目录
1. VGG解决的问题
2. 网络结构和参数
3. pytorch搭建vgg
4.flower_photos分类任务实践
5.资料
一、VGG解决的问题
论文链接:https://arxiv.org/pdf/1409.1556
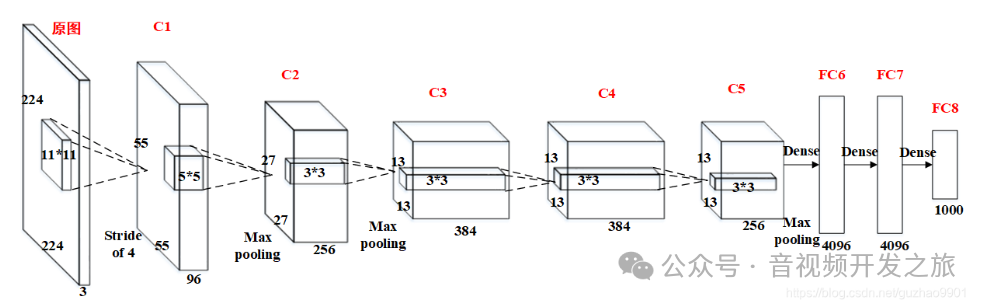
在VGG之前,大多数深度学习模型相对较浅,比如下面的AlexNet(5层卷积和3层全连接层)。
Vgg网络的一个亮点是,通过使用小尺寸卷积核,有效的增量网络的深度,降低计算的复杂度。堆叠多个3×3的卷积核来替代大尺度卷积核,减少所需参数:通过堆叠2个3×3的卷积核替代5×5的卷积核,堆叠3个3×3的卷积核替代7×7的卷积核,两者之间拥有相同的感受野
感受野(Receptive Field)是指输出特征图(feature map)的一个元素 对应输入图像上区域大小,较大的感受野可以帮助网络捕获更多的上下文信息,较小的感受野更适合捕捉图像中的细节特征。
感受野计算公式:F(i)=[F(i+1)-1]×Stride + Ksize
eg:步长Stride=1,卷积核大小Ksize=3Feature map: F = 1Conv3x3(3): F = (1 - 1) x 1 + 3 = 3Conv3x3(2): F = (3 - 1) x 1 + 3 = 5 #堆叠2个3×3的卷积核替代5×5的卷积核Conv3x3(1): F = (5 - 1) x 1 + 3 = 7 #堆叠3个3×3的卷积核替代7×7的卷积核
使用7x7的卷积核所需参数为7x7xCxC = 49C²,使用3个3x3卷积核3x(3x3xCxC) = 27C²。(第一个C表示输入特征矩阵深度,第二个C表示卷积核个数即输出矩阵深度),使用多个小卷积核进行堆叠比使用大卷积核 在相同感受野的情况下,使用的参数量更少
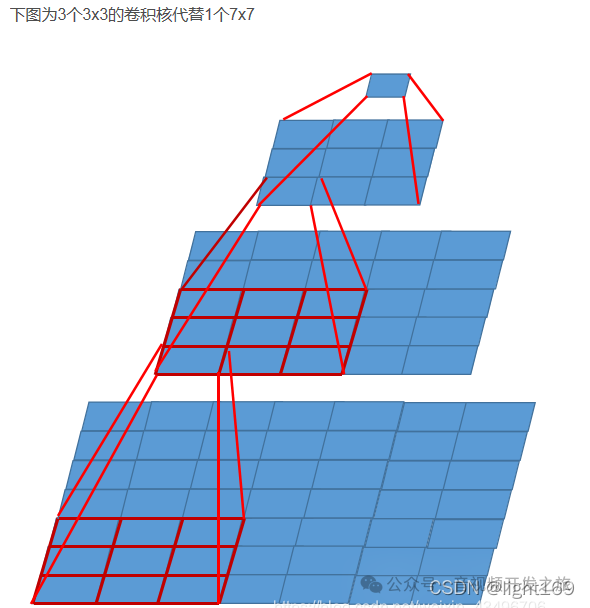
图像来自:VGG16网络结构详解
VGG另一个亮点是:使用了统一的结构,多个连续的卷积层,后面跟Relu,然后进行最大池化层处理。虽然之前的网络如Alexnet也是这种结构,但是它在不同层的卷积核大小和数量以及步长等参数有较大的变化,而VGG不同层的参数基本一致,后续的Resnet也是采用这种重复性的结构,便于扩展。
二、网络结构和参数
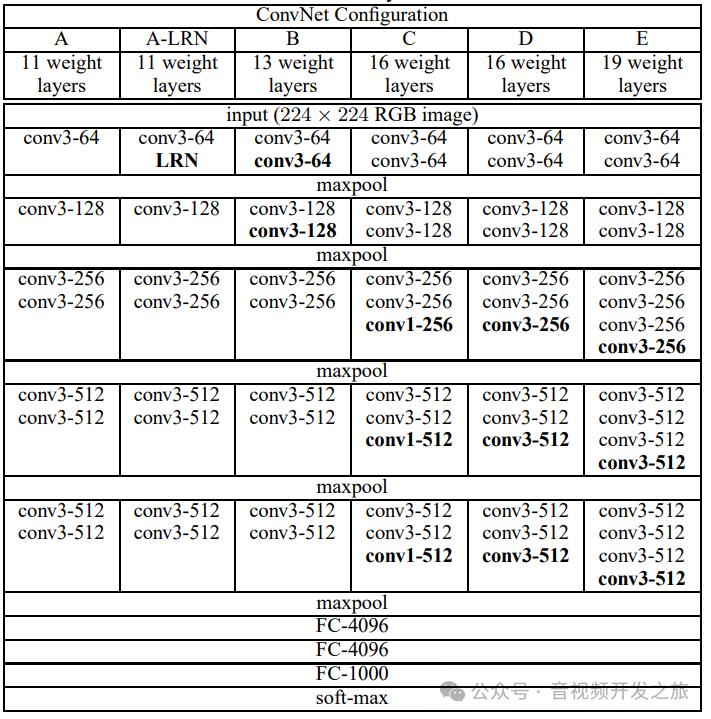
图片来自:https://arxiv.org/pdf/1409.1556
VGG16的结构对应如下
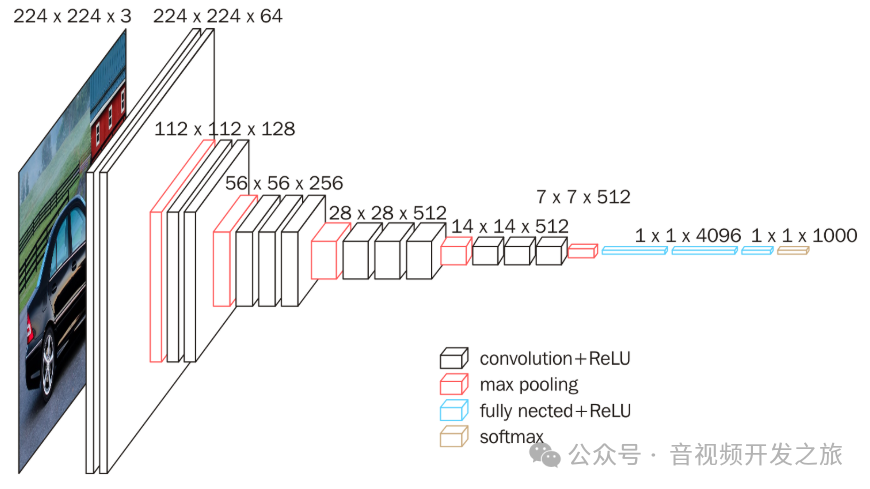
由于VGG最初用于ImageNet数据集的分类任务,所以输入图片统一尺寸为(224, 224)。整个网络中都用了3x3大小的卷积核,并配合1x1的卷积核进行简单的线型转变(不改变图片大小)
三、pytorch搭建Vgg(代码加了详细注释)
3.1 网络模型搭建
"""VGG模型"""import torchimport torch.nn as nnclass VGG(nn.Module):def __init__(self,features,num_classes=1000):#VGG 是当前类对象, self是当前实例对象#传递类对象让父类知道哪个子类在被初始化;传递实例对象为了让父类的构造方法能够访问和修改子类的实例super(VGG,self).__init__()#定义特征提取网络self.features = features#定义分类网络self.classifier = nn.Sequential(#将特征提取网络的卷积层输出的特征图(7X7大小,512个通道)展平flatten为4096的一维向量,应用全链接层nn.Linear(7*7*512,4096),#引入非线性激活Relu函数,inplace为True在某些情况可以节省内存nn.ReLU(True),#dropout正则化,已0.5的概率随机丢弃(置零)一些神经元,防止过拟合nn.Dropout(p=0.5),#同上,这里将4096维输入映射为另外一个4096维空间.