GPT模型的底层,其实是谷歌团队推出的Transformer模型。但是在GPT-3出现之前,大家一直对它没有多少了解。直到它的参数数量突破1750亿个的时候,它才建立起一个庞大的神经网络,这个神经网络最突出的特点是大数据、大模型和大计算。其实说白了,就是“大力出奇迹,暴力计算”。
在经过基于大量数据的预训练和大量的计算之后,GPT模型表现出了令人惊艳的语言理解和生成能力,可以选择性地记住前文的重点,形成思维链推理能力。
那么GPT模型生成意义丰富的文本的奥妙是什么呢?其实它依赖于大量的语言数据和核心的大语言模型(LLM)。
简言之,我们可以将GPT模型理解为一个会做文字接龙的模型:当我们给出一个不完整的句子,GPT会接上一个可能的词或字,就像我们在使用输入法时,我们输入上文,输入法会联想出下文一样。
假设我们选择了《水浒传》中武松打虎的故事作为GPT模型的学习材料,将提示词设定为“以武松这个亲历者的心态描述打虎的过程和他的心理状态”。那么根据提示词,起始词可能是“我”,模型可能会连续生成“是”字,然后将其与前面的“我”组合成“我是”。接着,模型可能会根据单词出现的概率继续预测下一个字,生成“武”字。随后,继续组合“我是”和“武”,形成“我是武”。这一过程会不断循环,直到模型生成符合预设要求的文本,例如“我是武松”。
通过这种方式,GPT模型能够逐步构建一段符合预期的、连贯的文本,描述出武松打虎的经历与心情。下图是一个简单的示意图,展示了模型生成文本的迭代过程。

注意,智能输入法是根据用户的输入,在已输入词语的基础上,自动预测可能需要输入的词语,以帮助用户提升打字速度。然而,GPT模型和智能输入法在本质上有很大的差别。GPT模型的真正能力是基于训练和大量语言数据的文本生成,其目标是创造性地生成文本,能够理解上下文,并生成与输入相关、通顺连贯的内容,而不是简单的联想输入。GPT模型除了在词和语句生成上符合人类的预期,也产生了和人一样的语言理解力和表达力,并且具备了逻辑分析和推理能力。
GPT模型为什么能生成有意义的文本
news2026/4/9 16:02:56
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1943328.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

宠物经济纵深观察:口红效应显著,呈可持续发展态势
七月以来,全国各地陆续开启高温模式。和人一样,“毛孩子们”同样也难耐高温,由此,围绕猫猫狗狗的“宠物经济”迅速升温,宠物冰垫、宠物饮水机、宠物烘干机......一系列宠物单品掀起夏日消费热潮。
就在几天前…

mysql的主从复制和读写分离:
mysql的主从复制和读写分离:
主从复制
面试必问:主从复制的原理
主从复制的模式:
1、mysql的默认模式:
异步模式 主库在更新完事务之后会立即把结果返回给从服务器,并不关心从库是否接受到,以及从库是…

汽车研发项目管理系统排行榜:五大热门汽车项目管理系统推荐
汽车研发项目管理软件在汽车制造行业中扮演着至关重要的角色,本文介绍了五款在汽车及零部件领域专业的项目管理软件。
一、 奥博思 PowerProject 企业级项目管理系统
奥博思 PowerProject 项目管理系统(支持项目管理、项目集管理、项目组合管理三位一体…
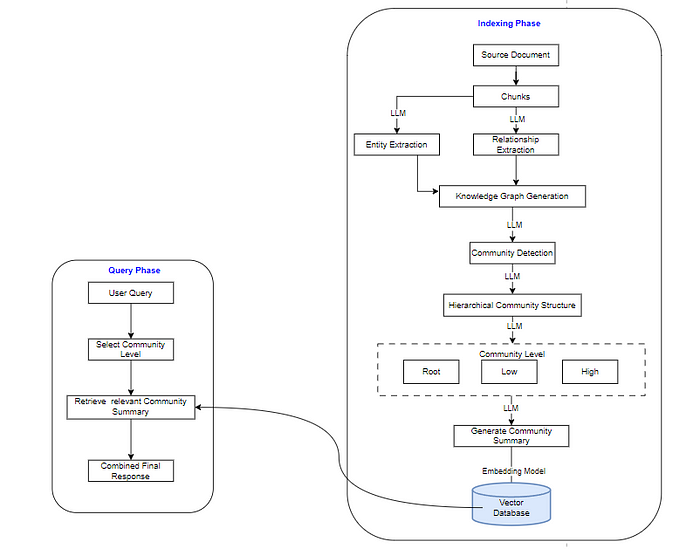
LLM之RAG理论(十二)| RAG和Graph RAG对比
最近Graph RAG非常火,它来自微软的一篇论文《From Local to Global: A Graph RAG Approach to Query-Focused Summarization》,论文地址:https://arxiv.org/pdf/2404.16130。本文将对RAG 和 Graph RAG在架构和成本方面做简要分析。
一、RAG …

