什么是Airflow?
在开始之前,让我们先简单了解一下Airflow是什么。Apache Airflow是一个开源的工作流管理平台。它允许你以代码的方式定义、调度和监控复杂的数据处理管道。
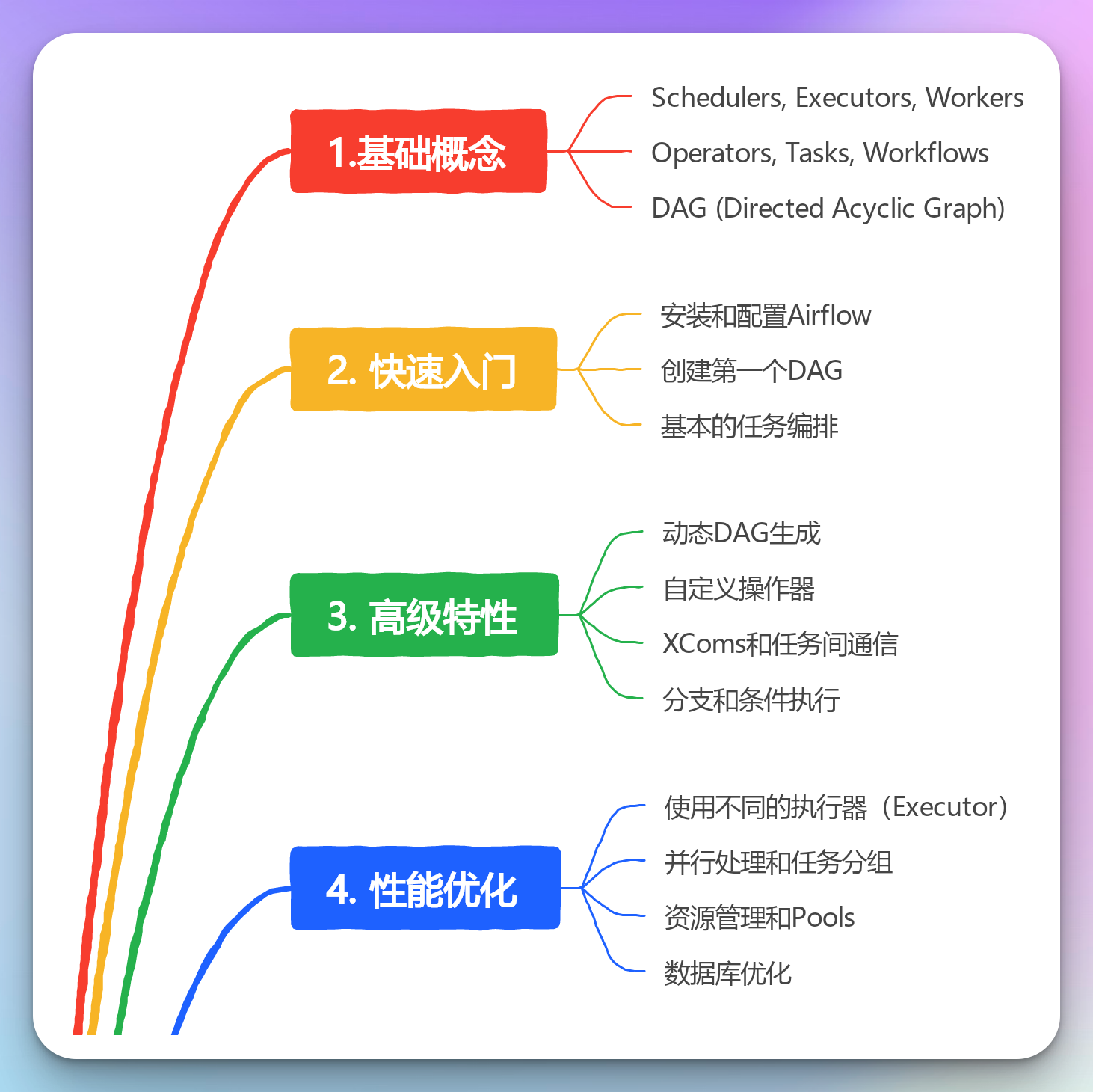
想象一下,你有一系列需要按特定顺序执行的任务,而且这些任务之间还有依赖关系,Airflow就是为解决这类问题而生的。
目录
- 什么是Airflow?
- 我的学习故事
- 学习Airflow的糙快猛方法
- 1. 理解核心概念
- 2. 快速上手实践
- 3. 深入学习和实践
- 4. 结合实际项目
- 本节学习心得
- 进阶学习:深入Airflow的高级特性
- 1. 动态DAG生成
- 2. 使用XComs进行任务间通信
- 3. 使用Sensors等待条件满足
- 实际工作中的应用
- 案例:构建数据湖ETL流程
- 本节学习心得
- Airflow性能优化
- 1. 使用多线程或多进程执行器
- 2. 优化数据库访问
- 3. 使用池限制并发任务
- 与大数据生态系统集成
- 1. 集成Spark
- 2. 集成Hive
- 3. 集成Hadoop
- 企业环境中的最佳实践
- 1. 使用变量和连接
- 2. 实现错误处理和告警
- 3. 版本控制和CI/CD
- 4. 监控和日志管理
- 本节学习心得
- 高级调度功能
- 1. 动态调度
- 2. 基于依赖的调度
- Airflow测试策略
- 1. 单元测试
- 2. 集成测试
- 3. 模拟测试
- 复杂数据管道中的应用
- 案例:多源数据集成与分析管道
- 进阶学习心得
- Airflow高级特性
- 1. 动态DAG生成
- 2. 自定义操作器
- 3. 任务分支
- 实战最佳实践
- 1. 日志管理
- 2. 管理密钥和配置
- 3. 大规模部署
- 实际工作中的挑战与解决方案
- 挑战1:处理长时间运行的任务
- 挑战2:处理大量小任务
- 挑战3:数据质量管理
- 本节学习心得
- 高级应用场景
- 1. 机器学习工作流
- 2. 数据湖构建
- 性能调优技巧
- 1. 使用Pools限制并发
- 2. 优化数据库访问
- 3. 使用Celery Executor提高并行性
- 与其他大数据工具的集成
- 1. 集成Apache Spark
- 2. 集成Apache Kafka
- 3. 集成Apache Hadoop
- 本节学习心得
- 高级架构设计
- 1. 多集群部署
- 2. 细粒度的访问控制
- 3. 动态DAG生成
- 故障排除技巧
- 1. 高级日志分析
- 2. 任务重试策略
- 3. 任务监控和告警
- 企业级最佳实践
- 1. 版本控制和 CI/CD
- 2. 数据质量检查
- 3. 资源管理
- 最后的总结-思维导图
我的学习故事

