-
创建虚拟环境用于运行
-
运行 InternLM 的基础环境,命名为 llamaindex conda create -n llamaindex python=3.10
- 查看存在的环境
conda env list
- 激活刚刚创建的环境
conda activate llamaindex
- 安装基本库pytorch,torchvision ,torchaudio,pytorch-cuda 并指定通道(建议写上对应的版本号)
-
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia
-
-
-
安装 Llamaindex
- 此操作在对应的虚拟环境中安装 Llamaindex和相关的包
pip install llama-index==0.10.38 llama-index-llms-huggingface==0.2.0 "transformers[torch]==4.41.1" "huggingface_hub[inference]==0.23.1" huggingface_hub==0.23.1 sentence-transformers==2.7.0 sentencepiece==0.2.0
- 此操作在对应的虚拟环境中安装 Llamaindex和相关的包
-
下载 Sentence Transformer 模型
- 为了方面管理建立对应的路径,在根目录下创建2个文件(
mkdir llamaindex_demo mkdir model
) - 然后在llamaindex_demo目录下创建下载脚本(
touch llamaindex_demo/download_hf.py
) - 在download_hf.py文件中写入
-
import os
# 设置环境变量
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'# 下载模型下载源词向量模型Sentence Transformer
os.system('huggingface-cli download --resume-download sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir /root/model/sentence-transformer')
-
- 执行下载模型脚本
python download_hf.py
- 如果上面的步骤不存在nltk此处需要手动下载nltk模型(cd /root
git clone https://gitee.com/yzy0612/nltk_data.git --branch gh-pages
cd nltk_data
mv packages/* ./
cd tokenizers
unzip punkt.zip
cd ../taggers
unzip averaged_perceptron_tagger.zip)
- 为了方面管理建立对应的路径,在根目录下创建2个文件(
-
LlamaIndex HuggingFaceLLM
- 下载模型internlm2-chat-1_8b (pip install internlm2-chat-1_8b )
- 如果有对应的模型可以软链接出来ln -s 模型路径 要复制到哪里的路径如(
cd ~/model ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b/ ./
) - 创建运行模型脚本 touch
touch ~/llamaindex_demo/llamaindex_internlm.py
- 编辑llamaindex_internlm.py文件(
from llama_index.llms.huggingface import HuggingFaceLLM from llama_index.core.llms import ChatMessage llm = HuggingFaceLLM( model_name="/root/model/internlm2-chat-1_8b", tokenizer_name="/root/model/internlm2-chat-1_8b", model_kwargs={"trust_remote_code":True}, tokenizer_kwargs={"trust_remote_code":True} ) rsp = llm.chat(messages=[ChatMessage(content="xtuner是什么?")]) print(rsp)) - 运行模型
python llamaindex_internlm.py
-
LlamaIndex RAG
-
安装
LlamaIndex词嵌入向量依赖(pip install llama-index-embeddings-huggingface llama-index-embeddings-instructor
)
-
如果上面步骤报错请根据提示安装对应的插件版本(如 pip install huggingface-hub==0.23.5)
-
获取知识库(创建data 把xtuner包中文件移动到对应的目录cd ~/llamaindex_demo
mkdir data
cd data
git clone https://github.com/InternLM/xtuner.git
mv xtuner/README_zh-CN.md ./) -
创建运行模型代码
llamaindex_RAG.py
-
llamaindex_RAG.py文件内容(from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings from llama_index.embeddings.huggingface import HuggingFaceEmbedding from llama_index.llms.huggingface import HuggingFaceLLM embed_model = HuggingFaceEmbedding( model_name="/root/model/sentence-transformer" ) Settings.embed_model = embed_model llm = HuggingFaceLLM( model_name="/root/model/internlm2-chat-1_8b", tokenizer_name="/root/model/internlm2-chat-1_8b", model_kwargs={"trust_remote_code":True}, tokenizer_kwargs={"trust_remote_code":True} ) Settings.llm = llm documents = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data() index = VectorStoreIndex.from_documents(documents) query_engine = index.as_query_engine() response = query_engine.query("xtuner是什么?") print(response)) - 运行
python llamaindex_RAG.py
-
-
浏览器上运行对话
- 安装服务依赖
pip install streamlit==1.36.0
- 创建运行脚本app.py
import streamlit as st
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.huggingface import HuggingFaceLLMst.set_page_config(page_title="llama_index_demo", page_icon="🦜🔗")
st.title("llama_index_demo")# 初始化模型
@st.cache_resource
def init_models():
embed_model = HuggingFaceEmbedding(
model_name="/root/model/sentence-transformer"
)
Settings.embed_model = embed_modelllm = HuggingFaceLLM(
model_name="/root/model/internlm2-chat-1_8b",
tokenizer_name="/root/model/internlm2-chat-1_8b",
model_kwargs={"trust_remote_code": True},
tokenizer_kwargs={"trust_remote_code": True}
)
Settings.llm = llmdocuments = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()return query_engine
# 检查是否需要初始化模型
if 'query_engine' not in st.session_state:
st.session_state['query_engine'] = init_models()def greet2(question):
response = st.session_state['query_engine'].query(question)
return response
# Store LLM generated responses
if "messages" not in st.session_state.keys():
st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}]# Display or clear chat messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.write(message["content"])def clear_chat_history():
st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}]st.sidebar.button('Clear Chat History', on_click=clear_chat_history)
# Function for generating LLaMA2 response
def generate_llama_index_response(prompt_input):
return greet2(prompt_input)# User-provided prompt
if prompt := st.chat_input():
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.write(prompt)# Gegenerate_llama_index_response last message is not from assistant
if st.session_state.messages[-1]["role"] != "assistant":
with st.chat_message("assistant"):
with st.spinner("Thinking..."):
response = generate_llama_index_response(prompt)
placeholder = st.empty()
placeholder.markdown(response)
message = {"role": "assistant", "content": response}
st.session_state.messages.append(message) -
运行
streamlit run app.py
- 默认端口8503( http://localhost:8503)
- 最终效果

