最近Graph RAG非常火,它来自微软的一篇论文《From Local to Global: A Graph RAG Approach to Query-Focused Summarization》,论文地址:https://arxiv.org/pdf/2404.16130。本文将对RAG 和 Graph RAG在架构和成本方面做简要分析。
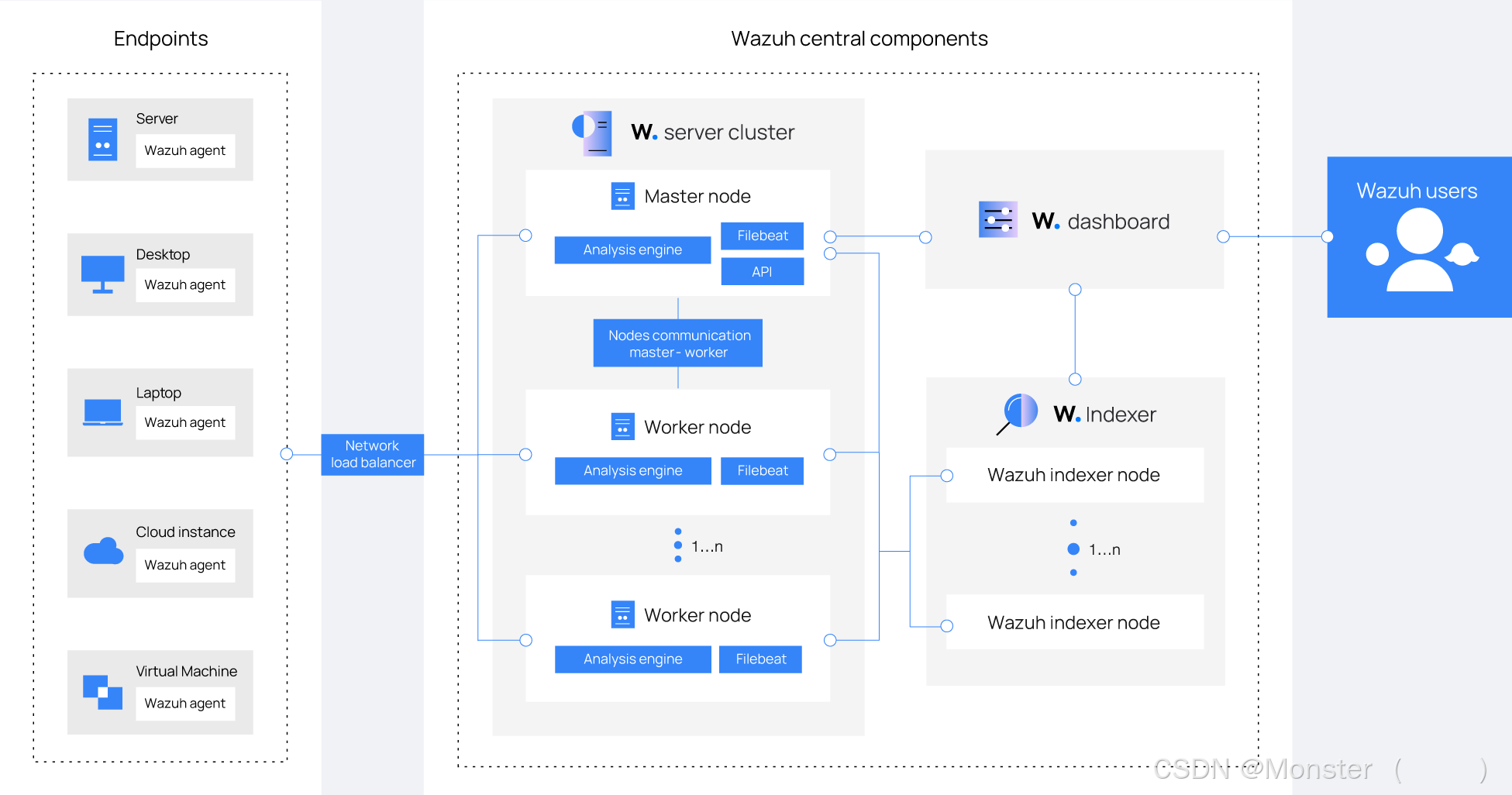
一、RAG 和 Graph RAG 的架构
RAG 方法体系结构可以分为两个不同的阶段:索引阶段和查询阶段。
在索引阶段,将完成非结构化文本的预处理和矢量存储中的存储。
在查询阶段,将用户查询通过嵌入模型转换为嵌入,并从向量数据库中检索类似的内容,LLM根据问题和检索内容生成答案。
1.1 RAG架构
检索增强生成(RAG)是一个框架,通过支持外部知识源的模型来补充LLM信息的内部表示,从而提高LLM生成响应的质量。
在基于LLM问答的系统中实施 RAG 的主要好处是它确保模型可以访问最新、最可靠的事实,并且用户可以访问模型的来源,确保其声明可以被检查为准确性并最终被信任。
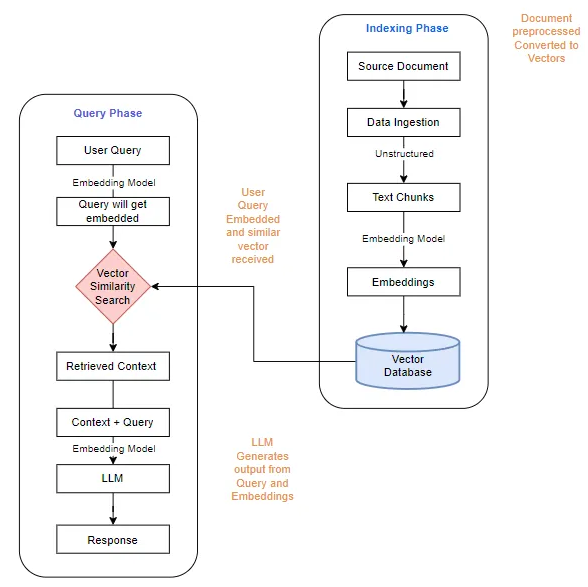
1.2 Graph RAG
在检索增强生成 (RAG) 的上下文中,Graph RAG 引入了一项重大增强功能:使用大型语言模型 (LLM(最好是 GPT-4) 将源文档块转换为实体和关系。这个预处理步骤至关重要,因为实体及其之间关系的准确提取对于后续的知识图谱构建至关重要,这因领域而异。
