代码原理
基于CNN-BiLSTM的数据回归预测是一种结合卷积神经网络(CNN)和双向长短期记忆网络(BiLSTM)的混合模型,用于处理和预测时间序列数据。以下是该方法的简单原理及流程:
原理
(1)卷积神经网络(CNN):
- 特征提取:CNN用于从输入数据中提取局部特征,通过多个卷积层和池化层,CNN可以识别数据中的重要模式和特征。
(2)双向长短期记忆网络(BiLSTM):
- 序列处理:BiLSTM是一种改进的长短期记忆网络(LSTM),它包含两个LSTM网络:一个按时间顺序处理序列,另一个按时间逆序处理序列。通过双向处理,BiLSTM能够更全面地捕捉时间序列中的依赖关系和模式。
流程
(1)数据准备:
- 数据收集:收集所需的时间序列数据,确保数据的完整性和准确性。
- 数据预处理:进行数据清洗、归一化,并将数据分割成训练集和测试集。
(2)构建模型:
- 输入层:将预处理后的数据输入模型。
- 卷积层:使用多个卷积层从输入数据中提取局部特征,每个卷积层之后可能会接一个池化层,以减少特征维度,降低计算复杂度。
- BiLSTM层:将卷积层提取的特征序列输入到BiLSTM网络中。BiLSTM通过前向和后向两个LSTM网络处理数据,捕捉双向的时序依赖关系。
- 全连接层:将BiLSTM层输出的高维特征映射到目标回归值。
(3)模型训练:
- 损失函数:选择适合的损失函数(如均方误差)来评估模型的预测误差。
- 优化器:选择优化算法(如Adam)来调整模型参数,使损失函数最小化。
- 训练过程:通过多次迭代(epoch),使用训练集进行模型训练,不断优化模型参数。
(4)模型评估:
- 测试集评估:使用测试集评估模型的预测性能,计算误差指标(如均方误差、均方根误差等)。
- 调整和优化:根据评估结果,调整模型结构或超参数,进一步提升模型性能。
(5)预测和应用:
- 实际预测:将新数据输入训练好的模型,进行回归预测。
- 应用场景:根据具体应用需求,将预测结果用于实际业务决策或其他相关领域。
- 通过结合CNN和BiLSTM的优势,该混合模型能够更全面地捕捉时间序列数据中的重要特征和双向依赖关系,从而提供高精度的回归预测结果。
部分代码
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc
%% 导入数据
data = readmatrix('回归数据集.xlsx');
data = data(:,1:14);
res=data(randperm(size(data,1)),:); %此行代码用于打乱原始样本,使训练集测试集随机被抽取,有助于更新预测结果。
num_samples = size(res,1); %样本个数
% 训练集和测试集划分
outdim = 1; % 最后一列为输出
num_size = 0.7; % 训练集占数据集比例
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%% 数据平铺
for i = 1:size(P_train,2)
trainD{i,:} = (reshape(p_train(:,i),size(p_train,1),1,1));
end
for i = 1:size(p_test,2)
testD{i,:} = (reshape(p_test(:,i),size(p_test,1),1,1));
end
targetD = t_train;
targetD_test = t_test;
numFeatures = size(p_train,1);
layers0 = [ ...
