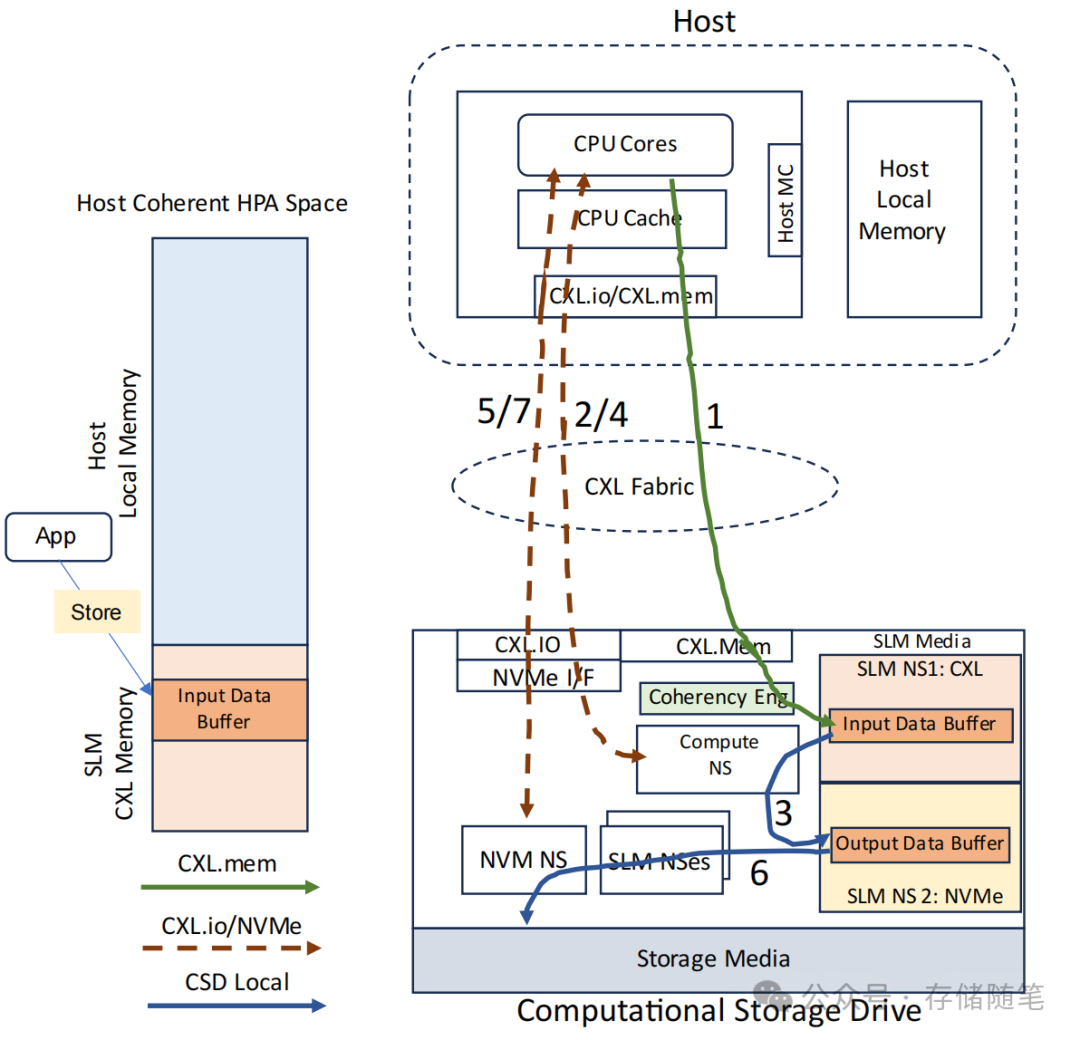
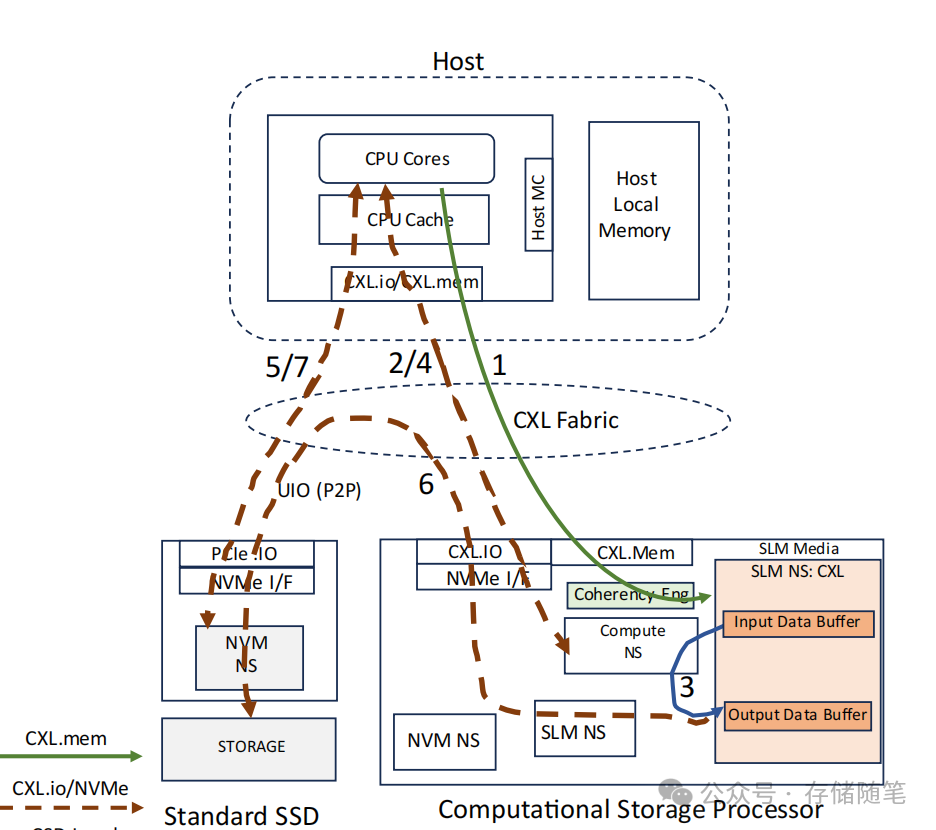
场景1:数据写入之前
目标是避免数据从存储设备传输到主机内存再返回存储设备的传统过程中的数据搬运成本。通过利用CXL和NVMe技术的结合,可以在存储层直接对数据进行处理,即所谓的计算存储(Computational Storage)。这特别适用于那些需要对数据进行快速处理然后存储的场景,比如数据压缩、加密、过滤等。
操作步骤:
-
数据准备:应用程序使用CXL.mem指令直接将输入数据写入到位于SLM(Subsystem Local Memory,子系统本地内存)的CXL内存地址空间中的输入数据缓冲区。这个缓冲区可能是计算存储设备内部的一部分,且某些数据可能在操作完成时驻留在主机缓存中。
-
计算任务触发:主机向计算命名空间(Compute NS)发送NVMe Execute Program命令,指示计算单元执行特定的计算任务。计算单元直接在SLM中的输入数据缓冲区上操作,不需要将数据移动到主机内存中。
-
数据处理:计算NS基于输入数据执行计算任务,并将处理结果存储到同样位于SLM的输出数据缓冲区中。这一过程中,CXL BI Snoop协议确保了主机缓存与输入/输出缓冲区之间的一致性,即保证了数据的最新状态。
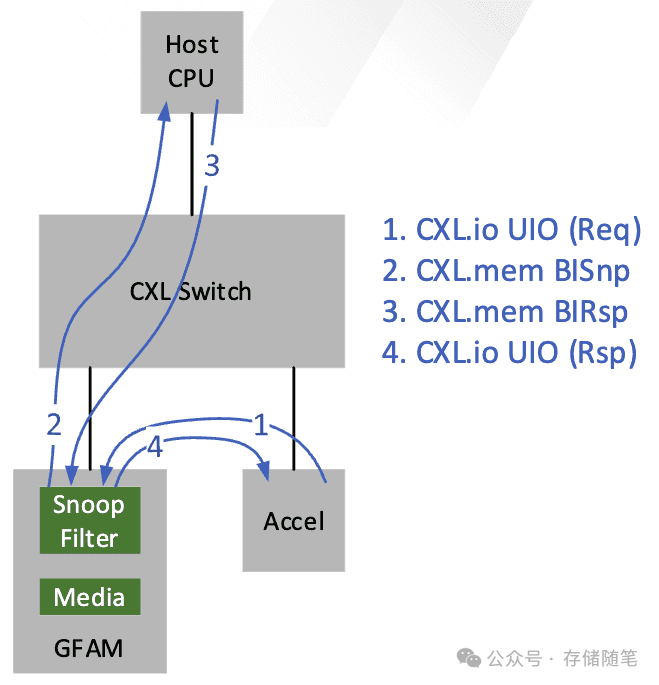
Back Invalidate Snoop:在CXL架构下,为了保持内存一致性,特别是对于共享CXL内存资源的情况,Back Invalidate Snoop 是一种CXL 3.0新引入的请求类型。当从属的CXL内存设备(如SSD或其他带有CXL.mem接口的存储设备)需要更新自身的内存缓存副本时,它可以发起Back Invalidate Snoop 请求,直接向Home Agent或者其他持有最新数据的设备请求更新一致性状态。通过这种方式,CXL设备能够在不经过Root Complex的情况下自行发起并完成一致性状态的更新,有效地解除了对上游CXL通道的拥堵,同时降低了遍历延迟。
