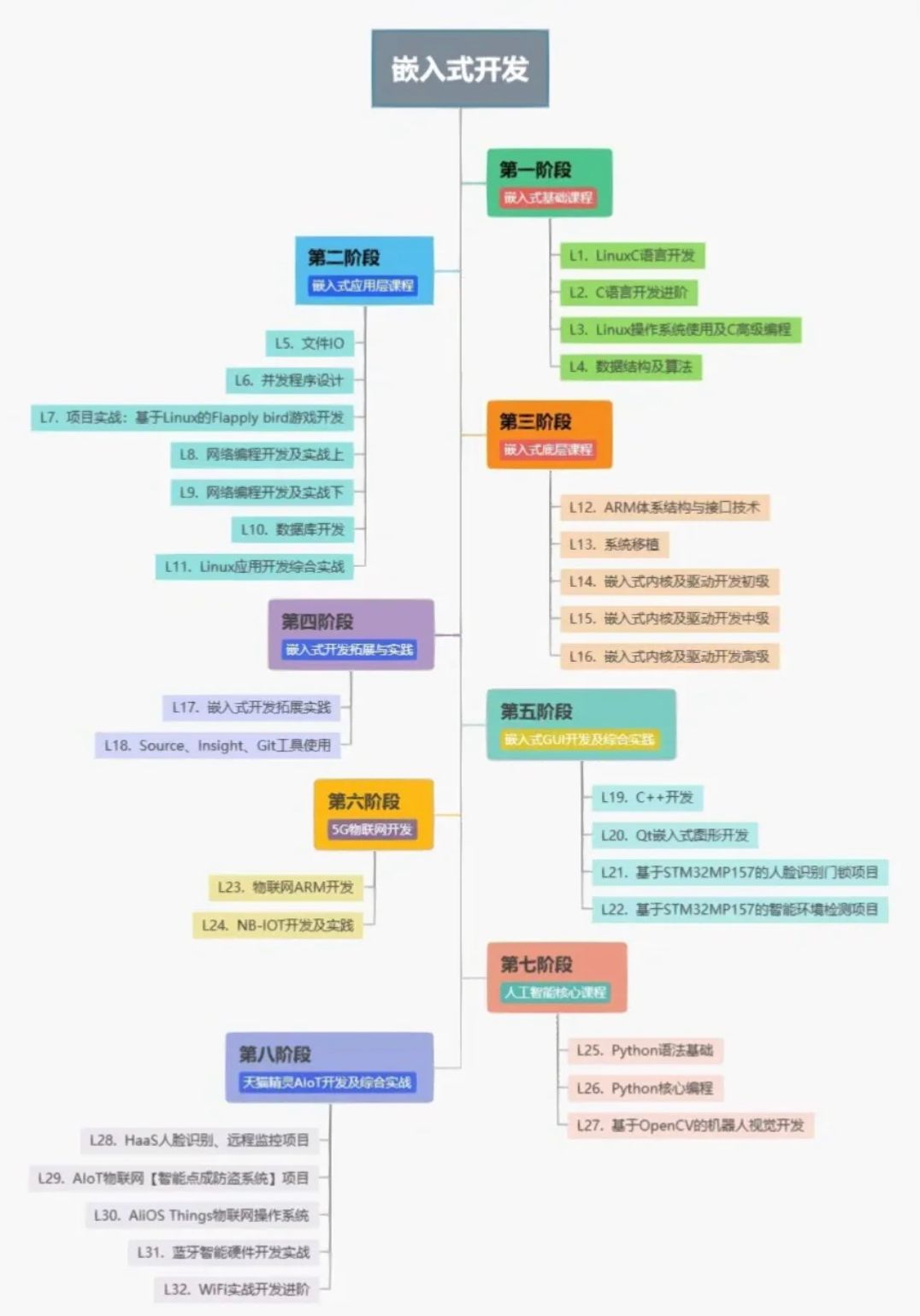
1.大批量插入数据指令load
当需要大批量插入数据时,insert的效率比较低,此时可以使用load命令
使用方法如下:
(1)客户端连接服务端时,加上参数--local-infile
mysql --local-infile -u root -p
(2)设置全局参数local infile为1,开启从本地加载文件导入数据的开关
set global local_infile=1;查看一个参数是否开启的方法是select @@参数名,返回0就是没开启,返回1就是开启了

(3)执行load指令,将准备好的数据,加载到表结构中
load data local infile '数据文件的路径' into table 表名 fields terminated by ',' lines terminated by '\n';
#fields terminated by ',’表示数据不同字段以英文逗号分隔
#lines terminated by '\n';表述不同行的数据以回车换行分隔插入数据时,要尽量让数据按主键顺序插入(如下图),主键乱序插入影响性能

2.设计主键原则
(1)尽量降低主键的长度。
(2)插入数据时,尽量选择顺序插入
(3)选择使用AUTOINCREMENT自增主键。尽量不要使用UUID做主键或者是其他自然主键,如身份证号。
(4)尽量避免对主键的修改。
3.order by排序查询优化
使用order by进行排序有2种方式:
(1)using filesort:没使用索引进行排序
(2)using index:使用了索引进行排序,效率更高
查看order by语句是否使用了索引,只需要使用explain即可。如下图,在最后一栏的extra中有标注:

3.1多字段排序问题
当order by后有多个字段时,它会先根据第一个字段进行排序,在第一个字段数据相同时,才会再排序第二个字段,所以order by后字段的书写顺序很重要。
索引本身就是一种排序,所以当order by搜索的字段有索引时,可以直接使用索引得出结果,大大提高了效率(前提是使用的覆盖索引)。如下图:

但如果order by后接多个字段进行排序时,就不能简单的使用单列索引了,而是要使用联合索引。这里必须要提一下联合索引的结构。如下图所示,联合索引是先根据最左边的字段建立索引,在左边字段索引相同的情况下才会根据下一个字段进行排序:

这样就会order by排序多字段非常相似,也就直接利用联合索引完成多字段排序,如下图:

当然,如果order by后字段的书写顺序和创建联合索引时字段的书写顺序不一致,就无法完全使用联合索引了,如下图,虽然也是用了联合索引,但最关键的排序过程并不是利用索引得到的:

3.2索引自身的升序降序
order by在搜索时可以根据asc、desc分别得到升序、降序的结果,而索引本身也有升序、降序的区别。
在默认情况下,索引是升序的,但如果用order by来降序排序某个字段也不是不可以使用索引,因为索引的叶子结点是一个双向链表,所以只需要反向排序即可,如下图,出现了backward index scan,代表索引进行了反向扫描:

不过在使用联合索引的时候就需要注意了,像上图这样两个字段都是降序排序那尚且可以使用联合索引反向扫描,但如果一个升序一个降序就不可以了,如下图:

不过,对于这种情况也并不是没有办法。
使用命令查看数据库内索引时,可以看到其顺序标识为A,代表升序(如果是D,则代表降序):

在创建索引时,是可以选择升序还是降序的,在创建联合索引时也可以分别设置字段是不同的排序方式:如下图
![]()

这样的联合索引就可以应对前述的问题了。
4.group by分组查询优化
group by分组查询也可以使用索引,如下图:

图中使用的是联合索引,受限于联合索引的最左前缀法则,group by必须按照联合索引的顺序进行分组
(1)下图使用age进行分组,由于缺少了最左边的profession字段,所以并不能完全使用联合索引

(2)同时按照profession与age字段分组,就可以使用索引了
 (3)profession字段出现在where后,也可以满足最左前缀法则
(3)profession字段出现在where后,也可以满足最左前缀法则

select语句里where执行在group by之前

5.count的几种使用方式效率对比