LLM 指令微调
- LLM 指令微调
- 0. 概览
- 1. 指令数据的构建
- 1.1 基于现有NLP任务数据集构建
- 1.2 基于日常对话数据构建
- 1.3 基于合成数据构建
- 1.4 指令数据构建的提升方法
- 2. 指令微调的策略
- 2.1 优化设置
- 2.2 数据组织策略
- 3. 参数高效的模型微调
- 3.1 低秩适配微调方法
- 3.2 其他高效微调方法
- 4. 与预训练的区别
- 5. 实践经验
0. 概览
指令微调基本步骤:
- 准备预训练模型
- 准备微调数据集
- 设计输入输出格式
- 微调模型
- 评估测试
- 应用部署
1. 指令数据的构建
1.1 基于现有NLP任务数据集构建
1.2 基于日常对话数据构建
1.3 基于合成数据构建
1.4 指令数据构建的提升方法
2. 指令微调的策略
在训练方式上,指令微调与预训练较为相似,下面详细介绍指令微调所特有的策略。
2.1 优化设置
指令微调中优化器的设置(AdamW或者Adafactor)、 稳定训练技巧(权重衰减、梯度裁剪)和训练技术(3D并行、ZeRO和混合精度训练)都和预训练保持一致。完全可以沿用。
指令微调的不同之处:
- 目标函数:预训练阶段一般采用语言函数建模损失。指令微调可以被视为一个有监督的训练过程,通常采用的目标函数为序列到序列的损失,仅在输出部分计算损失,而不计算输入部分的损失。
- 批次大小与学习率:较小的批次大小和学习率。比如InstructGPT 微调的batchsize=8,学习率为5.0310-6.Alpaca的batchsize=128,学习率预热到210-5 然后采用余弦衰减策略.
- 多轮对话数据的高效训练:对于多轮对话数据,通常的训练是将其拆分成多个不同的对话数据进行单独训练。为了提升效率,可以采用特殊的掩码机制来实现多轮对话数据的高效训练。在因果解码架构中,由于输入输出没有明显的界限,可以将所有一个对话的多轮内容一次性输入模型,通过设计损失掩码来实现仅针对每轮对话的模型输出部分进行损失计算,从而显著减少重复前缀计算的开销。 只有因果解码架构可以实现这样的?
2.2 数据组织策略
- 平衡数据分布
- 多阶段指令数据微调
- 结合预训练数据与指令微调
3. 参数高效的模型微调
参数高效微调是一个重要研究方向,旨在减少需要训练的模型参数,同时保证微调后的模型性能 能够与全量微调的表现相媲美。
3.1 低秩适配微调方法

