GPU虚拟化到池化技术深度分析
在大型模型的推动下,GPU算力的需求日益增长。然而,企业常常受限于有限的GPU卡资源,即使采用虚拟化技术,也难以充分利用或持续使用这些资源。为解决GPU算力资源的不均衡问题,同时推动国产化替代,提升GPU资源的利用效率,GPU算力池化的需求刻不容缓。
本文深入探讨了GPU设备虚拟化的多种路径,分享了GPU虚拟化和共享方案,以及如何实现GPU算力池化的云原生技术。让我们一起探索如何优化GPU资源,满足不断增长的算力需求。
AI智能化应用,如人脸识别、语音识别、文本识别等,已广泛渗透各行各业。这些被称为判定式AI的应用,通常与特定业务场景紧密结合。在使用GPU卡时,各应用通常独立运行,未充分利用业务间的GPU共享能力。
然而,通过vGPU虚拟化切分技术,一张物理GPU卡可虚拟出多张vGPU,实现多个判定式AI应用并行运行。这不仅提高了GPU资源的利用率,还为各行业带来了更高效、智能的解决方案。
随着大型模型的盛行,对GPU算力的需求急剧上升。然而,现实中企业常常受限于稀缺的GPU卡资源,难以满足多元化的业务需求。即使采用虚拟化技术,也难以实现GPU卡资源的充分和持续利用,导致宝贵的GPU资源无法发挥最大效能。
一、从GPU虚拟化需求到池化需求
智能化应用数量的增长对GPU算力资源的需求越来越多。NVIDIA虽然提供了GPU虚拟化和多GPU实例切分方案等,依然无法满足自由定义虚拟GPU和整个企业GPU资源的共享复用需求。
TensorFlow、Pytorch等智能化应用框架开发的应用往往会独占一张GPU整卡(AntMan框架是为共享的形式设计的),从而使GPU卡短缺,另一方面,大部分应用却只使用卡的一小部分资源,例如身份证识别、票据识别、语音识别、投研分析等推理场景,这些场景GPU卡的利用率都比较低,没有业务请求时利用率甚至是0%,有算力却受限于卡的有限数量。
推理场景一卡独享,既浪费又矛盾。因此,算力切分已成为众多场景的刚需。然而,受限于组织架构等因素,各团队自行采购GPU,导致算力资源孤岛化、分布不均:有的团队GPU空闲,有的却无卡可用。
为解决GPU算力资源分配不均等问题,我们致力于推动国产化替代,满足在线与离线、业务高低峰、训练推理以及开发测试生产环境的资源需求差异。通过实现统一管理和调度复用,提升GPU资源的利用率。我们期待实现GPU资源的切分、聚合、超分、远程调用和应用热迁移等能力,以应对GPU算力池化的紧迫需求。
二、GPU设备虚拟化路线
GPU设备虚拟化有几种可行方案。
首先,我们探讨PCIe直通模式(也被称为pGPU的PCIe Pass-through技术)。这种模式将物理主机的GPU卡直接映射到虚拟机上。然而,由于其独占性,无法解决多应用共享一张GPU卡的问题,因此其实际价值有限。
