Bert概述
BERT(Bidirectional Encoder Representations from Transformers)是一种深度学习模型,用于自然语言处理(NLP)任务。BERT的核心是由一种强大的神经网络架构——Transformer驱动的。这种架构包含了一种称为自注意力的机制,使BERT能够根据上下文(前后文)来衡量每个词的重要性。这种上下文感知赋予BERT生成上下文化词嵌入的能力,即考虑句子中词义的词表示。这就像BERT反复阅读句子以深入理解每个词的作用。
BERT的训练方式有两种:Masked Language Model和Next Sentence Prediction。参考这里
基于BERT实现文本情感分类
所谓情感分类就是指判断句子是积极情感还是消极情感,例如说“今天这顿饭太美味了”是积极的情感,“今天这顿饭简直吃不下去”是消极的情感。
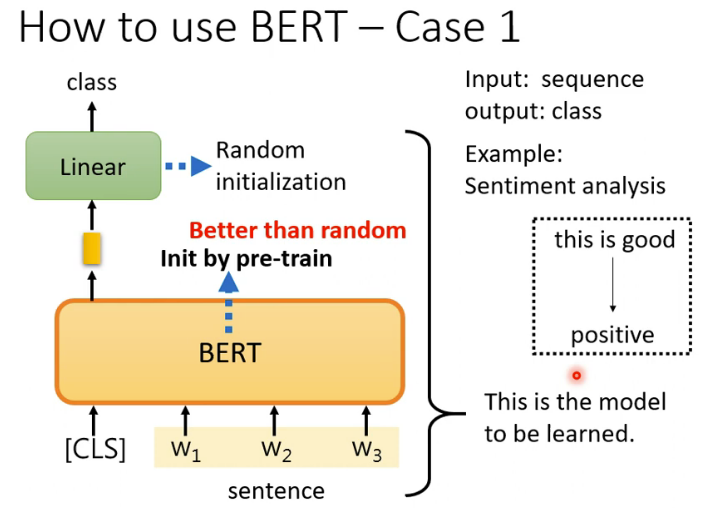
基于BERT完成情感分类的基本思路如图所示。我们知道BERT是一个预训练模型,我们把句子扔给它的时候,它对应每个字都会输出一个向量。但是在把句子扔给BERT之前,我们会在句子最前面增加一个特殊符号[CLS]。对应这个[CLS],BERT也会输出一个向量,我们就是利用这个向量来进行情感分类。为什么可以直接利用这个向量呢?这是因为BERT内部采用的是自注意力机制,自注意力机制的特点是考虑全局又聚焦重点,实际上[CLS]对应的向量已经嵌入了整个句子的信息,而且重点词字嵌入的信息权重要大。所以,我们将这个向量扔给一个全连接层,就可以完成分类任务了。参考这里
代码
数据预处理
数据集的下载,提取码为zfh3
import pandas as pd
import os
import logging
logging.basicConfig(format='%(asctime)s - %(levelname)s - %(name)s - %(message)s',
datefmt='%m/%d/%Y %H:%M:%S',
level=logging.INFO)
logger = logging.getLogger(__name__)
class InputExample(object):
"""A single training/test example for simple sequence classification."""
def __init__(self, text, label=None):
self.text = text
self.label = label
class InputFeatures(object):
"""A single set of features of data."""
def __init__(self, input_ids, input_mask, segment_ids, label_id):
self.input_ids = input_ids
self.input_mask = input_mask
self.segment_ids = segment_ids
self.label_id = label_id
class DataProcessor(object):
"""Base class for data converters for sequence classification data sets."""
def get_train_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the train set."""
raise NotImplementedError()
def get_dev_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the dev set."""
raise NotImplementedError()
def get_test_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the test set."""
raise NotImplementedError()
def get_labels(self):
"""Gets the list of labels for this data set."""
raise NotImplementedError()
@classmethod
def _read_csv(cls, input_file, quotechar=None):
"""Reads a tab separated value file."""