- 安装服务依赖
基于 LlamaIndex 构建自己的 RAG 知识库
news2026/3/26 20:08:11
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1946781.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
动态代理更改Java方法的返回参数(可用于优化feign调用后R对象的统一处理)
动态代理更改Java方法的返回参数(可用于优化feign调用后R对象的统一处理) 需求原始解决方案优化后方案1.首先创建AfterInterface.java2.创建InvocationHandler处理代理方法3. 调用 实际运行场景拓展 需求
某些场景,调用别人的方法࿰…

手机空号过滤批量查询的意义及方法
手机空号过滤批量查询是现代营销和通信管理中常用的技术手段,旨在通过批量处理手机号码,筛选出活跃号码和空号等无效号码,以提高营销效率和减少不必要的通信成本。以下是关于手机空号过滤批量查询的详细解答:
一、手机空号过滤批…

3dsMax 设置近平面削减,靠近模型之后看不到模型,看很小的模型放大看不到
3dsMax 设置近平面削减,靠近模型之后看不到模型,看很小的模型放大看不
问题展示
解决办法_1 把这两个东西最上面的拖拽到最上面,最下面的拖拽到最下面。 解决办法_2
勾选视口裁剪
把这两个东西最上面的拖拽到最上面,最下面的…

华为ensp中ISIS原理与配置(超详细)
isis原理与配置
8-20字节;
地址组成:area id,system id,set三部分组成;
system id占6个字节;sel占一个,剩下的为area id区域号;
system id 唯一,
一般将router id 配…

opengl 写一个3D立方体——计算机图形学编程 第4章 管理3D图形数据 笔记
计算机图形学编程(使用OpenGL和C) 第4章 管理3D图形数据 笔记
数据处理 想要绘制一个对象,它的顶点数据需要发送给顶点着色器。通常会把顶点数据在C端放入 一个缓冲区,并把这个缓冲区和着色器中声明的顶点属性相关联。
初始化立…

Python中高效处理大数据的几种方法
随着数据量的爆炸性增长,如何在Python中高效地处理大数据成为了许多开发者和数据科学家的关注焦点。Python以其简洁的语法和丰富的库支持,在数据处理领域占据了重要地位。本文将介绍几种在Python中高效处理大数据的常用方法。
目录
1. 使用Pandas进行数…

