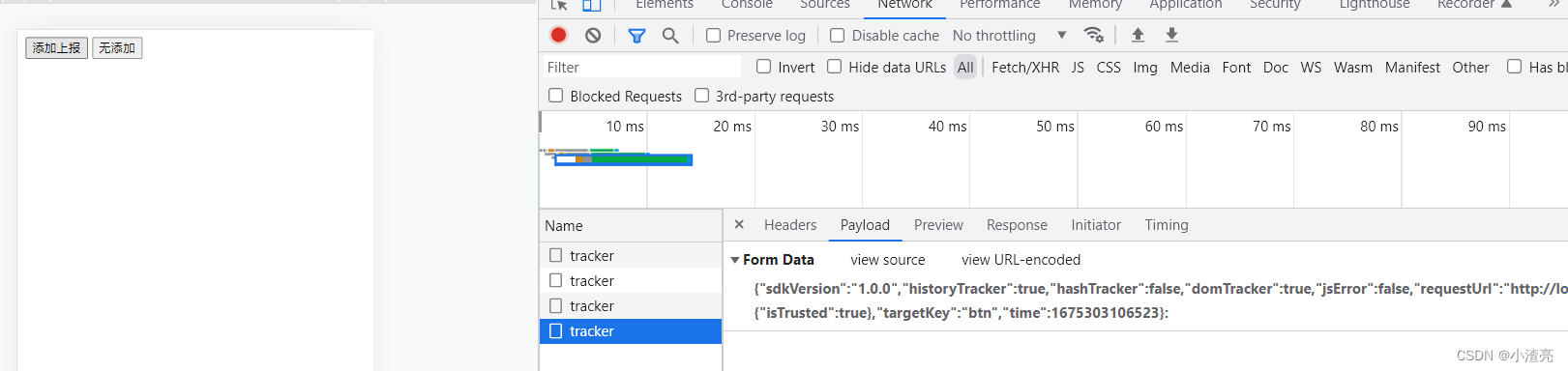
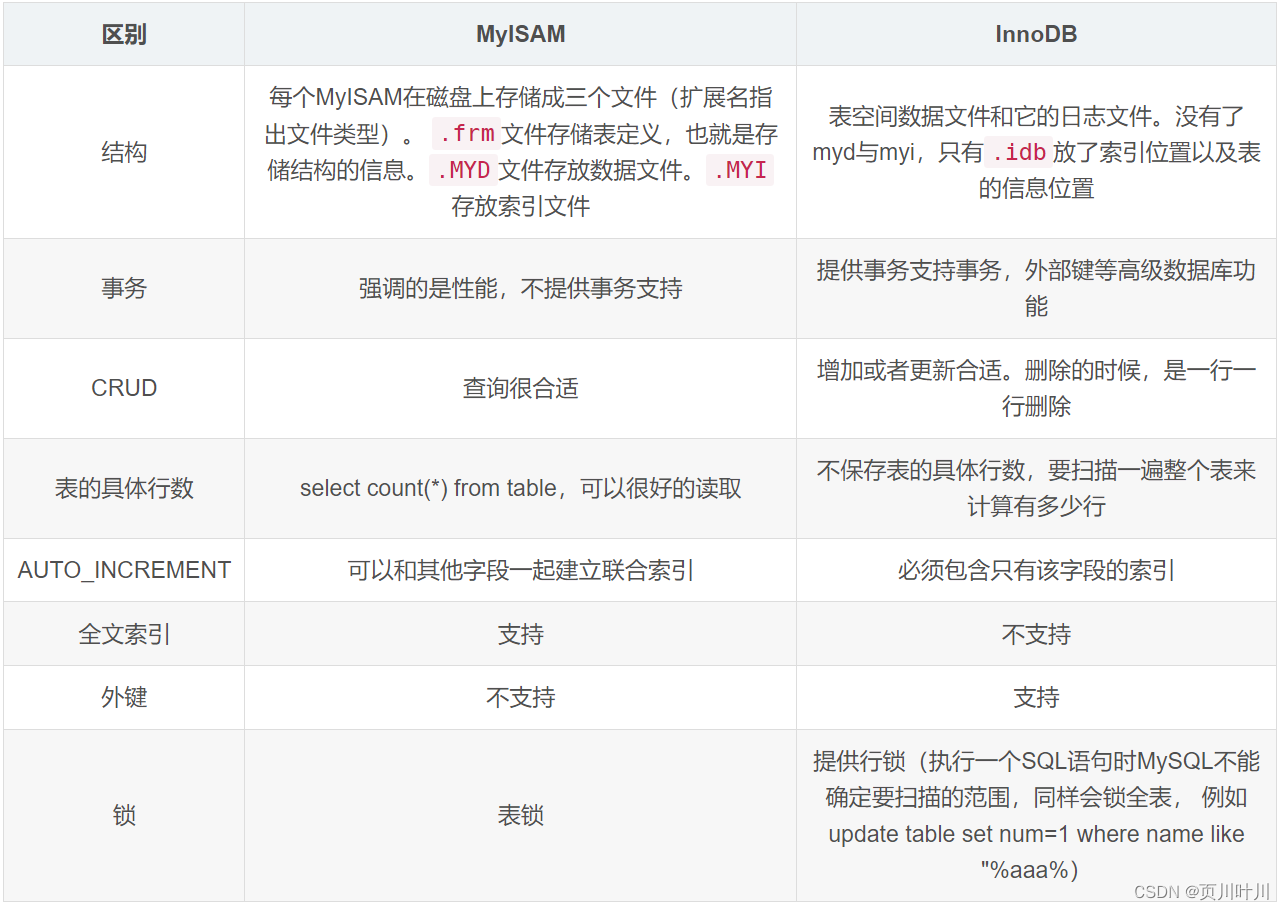
由于Btree数据结构特性,当节点达到上溢条件时会发生分裂,进而保持Btree的原本特性 B树 详解及C语言简单实现,在之前的postgres 源码解析 45 btree分裂流程_bt_split已对分裂流程进行讲解,接下来将从源码角度学习postgres btree分裂点的确认流程,本篇侧重将其数据结构和分裂规则相关知识,后续呈现执行流程及其实现原理。
关键数据结构