# dicts = []
data = pd.read_csv(input_file)
return data
class MyPro(DataProcessor):
'''自定义数据读取方法,针对json文件
Returns:
examples: 数据集,包含index、中文文本、类别三个部分
'''
def get_train_examples(self, data_dir):
return self._create_examples(
self._read_csv(os.path.join(data_dir, 'train_data.csv')), 'train')
def get_dev_examples(self, data_dir):
return self._create_examples(
self._read_csv(os.path.join(data_dir, 'dev_data.csv')), 'dev')
def get_test_examples(self, data_dir):
return self._create_examples(
self._read_csv(os.path.join(data_dir, 'test_data.csv')), 'test')
def get_labels(self):
return [0, 1]
def _create_examples(self, data, set_type):
examples = []
for index, row in data.iterrows():
# guid = "%s-%s" % (set_type, i)
text = row['review']
label = row['label']
examples.append(
InputExample(text=text, label=label))
return examples
def convert_examples_to_features(examples, label_list, max_seq_length, tokenizer, show_exp=True):
'''Loads a data file into a list of `InputBatch`s.
Args:
examples : [List] 输入样本,句子和label
label_list : [List] 所有可能的类别,0和1
max_seq_length: [int] 文本最大长度
tokenizer : [Method] 分词方法
Returns:
features:
input_ids : [ListOf] token的id,在chinese模式中就是每个分词的id,对应一个word vector
input_mask : [ListOfInt] 真实字符对应1,补全字符对应0
segment_ids: [ListOfInt] 句子标识符,第一句全为0,第二句全为1
label_id : [ListOfInt] 将Label_list转化为相应的id表示
'''
label_map = {}
for (i, label) in enumerate(label_list):
label_map[label] = i
features = []
for (ex_index, example) in enumerate(examples):
# 分词
tokens = tokenizer.tokenize(example.text)
# tokens进行编码
encode_dict = tokenizer.encode_plus(text=tokens,
max_length=max_seq_length,
pad_to_max_length=True,
is_pretokenized=True,
return_token_type_ids=True,
return_attention_mask=True)
input_ids = encode_dict['input_ids']
input_mask = encode_dict['attention_mask']
segment_ids = encode_dict['token_type_ids']
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
label_id = label_map[example.label]
if ex_index < 5 and show_exp:
logger.info("*** Example ***")
logger.info("tokens: %s" % " ".join(
[str(x) for x in tokens]))
logger.info("input_ids: %s" % " ".join([str(x) for x in input_ids]))
logger.info("input_mask: %s" % " ".join([str(x) for x in input_mask]))
logger.info(
"segment_ids: %s" % " ".join([str(x) for x in segment_ids]))
logger.info("label: %s (id = %d)" % (example.label, label_id))
features.append(
InputFeatures(input_ids=input_ids,
input_mask=input_mask,
segment_ids=segment_ids,
label_id=label_id))
return features
如何理解?
将原始文本数据通过分词、编码等步骤转换为模型训练所需的格式,包括input_ids(编码后的token)、input_mask(注意力掩码)和segment_ids(token类型ids)。这些数据将作为模型的输入。
假设我们有一个文本示例,并且我们使用BERT分词器进行预处理。以下是示例文本和初始化分词器的代码:
from transformers import BertTokenizer # 示例文本 text = "Hello, how are you?" # 初始化BERT分词器 tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') # 假设最大序列长度为10 max_seq_length = 10接下来,我们将通过上面的代码片段对文本进行预处理:
# 假设我们的examples是一个包含单个文本的列表 examples = [{'text': text}] # 遍历示例列表 for (ex_index, example) in enumerate(examples): # 分词 tokens = tokenizer.tokenize(example['text']) # tokens进行编码 encode_dict = tokenizer.encode_plus( text=tokens, max_length=max_seq_length, pad_to_max_length=True, is_pretokenized=True, return_token_type_ids=True, return_attention_mask=True ) input_ids = encode_dict['input_ids'] input_mask = encode_dict['attention_mask'] segment_ids = encode_dict['token_type_ids'] # 打印结果 print(f"Example {ex_index}") print(f"Tokens: {tokens}") print(f"Input IDs: {input_ids}") print(f"Input Mask: {input_mask}") print(f"Segment IDs: {segment_ids}")执行上述代码后,我们将得到以下输出(输出可能会根据BERT模型的版本和分词器设置略有不同):
Example 0 Tokens: ['Hello', ',', 'how', 'are', 'you', '?'] Input IDs: [101, 7592, 1010, 2129, 2026, 102, 0, 0, 0, 0] Input Mask: [1, 1, 1, 1, 1, 1, 0, 0, 0, 0] Segment IDs: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]解释输出:
- Tokens: 这是分词后的结果,原始文本被拆分为BERT模型可以理解的token。
- Input IDs: 每个token被转换为一个唯一的整数ID,表示其在词汇表中的位置。
- Input Mask: 表示哪些位置是真正的token(1),哪些位置是填充的(0)。在这个例子中,填充的部分是最后四个0。
- Segment IDs: 由于我们只有一个句子,所以所有token的segment ID都是0。如果文本包含多个句子,第二个句子的token将有一个不同的segment ID(通常是1)。
数据处理成dataSet
import torch
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, features, mode):
self.nums = len(features)
self.input_ids = [torch.tensor(example.input_ids).long() for example in features]
self.input_mask = [torch.tensor(example.input_mask).float() for example in features]
self.segment_ids = [torch.tensor(example.segment_ids).long() for example in features]
self.label_id = None
if mode == 'train' or 'test':
self.label_id = [torch.tensor(example.label_id) for example in features]
def __getitem__(self, index):
data = {'input_ids': self.input_ids[index],
'input_mask': self.input_mask[index],
'segment_ids': self.segment_ids[index]}
if self.label_id is not None:
data['label_id'] = self.label_id[index]
return data
def __len__(self):
return self.nums
模型的搭建
from torch import nn
import os
from transformers import BertModel
class ClassifierModel(nn.Module):
def __init__(self,
bert_dir,
dropout_prob=0.1):
super(ClassifierModel, self).__init__()
config_path = os.path.join(bert_dir, 'config.json')
assert os.path.exists(bert_dir) and os.path.exists(config_path), \
'pretrained bert file does not exist'
self.bert_module = BertModel.from_pretrained(bert_dir)
self.bert_config = self.bert_module.config
self.dropout_layer = nn.Dropout(dropout_prob)
out_dims = self.bert_config.hidden_size
self.obj_classifier = nn.Linear(out_dims, 2)
def forward(self,
input_ids,
input_mask,
segment_ids,
label_id=None):
bert_outputs = self.bert_module(
input_ids=input_ids,
attention_mask=input_mask,
token_type_ids=segment_ids
)
seq_out, pooled_out = bert_outputs[0], bert_outputs[1]
#对反向传播及逆行截断
x = pooled_out.detach()
out = self.obj_classifier(x)
return out
模型的训练
BERT是一个预训练模型,我们把句子扔给它的时候,它对应每个字都会输出一个向量。【下载Bert模型==>操作手册】
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import *
from dataset import *
from dataProcessor import *
import matplotlib.pyplot as plt
import time
from transformers import BertTokenizer
from transformers import logging
logging.set_verbosity_warning()
# 加载训练数据
datadir = "data"
bert_dir = "bert\\bert-chinese"
my_processor = MyPro()
label_list = my_processor.get_labels()
train_data = my_processor.get_train_examples(datadir)
test_data = my_processor.get_test_examples(datadir)
tokenizer = BertTokenizer.from_pretrained(bert_dir)
train_features = convert_examples_to_features(train_data, label_list, 128, tokenizer)
test_features = convert_examples_to_features(test_data, label_list, 128, tokenizer)
train_dataset = MyDataset(train_features, 'train')
test_dataset = MyDataset(test_features, 'test')
train_data_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
test_data_loader = DataLoader(dataset=test_dataset, batch_size=64, shuffle=True)
train_data_len = len(train_dataset)
test_data_len = len(test_dataset)