详细扩展阅读:浅析CXL P2P DMA加速数据传输的原理
-
完成通知:计算完成后,会为计算NS发布完成队列消息(Completion Queue Entry, CQE),通知主机任务已完成。
-
数据持久化:主机接着发出NVMe Copy命令,将输出数据缓冲区中的数据直接复制到存储媒体中。由于输出缓冲区位于CXL HDM(Host-Directed Memory)空间内,使用PCIe UIO(User-Initiated I/O)实现点对点(P2P)直接从HDM空间写入存储介质,进一步减少数据移动。
-
最终确认:当数据写入存储媒体后,NVM Namespace会发布另一个CQE,确认数据已成功写入。
应用价值:
-
减少数据搬运:绕过主机内存的数据移动,直接在计算存储设备内部处理数据,显著降低了数据迁移的开销和延迟。
-
提高效率:对于小规模数据尤其有效,CXL直接加载/存储访问提供了比传统PCIe更高效的路径。
-
优化系统性能:通过保持数据的内存一致性,确保了所有设备对共享数据的视图是一致的,提升了整体系统的响应速度和可靠性。
通过计算存储的机制,有效提升了数据处理的效率,减少了数据搬运的需求,进而优化了存储和计算资源的利用率。这对于需要即时处理和存储大量数据的应用场景,如大数据分析、物联网边缘计算等,具有重要价值。
场景2: 数据预处理
该场景聚焦于数据预处理的场景,发生在数据被发送到主机之前。这一用例充分利用了CXL和SLM内存的特点,以实现数据处理的低延迟和高效性。