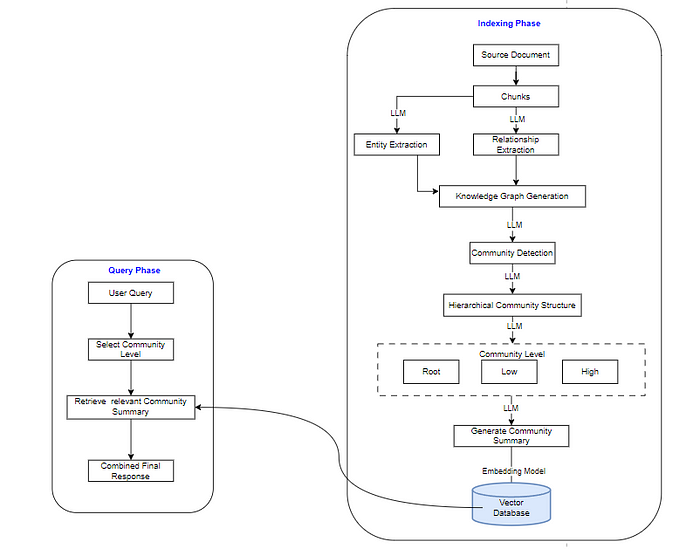
当我们仔细观察架构时,我们可以看到,首先将文档拆分为可管理的块,并将这些块转换为实体和关系,这些实体和关系构成了知识图谱的基础。利用 LLM,我们为每个节点确定最接近的社区,从而创建分层结构。此层次结构允许模型生成社区级别的摘要,然后将其存储在向量数据库中。
当用户提交查询时,将对其进行处理以标识最相关的社区级别。系统从排名最高的社区检索摘要,并使用 LLM。
二、RAG 和 Graph RAG 的成本
RAG(检索增强生成)和 Graph RAG 都有自己的优点和缺点。从我审查过的几个测试用例来看,每种方法产生的响应都存在显着差异。
与传统 RAG 相比,Graph RAG 的主要优势在于它能够检索有关查询中提到的实体的全面详细信息。Graph RAG 不仅获取有关查询实体的详细信息,还标识并将其与其他连接的实体相关联。相比之下,标准 RAG 检索的信息仅限于特定文档块,更广泛的关系和联系捕获不足。
Graph RAG 的增强功能也有其自身的挑战。在我的实验中,我提取了一个包含大约 83,000 个令牌的文件,这些令牌需要分块和嵌入。使用标准的 RAG 方法,使用大致相同数量的令牌创建嵌入。当我使用 Graph RAG 摄取同一个文件时,该过程涉及大量的提示和处理,产生了大约 1,000,000 个令牌——几乎是单个文件原始令牌计数的 12 倍。