增加非线性能力,特征进行转换,提取更有用信息nn.Linear(4096,4096)nn.ReLU(True),nn.Dropout(p=0.5),#第三层全链接层,将4096维映射为类别数量的维度,为每个类型分别生成一个实数得分nn.Linear(4096,num_classes),)#前向传播, 传入收入u的图片def forward(self,x):#特征提取x=self.features(x)#特征提取的输出是四维张量(batchsize,channel,h,w),这里start_dim=1沿第一维进行展平,结果为(batchsize,channel*w*h). pytorch中全链接层(nn.Linear)期望的收入u是一个二维张量,其中第一维为batchsize,第二维为样本的特征向量.因此需要手动的将卷积层输出的多维数据展平为二维x = torch.flatten(x,start_dim=1)#分类x = self.classifier(x)return x# 字典配置,可以很方便的切换不同深度的网络cfgs = {'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],}#特征提取函数,这个设计很巧妙,把实现和配置分离解耦合def make_features(cfg:list):#用于存储网络层列表layers =[]#输入的图像通道RGBin_channels = 3#遍历列表,根据配置 实现不同的layerfor v in cfg:#最大池化层if v=='M':layer +=[nn.MaxPool2d(kernel_size=2,stride=2)]else:#构建2d卷积层以及紧跟的relu激活函数conv2d = nn.Conv2d(in_channel,v,kernel_size=3,padding=1)layer += [conv2d,nn.ReLU(True)]#把当前输出作为下一层的输入in_channels = v#最后使用Sequential把layer连接起来,这里使用了列表非关键词解包return nn.Sequential(*layers)def vgg(model_name =='vgg16',**kwargs):#根据model_name从配置中获取对应的网络结构cfg = cfgs[model_name]#提取特征fetures = make_features(cfg)#根据特征,以及非关键词参数创建VGG模型对象model=VGG(features,**kwargs)return model
3.2 模型训练
"""VGG 训练代码"""import osimport sysimport torchimport torch.nn as nnfrom torchvision import transforms,datasets,utilsimport matplotlib.pyplot as pltimport torch.optim as optimfrom tqdm import tqdmfrom model import VGGdef train():device = torch.device("cuda" if torch.cuda.is_available() else "cpu")#数据增强data_transform = {#训练数据,采用随机尺寸裁剪和随机水平翻转来增加数据的多样性#toTensor 将PIL或者numpy ndarray转为FloatTensor,并吧图像的像素之从0-255转为0-1#归一化使得模型的训练更加稳定"train": transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])#验证数据,进行尺寸的调整."val":transforms.Compose([transforms.Resize((224,224)),transforms.ToTensor(),transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])}data_root = os.path.abspath(os.path.join(os.getcwd(), "./"))image_path = os.path.join(data_root, "data_set")#加载数据集,datasets.ImageFolder类 用于加载按照分类命名的文件夹结构数据(每个类一个文件夹)train_dataset = datasets.ImageFolder(root=os.path.join(image_path,"train"),transform = data_transform['train'])val_dataset = datasets.ImageFolder(root=os.path.join(image_path,"val"),transform = data_transform['val'])#初始化数据加载器, 负责将数据集分批次处理,对于内存管理和训练加速很重要train_loader = torch.utils.data.DataLoader(train_dataset,batch_size = 32,shuffle=True,num_workers=0)val_loader = torch.utils.data.DataLoader(val_dataset,batch_size = 32,shuffle=True,num_workers=0)#初始化网络 loss函数以及优化器model_name = "vgg16"net = vgg(model_name=model_name,num_classes=5)net.to(device)#使用分类任务常用的交叉损失熵loss; 如果是回归任务常用的是MSEloss;如果是目标检测(更综合的任务),涉及物体的定位和类别识别(一个边界框和类别),会使用多个loss(边界框回归损失;类别分类损失;对象置信度损失)loss_function = nn.CrossEntropyLoss()#常用的Adam优化器,Adam优化器结合了动量Momentum和RMSprop,能为不同的参数自适应的调整学习率. 除了Adam也有其他的优化器,比如SGD(随机梯度下降)+Momentum,Adagrad 等optimizer = optim.Adam(net.parameters(),lr=0.0001)#训练epochs=10save_path = 'VGGNet.pth'best_accuracy = 0.0val_num = len(val_dataset)for epoch in range(epochs):#设置为训练模式,开始训练#训练模式会启动所有层的参数更新,在反向传播过程中,梯度会计算并更新到参数上net.train()running_loss = 0.0train_bar = tqdm(train_loader,file=sys.stdout)for step ,data in enumerate(train_bar):images,labels = data#清空梯度# pytorch中梯度默认是累积的,即如果在同一个优化器实例上连续多次调用backward,梯度将会累加到之前的梯度上,会导致训练不稳定#每次参数更新应该基于当前批次的损失计算,不应该受到之前批次的影响,保证独立. 清空梯度是优化器的基本要求optimizer.zero_grad()#将images转移到deivce设备,前向传播计算输出outputs = net(images.to(device))#计算损失loss = loss_function(outputs,labels.to(device))#反向传播,负责计算每个参数的梯度,并保存在参数的.grad中但此时参数尚未更新loss.backward()#optimizer.step 更新权重,负责计算反向传播得到的梯度来更新模型参数optimizer.step()running_loss += loss.item()#val 在每一轮训练结束后,模型被设置为验证模式,并计算在验证集上的准确率#(验证)评估模式,禁用所有层的参数更新,即在反向传播过程中,梯度不会计算也不会影响参数;关闭Dropoutnet.eval()acc = 0.0#torch.no_grad 确保在验证过程中不计算梯度,以节省内存和计算资源with torch.no_grad():val_bar = tqdm(val_loader,file=sys.stdout)for val_data in val_bar:val_images,val_labels = val_dataoutputs = net(val_images.to(device))predict_y = torch.max(outputs,dim=1)[1]acc += torch.eq(predict_y,val_labels.to(device)).sum().item()val_accuracy = acc/val_num#保存最佳模型if val_accuracy > best_accuracy:best_accuracy = val_accuracytorch.save(net.state_dict(),save_path)
3.3 模型推理