那些需要在数据被主机正式接收和进一步处理前,进行快速预处理或筛选的场景。例如,在边缘计算或实时数据分析中,可能需要对传感器收集的原始数据进行初步处理,以提取关键信息或过滤无关数据,然后再将处理后的数据发送给主机应用进行深入分析或存储。通过这种方式,系统能够在数据流经系统时即时处理,减少不必要的数据传输量,优化网络和计算资源的使用,同时加快数据处理的响应时间。
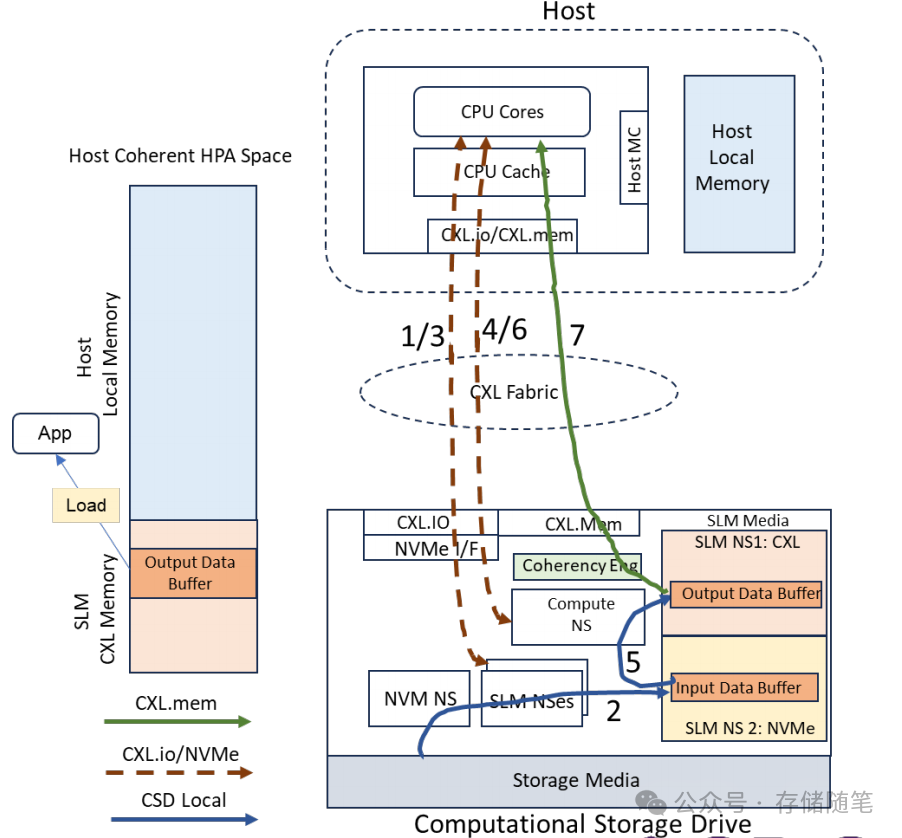
操作步骤
-
数据传输至SLM:主机发起NVMe Memory Copy命令,将NVM NS中的数据复制到SLM的输入数据缓冲区。这一步骤完成后,相应的完成队列信息(CQE)会被发布。
-
-
输入数据缓冲区:位于SLM内存中,数据从NVM NS通过NVMe Memory Copy命令被复制至此。
-
输出数据缓冲区:设置在SLM的CXL内存地址空间,用于存放处理后的结果。
-
-
计算任务执行:随后,主机向计算命名空间(Compute NS)发送NVMe Execute Program命令,触发计算单元在输入数据缓冲区上的操作,并将处理结果直接写入到输出数据缓冲区中。此过程中,CXL BI Snoop协议确保了主机缓存与输出数据缓冲区间的内存一致性。
-
结果读取:处理完毕后,应用程序通过CXL.mem指令读取输出数据缓冲区中的数据,完成数据预处理流程。
应用价值
-
避免数据搬运:通过直接在SLM内存中处理数据,该用例避免了使用DMA技术在主机内存和外设之间来回拷贝数据的需要,从而减少了数据移动的延迟和系统负担。
-
低延迟访问:利用CXL.mem提供的直接加载/存储访问能力,特别是对于小规模输出数据,能够显著降低访问延迟,提升数据处理速度。
-
内存一致性:通过CXL协议,确保了计算存储设备与主机内存间的数据一致性,维持了数据的最新状态,无需额外同步步骤。
场景3: 计算卸载
该场景关注的是“计算卸载”(Compute Offload),利用CXL和NVMe技术结合,实现高效数据处理和计算任务。特别适合于那些对数据处理速度有严格要求、且需要实时或近实时处理的场景,例如金融交易系统中的实时风险评估、视频监控系统的即时分析、或是IoT设备中的边缘计算应用。通过计算卸载,系统能够快速响应,减少数据传输延迟,提升整体处理能力,同时减轻主机CPU的负载压力。