还记得我刚开始学习Airflow的时候,那感觉就像是第一次踏入健身房的新手。面对琳琅满目的"器械"(Airflow的各种概念和组件),我完全不知所措。但是,我很快想起了我的座右铭:“学习就应该糙快猛,不要一下子追求完美,在不完美的状态下前行才是最高效的姿势。”
于是,我决定先从最基本的概念开始,然后迅速上手实践。
学习Airflow的糙快猛方法
1. 理解核心概念

首先,我花了一天时间快速浏览Airflow的核心概念:
- DAG (Directed Acyclic Graph): 有向无环图,用于定义任务之间的依赖关系。
- Operator: 定义单个任务的最小单元。
- Task: Operator的具体实例。
- Workflow: 由多个Task组成的工作流。
2. 快速上手实践

理解了基本概念后,我立即开始动手。我创建了一个简单的DAG,包含两个任务:一个打印"Hello",另一个打印"World"。
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime, timedelta
def print_hello():
return 'Hello'
def print_world():
return 'World'
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2024, 7, 20),
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
dag = DAG('hello_world', default_args=default_args, schedule_interval=timedelta(days=1))
t1 = PythonOperator(
task_id='print_hello',
python_callable=print_hello,
dag=dag)
t2 = PythonOperator(
task_id='print_world',
python_callable=print_world,
dag=dag)
t1 >> t2
这个简单的例子让我对Airflow的基本使用有了直观的认识。
3. 深入学习和实践

接下来,我开始逐步深入学习Airflow的其他特性:
- 学习不同类型的Operator(比如BashOperator, PythonOperator等)
- 理解和使用Airflow的调度功能
- 学习如何处理任务间的依赖关系
- 探索Airflow的UI界面,学习如何监控和管理工作流
在这个过程中,我始终保持"糙快猛"的学习态度。我不追求一次就完全掌握所有内容,而是先快速了解,然后在实践中逐步深入。
4. 结合实际项目

学习了基础知识后,我开始将Airflow应用到实际的大数据处理项目中。我创建了一个数据ETL(提取、转换、加载)的工作流,包括从数据源抓取数据、数据清洗、数据转换和最终加载到数据仓库的过程。
这个过程让我深刻体会到了Airflow在大数据处理中的强大功能。它不仅可以自动化整个数据处理流程,还能方便地处理任务依赖、失败重试等复杂场景。
本节学习心得
回顾我这一阶段的Airflow学习之旅,我有以下几点心得:
- 保持糙快猛的态度: 不要追求一开始就完美,先快速上手,在实践中学习和改进。
- 理论结合实践: 快速了解基本概念后,立即动手实践。
- 循序渐进: 从简单的任务开始,逐步增加复杂度。
- 结合实际项目: 将所学知识应用到实际项目中,在解决实际问题的过程中加深理解。

进阶学习:深入Airflow的高级特性
在掌握了Airflow的基础知识后,是时候向更高阶的应用迈进了。
记住,即使在学习高级特性时,我们也要保持"糙快猛"的态度 —— 快速尝试,在实践中学习。
1. 动态DAG生成

在实际工作中,我们经常需要根据不同的条件动态生成DAG。例如,你可能需要为每个数据源创建一个独立的DAG。
这里有一个简单的例子:
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime, timedelta
def create_dag(dag_id, schedule, default_args):
def hello_world_py(*args):
print('Hello World')
print('This is DAG: {}'.format(dag_id))
dag = DAG(dag_id, schedule_interval=schedule, default_args=default_args)
with dag:
t1 = PythonOperator(
task_id='hello_world',
python_callable=hello_world_py,
dag=dag)
return dag
# 生成多个DAG
for i in range(3):
dag_id = 'hello_world_{}'.format(i)
default_args = {
'owner': 'airflow',
'start_date': datetime(2024, 7, 20),
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
schedule = '@daily'
globals()[dag_id] = create_dag(dag_id, schedule, default_args)
这个例子展示了如何动态创建多个DAG。这在处理多个相似但略有不同的工作流时非常有用。
2. 使用XComs进行任务间通信

XComs(Cross-communications)允许任务之间交换小量数据。这在需要将一个任务的输出传递给另一个任务时非常有用。
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime, timedelta
default_args = {
'owner': 'airflow',
'start_date': datetime(2024, 7, 20),
}
dag = DAG('xcom_example', default_args=default_args, schedule_interval=timedelta(days=1))
def push_function(**context):
context['ti'].xcom_push(key='my_key', value='Hello from push_function')
def pull_function(**context):
value = context['ti'].xcom_pull(key='my_key', task_ids='push_task')
print(f"Pulled value: {value}")
push_task = PythonOperator(
task_id='push_task',
python_callable=push_function,
provide_context=True,
dag=dag)
pull_task = PythonOperator(
task_id='pull_task',
python_callable=pull_function,
provide_context=True,
dag=dag)
push_task >> pull_task
在这个例子中,push_task将一个值推送到XCom,然后pull_task从XCom中提取这个值。
3. 使用Sensors等待条件满足