第二是采用SR-IOV技术,允许一个PCIe设备在多个虚拟机之间共享,同时保持较高性能。
通过SR-IOV在物理GPU设备上创建多个虚拟 vGPU来实现的,每个虚拟vGPU可以被分配给一个虚拟机,让虚拟机直接访问和控制这些虚拟功能,从而实现高效的I/O虚拟化。NVIDIA早期的vGPU就是这样的实现,不过NVIDIA vGPU需要额外的license,额外增加了成本。SR-IOV虽然实现了1:N的能力,但其灵活性比较差,难以更细粒度的分割和调度。
MPT(Mediated Pass-Through),一种创新的PCIe设备虚拟化解决方案,融合了1:N的灵活性、卓越的性能和完整的功能。在内核态实现device-model的逻辑,尽管厂商可能不会公开硬件编程接口,但MPT的采用仍可能导致对特定厂商的依赖。
第四用的最多的模式是API转发模式。
根据AI应用的调用层次(如下图),API转发有多个层次,包括:
- CUDA API转发(图中①)
- GPU Driver API转发(图中②)
- 设备硬件层API转发(图中③)
设备硬件层API常被束之高阁,然而CUDA API转发模式(即用户态)与GPU卡驱动Driver API转发模式(即内核态)却大行其道。这两种模式分别通过截获CUDA请求和驱动层请求实现转发,为业界广泛采纳。
AI开发框架常与GPU卡紧密结合,如华为的CANN、海光的DTK,以及英伟达的TensorFlow和Pytorch等。在AI应用中,这些框架可进行有效转发,极大提升AI应用迁移的便捷性。
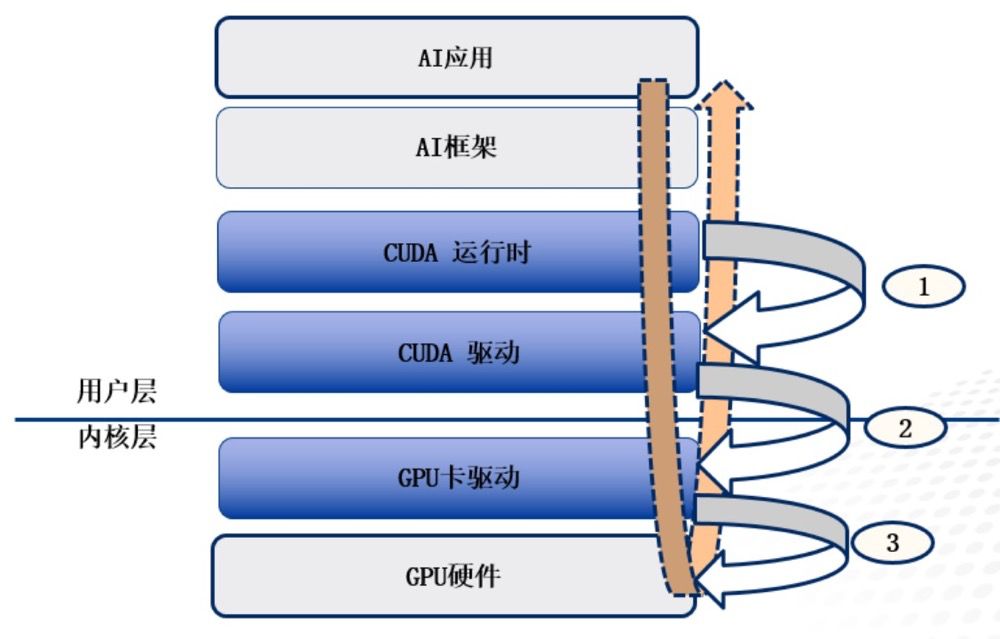
AI应用调用层次
三、GPU虚拟化和共享方案
掌握GPU设备虚拟化技巧,深度探讨其实现方式。GPU虚拟化和共享拥有丰富方案,英伟达官方推出vGPU、MIG、MPS等解决方案,同时也存在非官方的vCUDA、rCUDA、内核劫持等策略。
四、NVIDIA VGPU方案
NVIDIA vGPU,一款由NVIDIA提供的虚拟化解决方案,以其卓越的可靠性和安全性著称。然而,它无法支持容器,只能虚拟化有限数量的vGPU,灵活性受限。此外,资源比例无法动态调整,存在共享损耗,且不支持定制开发,需支付额外许可证费用。
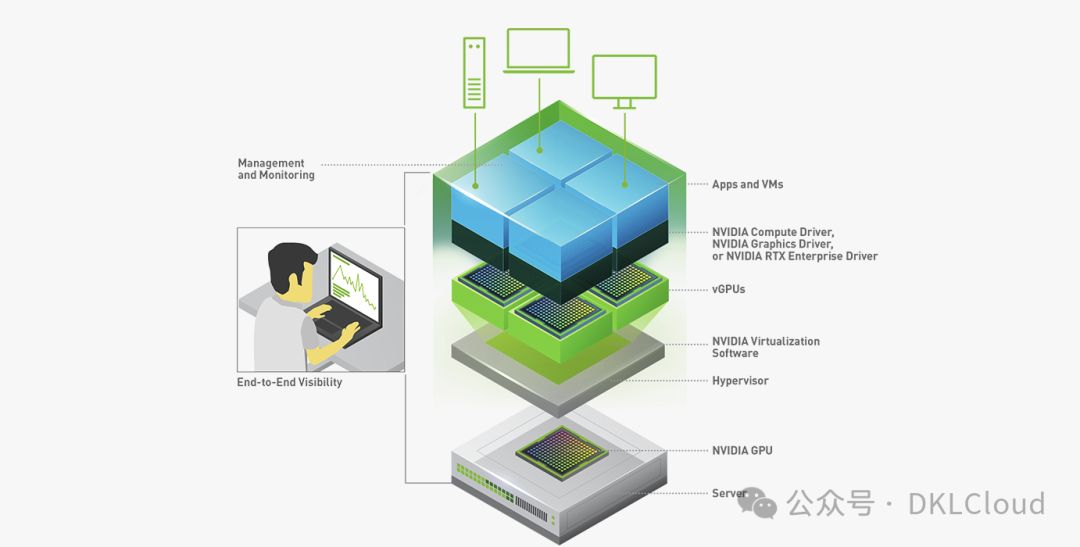
vGPU 原理揭秘:
在NVIDIA的虚拟GPU驱动的虚拟化环境中,vGPU软件与Hypervisor携手,共同安装在虚拟化层上。这为提升效率和性能提供了强大的支持。
此款软件能创造虚拟GPU,让每个虚拟机(VM)都能与服务器上的物理GPU共享资源。对于需求极高的工作流程,单VM可利用多个物理GPU。