说明:
在计算分裂点的整个过程中,会生成FindSplitData结构体,该结构体记录了寻找分裂位置的相关信息,特别是最佳分裂为止以及待插入元组信息。

分裂最优点的确定会在众多的候选分裂点中选取,分裂点的数据结构由SplitPoint表示,该结构体记录了左页和右页的空闲空间,落在右叶中第一个元组在分裂页中的偏移量以及插入元组是否插入原分裂页等信息。

填充因子的确认
pg会根据页节点类型与元组情况确认分裂页的填充因子,具体情况如下:
1 分裂页为非叶子结点 ,填充因子为70 %;
2 分裂页为该层的最右侧节点 ,填充因子为90 %;
3 非最右页叶子结点 , 90 %或者 50 %,具体情况具体分析,如下:
对于非最右页叶子结点填充因子的确认设计到一种优化,其定义在 _bt_afternewitemoff 函数中
其规定需满足以下条件:
1) 该索引为复合索引;
2) 插入的索引元组在后续分裂后非索引页的第一个元组
3)元组拥有固定大小
4) 元祖宽度不超过16字节
这种优化适用于当复合索引中存在局部单调增加插入的模式,且领先的键属性值形成局部分组,并且我们预计接下来会再次插入相同的分组时。
讨论 :
1 插入元组为最右端

1)如果插入元组与分裂页最大项指针对应的索引元组相等的属性数目小于复合索引的属性总数(至少含有一个属性对应的数值相等),规定此时填充因子为 90 %;
2)反之填充因此为 50 %;
这么做是因为,当满足了上述所有条件后,pg推测如果下面还会有插入操作,下一个插入的大概率还会是同类型的键值递增的元组(比如此例中 id依旧为1,key为H的元组),且这个元组会被插入在分裂后的右页上,这时如果这次分裂用了填充百分比计算分裂点的delta的话,右页会有更多的可用空间,会延缓右页的再分裂。
2 插入元组非最右端
1) 如果Curr索引元组指向的堆表块号 Curr_heap_block_no 与Prev索引元组指向的堆表块号Prev_heap_block_no 相同 || Curr_heap_block_no = Prev_heap_block_no+1 且Curr索引元组指向的堆元组为堆页的第一个元组:
a. 如果Curr索引元组与Prev索引元组相等的属性数量在 [ 1,索引属性总数),进一步判断插入元组处于分裂页何处,
若处于分裂页空间的 90 % 位置之前,填充因子为50 %;

