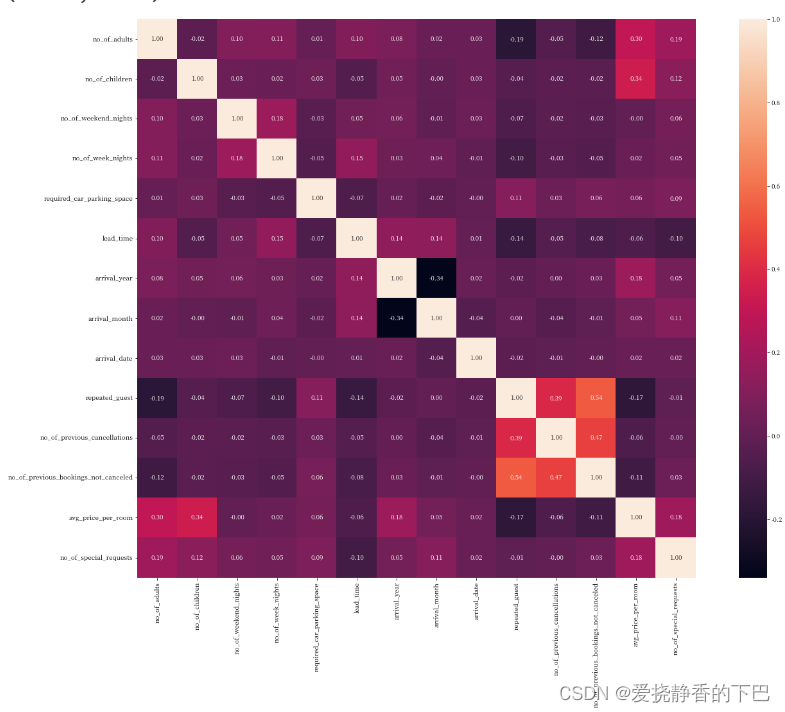
一、面向对象五大基本原则是什么
1.单一职责原则SRP(Single Responsibility Principle)
类的功能要单一,不能包罗万象,跟杂货铺似的。
2.开放封闭原则OCP(Open-Close Principle)
一个模块对于扩展是开放的,对于修改是封闭的
3.里式替换原则LSP(Liskov Substitution Principle LSP)
子类可以替换父类出现在父类能够出现的任何地方。比如你能代表你爸去你姥姥家干活。
4.接口分离原则ISP(Interface Segregation Principle ISP)
设计时采用多个与特定客户类有关的接口比采用一个通用的接口要好。就比如一个手机拥有打电话,看视频,玩游戏等功能,把这几个功能拆分成不同的接口,比在一个接口里要好的多。
5.依赖倒置原则DIP( Dependency Inversion Principle DIP)
高层次的模块不应该依赖于低层次的模块,他们都应该依赖于抽象。抽象不应该依赖于具体实现,具体实现应该依赖于抽象。就是你出国要说你是中国人,而不能说你是哪个村子的。比如说中国人是抽象的,下面有具体的xx省,xx市,xx县。你要依赖的抽象是中国人,而不是你是xx村的。实现尽量依赖抽象,不依赖具体实现。
二、BIO,NIO,AIO 有什么区别?
BIO:Block IO 同步阻塞式 IO,并发处理能力低。
NIO:Non IO 同步非阻塞 IO,客户端和服务器端通过Channel(通道)通讯,实现了多路复用。
AIO:Asynchronous IO 是 NIO 的升级,也叫 NIO2,实现了异步非阻塞 IO,异步 IO 的操作基于事件和回调机制。
同步,因为这种情况下你并不知道子任务的执行情况,虽然主子两个任务并行,但还是需要主任务手动去获取子任务的执行状态。异步多了个任务结束回调。
详细回答
BIO (Blocking I/O): 同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
NIO (New I/O): NIO是一种同步非阻塞的I/O模型,在Java 1.4 中引入了
NIO框架,对应 java.nio 包,提供了 Channel , Selector,Buffer等抽象。NIO中的
N可以理解为Non-blocking,不单纯是New。它支持面向缓冲的,基于通道的I/O操
作方法。 NIO提供了与传统BIO模型中的 Socket 和 ServerSocket 相对应的
SocketChannel 和 ServerSocketChannel 两种不同的套接字通道实现,两种通道都
支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是
性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,
可以使用同步阻塞I/O来提升开发速率和更好的维护性;对于高负载、高并发的(网
络)应用,应使用 NIO 的非阻塞模式来开发
AIO (Asynchronous I/O): AIO 也就是 NIO 2。在 Java 7 中引入了 NIO
的改进版 NIO 2,它是异步非阻塞的IO模型。异步 IO 是基于事件和回调机制实现的,
也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通
知相应的线程进行后续的操作。AIO 是异步IO的缩写,虽然 NIO 在网络操作中,提
供了非阻塞的方法,但是 NIO 的 IO 行为还是同步的。对于 NIO 来说,我们的业务
线程是在 IO 操作准备好时,得到通知,接着就由这个线程自行进行 IO 操作,IO操
作本身是同步的。目前来说 AIO 的应用还不是很广泛,Netty 之前也尝试使用过 AIO,不过又放弃了。
三、集合
1. Set
HashSet(无序,唯一):基于 HashMap 实现的,底层采用 HashMap 来保
存元素
LinkedHashSet: LinkedHashSet 继承与 HashSet,并且其内部是通过
LinkedHashMap 来实现的。有点类似于我们之前说的LinkedHashMap 其内部是基
于 Hashmap 实现一样,不过还是有一点点区别的。
TreeSet(有序,唯一): 红黑树(自平衡的排序二叉树。)
2. Map
HashMap: JDK1.8之前HashMap由数组+链表组成的,数组是HashMap的主