-
LoRA 基础
大语言模型汇总包含大量的线性变换层,其中参数矩阵的维度非常高,LoRA论文中发现模型在针对特定任务进行适配时,参数矩阵往往是过参数化的,其存在一个较低的内在秩。为了解决这个问题,LoRA提出在预训练模型的参数矩阵上添加低秩分解矩阵来近似每层的参数更新,从而减少适配下游任务所需要训练的参数。给定一个参数矩阵W,其更新过程可以一般性地表达为 W = W 0 + Δ W W = W_0 + \Delta W W=W0+ΔW
其中 W 0 W_0 W0是原始参数矩阵, Δ W \Delta W ΔW是更新的梯度矩阵。
LoRA的基本思想是冻结原始矩阵W0,通过低秩分解矩阵A(HR),B(HR)来近似参数更新矩阵 Δ W = A ∗ B T \Delta W = A*B^T ΔW=A∗BT,其中R<<H 是减小后的秩。在微调期间,原始矩阵参数W0,不会被更新,低秩分解矩阵A和B则时可训练参数用于适配下游任务。在前向传播过程中,原始计算中间状态 h = W 0 ∗ x h = W_0 * x h=W0∗x 的更是可以修改为 h = W 0 ∗ x + A ∗ B T ∗ x h = W_0*x + A*B^T*x h=W0∗x+A∗BT∗x
在训练完成后,进一步将原始参数矩阵W0 和训练得到的权重A和B进行合并, W = W 0 + A B T W=W_0+AB^T W=W0+ABT,得到更新后的参数矩阵。因次LoRA 微调得到的模型在解码中不会增加额外开销。 -
LoRA 所需的显存估计
LoRA 微调需要的显存大小从全量微调的16P大幅减少为 2 P + 16 P L o R A 2P+16P_{LoRA} 2P+16PLoRA
-
LoRA 变种
在原始的LoRA中,每个低秩矩阵的低秩参数R都被设定为固定且相同的数值,并且在训练过程中无法进行调整,这种设定忽略了不同的秩在微调任务中可能产生的差异化影响。因此通过这种方式训练得到的低秩矩阵往往并非最优解。
AdaLoRA 讨论了如何更好地进行秩的设置。它引入了一种动态低秩适应技术,在训练过程中 动态调整每个参数矩阵需要训练的秩的同时控制训练的参数总量。模型在微调过程中通过损失来衡量每个参数矩阵对训练结果的重要性,重要性较高的参数矩阵被赋予较高的秩,进而能更好地学习到有助于任务的信息。相对而言,不太重要的参数矩阵被赋予比较低的秩,来防止过拟合并节省计算资源。
QLoRA 将原始的参数矩阵量化为4比特,而低秩参数部分仍使用16比特进行训练,在保持微调效果的同时进一步节省了显存开销。给定参数为P的模型,QLoRA微调所需的显存 由 LoRA微调所需显存2P 降低为0.5P,这样就可以在一个48GB的GPU上微调65B的模型,接近16比特模型微调的性能.
- ZeroQuant,SmoothQuant
3.2 其他高效微调方法
-
适配器微调
- Adapter Tuning, 在transformer中引入小型神经网络模块。为了实现适配器微调,研究者提出使用瓶颈网络架构:首先将原始的特质向量压缩到较低维度,然后使用激活函数进行非线性变换,最后再恢复到原始维度。KaTeX parse error: Undefined control sequence: \sigmoid at position 9: h = h + \̲s̲i̲g̲m̲o̲i̲d̲(h*W^d)*W^u,其中𝑾𝑑 ∈ R(𝐻×𝑅),𝑾𝑢 ∈ R(𝑅×𝐻),且𝑅 ≪ 𝐻。通常来说,适配器模块将会被集成到Transformer 架构的每一层中,使用串行的方式分别插入在多头注意力层和前馈网络层之后、层归一化之前。在微调过程中,适配器模块将根据特定的任务目标进行优化,而原始的语言模型参数在这个过程中保持不变。通过这种方式,可以在微调过程中有效减少需要训练参数的数量。

- Adapter Tuning, 在transformer中引入小型神经网络模块。为了实现适配器微调,研究者提出使用瓶颈网络架构:首先将原始的特质向量压缩到较低维度,然后使用激活函数进行非线性变换,最后再恢复到原始维度。KaTeX parse error: Undefined control sequence: \sigmoid at position 9: h = h + \̲s̲i̲g̲m̲o̲i̲d̲(h*W^d)*W^u,其中𝑾𝑑 ∈ R(𝐻×𝑅),𝑾𝑢 ∈ R(𝑅×𝐻),且𝑅 ≪ 𝐻。通常来说,适配器模块将会被集成到Transformer 架构的每一层中,使用串行的方式分别插入在多头注意力层和前馈网络层之后、层归一化之前。在微调过程中,适配器模块将根据特定的任务目标进行优化,而原始的语言模型参数在这个过程中保持不变。通过这种方式,可以在微调过程中有效减少需要训练参数的数量。
-
前缀微调
- prefix Tuning. 在语言模型的每个多头注意力层中都添加一组前缀参数。这些前缀参数组成了一个可训练的连续矩阵,可以视为若干虚拟词元的嵌入向量,他们会根据特定任务进行学习。具体实现上,基于原始的注意力计算公式,一系列前缀词元被拼接到每个注意力的键向量与值向量(key 和value)之前,每个head的计算公式可以表示为:
h
e
a
d
=
A
t
t
e
n
t
i
o
n
(
X
W
Q
,
P
K
⊕
X
W
K
,
P
V
⊕
X
W
V
)
head = Attention(XW^Q,P^K⊕ XW^K, P^V⊕ XW^V)
head=Attention(XWQ,PK⊕XWK,PV⊕XWV) 其中Attention代表原始的注意力操作,⊕ 表示矩阵拼接,PK,PV是(L*H),L代表前缀向量的长度,一般在10-100之间,可以根据任务场景调整。为了更好的优化前缀向量,研究者提出了一种重参数化的技巧,引入了一个多层感知机的映射函数
P
=
M
L
P
θ
(
P
′
)
P=MLP_\theta(P')
P=MLPθ(P′).重参数化技巧可以将较小的矩阵映射到前缀参数矩阵,而不是直接优化前缀,这一技巧对稳定训练很有帮助。经过优化后,映射函数将被舍弃,只保留最终得到的前缀参数𝑷 来增强特定任务的性能。在前缀微调中,整个模型中只有前缀参数会被训练,因此可以实现参数高效的模型优化。