我们的软件内含适用于各类VM的显卡或计算驱动。由于原本由CPU完成的任务被分配到GPU,用户将体验到更卓越的性能。虚拟化和云环境能够支持对工程和创意应用、以及计算密集型工作负载(如AI和数据科学)的严格要求。
NVIDIA的虚拟GPU(vGPU)软件,为各类任务提供卓越的图形处理性能,从图像丰富的虚拟工作站到数据科学和AI应用。它使IT部门能够充分利用虚拟化带来的管理和安全优势,同时满足现代工作负载对NVIDIA GPU的强大需求。vGPU软件安装在云或企业数据中心服务器的物理GPU上,可创建可在多个虚拟机间共享的虚拟GPU。这些虚拟机可以随时随地通过任何设备访问。借助NVIDIA vGPU,您可以轻松实现高性能计算与灵活访问的完美结合。
优势:

- 利用实时迁移GPU加速的虚拟机,您将获得无缝持续运行和前瞻性管理能力,确保用户体验不受干扰,数据安全无虞。
- 借助统一的虚拟GPU加速设施,混合VDI和计算工作负载得以高效运行,从而显著提升数据中心资源的使用效率。
- 通过拆分和共享GPU资源,或为单个VM分配多个GPU,我们能够支持需求极高的工作负载,实现性能的最大化利用。
- 借助灵活的调度选项,实现几乎与非虚拟化环境无异的性能。
支持虚拟化的GPU 卡介绍:

五、NVIDIA MIG 虚拟化 多实例 GPU
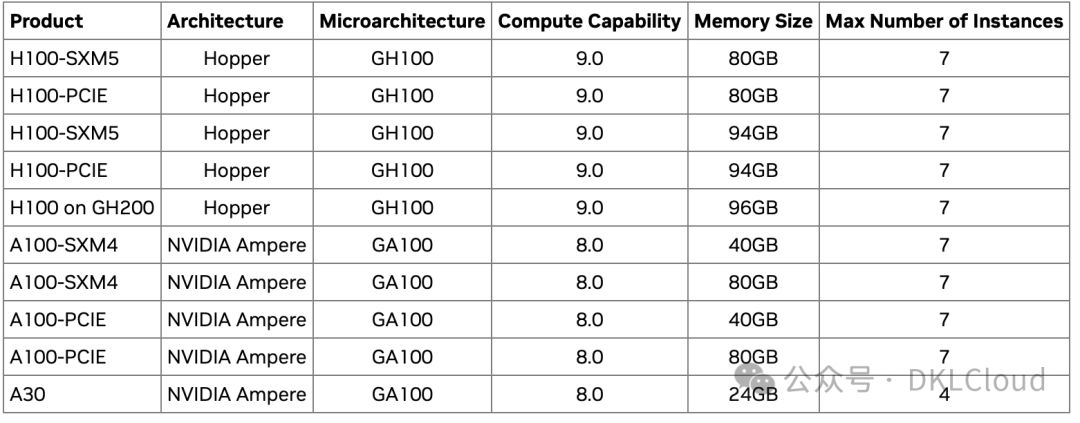
MIG,一种先进的多实例GPU解决方案,专为Linux操作系统量身定制。它需要CUDA11/R450或更高版本才能完美运行。MIG与A100、H100等高端显卡完美匹配,同时支持裸机和容器环境,以及vGPU模式。一旦将GPU卡配置为MIG,您就可以动态管理多个实例。MIG设置具有持久性,即使在重启后也不会受到影响,除非用户主动切换。
MIG技术,让GPU资源在单卡上实现最高7倍的扩展,为研发人员带来更丰富的资源和更高的操作灵活性。它优化了GPU使用效率,允许在同一GPU上并行处理推理、训练和HPC任务。每个MIG实例都像独立GPU一样运行,保持编程模型的稳定性,极大地便利了开发者。
单个 GPU 中包含七个独立实例。
多实例GPU(MIG)技术,为NVIDIA Blackwell和Hopper™系列GPU注入更强动力与更高价值。此技术能将单个GPU划分为七个独立实例,每个实例均配备高带宽显存、缓存和计算核心。借助MIG,管理员可轻松应对各种规模的负载,确保稳定可靠的服务质量(QoS),让每位用户都能尽享加速计算的便利。
优势概览:

- MIG技术,让单个GPU资源提升至原来的7倍!为研发人员和开发者带来丰富的资源与高度的灵活性。立即体验,释放无限潜能!