Sensors是一种特殊类型的Operator,它会一直运行直到某个条件满足。这在等待文件出现或外部系统准备就绪时非常有用。
from airflow import DAG
from airflow.sensors.filesystem import FileSensor
from airflow.operators.dummy_operator import DummyOperator
from datetime import datetime, timedelta
default_args = {
'owner': 'airflow',
'start_date': datetime(2024, 7, 20),
}
dag = DAG('file_sensor_example', default_args=default_args, schedule_interval=timedelta(days=1))
file_sensor_task = FileSensor(
task_id='file_sense',
filepath='/path/to/file',
poke_interval=300,
dag=dag)
dummy_task = DummyOperator(
task_id='dummy_task',
dag=dag)
file_sensor_task >> dummy_task
在这个例子中,FileSensor会每5分钟(300秒)检查一次指定的文件是否存在。只有当文件存在时,后续的dummy_task才会执行。
实际工作中的应用
在我的工作中,Airflow已经成为了处理复杂数据流的核心工具。这里我想分享一个实际的应用场景。
案例:构建数据湖ETL流程
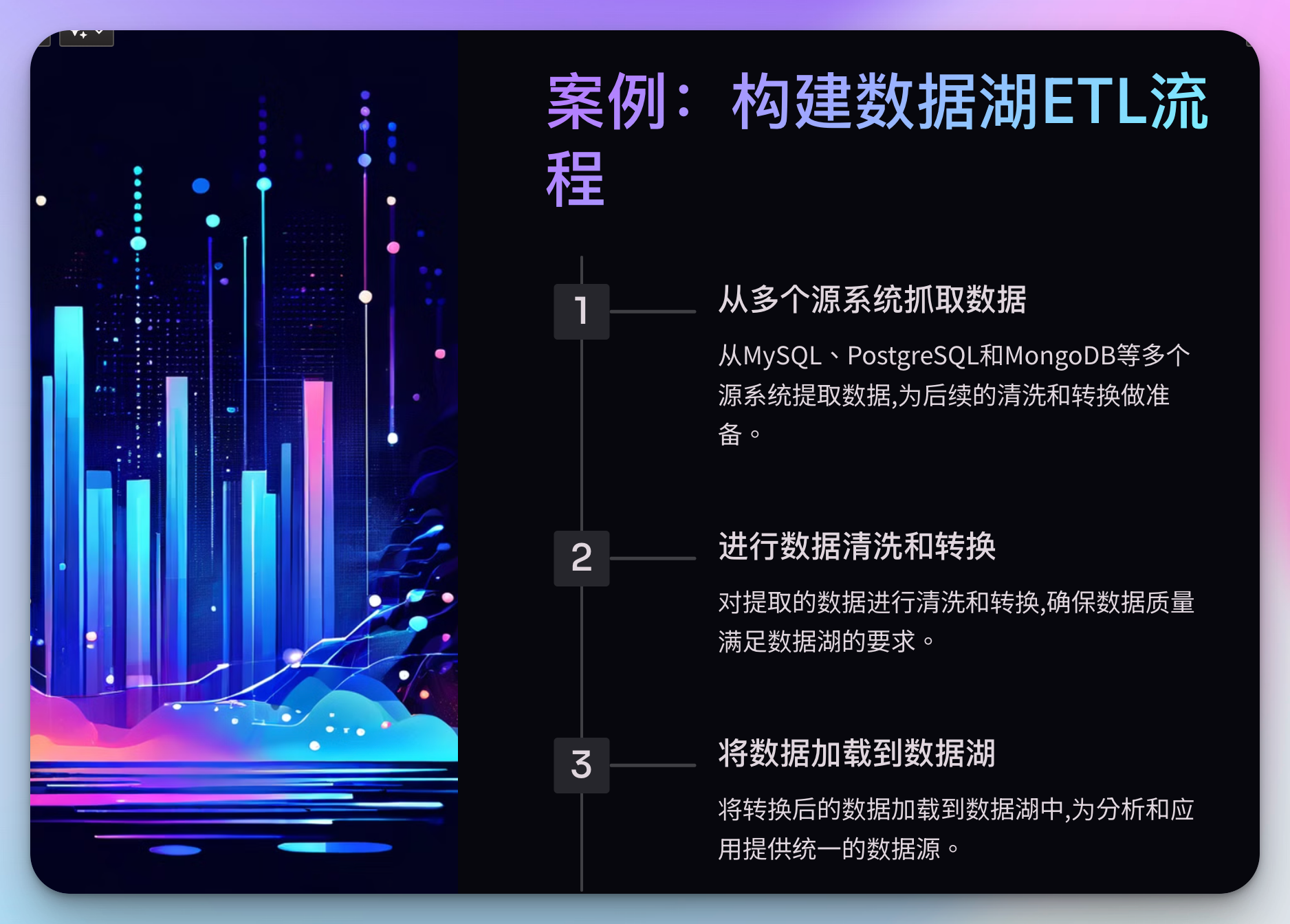
在一个大型数据湖项目中,我们需要从多个源系统抓取数据,进行清洗和转换,然后加载到数据湖中。这个过程涉及多个步骤,且每个数据源的处理逻辑略有不同。
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from airflow.sensors.external_task_sensor import ExternalTaskSensor
from datetime import datetime, timedelta
default_args = {
'owner': 'data_team',
'start_date': datetime(2024, 7, 20),
'retries': 3,
'retry_delay': timedelta(minutes=5),
}
dag = DAG('data_lake_etl', default_args=default_args, schedule_interval='@daily')
def extract(source, **kwargs):
# 模拟从源系统抓取数据
print(f"Extracting data from {source}")
def transform(**kwargs):
# 模拟数据转换过程
print("Transforming data")
def load(**kwargs):
# 模拟数据加载到数据湖
print("Loading data to data lake")
# 为每个数据源创建提取任务
sources = ['mysql', 'postgresql', 'mongodb']
extract_tasks = []
for source in sources:
task = PythonOperator(
task_id=f'extract_{source}',
python_callable=extract,
op_kwargs={'source': source},
dag=dag
)
extract_tasks.append(task)
# 转换任务
transform_task = PythonOperator(
task_id='transform',
python_callable=transform,
dag=dag
)
# 加载任务
load_task = PythonOperator(
task_id='load',
python_callable=load,
dag=dag
)
# 设置任务依赖
extract_tasks >> transform_task >> load_task
# 添加一个传感器,等待上游系统的数据准备就绪
upstream_sensor = ExternalTaskSensor(
task_id='wait_for_upstream',
external_dag_id='upstream_data_preparation',
external_task_id='data_ready',
dag=dag,
)
upstream_sensor >> extract_tasks
这个DAG展示了如何处理多个数据源的ETL过程。它包括等待上游数据准备、从多个源并行提取数据、转换数据和加载数据等步骤。这种结构使得整个流程更加清晰和可维护。
本节学习心得
-
从简单开始,逐步复杂化:即使在学习高级特性时,也要从简单的例子开始,然后逐步增加复杂度。
-
关注实际问题:学习新特性时,思考它如何解决你在工作中遇到的实际问题。这样可以加深理解并提高学习动力。
-
持续实践和优化:Airflow的学习是一个持续的过程。随着你对它的理解加深,不断回顾和优化你的DAG,使其更加高效和易维护。
-
参与社区:Airflow有一个活跃的开源社区。参与讨论、阅读他人的代码,甚至为项目贡献代码,都是提高技能的好方法。
-
保持好奇心:技术在不断发展,Airflow也在持续更新。保持对新特性和最佳实践的关注,这将帮助你在这个领域保持领先。
Airflow性能优化

在处理大规模数据流时,优化Airflow的性能变得尤为重要。以下是一些我在实践中总结的优化技巧:
1. 使用多线程或多进程执行器
默认的SequentialExecutor只能串行执行任务。在生产环境中,使用CeleryExecutor或KubernetesExecutor可以显著提高并行处理能力。
from airflow.executors.celery_executor import CeleryExecutor
# 在airflow.cfg中设置
executor = CeleryExecutor
2. 优化数据库访问
频繁的数据库访问可能成为性能瓶颈。使用SubDagOperator或TaskGroups可以减少数据库操作,提高性能。
from airflow.operators.subdag_operator import SubDagOperator
def subdag(parent_dag_name, child_dag_name, args):
dag_subdag = DAG(
dag_id=f'{parent_dag_name}.{child_dag_name}',
default_args=args,
schedule_interval="@daily",
)
# 定义子DAG的任务
# ...
return dag_subdag
subdag_task = SubDagOperator(
task_id='subdag_task',
subdag=subdag('parent_dag', 'child_dag', default_args),
dag=dag,
)
3. 使用池限制并发任务
使用池(Pool)可以限制特定资源的并发使用,避免过载。
from airflow.models.pool import Pool
# 在Airflow UI或通过命令行创建池
pool = Pool(
pool='my_resource_pool',
slots=5 # 最多同时运行5个任务
)
session.add(pool)
session.commit()
# 在任务中使用池
task = PythonOperator(
task_id='my_task',
python_callable=my_function,
pool='my_resource_pool',
dag=dag
)
与大数据生态系统集成