- prefix Tuning. 在语言模型的每个多头注意力层中都添加一组前缀参数。这些前缀参数组成了一个可训练的连续矩阵,可以视为若干虚拟词元的嵌入向量,他们会根据特定任务进行学习。具体实现上,基于原始的注意力计算公式,一系列前缀词元被拼接到每个注意力的键向量与值向量(key 和value)之前,每个head的计算公式可以表示为:
h
e
a
d
=
A
t
t
e
n
t
i
o
n
(
X
W
Q
,
P
K
⊕
X
W
K
,
P
V
⊕
X
W
V
)
head = Attention(XW^Q,P^K⊕ XW^K, P^V⊕ XW^V)
head=Attention(XWQ,PK⊕XWK,PV⊕XWV) 其中Attention代表原始的注意力操作,⊕ 表示矩阵拼接,PK,PV是(L*H),L代表前缀向量的长度,一般在10-100之间,可以根据任务场景调整。为了更好的优化前缀向量,研究者提出了一种重参数化的技巧,引入了一个多层感知机的映射函数
P
=
M
L
P
θ
(
P
′
)
P=MLP_\theta(P')
P=MLPθ(P′).重参数化技巧可以将较小的矩阵映射到前缀参数矩阵,而不是直接优化前缀,这一技巧对稳定训练很有帮助。经过优化后,映射函数将被舍弃,只保留最终得到的前缀参数𝑷 来增强特定任务的性能。在前缀微调中,整个模型中只有前缀参数会被训练,因此可以实现参数高效的模型优化。
-
提示微调
- P-tuning,Prompt Tuning.
- 提示微调仅在输入嵌入层中加入可训练的提示向量。首先在输入文本端插入一组连续嵌入数值的提示词元,这些词元可以自由形式或前缀形式来增强输入文本,用于解决特定的下游任务。在具体实现中,只需要将可学习的特定任务提示向量与输入文本向量结合起来一起输入到语言模型中。
- P-tuning 提出了使用自由形式来组合输入文本和提示向量,通过双向LSTM来学习软提示词元的表示,它可以同时使用于自然语言理解和生成任务。
- Prompt Tuning 以前缀形式添加提示,直接在输入前拼接连续型向量。
- 在提示微调的训练过程中,只有提示的嵌入向量会根据特定任务进行监督学习,然而由于只在输入层中包含了极少量的可训练参数,有研究工作表明该方法的性能高度依赖底层语言模型的能力。

4. 与预训练的区别
指令微调代码与预训练代码 高度一致,区别主要在于指令微调数据集的构建SFTData 和序列到序列损失的计算DataCollatorForSupervisedDataset.
- 使用与下游任务更接近的指令能够带来更大的提升。
- 提高指令复杂性和多样性能够促进语言模型性能的提升
- 更大的参数规模有助于提升模型指令遵循能力。
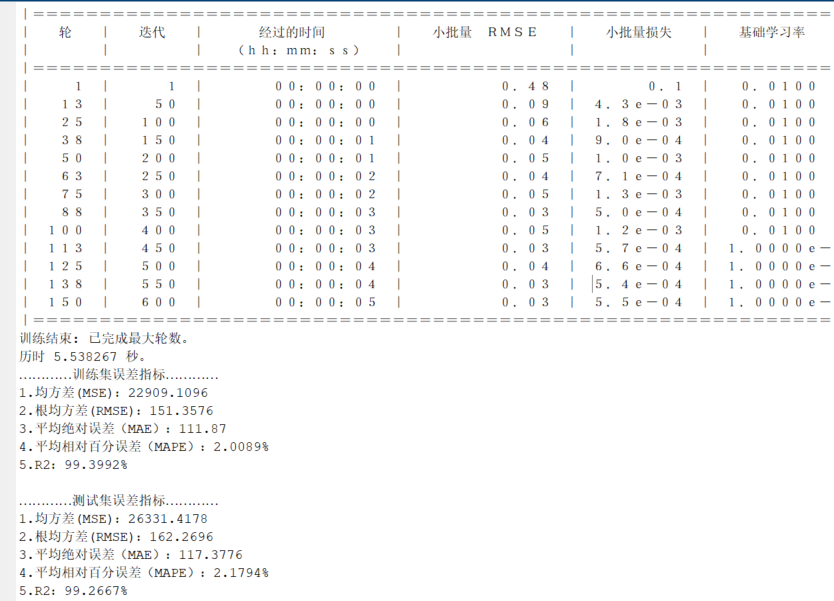
5. 实践经验
- QLoRA + FlashAttention 更省资源














![[MySQL]02 存储引擎与索引,锁机制,SQL优化](https://i-blog.csdnimg.cn/direct/4a7e96cd8fb34e92ae4184d7f333b0ef.png)