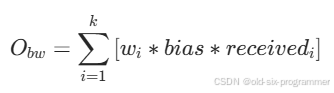题目
给定一个m x n的二维字符网格board和一个字符串单词word。如果word存在于网格中,返回true。否则,返回false。单词必须按照字母顺序,通过相邻的单元格内的字母构成。所谓相邻单元格,是那些水平相邻或垂直相邻的单元格。
备注:board和word仅由大小写英文字母组成。
注意:同一个单元格内的字母不允许被重复使用。
示例 1:

输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCCED"
输出:true示例 2:

输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "SEE"
输出:true示例 3:

输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCB"
输出:false回溯法
使用回溯法求解本题的基本思想是:深度优先搜索每一个可能的路径,同时确保沿着路径上的字符能够构成目标单词;如果发现无法构成目标单词或者已经探索完所有路径,就回溯到上一步继续尝试其他分支。关键在于控制访问状态,避免重复访问同一单元格。使用回溯法求解本题的主要步骤如下。
1、定义一个递归函数,输入当前坐标、已访问矩阵、当前构建的单词片段。
2、检查当前位置的字符是否与单词的当前片段匹配,如果不匹配直接返回。
3、标记当前位置为已访问。
4、如果当前构建的单词片段等于目标单词,返回True。
5、对当前坐标四周的合法未访问位置递归调用该函数。
6、如果所有方向都无法匹配成功,则回溯:取消当前位置的访问标记,返回False。
7、遍历网格的每个单元格,调用上述递归函数开始搜索。
根据上面的算法步骤,我们可以得出下面的示例代码。
def board_word_search_by_backtracking(board, word):
def dfs(i, j, k):
if not 0 <= i < m or not 0 <= j < n or board[i][j] != word[k] or visited[i][j]:
return False
if k == len(word) - 1:
return True
visited[i][j] = True
result = (dfs(i + 1, j, k + 1) or
dfs(i - 1, j, k + 1) or
dfs(i, j + 1, k + 1) or
dfs(i, j - 1, k + 1))
visited[i][j] = False
return result
m, n = len(board), len(board[0])
visited = [[False]*n for _ in range(m)]
for i in range(m):
for j in range(n):
if dfs(i, j, 0):
return True
return False
board = [
["A", "B", "C", "E"],
["S", "F", "C", "S"],
["A", "D", "E", "E"]
]
word = "ABCCED"
print(board_word_search_by_backtracking(board, word))广度优先搜索算法
使用广度优先搜索(BFS)算法求解本题的基本思想是:从每个可能的起始位置开始,一层一层地扩展到其周围的邻居节点,同时跟踪已访问的位置和当前构建的单词路径;通过维护一个队列来保存待探索的节点,并使用哈希集合记录已访问状态,可以有效地避免重复访问,直到找到匹配的单词或探索完所有路径。使用广度优先搜索算法求解本题的主要步骤如下。
1、创建一个队列用于存储待探索的节点,每个节点包含当前坐标和已构建的单词片段。
2、遍历board,将所有与word首字符匹配的单元格作为起始节点加入队列,并记录它们的访问状态。
3、当队列非空时,从队列中弹出节点,检查其构建的单词片段是否等于word,如果是则返回true。
4、对于每个弹出的节点,探索其四个相邻节点。如果相邻节点未访问且字符匹配,则将新节点(包含更新的坐标和单词片段)加入队列,并标记为已访问。
5、如果队列为空,说明所有路径都已探索但未找到匹配,返回false。
根据上面的算法步骤,我们可以得出下面的示例代码。
from collections import deque
def board_word_search_by_bfs(board, word):
def get_neighbors(x, y):
for dx, dy in [(-1, 0), (1, 0), (0, -1), (0, 1)]:
nx, ny = x + dx, y + dy
if 0 <= nx < m and 0 <= ny < n:
yield nx, ny
m, n = len(board), len(board[0])
visited = [[False]*n for _ in range(m)]
for i in range(m):
for j in range(n):
if board[i][j] == word[0]:
queue = deque([(i, j, 0)])
visited[i][j] = True
while queue:
x, y, idx = queue.popleft()
if idx == len(word) - 1:
return True
for nx, ny in get_neighbors(x, y):
if not visited[nx][ny] and board[nx][ny] == word[idx + 1]:
visited[nx][ny] = True
queue.append((nx, ny, idx + 1))
for x in range(m):
for y in range(n):
visited[x][y] = False
return False
board = [
["A", "B", "C", "E"],
["S", "F", "C", "S"],
["A", "D", "E", "E"]
]
word = "ABCCED"
print(board_word_search_by_bfs(board, word))总结
两种算法的时间复杂度均为O(m * n * 4^L),其中m和n分别是网格的行数和列数,L是单词的长度。这是因为每个单元格可能触发一条路径,而每条路径最多可能有4个不同的方向可以探索。空间复杂度均为O(m * n),因为需要这么多的空间来记录已访问状态。相比回溯法,BFS在处理较宽的搜索树时通常更为高效,因为它可以更快地找到最短路径。但BFS实现相对复杂一些,需要管理队列和已访问状态的哈希集合。


![[AWS]MSK调用,报错Access denied](https://i-blog.csdnimg.cn/direct/4b1643fc9fee49178045f19810a596f8.png)