Airflow的强大之处在于它可以无缝集成各种大数据工具。以下是一些常见的集成场景:
1. 集成Spark
使用SparkSubmitOperator可以轻松地在Airflow中提交和管理Spark作业。
from airflow.providers.apache.spark.operators.spark_submit import SparkSubmitOperator
spark_task = SparkSubmitOperator(
task_id='spark_task',
application='/path/to/spark_job.py',
conn_id='spark_default',
dag=dag
)
2. 集成Hive
使用HiveOperator可以在Airflow中执行Hive查询。
from airflow.providers.apache.hive.operators.hive import HiveOperator
hive_task = HiveOperator(
task_id='hive_task',
hql='SELECT * FROM my_table',
hive_cli_conn_id='hive_cli_default',
dag=dag
)
3. 集成Hadoop
使用HDFSSensor可以检测HDFS上的文件是否存在。
from airflow.providers.apache.hdfs.sensors.hdfs import HdfsSensor
hdfs_sensor = HdfsSensor(
task_id='hdfs_sensor',
filepath='/user/hadoop/file',
hdfs_conn_id='hdfs_default',
poke_interval=5 * 60,
dag=dag
)
企业环境中的最佳实践

在企业环境中使用Airflow时,需要考虑更多的因素,如安全性、可维护性和可扩展性。以下是一些最佳实践:
1. 使用变量和连接
将敏感信息存储在Airflow的变量和连接中,而不是直接硬编码在DAG中。
from airflow.models import Variable
from airflow.hooks.base_hook import BaseHook
# 使用变量
api_key = Variable.get("api_key")
# 使用连接
conn = BaseHook.get_connection("my_conn_id")
2. 实现错误处理和告警
使用on_failure_callback函数来处理任务失败并发送告警。
from airflow.operators.python_operator import PythonOperator
from airflow.utils.email import send_email
def task_fail_alert(context):
subject = f"Airflow alert: {context['task_instance'].task_id} Failed"
body = f"Task {context['task_instance'].task_id} failed in DAG {context['dag'].dag_id}"
send_email(['alert@example.com'], subject, body)
task = PythonOperator(
task_id='my_task',
python_callable=my_function,
on_failure_callback=task_fail_alert,
dag=dag
)
3. 版本控制和CI/CD
将DAG文件纳入版本控制系统,并建立CI/CD流程以自动化部署过程。
# 示例:使用Git管理DAG文件
git init
git add dags/
git commit -m "Initial DAG files"
git push origin master
# 使用CI/CD工具(如Jenkins)自动部署DAG
jenkins_job:
stage('Deploy'):
- ssh user@airflow-server 'cd /path/to/airflow && git pull'
- ssh user@airflow-server 'airflow dags list'
4. 监控和日志管理
利用Airflow的内置UI进行监控,并考虑将日志集成到集中式日志管理系统(如ELK栈)中。
# 在airflow.cfg中配置日志
[core]
remote_logging = True
remote_log_conn_id = my_elasticsearch_conn
remote_base_log_folder = http://my-elasticsearch-cluster:9200/airflow/logs
本节学习心得
-
持续学习新特性:Airflow在不断发展,定期查看官方文档和release notes,了解新特性和改进。
-
构建可重用组件:随着你的Airflow使用经验增加,尝试构建可在多个DAG中重用的自定义组件。这不仅能提高效率,还能确保一致性。
-
性能调优是一个迭代过程:不要期望一次性解决所有性能问题。随着数据量和复杂度的增加,持续监控和优化你的DAG。
-
安全第一:在处理敏感数据或在生产环境中部署时,始终将安全性放在首位。利用Airflow提供的安全特性,如RBAC(基于角色的访问控制)。
-
拥抱开源社区:Airflow有一个活跃的开源社区。不要害怕提问、报告问题或贡献代码。这不仅能帮助你解决问题,还能提升你在社区中的地位。
高级调度功能

