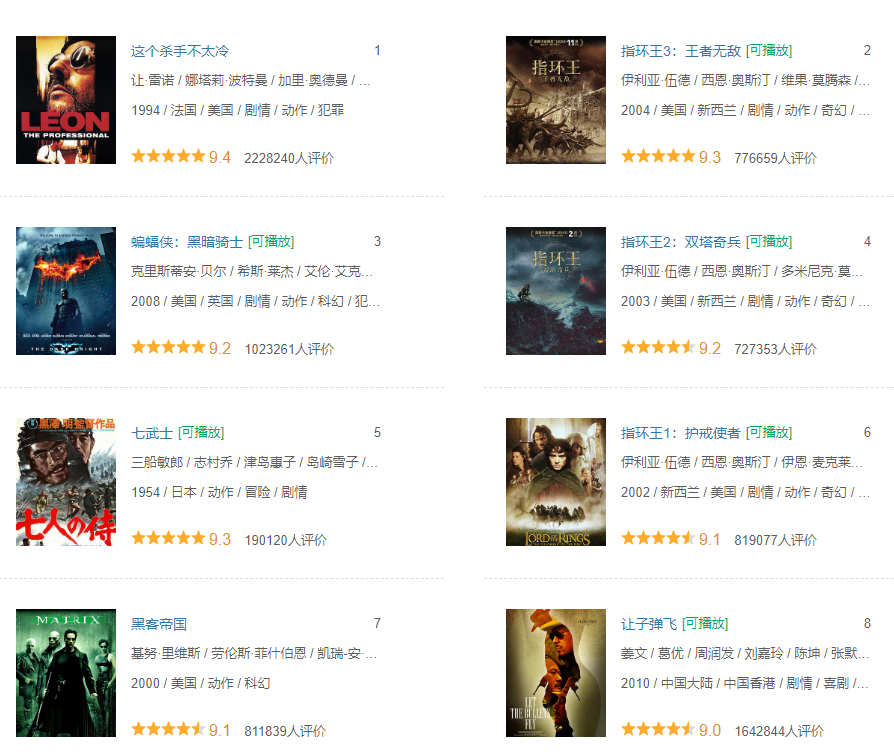
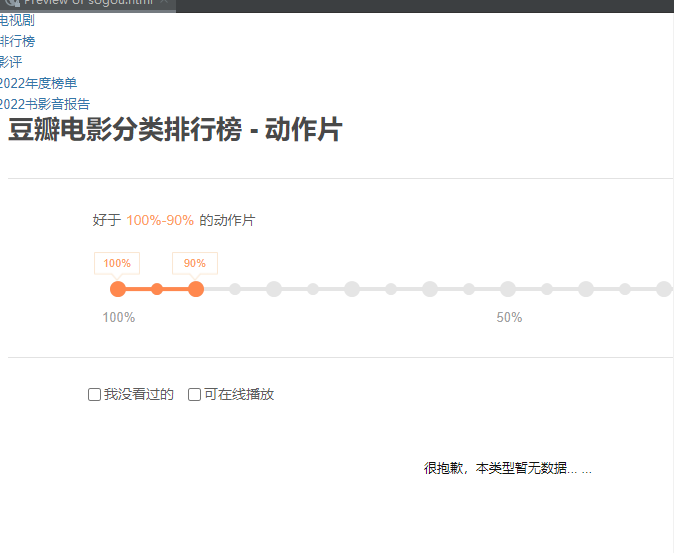
一、网站的正常界面
1、网址
https://movie.douban.com/typerank?type_name=%E5%8A%A8%E4%BD%9C%E7%89%87&type=5&interval_id=100:90&action=2、正常的页面
二、爬取数据
1、源代码
import requests头={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}网页="https://movie.douban.com/typerank?type_name=%E5%8A%A8%E4%BD%9C%E7%89%87&type=5&interval_id=100:90&action="响应=requests.get(网页,headers=头)响应内容=响应.textprint(响应内容)with open("sogou.html","w",encoding="utf-8") as 数据: 数据.write(响应内容)print("存储数据成功!!!")2、运行结果,发现没有我们想要的电影数据
三、打开开发者工具,重新刷新界面找数据