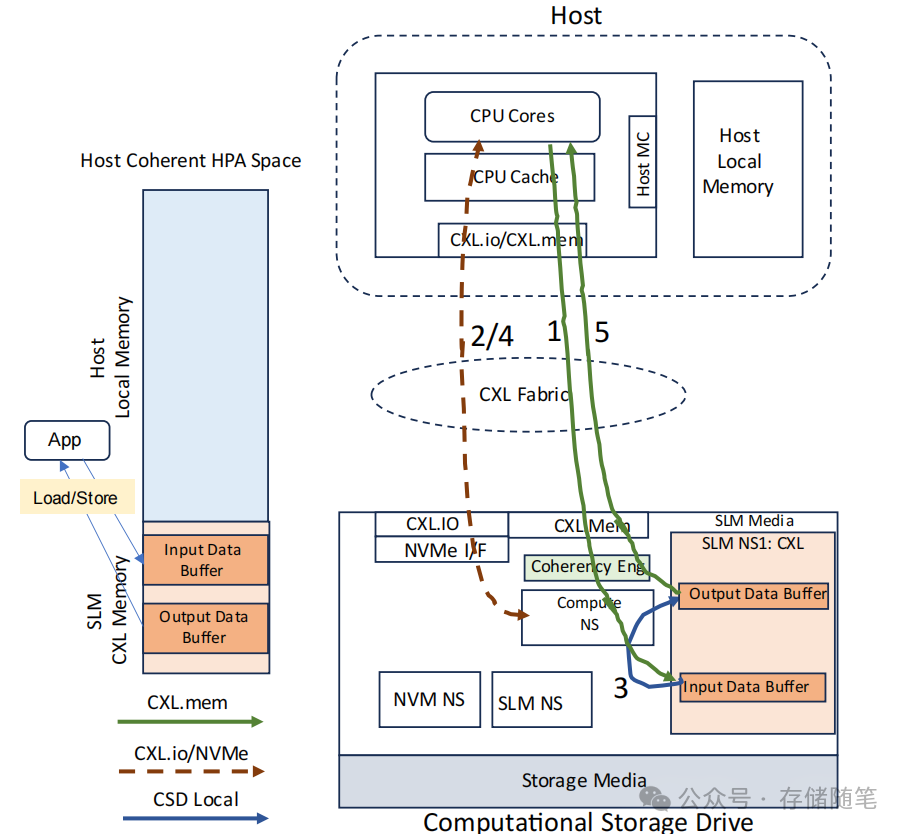
操作步骤
-
应用写入输入数据:应用程序通过CXL.mem接口直接写入输入数据缓冲区。部分或全部数据可能在写入完成后暂存于主机缓存中。
-
执行计算任务:主机向计算命名空间(Compute NS)发出NVMe Execute Program命令,指示计算设备对输入数据缓冲区中的数据进行操作,并将结果存储到输出数据缓冲区。使用CXL BI Snoop协议来确保主机缓存与输入数据缓冲区及输出数据缓冲区间的数据一致性。
-
完成通知:计算任务完成后,会为Compute NS发布完成队列消息(CQE)。
-
应用读取输出数据:应用程序通过CXL.mem接口读取输出数据缓冲区中的结果数据,完成计算任务的整个流程。
应用价值
-
避免数据搬运至主机内存:通过将计算任务直接在计算存储设备上执行,避免了传统方式下数据从存储介质到主机内存的频繁搬运,降低了系统瓶颈和延迟。
-
直接访问降低延迟:CXL支持的直接加载/存储(ld/st)访问,特别是对于小规模的输入/输出数据,极大地缩短了访问时间,提高了整体处理效率。
-
通用计算卸载:允许将一般性的计算任务从主机CPU转移到计算存储设备上执行,释放CPU资源,增强系统整体性能和响应速度。
场景4:在线购物
在电子商务日益普及的今天,提供一个高效、安全、愉悦的在线购物体验对于电商平台至关重要。该场景聚焦于用户端的互动流程,确保平台能满足不同用户群体的需求,提高转化率和用户满意度。面临的技术与实施挑战主要有:
-
技术实现:如何高效地处理大量并发请求,保证系统稳定性,以及如何优化搜索引擎,提升搜索效率和准确性。
-
数据处理:如何有效管理和分析海量用户行为数据,以支持个性化推荐算法。