体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突).JDK1.8以后
在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转
化为红黑树,以减少搜索时间。需要注意Jdk 1.8中对HashMap的实现做了优化,当链表中的节点数据超过八个之后,该链表会转为红黑树来提高查询效率,从原来的O(n)到O(logn)
HashMap 基于 Hash 算法实现的
1. 当我们往Hashmap中put元素时,利用key的hashCode重新hash计算出当前对象的元素在数组中的下标
2. 存储时,如果出现hash值相同的key,此时有两种情况。(1)如果key相同,则覆盖原始值;(2)如果key不同(出现冲突),则将当前的key-value放入链表中
3. 获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。
4. 理解了以上过程就不难明白HashMap是如何解决hash冲突的问题,核心就是使用了数组的存储方式,然后将冲突的key的对象放入链表中,一旦发现冲突就在链表中做进一步的对比。
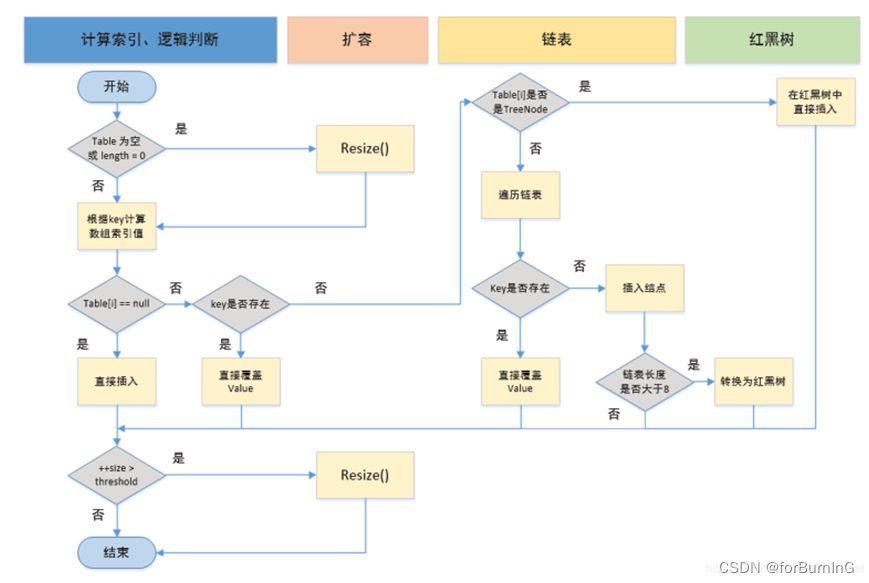
在Java中,保存数据有两种比较简单的数据结构:数组和链表。数组的特点是:寻址容易,插入和删除困难;链表的特点是:寻址困难,但插入和删除容易;所以我们将数组和链表结合在一起,发挥两者各自的优势,使用一种叫做拉链法的方式可以解决哈希冲突。
拉链法:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
LinkedHashMap:LinkedHashMap 继承自 HashMap,所以它的底层仍然是
基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面
结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。
同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。
HashTable: 数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的
TreeMap: 红黑树(自平衡的排序二叉树)
四、Java集合的快速失败机制 “fail-fast”?
是java集合的一种错误检测机制,当多个线程对集合进行结构上的改变的操作时,有可能会产生 fail-fast 机制。
例如:假设存在两个线程(线程1、线程2),线程1通过Iterator在遍历集合A中的元素,在某个时候线程2修改了集合A的结构(是结构上面的修改,而不是简单的修改集合元素的内容),那么这个时候程序就会抛出 ConcurrentModificationException 异常,从而产生fail-fast机制。
原因:迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个modCount 变量。集合在被遍历期间如果内容发生变化,就会改变modCount的值。每当迭代器使用hashNext()/next()遍历下一个元素之前,都会检测modCount变量是否为expectedmodCount值,是的话就返回遍历;否则抛出异常,终止遍历。
解决办法:
1. 在遍历过程中,所有涉及到改变modCount值得地方全部加上synchronized。
2. 使用CopyOnWriteArrayList来替换ArrayList
五、怎么确保一个集合不能被修改?
可以使用 Collections. unmodifiableCollection(Collection c) 方法来创建一个只读集合,这样改变集合的任何操作都会抛出 Java. lang.UnsupportedOperationException 异常。
六、能否使用任何类作为 Map 的 key?
1、可以使用任何类作为 Map 的 key,然而在使用之前,需要考虑以下几点:
如果类重写了 equals() 方法,也应该重写 hashCode() 方法。
2、类的所有实例需要遵循与 equals() 和 hashCode() 相关的规则。
如果一个类没有使用 equals(),不应该在 hashCode() 中使用它。
3、用户自定义 Key 类最佳实践是使之为不可变的,这样 hashCode() 值
可以被缓存起来,拥有更好的性能。不可变的类也可以确保 hashCode()
和 equals() 在未来不会改变,这样就会解决与可变相关的问题了。