基于STM32的逻辑分析仪
文章目录 一、逻辑分析仪体验1、使用示例1.1 逻辑分析仪1.2 开源软件PulseView 2、核心技术2.1 技术方案2.2 信号采集与存储2.3 数据上传 3、使用逻辑分析仪4、 SourceInsight 使用技巧4.1新建工程4.2 设置工程名及工程数据目录4.3 指定源码目录4.4 添加源码4.5 同步文件4.6 操…

为RTEMS Raspberrypi4 BSP添加SPI支持
为RTEMS Raspberrypi4 BSP添加SPI支持
主要参考了dev/bsps/shared/dev/spi/cadence-spi.c
RTEMS 使用了基于linux的SPI框架,SPI总线驱动已经在内核中实现。在这个项目中我需要实习的是 RPI4的SPI主机控制器驱动
SPI在RTEMS中的实现如图: 首先需要将S…

25.x86游戏实战-理解发包流程
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动!
本次游戏没法给
内容参考于:微尘网络安全
工具下载: 链接:https://pan.baidu.com/s/1rEEJnt85npn7N38Ai0_F2Q?pwd6tw3 提…

江科大/江协科技 STM32学习笔记P9-11
文章目录 OLED1、OLED硬件main.c EXTI外部中断1、中断系统2、中断执行流程图3、STM32中断4、中断地址的作用5、EXTI6、EXTI基本结构7、AFIO复用IO口8、EXTI框图或门和与门 9、旋转编码器介绍10、硬件电路 OLED
1、OLED硬件 SCL和SDA是I2C的通信引脚,需要接在单片机…

java包装类型缓存简单探究-Integer为例
文章目录 包装类型缓存自动装箱与valueOf感悟结语 包装类型缓存
包装类型缓存是什么 本文以常用的Integer包装类为例做一个探索,感兴趣可以用类似方法查看其他包装类。 我们都知道它会缓存 -128到127之间的整数Integer对象。 结论大伙都知道。那么我们今天就来探究…
【Android】安卓四大组件之广播知识总结
文章目录 动态注册使用BroadcastReceiver监听Intent广播注册Broadcast Receiver 静态注册自定义广播标准广播发送广播定义广播接收器注册广播接收器 有序广播修改发送方法定义第二个广播接收器注册广播接收器广播截断 使用本地广播实践-强制下线使用ActivityCollector管理所有活…

ubuntu那些ppa源在哪
Ubuntu中的 PPA 终极指南 - UBUNTU粉丝之家
什么是PPA
PPA 代表个人包存档。 PPA 允许应用程序开发人员和 Linux 用户创建自己的存储库来分发软件。 使用 PPA,您可以轻松获取较新的软件版本或官方 Ubuntu 存储库无法提供的软件。
为什么使用PPA?
正如…

【JavaEE】Spring Boot 自动装配原理(源码分析)
一. 前言
我们在写Spring Boot的程序代码的时候, 可以注入很多我们没有定义过的Bean.例如: Autowired private ApplicationContext applicationContext; Autowired public DataSourceTransactionManager transactionManager; Autowired public AutowireCapableBeanFactory …
软件开发者消除edge浏览器下载时“此应用不安全”的拦截方法
当Microsoft Edge浏览器显示“此应用不安全”或者“已阻止此不安全的下载”这类警告时,通常是因为Windows Defender SmartScreen或者其他安全功能认为下载的文件可能存在安全风险。对于软件开发者来说,大概率是由于软件没有进行数字签名,导致…

Visual Studio 2022新建 cmake 工程测试 tensorRT 自带样例 sampleOnnxMNIST
1. 新建 cmake 工程 vs2022_cmake_sampleOnnxMNIST_test( 如何新建 cmake 工程,请参考博客:Visual Studio 2022新建 cmake 工程测试 opencv helloworld )
2. 删除默认生成的 vs2022_cmake_sampleOnnxMNIST_test.h 头文件
3. 修改默认生成的 vs2022_cma…

【屏显MCU】多媒体接口总结
本文主要介绍【屏显MCU】的基本概念,用于开发过程中的理解 以下是图层叠加示例 【屏显MCU】多媒体接口总结 0. 个人简介 && 授权须知1. 三大引擎1.1 【显示引擎】Display Engine1.1.1 【UI】 图层的概念1.1.2 【Video】 图层的概念1.1.3 图层的 Blending 的…