-
用户体验优化:持续迭代产品设计,根据用户反馈调整功能,保持平台的吸引力。
应用步骤
1. 数据采集与预处理
-
数据接收:数据从各种源头(如传感器、日志文件等)收集,通过高速网络传入平台。
-
CXL加速的预处理:使用CXL连接的加速器(如FPGA或GPU),直接对数据进行初步清洗、格式化。CXL的高带宽和低延迟特性确保了数据在预处理阶段的快速流转。
2. 数据存储与缓存
-
NVMe SSD存储:原始数据和预处理后的数据存储在NVMe SSD上,利用NVMe的高速读写能力,加快数据存取速度。
-
CXL内存缓存:热点数据或待处理数据被缓存在CXL内存中,CXL的直接加载/存储访问功能(ld/st)使得数据访问速度极快,减少了数据从存储到计算资源的传输延迟。
3. 并行计算与分析
-
CXL互联加速:计算节点(如服务器)通过CXL互联,实现高速的内存一致性数据共享。计算节点直接访问CXL内存中的数据,进行并行处理和分析,无需频繁地与主内存交换数据。
-
计算卸载:特定的分析任务通过CXL连接的计算存储设备(如CXL附加的智能SSD)进行卸载,这些设备可以在数据存储位置直接执行计算,减少数据移动,进一步提升效率。
4. 结果聚合与反馈
-
CXL数据交换:各计算节点的处理结果通过CXL高速网络汇聚到中心节点,进行结果的汇总与分析。
-
即时反馈:基于聚合结果,系统通过CXL快速访问的内存区域,即时生成分析报告或触发相关行动,如自动调整策略、预警通知等。
尽管CXL与NVMe的结合前景广阔,但实际应用中仍面临一些挑战,包括但不限于软件栈的优化、计算资源的分配与管理、以及确保数据一致性和安全性。随着技术成熟,行业需要开发更加智能的资源调度算法,以及完善相应的编程模型和工具链,以简化应用开发和部署。
总之,CXL与NVMe的协作开启了计算存储的新篇章,为解决大数据时代的数据处理难题提供了强大的技术支撑。随着技术的不断演进,我们有理由相信,未来计算存储将更广泛地应用于各类高性能计算场景,推动数据处理进入一个全新的高效时代。