"""VGG 推理"""import osimport torchfrom PIL import Imagefrom torchvision import transformsfrom model import vggdef predict():device = torch.device('cuda' if torch.cuda.is_available() else "cpu")data_trasform = transforms.Compose([transforms.Resize((224,224)),transforms.ToTensor(),transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])image_path = './test.jpg'img = Image.open(image_path)img = data_transform(img) #[C H W]img =torch.unsqueeze(img,dim=0) #维度扩展,在第一维 增加Batchsize维度 [B,C,H,W]mode = vgg(model_name='vgg16',num_classes=5)mode = mode.to(device)weights_path = './VGGNet.pth'mode.load_state_dict(torch.load(weights_path))#将模型设置为评估模式,禁用模型中的dropout和batchnormalization的动态行为mode.eval()#禁用季度计算,减少内存和计算with torch.no_grad():output = mode(img.to(device)).cpu()#torch.squeeze移除张量中所有大小为1的维度,这里即移除Batchsize的维度output = torch.squeeze(output)#torch.softmax是将原始得分转为概率分布的函数,#归一化:sotfmax将一个向量的元素映射为(0,1)区间,所有元素的和为1,形成概率分布#对于多分类问题,softmax用于将模型的原始输出转为概率分布,表示每个类别的预测概率#eg:输入是tensor([ 3.6085, -0.7472, -0.0099, -2.4376, -0.3151]),经过softmax输出是tensor([0.9418, 0.0121, 0.0253, 0.0022, 0.0186])predict = torch.softmax(output,dim=0)#找到概率最高的类别索引 eg:输入tensor([0.9418, 0.0121, 0.0253, 0.0022, 0.0186]) 输出:predic_cla:0predict_cla= torch.argmax(predict).numpy()print(f"predict:{predict},predic_cla:{predict_cla}")
Softmax可以通过以下数学公式实现:

四、flower_photos分类
使用Vgg16预训练模型的迁移学习,把全链接层1000类训练为5类的分类任务
数据集地址: https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
训练集和验证集的划分
import osfrom shutil import copy, rmtreeimport randomdef mk_file(file_path: str):if os.path.exists(file_path):# 如果文件夹存在,则先删除原文件夹在重新创建rmtree(file_path)os.makedirs(file_path)def main():# 保证随机可复现random.seed(0)# 将数据集中10%的数据划分到验证集中split_rate = 0.1# 指向你解压后的flower_photos文件夹cwd = os.getcwd()data_root = os.path.join(cwd, "flower_data")origin_flower_path = os.path.join(data_root, "flower_photos")assert os.path.exists(origin_flower_path), "path '{}' does not exist.".format(origin_flower_path)flower_class = [cla for cla in os.listdir(origin_flower_path)if os.path.isdir(os.path.join(origin_flower_path, cla))]# 建立保存训练集的文件夹train_root = os.path.join(data_root, "train")mk_file(train_root)for cla in flower_class:# 建立每个类别对应的文件夹mk_file(os.path.join(train_root, cla))# 建立保存验证集的文件夹val_root = os.path.join(data_root, "val")mk_file(val_root)for cla in flower_class:# 建立每个类别对应的文件夹mk_file(os.path.join(val_root, cla))for cla in flower_class:cla_path = os.path.join(origin_flower_path, cla)images = os.listdir(cla_path)num = len(images)# 随机采样验证集的索引eval_index = random.sample(images, k=int(num*split_rate))for index, image in enumerate(images):if image in eval_index:# 将分配至验证集中的文件复制到相应目录image_path = os.path.join(cla_path, image)new_path = os.path.join(val_root, cla)copy(image_path, new_path)else:# 将分配至训练集中的文件复制到相应目录image_path = os.path.join(cla_path, image)new_path = os.path.join(train_root, cla)copy(image_path, new_path)print("\r[{}] processing [{}/{}]".format(cla, index+1, num), end="") # processing barprint()print("processing done!")#https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/blob/master/data_set/split_data.py
调用上面的tran和predict 训练和推理,即可
五、资料
1.论文链接:https://arxiv.org/pdf/1409.1556
2.代码实现:https://github.com/WZMIAOMIAO/deep-learning-for-image-processing
3.图像分类篇——使用pytorch搭建VGG网络 https://blog.csdn.net/weixin_43872060/article/details/116607840
霹雳吧啦Wz https://space.bilibili.com/18161609/channel/series
4.VGG网络详解及感受野的计算 https://www.bilibili.com/video/BV1q7411T7Y6/?spm_id_from=333.999.0.0&vd_source=179014f1a2f3078fc78ff0659a14acb9
5.使用pytorch搭建VGG网络 https://www.bilibili.com/video/BV1i7411T7ZN/?spm_id_from=333.999.0.0&vd_source=179014f1a2f3078fc78ff0659a14acb9
6.VGG模型解析 https://github.com/huaweicloud/ModelArts-Lab/wiki/VGG%E6%A8%A1%E5%9E%8B%E8%A7%A3%E6%9E%90
7.VGG16网络结构详解 https://blog.csdn.net/light169/article/details/123270587
8.AlexNet网络结构详解https://blog.csdn.net/guzhao9901/article/details/118552085