Airflow的调度功能远不止简单的定时执行。让我们探索一些高级调度技巧:
1. 动态调度
使用schedule_interval参数可以实现复杂的调度逻辑。
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime, timedelta
def dynamic_schedule():
# 根据当前日期动态决定调度间隔
now = datetime.now()
if now.weekday() < 5: # 周一到周五
return timedelta(hours=1)
else: # 周末
return timedelta(hours=4)
dag = DAG(
'dynamic_schedule_dag',
default_args={'start_date': datetime(2024, 7, 20)},
schedule_interval=dynamic_schedule,
catchup=False
)
def my_task():
print("Executing task")
task = PythonOperator(
task_id='my_task',
python_callable=my_task,
dag=dag
)
2. 基于依赖的调度
使用ExternalTaskSensor可以基于其他DAG的执行状态来触发当前DAG。
from airflow.sensors.external_task_sensor import ExternalTaskSensor
wait_for_other_dag = ExternalTaskSensor(
task_id='wait_for_other_dag',
external_dag_id='other_dag',
external_task_id='final_task',
mode='reschedule',
dag=dag
)
Airflow测试策略
测试是确保DAG可靠性的关键。以下是一些测试Airflow DAG的策略:
1. 单元测试
为每个任务编写单元测试,确保它们能够独立正确运行。
import unittest
from airflow.models import DagBag
class TestMyDAG(unittest.TestCase):
def setUp(self):
self.dagbag = DagBag()
def test_dag_loaded(self):
dag = self.dagbag.get_dag(dag_id='my_dag')
self.assertIsNotNone(dag)
self.assertEqual(len(dag.tasks), 3)
def test_task_python_operator(self):
dag = self.dagbag.get_dag(dag_id='my_dag')
task = dag.get_task('python_task')
self.assertIsInstance(task, PythonOperator)
self.assertEqual(task.python_callable, my_python_function)
if __name__ == '__main__':
unittest.main()
2. 集成测试
使用Airflow的测试模式运行整个DAG,检查任务间的依赖关系和数据流。
from airflow.utils.dag_cycle_tester import check_cycle
from airflow.models import DagBag
def test_dag_integrity():
dag_bag = DagBag(include_examples=False)
for dag_id, dag in dag_bag.dags.items():
check_cycle(dag) # 检查DAG中是否存在循环依赖
3. 模拟测试
使用mock库模拟外部依赖,测试DAG在各种情况下的行为。
from unittest.mock import patch
from airflow.models import DagBag
@patch('mymodule.external_api_call')
def test_external_task(mock_api):
mock_api.return_value = {'status': 'success'}
dag_bag = DagBag(include_examples=False)
dag = dag_bag.get_dag('my_dag')
task = dag.get_task('external_task')
task.execute(context={})
mock_api.assert_called_once()
复杂数据管道中的应用
在实际工作中,我们经常需要构建复杂的数据管道。让我们看一个更复杂的例子:
案例:多源数据集成与分析管道
假设我们需要从多个数据源收集数据,进行清洗和转换,然后进行分析和报告生成。
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from airflow.operators.bash_operator import BashOperator
from airflow.providers.apache.spark.operators.spark_submit import SparkSubmitOperator
from airflow.providers.apache.hive.operators.hive import HiveOperator
from airflow.providers.postgres.operators.postgres import PostgresOperator
from datetime import datetime, timedelta
default_args = {
'owner': 'data_team',
'depends_on_past': False,
'start_date': datetime(2024, 7, 20),
'email_on_failure': True,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
dag = DAG('complex_data_pipeline', default_args=default_args, schedule_interval='@daily')
# 1. 数据收集
collect_mysql = BashOperator(
task_id='collect_mysql',
bash_command='sqoop import --connect jdbc:mysql://mysql_server/db --table users',
dag=dag
)
collect_api = PythonOperator(
task_id='collect_api',
python_callable=fetch_api_data,
dag=dag
)
# 2. 数据清洗和转换
clean_transform = SparkSubmitOperator(
task_id='clean_transform',
application='/path/to/clean_transform_job.py',
conn_id='spark_default',
dag=dag
)
# 3. 数据加载到数据仓库
load_to_hive = HiveOperator(
task_id='load_to_hive',
hql='LOAD DATA INPATH "/cleaned_data" INTO TABLE cleaned_users',
dag=dag
)
# 4. 数据分析
analyze_data = SparkSubmitOperator(
task_id='analyze_data',
application='/path/to/analyze_job.py',
conn_id='spark_default',
dag=dag
)
# 5. 生成报告
generate_report = PostgresOperator(
task_id='generate_report',
sql='INSERT INTO reports SELECT * FROM analysis_results',
postgres_conn_id='postgres_default',
dag=dag
)
# 6. 发送通知
send_notification = PythonOperator(
task_id='send_notification',
python_callable=send_email_notification,
dag=dag
)
# 设置任务依赖
[collect_mysql, collect_api] >> clean_transform >> load_to_hive >> analyze_data >> generate_report >> send_notification
这个复杂的DAG展示了如何协调多个数据源、不同的处理步骤和多种技术栈。它包括数据收集、清洗、转换、分析和报告生成等步骤,涉及MySQL、API、Spark、Hive和PostgreSQL等多种技术。
进阶学习心得
-
掌握多种技术栈:Airflow常常是连接各种数据技术的枢纽。多了解一些常用的大数据技术(如Spark、Hive、Presto等)会让你在设计数据管道时更加得心应手。
-
关注数据质量:在设计数据管道时,考虑加入数据质量检查的步骤。可以使用Great Expectations等工具与Airflow集成,确保数据的准确性和一致性。
-
性能与可扩展性:随着数据量的增长,需要不断优化DAG的性能。学习如何有效地分区数据、并行处理任务,以及使用适当的执行器来提高处理能力。
-
监控与告警:建立全面的监控体系,包括任务执行时间、资源使用情况、失败率等。学习如何设置合适的告警阈值,以便及时发现和解决问题。
-
文档和知识共享:随着DAG复杂度的增加,良好的文档变得越来越重要。学会使用Airflow的文档字符串功能,为你的DAG和任务添加清晰的说明。
-
持续优化:数据管道是动态的,需要根据业务需求和数据特征不断调整。定期回顾和重构你的DAG,使其保持高效和可维护。
-
自动化测试和部署:随着项目规模的扩大,手动测试和部署变得不切实际。学习如何建立自动化的测试流程和CI/CD管道,以确保DAG的可靠性和快速迭代。
记住,即使在处理这些复杂的场景时,我们仍然要保持"糙快猛"的态度。先实现基本功能,然后逐步优化和完善。
Airflow高级特性