家里灰尘多又不想打扫。教你一招,省时省事,除尘很轻松
出差半个月前,我住在新装修的房子里两周。在新餐桌上铺了一块桌布,结果一周后布上就积了一层灰尘。而且,那些夜里,我经常听到妻子剧烈咳嗽,令人担心。她有中度肺部疾病,平时非常注意卫生,每天都…

mysql高阶语句:
mysql高阶语句:
高级语法的查询语句:
select * from 表名 where limitsdistinct 去重查询like 模糊查询
排序语法:关键字排序 升序和降序
默认的排序方式就是升序
升序:ASC 配合order by语法
select * from 表名…

大模型应用—大模型赋能搜索
大模型赋能搜索
AI正在改变搜索体验,使其对我们来说更加智能、个性化和高效。
你可能会想,“但是谷歌已经足够好了!”首先,谷歌的搜索相关性和个性化是有代价的,那么跨不同媒体类型的搜索呢?对于最相关的信息格式,甚至是自动化某些任务,比如抓取网站、索引内容和搜索…

因为很会用工具,拿下了很多客户!
作为一名想要得到更多业绩的打工人,能提高工作效率的工具一定要拥有!
今天,就给大家分享一个职场必备的提效神器,一起来看看它都有哪些功能吧!
1、多渠道客源
它可以从多个渠道去获取你想要的客户资源,无…

CSS画边框线带有渐变线和流光边框实例
流光边框css流光边框动画效果_哔哩哔哩_bilibili流光边框css流光边框动画效果_哔哩哔哩_bilibili纯CSS写一个动态流水灯边框的效果~_哔哩哔哩_bilibili荧光边框CSS 动画发光渐变边框特效_哔哩哔哩_bilibili
[data-v-25d37a3a] .flow-dialog-custom {background-col…

简单使用SpringMVC写一个图书管理系统的登入功能和图书展示功能
准备好前端的代码 这里已经准备好了前端的代码,这里仅仅简单的介绍登入功能,和展示图书列表的功能。
如图: 如上图所示,这里的前端代码还是比较多的,在这里我介绍,login.html还有book_list.html这两个。 l…

springboot智慧草莓基地管理系统--论文源码调试讲解
3 系统分析
当用户确定开发一款程序时,是需要遵循下面的顺序进行工作,概括为:系统分析-->系统设计-->系统开发-->系统测试,无论这个过程是否有变更或者迭代,都是按照这样的顺序开展工作的。系统分析就是分析…

golang 基础 泛型编程
(一) 示例1
package _caseimport "fmt"// 定义用户类型的结构体
type user struct {ID int64Name stringAge uint8
}// 定义地址类型的结构体
type address struct {ID intProvince stringCity string
}// 集合转列表函数&#…

83. UE5 RPG 实现属性值的设置
在前面,我们实现了角色升级相关的功能,在PlayerState上记录了角色的等级和经验值,并在变动时,通过委托广播的形式向外广播,然后在UI上,通过监听委托的变动,进行修改等级和经验值。 在这一篇里&a…

GoogleCTF2023 Writeup
GoogleCTF2023 Writeup
Misc
NPC
Crypto
LEAST COMMON GENOMINATOR?
Web
UNDER-CONSTRUCTION
NPC
A friend handed me this map and told me that it will lead me to the flag. It is confusing me and I don’t know how to read it, can you help me out?
Attach…

Unity 批处理详讲(含URP)
咱们在项目中,优化性能最重要的一个环节就是合批处理,,在早期Unity中,对于合批的处理手段主要有三种:
Static Batching Dynamic Batching GPU Instancing
如今Unity 为了提升合批范围与效率,提供了…

昇思 25 天学习打卡营第 15 天 | mindspore 实现 VisionTransformer 图像分类
1. 背景:
使用 mindspore 学习神经网络,打卡第 15 天;主要内容也依据 mindspore 的学习记录。
2. Vision Transformer 介绍:
mindspore 实现 VisionTransformer 图像分类;VisionTransformer 论文地址 VisionTransfo…

掌握Python:三本不可错过的经典书籍
强烈推荐Python初学者用这三本书入门!
Python3剑客
一、《Python编程从入门到实践》
这本书适合零基础的Python读者,旨在帮助他们快速入门Python编程,并达到初级开发者的水平。书中深入浅出地介绍了Python的基础概念,如变量、循环、函数等…