- MIG提供多样化的GPU实例大小选择,确保每项工作负载得到适当的处理。优化利用率,释放数据中心投资价值,让性能与成本双赢。
- MIG技术让GPU能同时处理推理、训练和HPC任务,保持稳定的延迟与吞吐量。与传统的时间分片方式不同,所有工作负载并行运行,显著提升性能表现。
技术原理:
若非MIG的介入,同一GPU上的各种作业(如AI推理请求)将争夺共享资源。显存带宽更大的作业会侵占其他作业的资源,使众多作业无法达成延迟目标。借助MIG,各作业能同时在不同的实例上运行,每个实例都拥有专属的计算、显存和显存带宽资源,从而实现可预测的性能,满足服务质量(QoS)要求,并尽可能提高GPU的利用率。

特性分析:
启动全新MIG(Multi-Instance GPU)特性,NVIDIA Ampere架构起的GPU可被安全分割为七种独立的GPU实例,全力服务于CUDA应用。这一创新设计使得多个用户得以各自拥有专属的GPU资源,实现最优利用。MIG特性尤其适合那些无法充分发挥GPU计算能力的工作负载场景,用户可以通过并行执行不同任务,最大程度地提升GPU效率。这不仅优化了资源分配,也提升了整体性能,让GPU的每一份力量都得到充分利用。
对于追求多租户服务的云服务提供商(CSP),MIG技术确保单一客户端的操作不干扰其他客户。同时,它提升了各客户间的安全隔离性,保障了服务的稳定与安全。
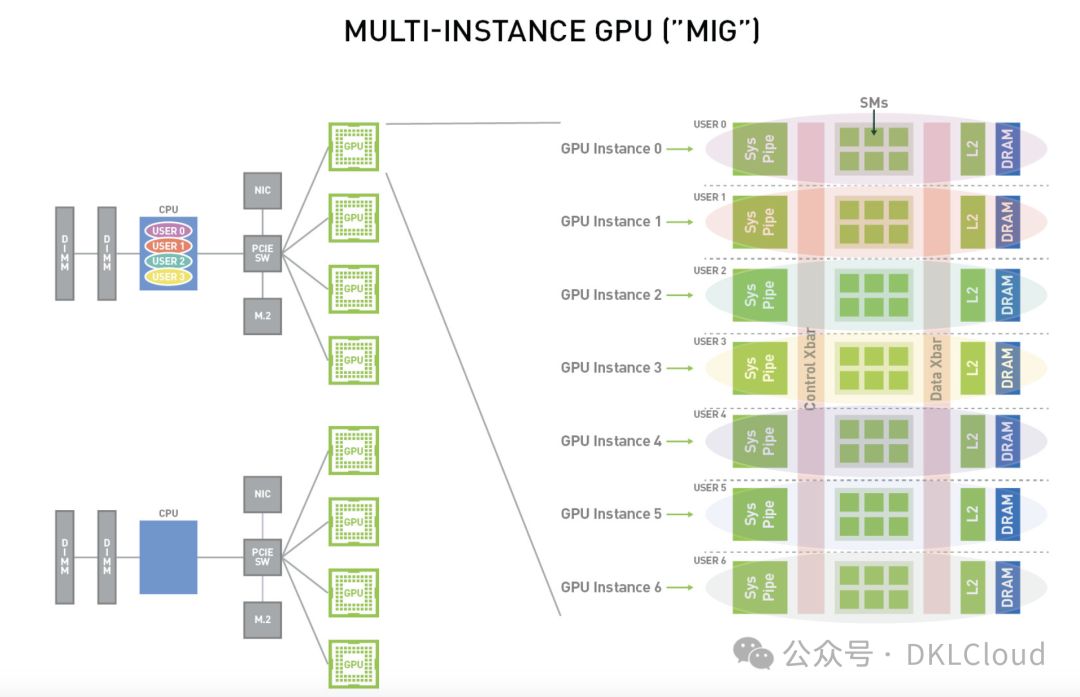
在MIG模式下,每个实例所对应的处理器具备独立且隔绝的内存系统访问路径——片上交叉开关端口、L2缓存分段、内存控制器以及DRAM地址总线均会专一地分配给单个实例。这使得即便有其他任务在对其自身缓存进行大量读写操作或已使DRAM接口达到饱和的情况下,单个工作负载仍能获得稳定、可预期的执行速度和延迟时间,同时保证相同水平的L2缓存分配与DRAM带宽资源。MIG能够对GPU中的计算资源(包括流式多处理器或SM,以及诸如拷贝引擎或解码器之类的GPU引擎)进行划分,从而为不同的客户(例如虚拟机、容器或进程)提供预设的服务质量(QoS)保障及故障隔离机制。
借助MIG技术,用户现在可以像管理实体GPU一样,轻松查看和调度新建虚拟GPU实例上的任务。MIG不仅与Linux系统完美兼容,还支持基于Docker Engine的容器部署。更令人振奋的是,MIG还能无缝对接Kubernetes,以及在Red Hat虚拟化和VMware vSphere等虚拟机管理程序上建立的虚拟机。
MIG支持如下部署方案:
1. 直接部署于裸金属环境,包含容器化部署
3. 利用支持的虚拟机管理程序实施vGPU部署
利用MIG技术,物理GPU可同步运行多个vGPU,实现虚拟机的并行运算。同时,vGPU的隔离性保障依然得以维持,确保数据安全。
根据需要调配和配置实例:
在NVIDIA GB200上,GPU可被分割为多个MIG实例,显存大小各异。例如,管理员能创建两个各占95GB的实例,或四个各占45GB的实例,甚至是七个各占23GB的实例。如此灵活的配置方式,让资源利用更加高效。
管理员可随时调整MIG实例,以适应用户需求和业务需求的快速变化,优化GPU资源分配。例如,白天使用七个MIG实例进行高效推理,夜间则整合为一个大型MIG实例,专注深度学习训练。
安全、并行运行工作负载:
每个MIG实例都配备了专用的计算、内存和缓存硬件资源,确保了稳定可靠的服务质量和故障隔离。换句话说,即使某个实例上的应用出现故障,也不会对其他实例造成影响。