若处于分裂页空间的 90 % 位置之后,填充因子为90 %;

2)其他情况的非最右页叶子结点 填充因子为50 %;
需要注意的是,这项优化不是百分百精确的,上述所满足的条件都是用来推断“局部单调增加插入,且领先的键属性值形成局部分组,并且预计接下来会再次插入相同的分组”这个场景的发生,但推断不一定对,可能会出现一些误优化,但误优化的结果并不致命,平均下来分裂点在页面的中间点。即优化对了,增加效率,优化错了,不会降低效率。源码参考_bt_afternewitemoff函数。
分裂间隔的确定
什么是分裂间隔?
根据“Prefix B-Trees”论文中的描述,分裂间隔只是在待分裂页的中间节点周围确定一个范围,在这个范围中找到一个分裂点,使得最终插入父节点的分隔符最短。
可以看出分裂间隔是以最佳均衡空间分裂点为中心的。pg加入了填充百分比计算delta后,使最佳均衡空间分裂点split[0]不再一定是页面中间点。这里只是设置初始间隔,不同策略下的分割间隔不同。
叶子结点与非叶子结点的容忍值是不同的,pg中规定:
/*
* Determine leftfree and rightfree values that are higher and lower than
* we're willing to tolerate. Note that the final split interval will be
* about 10% of nsplits in the common case where all non-pivot tuples
* (data items) from a leaf page are uniformly sized. We're a bit more
* aggressive when splitting internal pages.
* LEAF_SPLIT_DISTANCE = 0.05 INTERNAL_SPLIT_DISTANCE = 0.075
*/
if (state->is_leaf)
tolerance = state->olddataitemstotal * LEAF_SPLIT_DISTANCE;
else
tolerance = state->olddataitemstotal * INTERNAL_SPLIT_DISTANCE;
以 splits[0]为基准,确认左右页的空闲空间界限,找到第一个不在此临界范围内的分裂点序号,以此作为初始间隔值。
/* First candidate split point is the most evenly balanced */
spaceoptimal = state->splits;
lowleftfree = spaceoptimal->leftfree - tolerance;
lowrightfree = spaceoptimal->rightfree - tolerance;
highleftfree = spaceoptimal->leftfree + tolerance;
highrightfree = spaceoptimal->rightfree + tolerance;
/*
* Iterate through split points, starting from the split immediately after
* 'spaceoptimal'. Find the first split point that divides free space so
* unevenly that including it in the split interval would be unacceptable.
*/
for (int i = 1; i < state->nsplits; i++)
{
SplitPoint *split = state->splits + i;
/* Cannot use curdelta here, since its value is often weighted */
if (split->leftfree < lowleftfree || split->rightfree < lowrightfree ||
split->leftfree > highleftfree || split->rightfree > highrightfree)
return i;
}
perfectpenalty
含义:分裂间隔内的所有分裂点能够产生的最小的策略罚分。
作用:可以提高_bt_bestsplitloc寻找最佳分裂点的效率。
如何理解它的含义和作用?
perfectpenalty字面上看是完美罚分的意思,这里我们称它为最优策略罚分。
流程上,它作为_bt_strategy的返回值,返回给_bt_bestsplitloc函数当做最后挑选最佳分裂点的参照。
_bt_bestsplitloc会调用_bt_split_penalty对每个候选分裂点都计算一个罚分penalty,计算出penalty会先和perfectpenalty做一个比较,如果小于等于perfectpenalty的话,就不用再计算下一个分裂点,而是直接将此分裂点作为最佳分裂点返回,所以perfectpenalty起到了提前结束循环遍历的作用,提高了_bt_bestsplitloc的效率。如果penalty一直都比perfectpenalty大,则返回它们中最小的那一个,那这样就需要遍历分裂间隔内所有的分裂点。
各场景介绍
了解了策略和perfectpenalty的概念,下面分场景介绍策略的选择流程:
1 叶子结点 – 一般情况
策略:最一般的情况
结果:保持原有的分裂间隔,保持原有的splits顺序
perfectpenalty为分裂间隔边界元组的最小区分键值数。所以在分裂间隔内是可以找到一个分裂点可以达到最佳后缀截断效果的。下图为perfectpenalty产生过程:

2 叶子结点–存在大量重复元组
策略:SPLIT_MANY_DUPLICATES
特点:此场景下,页中元组有很多重复元组,但不全是单一的重复元组。
结果:将分裂间隔设置为所有分裂点个数,保持原有splits顺序。
场景确定过程:
_bt_strategy函数先调用_bt_keep_natts_fast计算了分裂间隔边界的元组的最小区分键值数,发现大于总键值数(已有键值都区分不了返回总键值数+1),即没有差异。因为元组是逻辑递增的,所以说明分裂间隔内都是重复元组。这时需要再确认一下分裂间隔外是否也都是一样的重复元祖,再为页面两端的元组调用一次_bt_keep_natts_fast,看它们是否有差异,结果发现它们最小区分键值数a不大于总键值数,即有差异。则说明,页面在分裂间隔外存在差异元祖,且最小区分键值数为a。
PG给此场景下的页面分裂,使用SPLIT_MANY_DUPLICATES策略。但并没有取a为perfectpenalty,而是直接采用的总键值数为perfectpenalty这是为了让页面尽量在重复元组块的边界分裂(防止可能会出现的连续不平衡的分裂)。
为什么以总键值数为perfectpenalty能够让页面在重复元祖块边界分裂?
因为在_bt_bestsplitloc中,重复元组块中的分裂点的penalty是总键值数+1,所以值为总键值数的perfectpenalty,会在重复块的边界结束最佳分裂点的查找。参考流程图解第7步和下图:
3.叶子节点-全部为重复元祖
1)该页为最右页
策略:SPLIT_SINGLE_VALUE
特点:页中全部都是一样的元组,且页面为当前层最右边的页面。
结果:将分裂间隔设置为1,改变填充百分比为96%,调用_bt_deltasortsplits 重新排序 splits 数组。
这时_bt_strategy给页面返回的perfectpenalty是总键值数+1,其实这里perfectpenalty是多少已经起不到什么作用了,因为分裂间隔只有1,最后_bt_bestsplitloc只会返回用96%的填充百分比重新排序的splits[0],由于填充百分比很大,这个最佳分裂点会非常靠右,分裂出的右页将会有大量可用空间,而左页几乎是满的。
2)该页非最右页
① 该页为重复项结束页
策略:SPLIT_SINGLE_VALUE
特点:页中全部都是一样的元组,页面不是当前层最右边的页面,且右兄弟节点中没有 该重复项,即为重复项的结束页。
结果:将分裂间隔设置为1,改变填充百分比为96%,调用_bt_deltasortsplits 重新排序 splits 数组。
跟上一种场景唯一的区别在于perfectpenalty为插入项和页面highkey的最小区分键值数。由于分裂间隔设置为1,perfectpenalty是多少也起不到什么作用。最终都是返回splits[0]。
如何判定页面是不是重复项的结束页?
通过看插入项和页面highkey是否有区别,因为highkey是右页面的最小值,且页中元组键值递增,如果有区别,说明下一页将不会含有该重复项,否则下一页还是以该重复项开头。
② 该页非重复项结束页
策略:SPLIT_DEF AULT
特点:页中全部都是一样的元组,页面不是当前层最右边的页面,且右兄弟节点中有 该重复项,即不为重复项的结束页。
结果:保持原有分裂间隔,保持原有splits顺序。
对于此场景下为什么不使用SPLIT_SINGLE_VALUE策略,源码中的解释是:
/*
* Single value strategy is only appropriate with ever-increasing heap
* TIDs; otherwise, original default strategy split should proceed to
* avoid pathological performance. Use page high key to infer if this is
* the rightmost page among pages that store the same duplicate value.
* This should not prevent insertions of heap TIDs that are slightly out
* of order from using single value strategy, since that's expected with
* concurrent inserters of the same duplicate value.
即,SPLIT_SINGLE_VALUE策略仅适用于不断增长的堆TID, 否则,应继续执行原始的默认策略拆分以避免病理性能…
4.中间节点
策略:SPLIT_DEFAULT
特点:所有中间节点的分裂都是默认策略
结果:保持原有分裂间隔,保持原有splits顺序。
_bt_findsplitloc流程图 (下篇讲解)