华清数据结构day4 24-7-19
链表的相关操作
linklist.h
#ifndef LINKLIST_H
#define LINKLIST_H
#include <myhead.h>
typedef int datatype;
typedef struct Node
{union{int len;datatype data;};struct Node *next;
} Node, *NodePtr;NodePtr list_create();
NodePtr apply_node(datatype e);
…
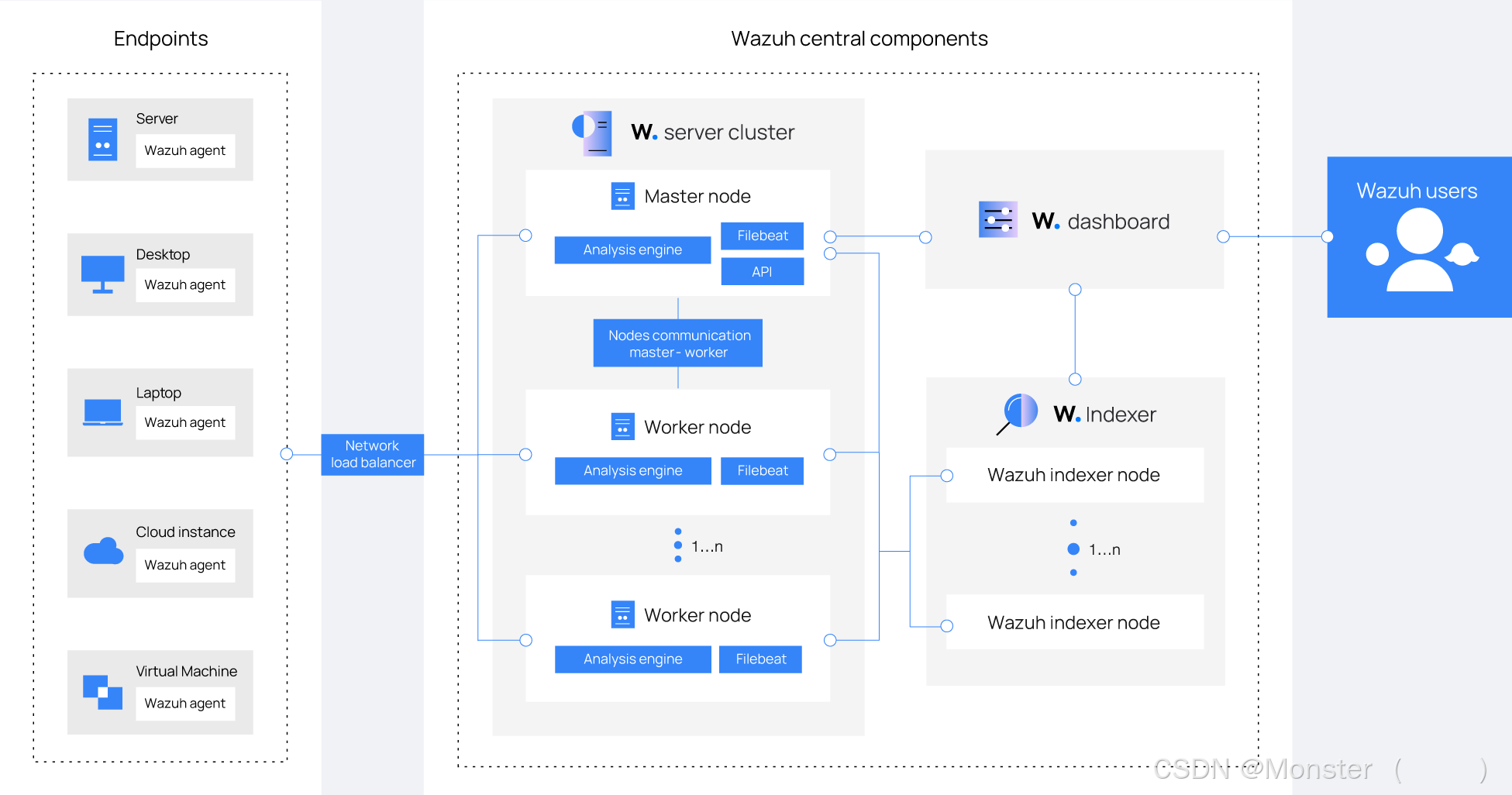
开源XDR-SIEM一体化平台 Wazuh (1)基础架构
简介
Wazuh平台提供了XDR和SIEM功能,保护云、容器和服务器工作负载。这些功能包括日志数据分析、入侵和恶意软件检测、文件完整性监控、配置评估、漏洞检测以及对法规遵从性的支持。详细信息可以参考Wazuh - Open Source XDR. Open Source SIEM.官方网站
Wazuh解决…

秒懂C++之string类(上)
目录 一.string类的常用接口说明
二.不太常用接口(了解接口)
三.string类的遍历访问
3.1 迭代器iterator
3.2 反向迭代器
四.string的其他功能
4.1 reserve(扩容)
4.2 resize
4.3 at
4.4 append
4.5
4.6 insert 一.string类的常用…