这表示,各类实例能运行多种工作负载,如交互式模型开发、深度学习训练、AI推理和高性能计算应用等。由于这些实例并行运作,它们在物理GPU上同时执行不同任务,却相互独立,互不影响。
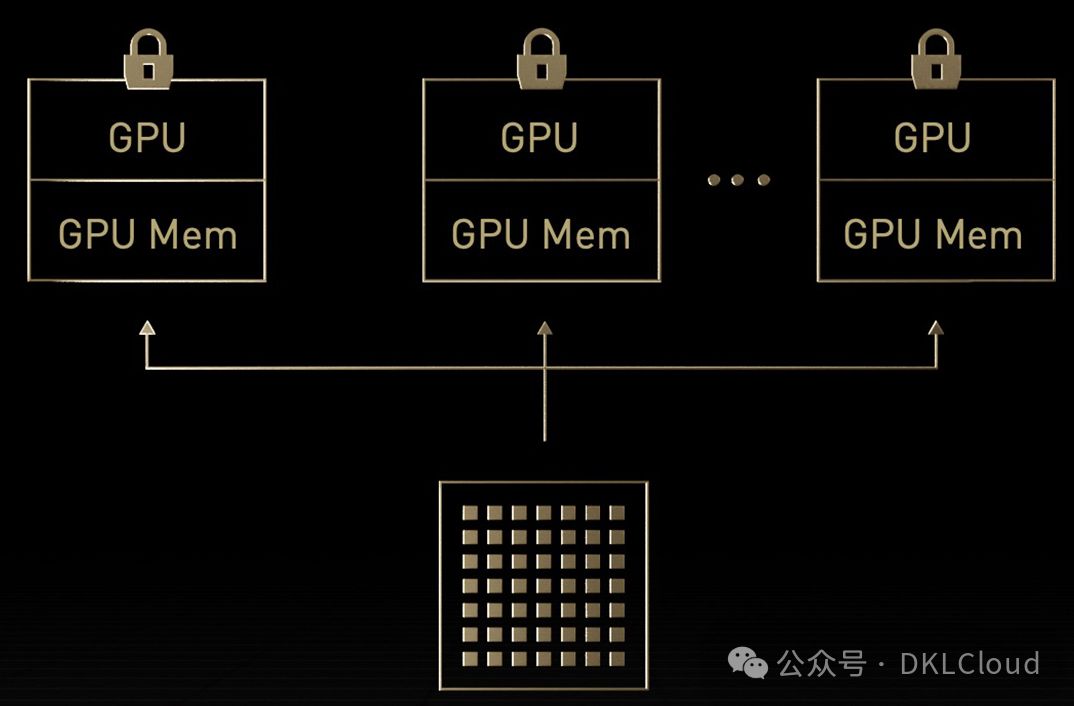
Blackwell GPU 中的 MIG
Blackwell 和 Hopper GPU,通过在虚拟化环境中配置多达7个GPU实例,实现了多租户、多用户支持,助力实现MIG。在硬件和服务器虚拟化管理程序层面,利用机密计算技术,安全地隔离每个实例。每个MIG实例均配备专用视频解码器,能在共享基础架构上提供安全、高吞吐量的智能视频分析(IVA)。借助并发MIG分析,管理员可实时监控适度规模的GPU加速,并为多个用户智能分配资源。
轻负载研究,无需全云实例。MIG技术可隔离并安全利用GPU部分,确保数据在静态、传输和使用时的绝对安全。这一策略不仅使云供应商定价更具弹性,也捕获了小型客户的潜在机会。
数据中心级MIG多实例结构图
六、MIG 规格介绍

支持MIG GPU列表
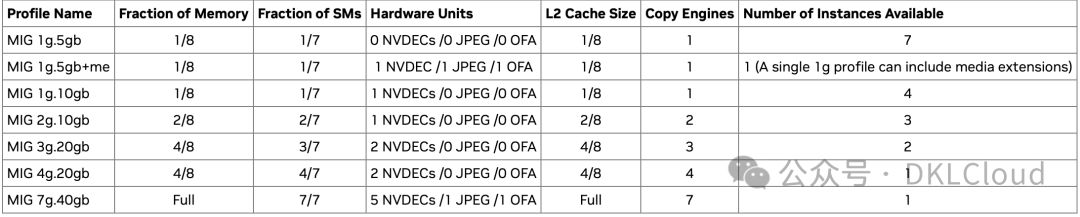
MIG划分 案例介绍:
A100-SXM4-40GB产品配置一览无余。对于80GB版本,配置将随内存比例变化,展示为1g.10gb、2g.20gb、3g.40gb、4g.40gb和7g.80gb。
GPU Instance Profiles on A100
下图以图形方式展示了如何构建所有有效的GPU实例组合
MIG Profiles on A100
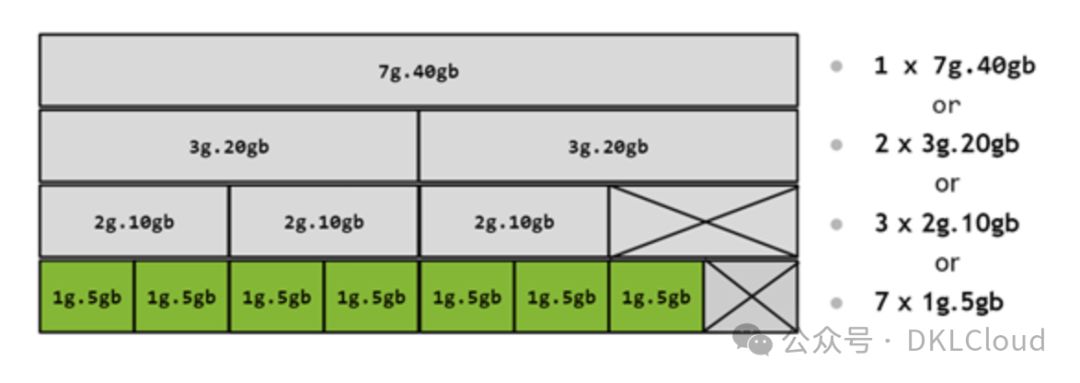
GPU Instance MIG切分介绍:
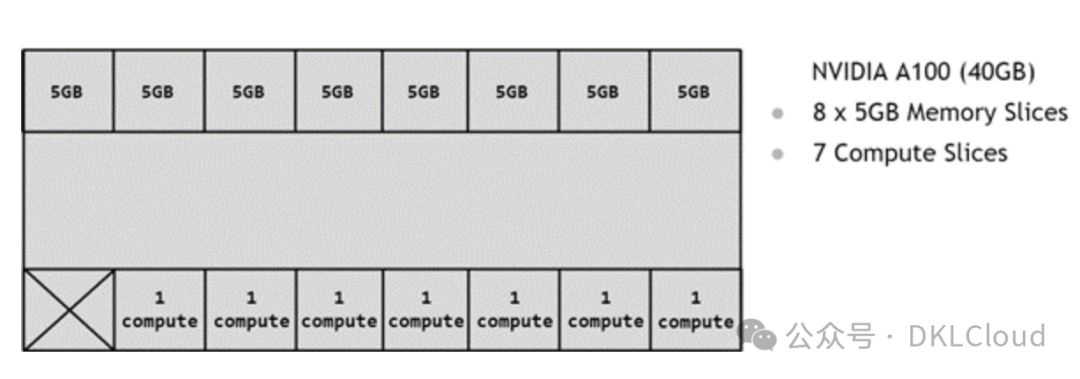
A100-40GB GPU的内存切片构成,包含8个5GB的内存区域和7个SM切片。此分区模式通过内存切片实现,具体如下图所示。
Available Slices on A100
如前所述,构建GPU实例(GI)需融合一定量的内存切片与计算切片。下图展示了如何将1个5GB内存切片与1个计算切片相结合,打造出1g.5gb的GI配置。
Combining Memory and Compute Slices

Combining Memory and Compute Slices
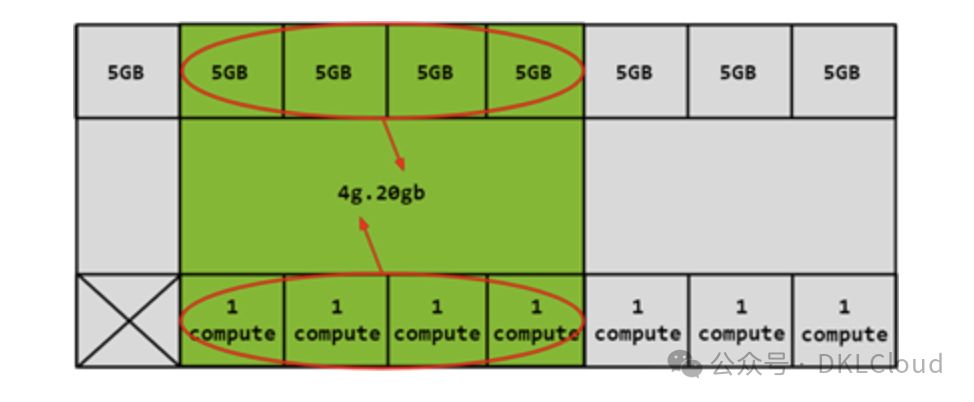
此配置在4GB或5GB的GPU实例中,提供了4个计算单元(核心或流处理器)。内存容量则达到了惊人的20GB,这是基于4倍于GPU实例规格的内存。这种高度灵活的配置方式,使得用户能够根据其特定应用需求,精确定制GPU资源。无论是进行大规模并行计算,还是处理高内存需求的任务,都能保证高效利用GPU的性能。例如,在深度学习训练、高性能计算以及图形密集型应用中,选择恰当的GPU资源组合,将发挥至关重要的作用。
七、MPS(Multi-Process Scheduling)
MPS多进程调度,作为CUDA应用程序编程接口的卓越二进制兼容版本,自Kepler的GP10架构起,由NVIDIA引入。它赋予多个流或CPU进程同时向GPU发射Kernel函数的能力,将之融合为单一应用上下文在GPU上执行。这一革新策略显著提升了GPU的利用率,实现了更高效的计算处理。
当使用MPS时,MPS Server会通过一个 CUDA Context 管理GPU硬件资源,多个MPS Clients会将他们的任务通过MPS Server 传入GPU ,从而越过了硬件时间分片调度的限制,使得他们的CUDA Kernels 实现真正意义上的并行。但MPS由于共享CUDA Context也带来一个致命缺陷,其故障隔离差,如果一个在执行kernel的任务退出,和该任务共享share IPC和UVM的任务一会一同出错退出。