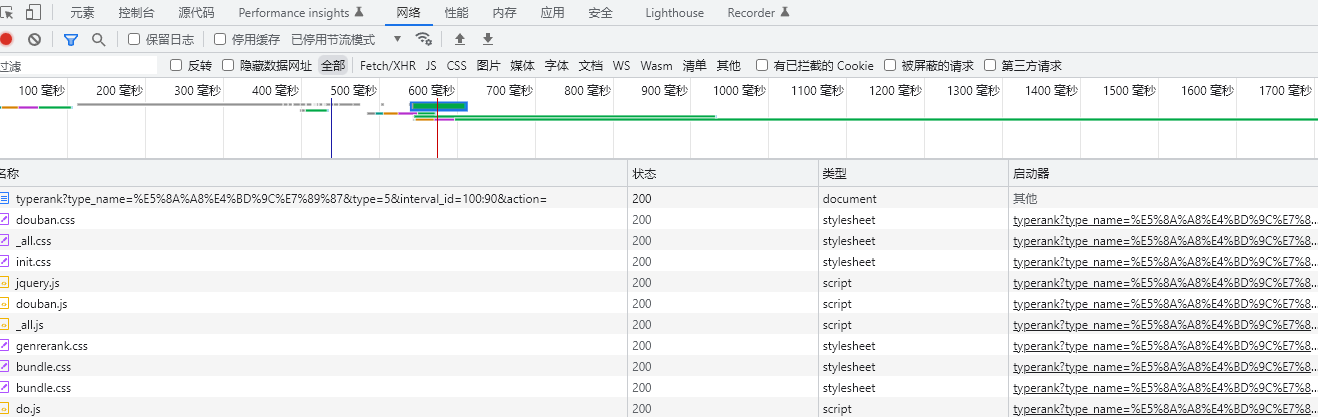
1、按ctrl+F,全局搜索电影名字

2、双击点击进去,找到一个响应里面有要找的电影名字
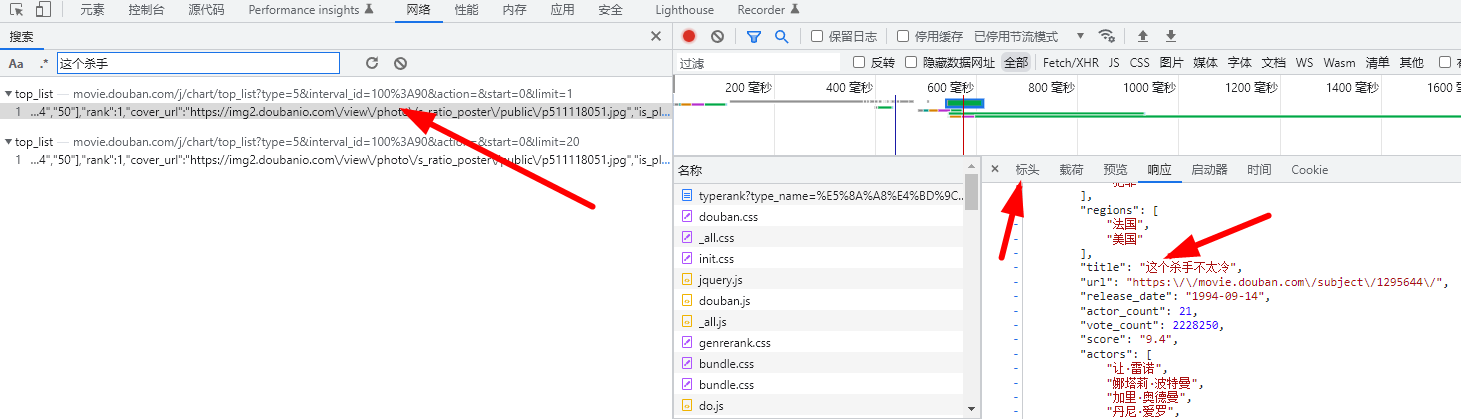
3、点击标头,该响应来自下面的网址,是一段JSON数据
https://movie.douban.com/j/chart/top_list?type=5&interval_id=100:90&action=&start=0&limit=1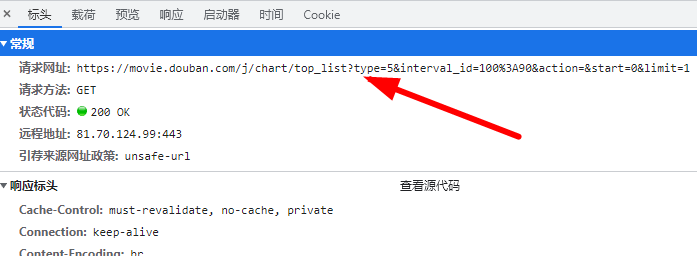
四、分析网址的参数
1、先在浏览器访问上面的链接
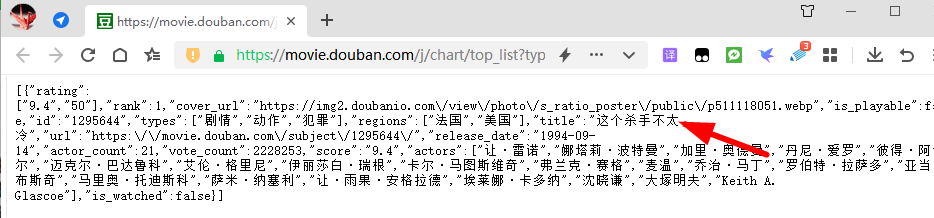
2、修改一下limit值,将其修改为20,返回了更多的数据,正好和正常访问网站内容都对应着
https://movie.douban.com/j/chart/top_list?type=5&interval_id=100:90&action=&start=0&limit=20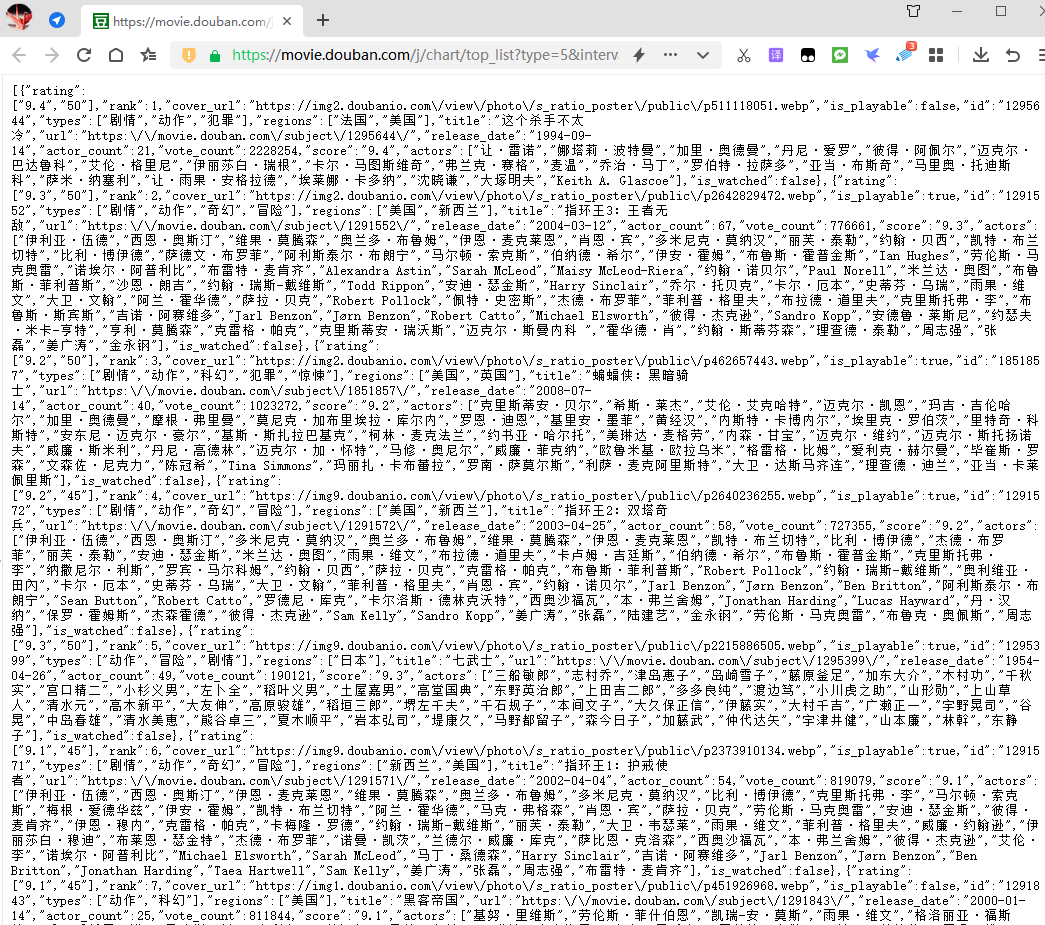
五、重现编辑代码
1、将网址修改为
https://movie.douban.com/j/chart/top_list?type=5&interval_id=100:90&action=&start=0&limit=202、因为返回的数据JSON数据,所以要就不能用text属性了
响应内容=响应.json()
3、只获取电影名字和电影得分,JSON数据里面都是字典,通过键名获取键值
import requests头={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}参数={"type":"5","interval_id":"100:90","action":"","start":"0","limit":"20",}网页="https://movie.douban.com/j/chart/top_list"响应=requests.get(网页,headers=头,params=参数)响应内容=响应.json()#fp=open("db.html","w",encoding="utf-8")with open("db.txt","w",encoding="utf-8") as 数据:for i in 响应内容: 电影名=i['title'] 得分=i["score"] 数据.write(电影名+":"+得分+"\n")4、运行结果

5、修改type和start值也会有惊喜哦!!!