参考文献:SNIA-RSDC24-Molgaard-CXL-NVMe-Collaborating-for-Computation.pdf
如果您看完有所受益,欢迎点击文章底部左下角“关注”并点击“分享”、“在看”,非常感谢!
精彩推荐:
-
浅析SSD性能与NAND速率的关联
-
MCR DIMM如何解决内存带宽瓶颈?
-
浅析MPS对PCIe系统稳定性的影响
-
DPU:值不值得托付下一代存储加速架构?
-
论文解读|数据中心内存RAS技术全景剖析
-
硬盘HDD:AI时代的战略金矿?
-
断电的固态硬盘数据能放多久?
-
CXL-GPU: 全球首款实现百ns以内的低延迟CXL解决方案
-
万字长文|下一代系统内存数据加速接口SDXI解读
-
数据中心:AI范式下的内存挑战与机遇
-
WDC西部数据闪存业务救赎之路,会成功吗?
-
属于PCIe 7.0的那道光来了~
-
深度剖析:AI存储架构的挑战与解决方案
-
浅析英伟达GPU NCCL P2P与共享内存
-
3D NAND原厂:哪家芯片存储效率更高?
-
大厂阿里、字节、腾讯都在关注这个事情!
-
磁带存储:“不老的传说”依然在继续
-
浅析3D NAND多层架构的可靠性问题
-
SSD LDPC软错误探测方案解读
-
关于SSD LDPC纠错能力的基础探究
-
存储系统如何规避数据静默错误?
-
PCIe P2P DMA全景解读
-
深度解读NVMe计算存储协议
-
浅析不同NAND架构的差异与影响
-
SSD基础架构与NAND IO并发问题探讨
-
字节跳动ZNS SSD应用案例解析
-
CXL崛起:2024启航,2025年开启新时代
-
NVMe SSD:ZNS与FDP对决,你选谁?
-
浅析PCI配置空间
-
浅析PCIe系统性能
-
存储随笔《NVMe专题》大合集及PDF版正式发布!