八、rCUDA
rCUDA指remote CUDA,是远程GPU调用方案,支持以透明的方式并发远程使用CUDA 设备。rCUDA提供了非GPU节点访问使用GPU 的方式,从而可以在非GPU 节点运行AI应用程序。rCUDA是一种C/S架构,Client使用CUDA运行库远程调用Server上的GPU接口,Server监控请求并使用GPU执行请求,返回执行结果。在实际场景中,无需为本地节点配置GPU资源,可以通过远程调用GPU资源从而无需关注GPU所在位置,是非常重要的能力,隔离了应用和GPU资源层。
九、vCUDA
vCUDA采用在用户层拦截和重定向CUDA API的方式,在VM中建立pGPU的逻辑映像,即vGPU,来实现GPU资源的细粒度划分、重组和再利用,支持多机并发、挂起恢复等VM的高级特性。vCUDA库是一个对nvidia-ml和libcuda库的封装库,通过劫持容器内用户程序的CUDA调用限制当前容器内进程对GPU 算力和显存的使用。vCUDA优点是API开源,容易实现;缺点是CUDA库升级快,CUDA 库升级则需要不断适配,成本高;另外隔离不准确无法提供算力精准限制的能力、安全性低用户可以绕过限制等。目前市面上厂商基本上都是采用vCUDA API转发的方式实现GPU算力池化。
十、GPU算力池化云原生实现
GPU池化(GPU-Pooling)是通过对物理GPU进行软件定义,融合了GPU虚拟化、多卡聚合、远程调用、动态释放等多种能力,解决GPU使用效率低和弹性扩展差的问题。GPU资源池化最理想的方案是屏蔽底层GPU异构资源细节(支持英伟达和国产各厂商GPU) ,分离上层AI 框架应用和底层GPU类型的耦合性。不过目前AI框架和GPU类型是紧耦合的,尚没有实现的方案抽象出一层能屏蔽异构GPU。基于不同框架开发的应用在迁移到其他类型GPU时,不得不重新构建应用,至少得迁移应用到另外的GPU,往往需要重新的适配和调试。
GPU虚拟化与池化的核心在于算力和故障的隔离。这可以通过硬件隔离,如空分方式,MPS共享CUDA Context方式以及Time Sharing时分方式实现。底层的隔离效果尤为显著,例如MIG硬件算力隔离方案,这是一种高效的硬件资源隔离和故障隔离策略。
但硬件设备编程接口和驱动接口往往是不公开的,所以对厂商依赖大,实施的难度非常大,灵活性差,如支持Ampere架构的A100等,最多只能切分为7个MIG实例等。NVIDIA MPS是除MIG外,算力隔离最好的。它将多个CUDA Context合并到一个CUDA Context中,省去Context Switch的开销并在Context内部实现了算力隔离,但也致额外的故障传播。MIG和MPS优缺点都非常明显,实际工程中用的并不普遍。采用API转发的多任务GPU时间分片的实现模式相对容易实现和应用最广。
利用AI应用对GPU的调用层次,我们可以实现多层次的资源池化能力。从CUDA层、Diver层到硬件设备层,各种抽象层次都能有效将需要加速的应用转发至GPU资源池中。总的来说,底层转发性能损失最小,操作范围广泛;但同时,编程工作量也随之增加,难度提高。
十一、云原生调度GPU算力
随着云原生应用的大规模实施,GPU算力资源池化需具备云原生部署功能,如支持Kubernetes、Docker服务。通过K8s Pod与GPU资源池按需创建的vGPU绑定,实现Pod中的应用执行。无论是英伟达还是国产GPU,所有显卡均可纳入算力资源池。目前,我们已实现不同显卡的分类,并根据不同框架应用需求,智能调度至相应GPU算力池。