1. 动态DAG生成
在某些情况下,我们需要根据外部条件动态生成DAG。这可以通过Python代码实现:
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime, timedelta
def create_dag(dag_id, schedule, default_args):
dag = DAG(dag_id, schedule_interval=schedule, default_args=default_args)
def hello_task():
print(f"Hello from DAG {dag_id}")
with dag:
t1 = PythonOperator(
task_id="hello_task",
python_callable=hello_task,
)
return dag
# 动态生成多个DAG
for i in range(1, 4):
dag_id = f'dynamic_dag_{i}'
default_args = {
'owner': 'airflow',
'start_date': datetime(2024, 7, 20),
'retries': 1,
}
schedule = f'0 {i} * * *' # 每天在不同的小时执行
globals()[dag_id] = create_dag(dag_id, schedule, default_args)
2. 自定义操作器
创建自定义操作器可以封装特定的业务逻辑,提高代码复用性:
from airflow.models import BaseOperator
from airflow.utils.decorators import apply_defaults
class MyCustomOperator(BaseOperator):
@apply_defaults
def __init__(self, my_field, *args, **kwargs):
super().__init__(*args, **kwargs)
self.my_field = my_field
def execute(self, context):
print(f"Executing MyCustomOperator with {self.my_field}")
# 实现自定义逻辑
# 在DAG中使用
custom_task = MyCustomOperator(
task_id='custom_task',
my_field='custom value',
dag=dag
)
3. 任务分支
使用BranchPythonOperator可以根据条件选择执行路径:
from airflow.operators.python_operator import BranchPythonOperator
def branch_func(**kwargs):
if kwargs['execution_date'].day % 2 == 0:
return 'even_day_task'
else:
return 'odd_day_task'
branching = BranchPythonOperator(
task_id='branching',
python_callable=branch_func,
provide_context=True,
dag=dag
)
even_day_task = DummyOperator(task_id='even_day_task', dag=dag)
odd_day_task = DummyOperator(task_id='odd_day_task', dag=dag)
branching >> [even_day_task, odd_day_task]
实战最佳实践
1. 日志管理
配置远程日志存储可以方便地查看和分析历史日志:
# 在airflow.cfg中配置
[core]
remote_logging = True
remote_log_conn_id = my_aws_conn
remote_base_log_folder = s3://my-bucket/airflow/logs
# 在DAG中使用自定义日志
import logging
def my_task(**kwargs):
logger = logging.getLogger("airflow.task")
logger.info("这是一条自定义日志信息")
custom_log_task = PythonOperator(
task_id='custom_log_task',
python_callable=my_task,
dag=dag
)
2. 管理密钥和配置
使用Airflow的Variables和Connections来管理敏感信息:
from airflow.models import Variable
from airflow.hooks.base_hook import BaseHook
# 在Airflow UI或通过命令行设置变量和连接
# airflow variables set api_key my_secret_key
# airflow connections add --conn_id my_db --conn_type postgres ...
def use_secrets(**kwargs):
api_key = Variable.get("api_key")
db_conn = BaseHook.get_connection("my_db")
# 使用api_key和db_conn进行操作
secret_task = PythonOperator(
task_id='secret_task',
python_callable=use_secrets,
dag=dag
)
3. 大规模部署
在生产环境中,使用Celery或Kubernetes执行器可以提高扩展性:
# 在airflow.cfg中配置
[core]
executor = CeleryExecutor
[celery]
broker_url = redis://redis:6379/0
result_backend = db+postgresql://airflow:airflow@postgres/airflow
# 或者使用Kubernetes执行器
[core]
executor = KubernetesExecutor
[kubernetes]
worker_container_repository = my-registry/airflow-worker
worker_container_tag = latest
实际工作中的挑战与解决方案
挑战1:处理长时间运行的任务
解决方案:使用外部服务触发长时间任务,然后使用Sensor等待完成。
from airflow.operators.http_operator import SimpleHttpOperator
from airflow.sensors.http_sensor import HttpSensor
trigger_long_task = SimpleHttpOperator(
task_id='trigger_long_task',
http_conn_id='my_api',
endpoint='/start_long_task',
method='POST',
dag=dag
)
wait_for_completion = HttpSensor(
task_id='wait_for_completion',
http_conn_id='my_api',
endpoint='/task_status',
request_params={'task_id': '{{ task_instance.xcom_pull(task_ids="trigger_long_task") }}'},
response_check=lambda response: response.json()['status'] == 'completed',
poke_interval=60,
timeout=3600,
dag=dag
)
trigger_long_task >> wait_for_completion
挑战2:处理大量小任务
解决方案:使用SubDagOperator或TaskGroup来组织和管理大量相似的小任务。
from airflow.operators.subdag_operator import SubDagOperator
from airflow.utils.task_group import TaskGroup
def subdag_factory(parent_dag_name, child_dag_name, args):
dag = DAG(
f'{parent_dag_name}.{child_dag_name}',
default_args=args,
schedule_interval="@daily",
)
for i in range(5):
PythonOperator(
task_id=f'task_{i}',
python_callable=lambda: print(f"Executing task_{i}"),
dag=dag
)
return dag
subdag_task = SubDagOperator(
task_id='subdag_task',
subdag=subdag_factory('main_dag', 'subdag_task', default_args),
dag=dag
)
# 或者使用TaskGroup
with TaskGroup("task_group") as task_group:
for i in range(5):
PythonOperator(
task_id=f'task_{i}',
python_callable=lambda: print(f"Executing task_{i}"),
dag=dag
)
挑战3:数据质量管理
解决方案:集成数据质量检查工具,如Great Expectations。
from airflow.operators.python_operator import PythonOperator
from great_expectations_provider.operators.great_expectations import GreatExpectationsOperator
validate_data = GreatExpectationsOperator(
task_id='validate_data',
expectation_suite_name="my_suite",
batch_kwargs={
"datasource": "my_datasource",
"data_asset_name": "my_table",
},
dag=dag
)
def handle_validation_result(**kwargs):
if kwargs['ti'].xcom_pull(task_ids='validate_data'):
print("数据验证通过")
else:
raise Exception("数据验证失败")
handle_result = PythonOperator(
task_id='handle_result',
python_callable=handle_validation_result,
provide_context=True,
dag=dag
)
validate_data >> handle_result
本节学习心得
-
持续学习新特性:Airflow的生态系统在不断发展,定期查看官方文档和社区动态,了解新的功能和最佳实践。
-
参与开源社区:尝试为Airflow项目贡献代码或文档。这不仅能提升你的技能,还能获得宝贵的反馈和经验。
-
关注性能优化:随着DAG数量和复杂度的增加,性能优化变得越来越重要。学习如何使用不同的执行器、优化数据库访问、合理设置并发等。
-
自动化运维:探索如何自动化Airflow的部署、升级和日常运维工作。学习使用容器技术和CI/CD流程来简化这些任务。
-
跨团队协作:在实际工作中,Airflow常常是连接数据工程、数据科学和业务团队的桥梁。学习如何有效地与不同背景的同事协作,共同设计和优化数据管道。
-
安全性考虑:随着数据的敏感性增加,了解如何在Airflow中实现细粒度的访问控制、数据加密等安全措施变得越来越重要。
-
灾难恢复和高可用性:学习如何设计和实现Airflow的灾难恢复方案,确保在各种故障情况下仍能保持服务的可用性。
高级应用场景
1. 机器学习工作流
Airflow可以用来编排复杂的机器学习工作流,包括数据准备、模型训练、评估和部署。
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from airflow.providers.amazon.aws.operators.sagemaker_training import SageMakerTrainingOperator
from airflow.providers.amazon.aws.operators.sagemaker_model import SageMakerModelOperator
from airflow.providers.amazon.aws.operators.sagemaker_endpoint import SageMakerEndpointOperator
def prepare_data(**kwargs):
# 数据准备逻辑
pass
def evaluate_model(**kwargs):
# 模型评估逻辑
pass
with DAG('ml_workflow', schedule_interval='@daily', default_args=default_args) as dag:
prepare_data_task = PythonOperator(
task_id='prepare_data',
python_callable=prepare_data
)
train_model = SageMakerTrainingOperator(
task_id='train_model',
config={
"AlgorithmSpecification": {
"TrainingImage": "{{ task_instance.xcom_pull(task_ids='prepare_data', key='training_image') }}",
"TrainingInputMode": "File"
},
"HyperParameters": {
"epochs": "10",
"batch-size": "128"
},
"InputDataConfig": [
{
"ChannelName": "train",
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": "{{ task_instance.xcom_pull(task_ids='prepare_data', key='training_data') }}"
}
}
}
],
"OutputDataConfig": {
"S3OutputPath": "s3://my-bucket/output"
},
"ResourceConfig": {
"InstanceCount": 1,
"InstanceType": "ml.m5.large",
"VolumeSizeInGB": 5
},
"RoleArn": "{{ task_instance.xcom_pull(task_ids='prepare_data', key='role_arn') }}",
"StoppingCondition": {
"MaxRuntimeInSeconds": 86400
},
"TrainingJobName": "{{ task_instance.task_id }}-{{ ds_nodash }}"
}
)
create_model = SageMakerModelOperator(
task_id='create_model',
config={
"ExecutionRoleArn": "{{ task_instance.xcom_pull(task_ids='prepare_data', key='role_arn') }}",
"ModelName": "{{ task_instance.task_id }}-{{ ds_nodash }}",
"PrimaryContainer": {
"Image": "{{ task_instance.xcom_pull(task_ids='prepare_data', key='inference_image') }}",
"ModelDataUrl": "{{ task_instance.xcom_pull(task_ids='train_model', key='model_artifact') }}"
}
}
)
deploy_model = SageMakerEndpointOperator(
task_id='deploy_model',
operation='create',
wait_for_completion=True,
config={
"EndpointConfigName": "{{ task_instance.task_id }}-{{ ds_nodash }}",
"EndpointName": "{{ task_instance.task_id }}-{{ ds_nodash }}",
"ProductionVariants": [
{
"InitialInstanceCount": 1,
"InstanceType": "ml.t2.medium",
"ModelName": "{{ task_instance.xcom_pull(task_ids='create_model', key='model_name') }}",
"VariantName": "AllTraffic"
}
]
}
)
evaluate_model_task = PythonOperator(
task_id='evaluate_model',
python_callable=evaluate_model
)
prepare_data_task >> train_model >> create_model >> deploy_model >> evaluate_model_task
2. 数据湖构建
使用Airflow构建和维护数据湖,包括数据摄取、转换和组织。
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from airflow.providers.amazon.aws.transfers.sql_to_s3 import SqlToS3Operator
from airflow.providers.amazon.aws.transfers.s3_to_redshift import S3ToRedshiftOperator
def process_data(**kwargs):
# 数据处理逻辑
pass
with DAG('data_lake_etl', schedule_interval='@daily', default_args=default_args) as dag:
extract_from_mysql = SqlToS3Operator(
task_id='extract_from_mysql',
query='SELECT * FROM users WHERE created_at = {{ ds }}',
s3_bucket='my-data-lake',
s3_key='raw/users/{{ ds }}/users.csv',
sql_conn_id='mysql_conn',
aws_conn_id='aws_default'
)
process_data_task = PythonOperator(
task_id='process_data',
python_callable=process_data
)
load_to_redshift = S3ToRedshiftOperator(
task_id='load_to_redshift',
schema='public',
table='users',
s3_bucket='my-data-lake',
s3_key='processed/users/{{ ds }}/users.csv',
copy_options=['CSV', 'IGNOREHEADER 1'],
redshift_conn_id='redshift_conn',
aws_conn_id='aws_default'
)
extract_from_mysql >> process_data_task >> load_to_redshift
性能调优技巧
1. 使用Pools限制并发
使用Pools可以限制特定资源的并发使用,避免过载。
from airflow.models.pool import Pool
from airflow.operators.python_operator import PythonOperator
# 创建一个pool
pool = Pool(
pool='resource_pool',
slots=5
)
session.add(pool)
session.commit()
def resource_intensive_task(**kwargs):
# 一些消耗资源的操作
pass
resource_task = PythonOperator(
task_id='resource_task',
python_callable=resource_intensive_task,
pool='resource_pool',
dag=dag
)
2. 优化数据库访问
使用集中式缓存来减少数据库访问。
from airflow.models import Variable
from airflow.hooks.base_hook import BaseHook
from cached_property import cached_property
class OptimizedVariableAccessor:
@cached_property
def get_variable(self):
return Variable.get("my_variable")
@cached_property
def get_connection(self):
return BaseHook.get_connection("my_conn")
optimized_accessor = OptimizedVariableAccessor()
def my_task(**kwargs):
value = optimized_accessor.get_variable
conn = optimized_accessor.get_connection
# 使用value和conn
3. 使用Celery Executor提高并行性
在airflow.cfg中配置Celery Executor:
executor = CeleryExecutor
broker_url = redis://redis:6379/0
result_backend = db+postgresql://airflow:airflow@postgres/airflow
然后在DAG中设置适当的并行度:
default_args = {
'owner': 'airflow',
'start_date': datetime(2024, 7, 20),
'retries': 1,
'retry_delay': timedelta(minutes=5),
'pool': 'default_pool',
'queue': 'default',
}
with DAG('optimized_dag', default_args=default_args, concurrency=20, max_active_runs=5) as dag:
# DAG tasks
与其他大数据工具的集成
1. 集成Apache Spark
使用SparkSubmitOperator提交Spark作业。
from airflow.providers.apache.spark.operators.spark_submit import SparkSubmitOperator
spark_job = SparkSubmitOperator(
task_id='spark_job',
application='/path/to/spark_job.py',
conn_id='spark_default',
conf={
"spark.executor.memory": "2g",
"spark.executor.cores": "2"
},
dag=dag
)
2. 集成Apache Kafka
使用自定义操作器与Kafka交互。
from airflow.models import BaseOperator
from airflow.utils.decorators import apply_defaults
from kafka import KafkaProducer
class KafkaPublishOperator(BaseOperator):
@apply_defaults
def __init__(self, topic, message, kafka_config, *args, **kwargs):
super().__init__(*args, **kwargs)
self.topic = topic
self.message = message
self.kafka_config = kafka_config
def execute(self, context):
producer = KafkaProducer(**self.kafka_config)
producer.send(self.topic, self.message.encode('utf-8'))
producer.flush()
publish_to_kafka = KafkaPublishOperator(
task_id='publish_to_kafka',
topic='my_topic',
message='Hello, Kafka!',
kafka_config={'bootstrap_servers': ['localhost:9092']},
dag=dag
)
3. 集成Apache Hadoop
使用HDFSOperator与HDFS交互。
from airflow.providers.apache.hdfs.operators.hdfs import HdfsOperator
hdfs_put = HdfsOperator(
task_id='hdfs_put',
hdfs_conn_id='hdfs_default',
source_local_path='/path/to/local/file',
target_hdfs_path='/path/in/hdfs',
operation='put',
dag=dag
)
本节学习心得
-
深入理解Airflow的内部机制:了解Airflow的调度器、执行器和元数据数据库是如何协同工作的,这将有助于你更好地优化和troubleshoot你的DAG。
-
构建可重用的组件:随着你的Airflow使用经验增加,尝试构建自定义的操作器、钩子和传感器。这不仅能提高效率,还能确保团队内的一致性。
-
性能调优是一个持续的过程:随着数据量和DAG复杂度的增加,持续监控和优化性能变得越来越重要。学习使用Airflow的指标和日志来识别瓶颈。
-
安全性和合规性:在处理敏感数据时,深入了解Airflow的安全特性,如细粒度的访问控制和数据加密。确保你的Airflow部署符合相关的数据保护法规。
-
拥抱云原生:随着云计算的普及,学习如何在云环境中部署和管理Airflow变得越来越重要。探索诸如AWS MWAA、Google Cloud Composer等托管服务。
-
与数据科学工作流集成:学习如何使用Airflow来编排和管理数据科学工作流,包括特征工程、模型训练和部署。这将使你成为连接数据工程和数据科学的桥梁。
-
持续学习新特性:Airflow生态系统正在快速发展。定期查看官方文档、博客和社区讨论,了解新特性和最佳实践。
记住,即使在面对这些高级主题时,我们仍然要保持"糙快猛"的态度。先实现基本功能,然后逐步优化和完善。
高级架构设计