一键解锁:科研服务器性能匹配秘籍,选择性能精准匹配科研任务和计算需求的服务器
一键解锁:科研服务器性能匹配秘籍
HPC科研工作站服务器集群细分领域迷途小书童 专注于HPC科研服务器细分领域kyfwq001 🎯在当今科技飞速发展的时代,科研工作对计算资源的需求日益增长😜。选择性能精准匹配科研任务和计算需求的服…
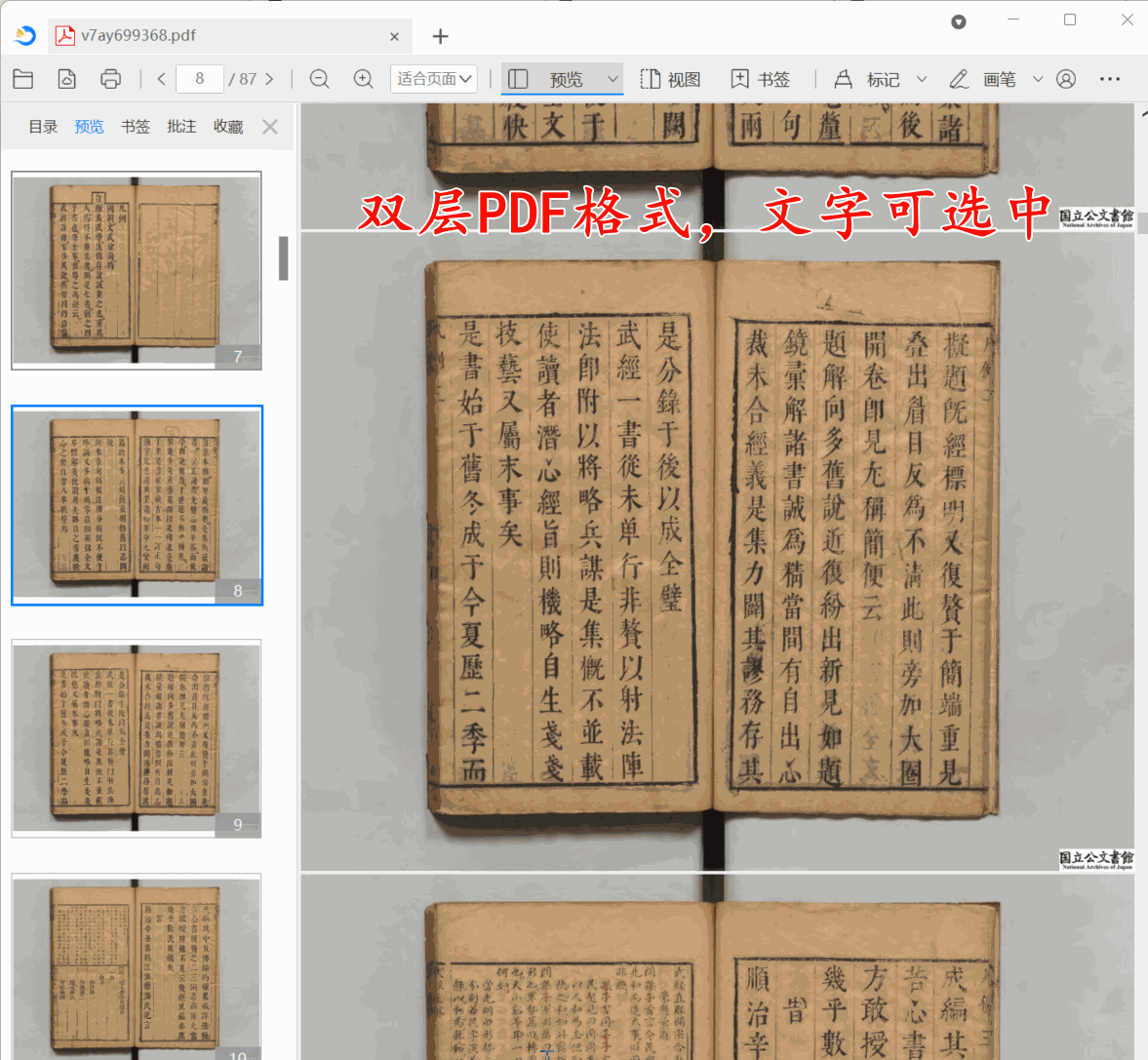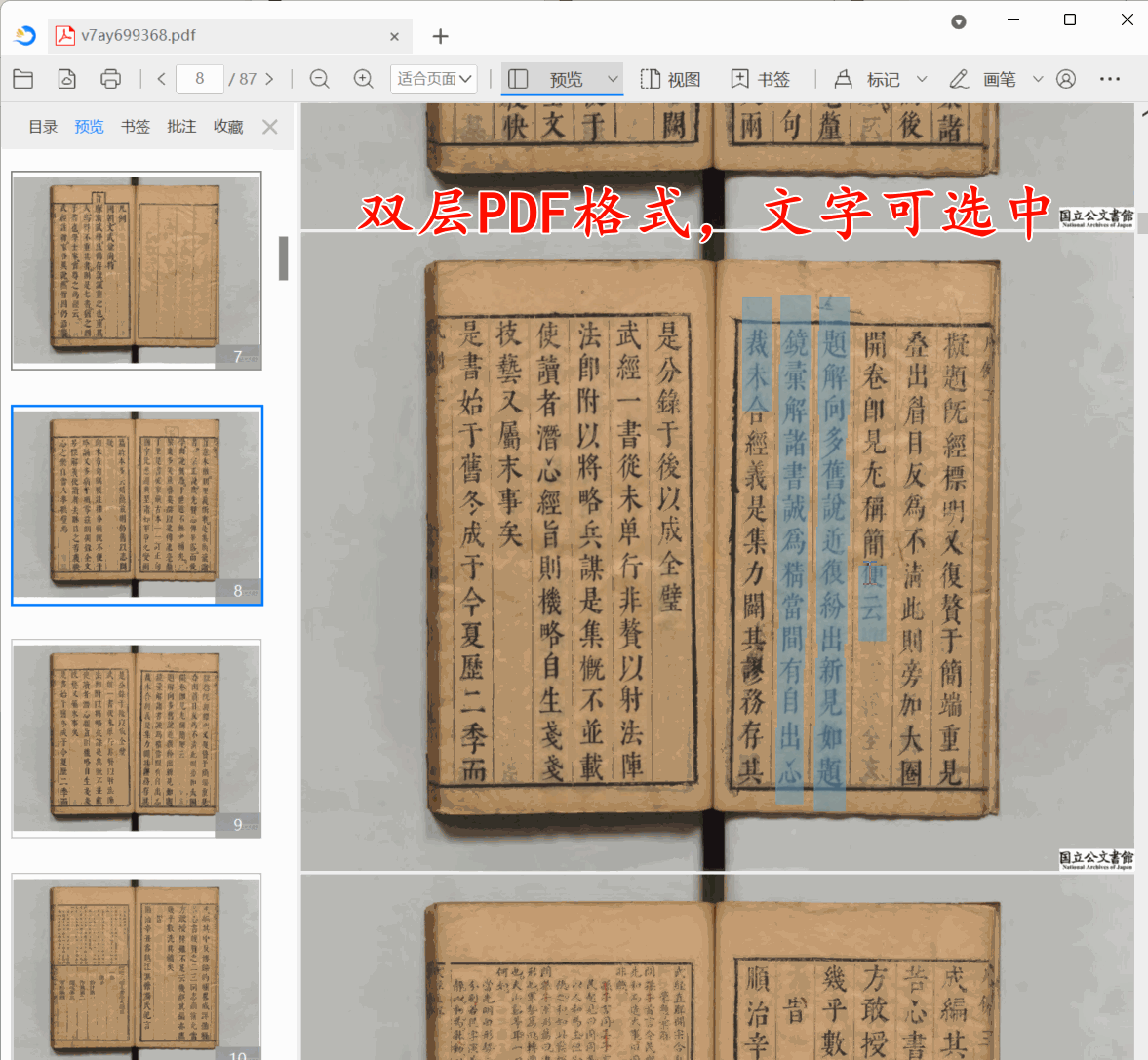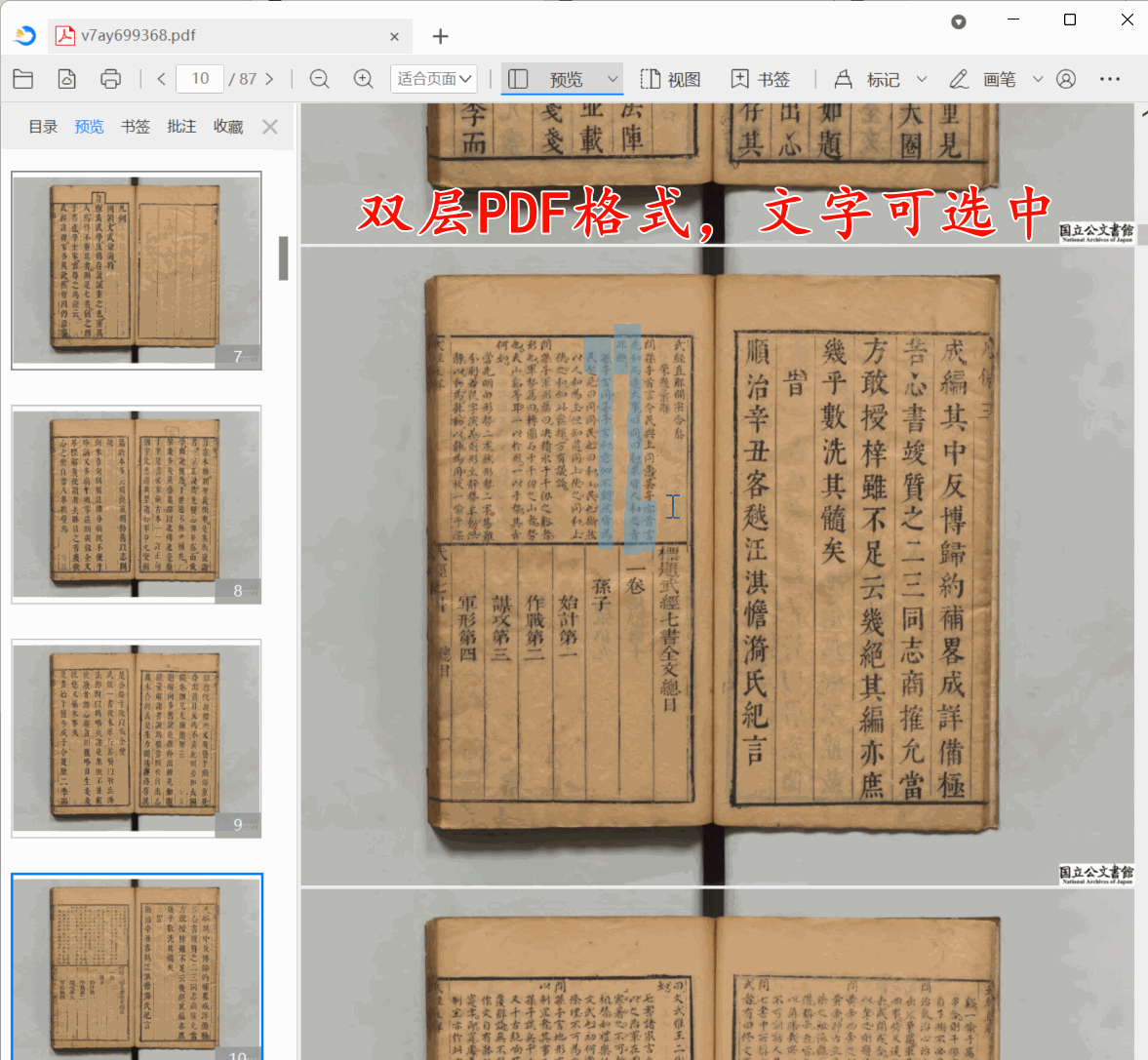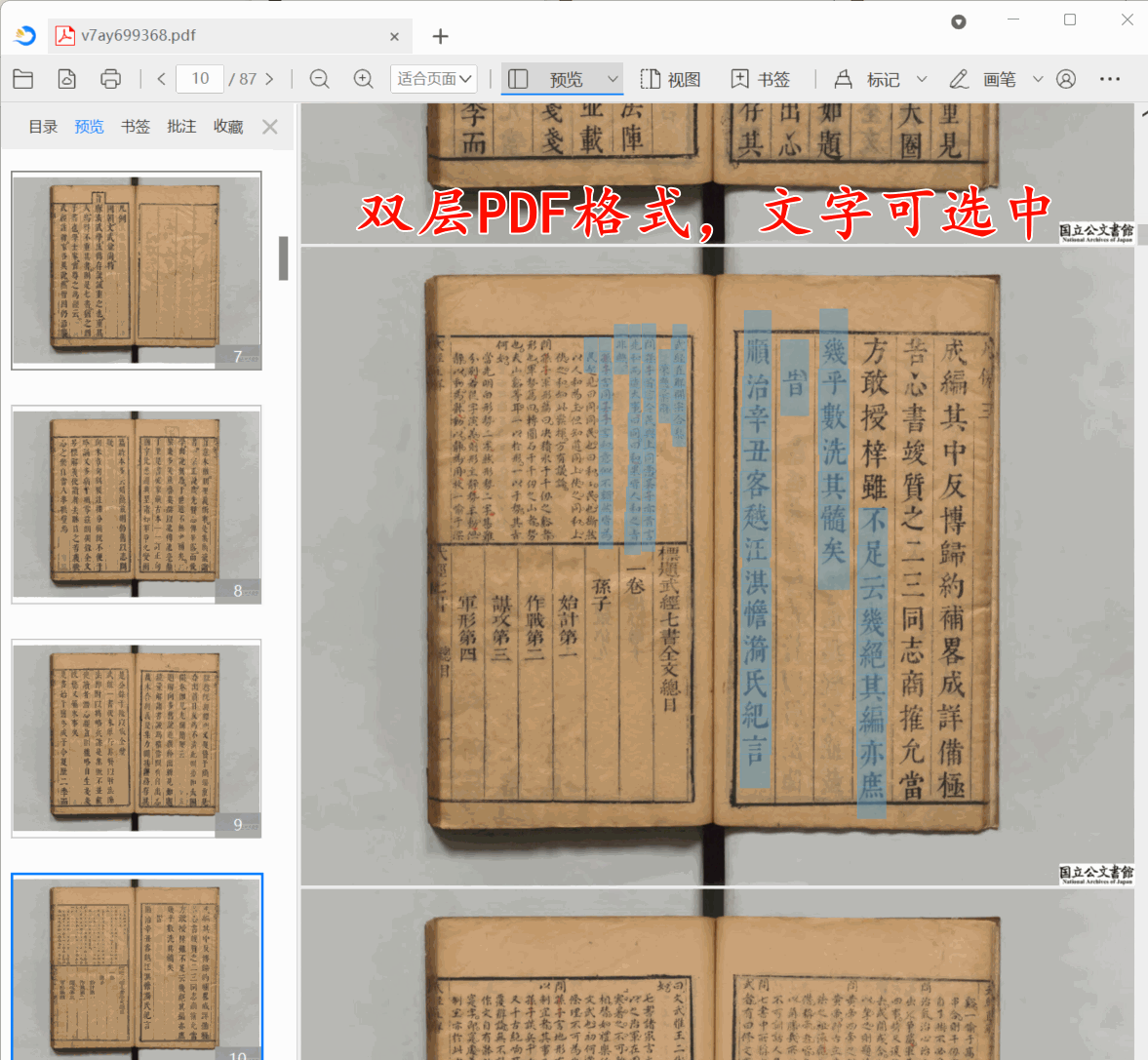
古籍双层PDF制作教程:保姆级古籍数字化教程
在智慧古籍数字化项目中,很多图书馆要求将古籍导出为双层PDF,并且确保输出双层PDF底层文本与上层图片偏移量控制在1毫米以内。那么本教程带你使用古籍数字化平台,3分钟把一个古籍书籍转化为双侧PDF。
第1步:上传古籍
点批量上传…

前序+中序、中序+后序构造二叉树
https://leetcode.cn/problems/construct-binary-tree-from-preorder-and-inorder-traversal/ https://leetcode.cn/problems/construct-binary-tree-from-inorder-and-postorder-traversal/ 前序中序 前序遍历,节点按照 [根左右] 排序。 中序遍历,节点…