提升资源管理效率,实现算力资源池的资源、资产管理与运行监控。优化调度能力,降低GPU资源碎片,满足AI应用需求迅速增长的挑战。未来,算力资源池化将成企业关注焦点。
Kubernetes(K8S)作为一款卓越的容器编排平台,其弹性伸缩特性赋予其无可比拟的优势,使得底层资源得以充分利用。在科技产业界,大模型推理和微调训练的需求激增,而Nvidia专业显卡供应紧张,形成了鲜明的矛盾。
在当前的矛盾环境下,将NVIDIA显卡与K8S容器平台巧妙融合,构建一个高效的GPU算力调度平台,无疑是解决这一挑战的最佳策略。这种融合能够充分挖掘每块显卡的潜力,借助Kubernetes的弹性伸缩特性,实现对GPU算力的智能调度和管理,为大规模AI模型的训练和推理提供坚实的基础支撑。
在Kubernetes容器平台上,我们可以通过其强大的资源调度和分配机制,对GPU集群的算力进行高效管理。Kubernetes具备丰富的资源管理功能,特别支持如GPU等特殊资源类型的管理。以下是在Kubernetes中实现GPU资源管控的核心步骤和关键概念:
1. GPU 插件支持:
Kubernetes无法直接掌控GPU资源,但NVIDIA GPU Device Plugin插件能弥补这一短板。此插件负责将GPU资源注册至Kubernetes,使其能够精准识别并高效管理。借助此插件,Kubernetes的GPU管理能力得以显著提升。
2. GPU 设备声明:
在集群节点上部署NVIDIA驱动、CUDA工具包等关键组件,并激活NVIDIA GPU设备插件,即可实时查看可用的GPU资源。
3. 资源请求和限制:
开发者在编写Pod或Deployment的yaml文件时,可以通过
优化后:探索NVIDIA GPU资源限制,访问".spec.containers[].resources.limits.nvidia.com/gpu"。
通过".spec.containers[].resources.requests.nvidia.com/gpu",您可以精确指定对GPU资源的需求。
"limits"规定了容器可使用的GPU上限,而`requests`则设定了运行所需的最小GPU数量。
4. 调度决策:
Kubernetes调度器在派发Pod时,会兼顾资源请求与限制,确保选定的节点拥有充足的GPU资源。它把GPU视为一种独特的资源进行优化调度。
5. 监控与计量:
利用Prometheus和Grafana等监控工具,实时掌握GPU利用率等关键数据,实现长期深度分析。助力管理员精准分配与优化GPU资源,提升系统性能。
6. GPU隔离:
利用MIG(Multi-Instance GPU)等先进技术,我们能精细划分GPU资源粒度,实现细密的GPU资源隔离和分配,提升资源使用效率。
7. 动态扩缩容:
利用Horizontal Pod Autoscaler (HPA)等强大工具,我们可以根据GPU的利用率或其他自定义参数,实现Pod数量的自动调整。这样,GPU资源就能得到智能的动态扩缩容。
利用这些策略,Kubernetes集群能高效地管理和分配GPU资源,实现对GPU集群算力的精细化管理。
CUDA:
NVIDIA推出的CUDA(Compute Unified Device Architecture)是一款并行计算平台和编程模型,它充分利用了NVIDIA GPU的强大并行计算能力,从而显著加速应用程序的执行。CUDA提供了一套丰富的编程接口和工具,让开发者能以标准的C/C++编程语言编写出高效的GPU加速程序。