在企业级环境中,Airflow的架构设计需要考虑可扩展性、高可用性和安全性。以下是一些高级架构设计的考虑因素:
1. 多集群部署
对于大型企业,可能需要部署多个Airflow集群以支持不同的业务单元或数据隔离要求。
# 在不同的集群中使用相同的DAG,但连接到不同的数据源
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime, timedelta
def process_data(**kwargs):
cluster = kwargs['dag'].params['cluster']
conn = get_connection(f"{cluster}_db")
# 处理特定集群的数据
print(f"Processing data for {cluster}")
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2024, 7, 20),
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
for cluster in ['finance', 'marketing', 'operations']:
dag_id = f'data_processing_{cluster}'
with DAG(dag_id, default_args=default_args, schedule_interval='@daily', params={'cluster': cluster}) as dag:
process_task = PythonOperator(
task_id='process_data',
python_callable=process_data,
provide_context=True,
)
2. 细粒度的访问控制
实现基于角色的访问控制(RBAC)以确保数据安全和合规性。
# 在airflow.cfg中启用RBAC
[webserver]
rbac = True
# 在DAG中使用访问控制
from airflow import DAG
from airflow.models import DagBag
from airflow.security import permissions
from airflow.www.security import AirflowSecurityManager
def has_access(user, dag_id, permission):
security_manager = AirflowSecurityManager()
return security_manager.has_access(permission, dag_id, user)
dag = DAG('secure_dag', default_args=default_args, schedule_interval='@daily')
if has_access(current_user, dag.dag_id, permissions.ACTION_CAN_READ):
# 执行DAG逻辑
else:
raise AirflowException("未授权访问")
3. 动态DAG生成
使用动态DAG生成来处理大量相似的工作流。
import os
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
def create_dag(dag_id, schedule, default_args):
def hello_world():
print(f"Hello from {dag_id}")
dag = DAG(dag_id, schedule_interval=schedule, default_args=default_args)
with dag:
t1 = PythonOperator(
task_id='hello_world',
python_callable=hello_world,
)
return dag
# 从配置文件或数据库动态读取DAG配置
dag_configs = [
{'id': 'dag_1', 'schedule': '@daily'},
{'id': 'dag_2', 'schedule': '@hourly'},
# ... 更多配置
]
for config in dag_configs:
dag_id = f'dynamic_dag_{config["id"]}'
default_args = {
'owner': 'airflow',
'start_date': datetime(2024, 7, 20),
}
globals()[dag_id] = create_dag(dag_id, config['schedule'], default_args)
故障排除技巧