print(f"训练集长度:{train_data_len}")
print(f"测试集长度:{test_data_len}")
# 创建网络模型
my_model = ClassifierModel(bert_dir)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
learning_rate = 5e-3
#optimizer = torch.optim.SGD(my_model.parameters(), lr=learning_rate)
# Adam 参数betas=(0.9, 0.99)
optimizer = torch.optim.Adam(my_model.parameters(), lr=learning_rate, betas=(0.9, 0.99))
# 总共的训练步数
total_train_step = 0
# 总共的测试步数
total_test_step = 0
step = 0
epoch = 50
train_loss_his = []
train_totalaccuracy_his = []
test_totalloss_his = []
test_totalaccuracy_his = []
start_time = time.time()
my_model.train()
for i in range(epoch):
print(f"-------第{i}轮训练开始-------")
train_total_accuracy = 0
for step, batch_data in enumerate(train_data_loader):
# writer.add_images("tarin_data", imgs, total_train_step)
print(batch_data['input_ids'].shape)
output = my_model(**batch_data)
loss = loss_fn(output, batch_data['label_id'])
train_accuracy = (output.argmax(1) == batch_data['label_id']).sum()
train_total_accuracy = train_total_accuracy + train_accuracy
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
train_loss_his.append(loss)
#writer.add_scalar("train_loss", loss.item(), total_train_step)
train_total_accuracy = train_total_accuracy / train_data_len
print(f"训练集上的准确率:{train_total_accuracy}")
train_totalaccuracy_his.append(train_total_accuracy)
# 测试开始
total_test_loss = 0
my_model.eval()
test_total_accuracy = 0
with torch.no_grad():
for batch_data in test_data_loader:
output = my_model(**batch_data)
loss = loss_fn(output, batch_data['label_id'])
total_test_loss = total_test_loss + loss
test_accuracy = (output.argmax(1) == batch_data['label_id']).sum()
test_total_accuracy = test_total_accuracy + test_accuracy
test_total_accuracy = test_total_accuracy / test_data_len
print(f"测试集上的准确率:{test_total_accuracy}")
print(f"测试集上的loss:{total_test_loss}")
test_totalloss_his.append(total_test_loss)
test_totalaccuracy_his.append(test_total_accuracy)
torch.save(my_model, "bert_{}.pth".format(i))
print("模型已保存")
模型的预测
# 假设这是您的分词器和预处理函数
from torch.utils.data import DataLoader
from transformers import BertTokenizer
import torch
from dataProcessor import convert_examples_to_features, MyPro, InputExample
from dataset import MyDataset
bert_dir = "bert\\bert-chinese"
tokenizer = BertTokenizer.from_pretrained(bert_dir)
my_processor = MyPro()
label_list = my_processor.get_labels()
# 从键盘读取输入
input_text = input("请输入一句话来判断其情感:")
# 创建一个InputExample对象
input_texts = InputExample(text=input_text, label=0) # 假设0表示消极,1表示积极
# 使用convert_examples_to_features函数处理输入语句
test_features = convert_examples_to_features([input_texts], label_list, 128, tokenizer)
test_dataset = MyDataset(test_features, 'test')
test_data_loader = DataLoader(dataset=test_dataset, batch_size=64, shuffle=True)
# 加载模型
my_model = torch.load("bert_10.pth", map_location=torch.device('cpu'))
my_model.eval()
with torch.no_grad():
for batch_data in test_data_loader:
outputs = my_model(**batch_data)
# 判断类别
if outputs.argmax().item() == 1:
print("积极")
else:
print("消极")
视频推荐
Bert模型和Transformer到底哪个更牛?
用BERT做下游任务的栗子
文章推荐
BERT与Transformer:深入比较两者的差异 (baidu.com)
BERT模型和Transformer模型之间有何关系?_bert和transformer的关系-CSDN博客
掌握BERT:从初学者到高级的自然语言处理(NLP)全面指南 - IcyFeather233 - 博客园 (cnblogs.com)













![AGI 之 【Hugging Face】 的【从零训练Transformer模型】之一 [ 如何寻找大型数据集 ] / [ 构建词元分析器 ] 的简单整理](https://i-blog.csdnimg.cn/direct/4648a918decd4b65b10337c2e632013f.png)