RootFS:
根文件系统(Root Filesystem),是Linux系统启动后首个加载的文件系统,位于文件系统的顶层。它汇聚了操作系统的核心文件和目录结构,涵盖了/bin、/sbin、/etc、/lib、/dev、/proc、/sys等关键部分。
在K8S容器平台上,一个典型的GPU应用软件栈如下:顶层是多个包含业务应用的容器,每个容器都包含业务应用、CUDA工具集(CUDA Toolkit)和容器RootFS;中间层是容器引擎(Docker)和安装了CUDA驱动程序的宿主机操作系统;底层是部署了多个GPU硬件显卡的服务器硬件。
主要组件:
CUDA 工具集,囊括 nvidia-container-runtime(shim)、nvidia-container-runtime-hook 与 nvidia-container library等重要组件,以及CLI工具。这一系列强大工具,为您的AI计算提供无缝支持,开启高效编程新篇章。
通过对比CUDA工具集嵌入前后的架构图,我们可以直观地识别各组件的位置以及其功能,从而洞察其内在机制。
图示:CUDA toolset 嵌入前的容器软件栈
图示:CUDA toolkit 嵌入后的容器软件栈
- nvidia-container-runtime(shim):
该组件曾经是 runc 的一个完整分支,其中注入了特定于 NVIDIA 的代码。自2019年以来,它已经成为安装在主机系统上的本机 runC 的一个轻量级包装器。nvidia-container-runtime 接受 runc spec作为输入,将 NVIDIA 容器运行时钩子(nvidia-container-runtime-hook)作为预启动钩子注入其中,然后调用本机 runc,并传递修改后的具有该钩子设置的 runc spec。对于 NVIDIA 容器运行时 v1.12.0 版本及更高版本,这个运行时(runtime)还对 OCI 运行时规范进行了额外修改,以注入特定的设备和挂载点,这些设备和挂载点不受 NVIDIA 容器 CLI 控制。
- nvidia-container-runtime-hook:
这个组件内嵌了一个可执行文件,专为 runC 预启动钩子打造。当容器创建后、启动前,runC 会主动调用此脚本,并授予其对关联的 config.json(如:config.example.json)的完全访问权限。接着,它精准提取 config.json 中的关键信息,并以此作为参数,激活 nvidia-container-cli CLI工具,携带一组恰如其分的标志。其中,最关键的标志就是指定应注入该容器的特定 GPU 设备。
- nvidia-container library 和 CLI:
这些组件为GNU/Linux容器的NVIDIA GPU自动配置提供了库和CLI实用工具。其内核原语依赖性设计,确保与任何容器运行时的兼容性。
K8S 侧:Device Plugin
在Kubernetes(K8S)中,设备插件(Device Plugin)是一种强大的扩展机制,它负责将节点上的各类设备资源(如GPU、FPGA、TPU等)无缝整合到Kubernetes的资源管理体系。通过设备插件,集群管理员能轻易地将这些设备资源暴露给Kubernetes API服务器,从而让集群内的Pod能够借助资源调度机制,充分利用这些设备资源。这不仅提升了资源利用率,也进一步优化了应用性能,实现了资源的高效管理。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-