在复杂的生产环境中,故障排除是一项关键技能。以下是一些高级故障排除技巧:
1. 高级日志分析
使用ELK栈(Elasticsearch, Logstash, Kibana)或类似工具进行集中式日志管理和分析。
# 在airflow.cfg中配置远程日志
[core]
remote_logging = True
remote_log_conn_id = my_elasticsearch_connection
remote_base_log_folder = http://my-elasticsearch-cluster:9200/airflow/logs
# 在DAG中使用结构化日志
import json
import logging
def structured_logging(**kwargs):
logger = logging.getLogger("airflow.task")
log_data = {
"task_id": kwargs['task'].task_id,
"dag_id": kwargs['dag'].dag_id,
"execution_date": kwargs['execution_date'].isoformat(),
"custom_field": "some value"
}
logger.info(json.dumps(log_data))
task = PythonOperator(
task_id='structured_logging_task',
python_callable=structured_logging,
provide_context=True,
dag=dag
)
2. 任务重试策略
实现智能重试策略以处理间歇性故障。
from airflow.operators.python_operator import PythonOperator
from airflow.utils.decorators import apply_defaults
class SmartRetryOperator(PythonOperator):
@apply_defaults
def __init__(self, max_retry_delay=timedelta(minutes=60), *args, **kwargs):
super().__init__(*args, **kwargs)
self.max_retry_delay = max_retry_delay
def execute(self, context):
try:
return super().execute(context)
except Exception as e:
if context['ti'].try_number <= self.retries:
retry_delay = min(2 ** (context['ti'].try_number - 1) * self.retry_delay, self.max_retry_delay)
self.retry(context['ti'].try_number, retry_delay)
else:
raise e
smart_retry_task = SmartRetryOperator(
task_id='smart_retry_task',
python_callable=some_function,
retries=5,
retry_delay=timedelta(minutes=5),
max_retry_delay=timedelta(hours=2),
dag=dag
)
3. 任务监控和告警
实现自定义的监控和告警机制。
from airflow.models import TaskInstance
from airflow.utils.email import send_email
from airflow.operators.python_operator import PythonOperator
def monitor_task_duration(task_id, dag_id, threshold_minutes):
ti = TaskInstance.find(task_id=task_id, dag_id=dag_id).order_by(TaskInstance.execution_date.desc()).first()
if ti and (ti.end_date - ti.start_date).total_seconds() / 60 > threshold_minutes:
send_email(
to='alert@example.com',
subject=f'Task {task_id} in DAG {dag_id} exceeded duration threshold',
html_content=f'Task took {(ti.end_date - ti.start_date).total_seconds() / 60} minutes'
)
monitor_task = PythonOperator(
task_id='monitor_task_duration',
python_callable=monitor_task_duration,
op_args=['some_task', 'some_dag', 60], # 监控 'some_task' 是否超过 60 分钟
dag=dag
)
企业级最佳实践

在大规模企业环境中使用Airflow时,以下是一些最佳实践:
1. 版本控制和 CI/CD
将DAG代码纳入版本控制,并实现 CI/CD 流程。
# .gitlab-ci.yml 示例
stages:
- test
- deploy
test_dags:
stage: test
script:
- python -m pytest tests/
deploy_dags:
stage: deploy
script:
- rsync -avz --delete dags/ airflow_server:/path/to/airflow/dags/
only:
- master
2. 数据质量检查
在 DAG 中集成数据质量检查。
from airflow.operators.python_operator import PythonOperator
from great_expectations_provider.operators.great_expectations import GreatExpectationsOperator
def check_data_quality(**kwargs):
# 执行数据质量检查
pass
data_quality_check = GreatExpectationsOperator(
task_id='data_quality_check',
expectation_suite_name='my_suite',
data_asset_name='my_table',
batch_kwargs={
'table': 'my_table',
'datasource': 'my_datasource'
},
dag=dag
)
process_data = PythonOperator(
task_id='process_data',
python_callable=process_data,
dag=dag
)
data_quality_check >> process_data
3. 资源管理
使用 Kubernetes 执行器来动态分配资源。
# 在 airflow.cfg 中配置
executor = KubernetesExecutor
# 在 DAG 中使用
from airflow.contrib.operators.kubernetes_pod_operator import KubernetesPodOperator
k8s_task = KubernetesPodOperator(
namespace='default',
image="python:3.8-slim-buster",
cmds=["python","-c"],
arguments=["print('hello world')"],
labels={"foo": "bar"},
name="airflow-test-pod",
task_id="task-two",
in_cluster=True, # 如果 Airflow 运行在 Kubernetes 集群内
cluster_context='docker-desktop', # 如果 Airflow 运行在集群外
is_delete_operator_pod=True,
get_logs=True,
dag=dag
)
最后的总结-思维导图
感谢你看到最后,这篇 Airflow 的系统学习之路,如果遇到相关的问题,可以查询~
最后总结一下在这整个过程中我们需要具备的

另外