% 输入特征
sequenceInputLayer([numFeatures,1,1],'name','input') %输入层设置
sequenceFoldingLayer('name','fold') %使用序列折叠层对图像序列的时间步长进行独立的卷积运算。
% CNN特征提取
convolution2dLayer([3,1],16,'Stride',[1,1],'name','conv1') %添加卷积层,64,1表示过滤器大小,10过滤器个数,Stride是垂直和水平过滤的步长
batchNormalizationLayer('name','batchnorm1') % BN层,用于加速训练过程,防止梯度消失或梯度爆炸
reluLayer('name','relu1') % ReLU激活层,用于保持输出的非线性性及修正梯度的问题
% 池化层
maxPooling2dLayer([2,1],'Stride',2,'Padding','same','name','maxpool') % 第一层池化层,包括3x3大小的池化窗口,步长为1,same填充方式
% 展开层
sequenceUnfoldingLayer('name','unfold') %独立的卷积运行结束后,要将序列恢复
%平滑层
flattenLayer('name','flatten')
bilstmLayer(25,'Outputmode','last','name','hidden1')
dropoutLayer(0.1,'name','dropout_1') % Dropout层,以概率为0.2丢弃输入
fullyConnectedLayer(1,'name','fullconnect') % 全连接层设置(影响输出维度)(cell层出来的输出层) %
regressionLayer('Name','output') ];
lgraph0 = layerGraph(layers0);
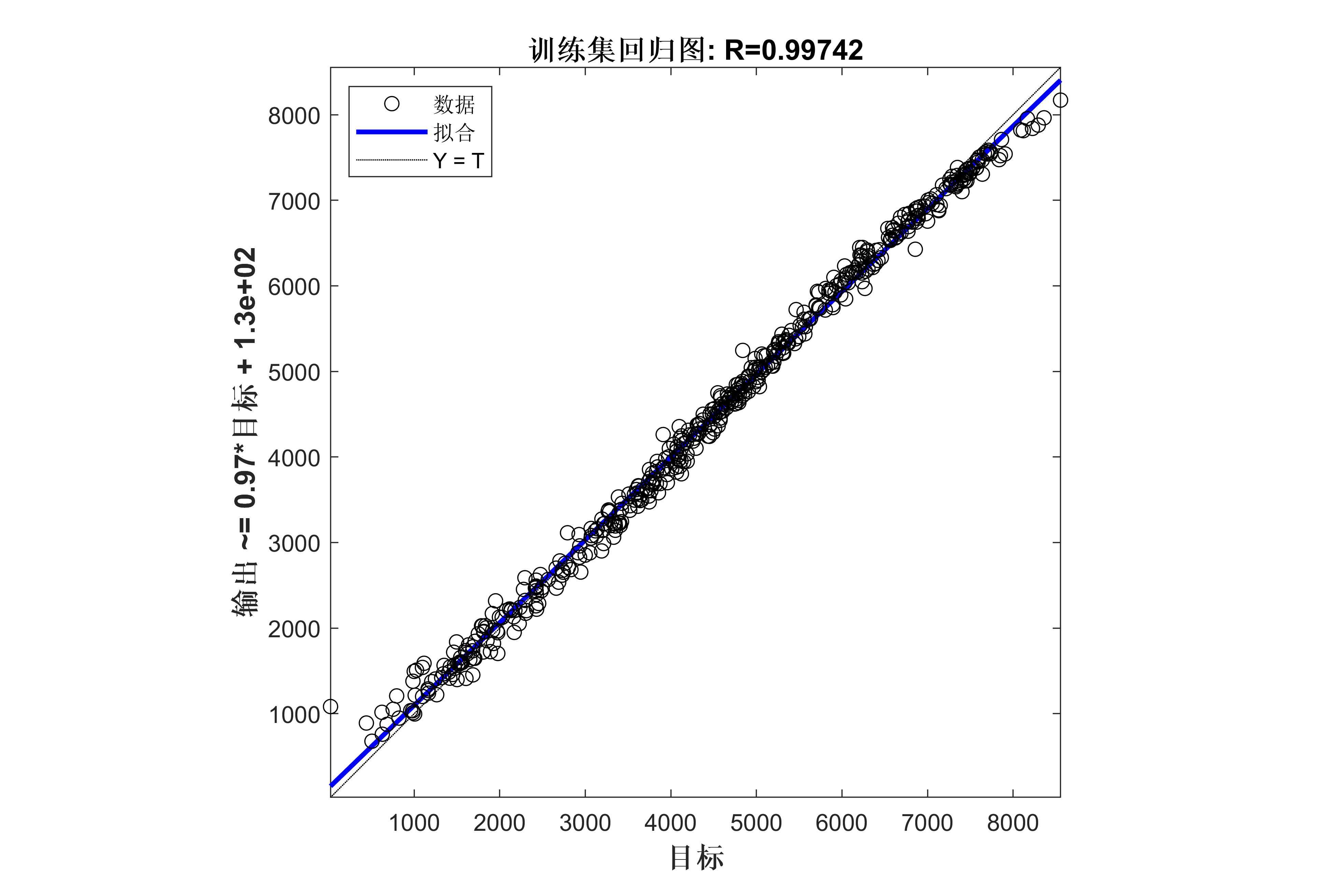
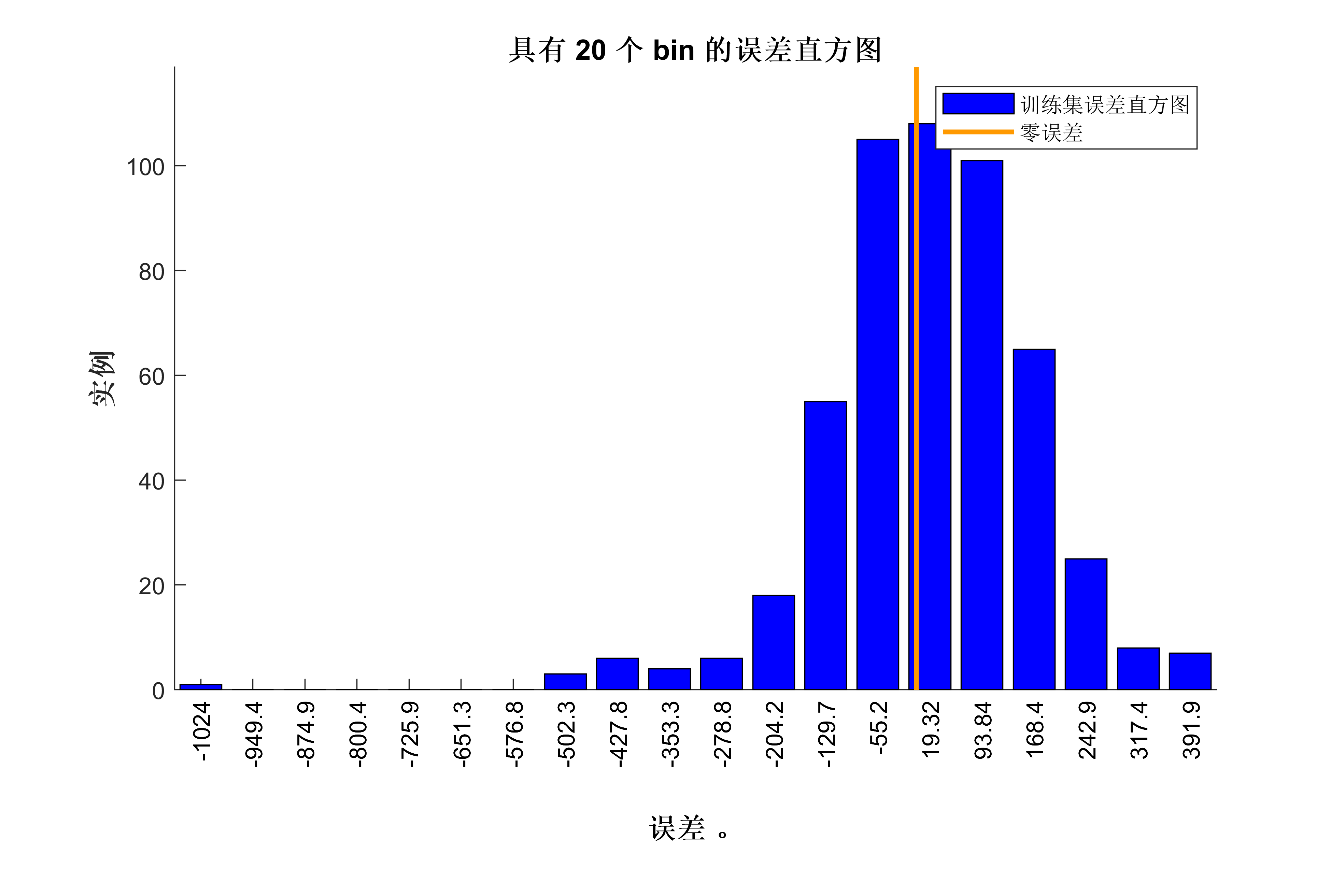
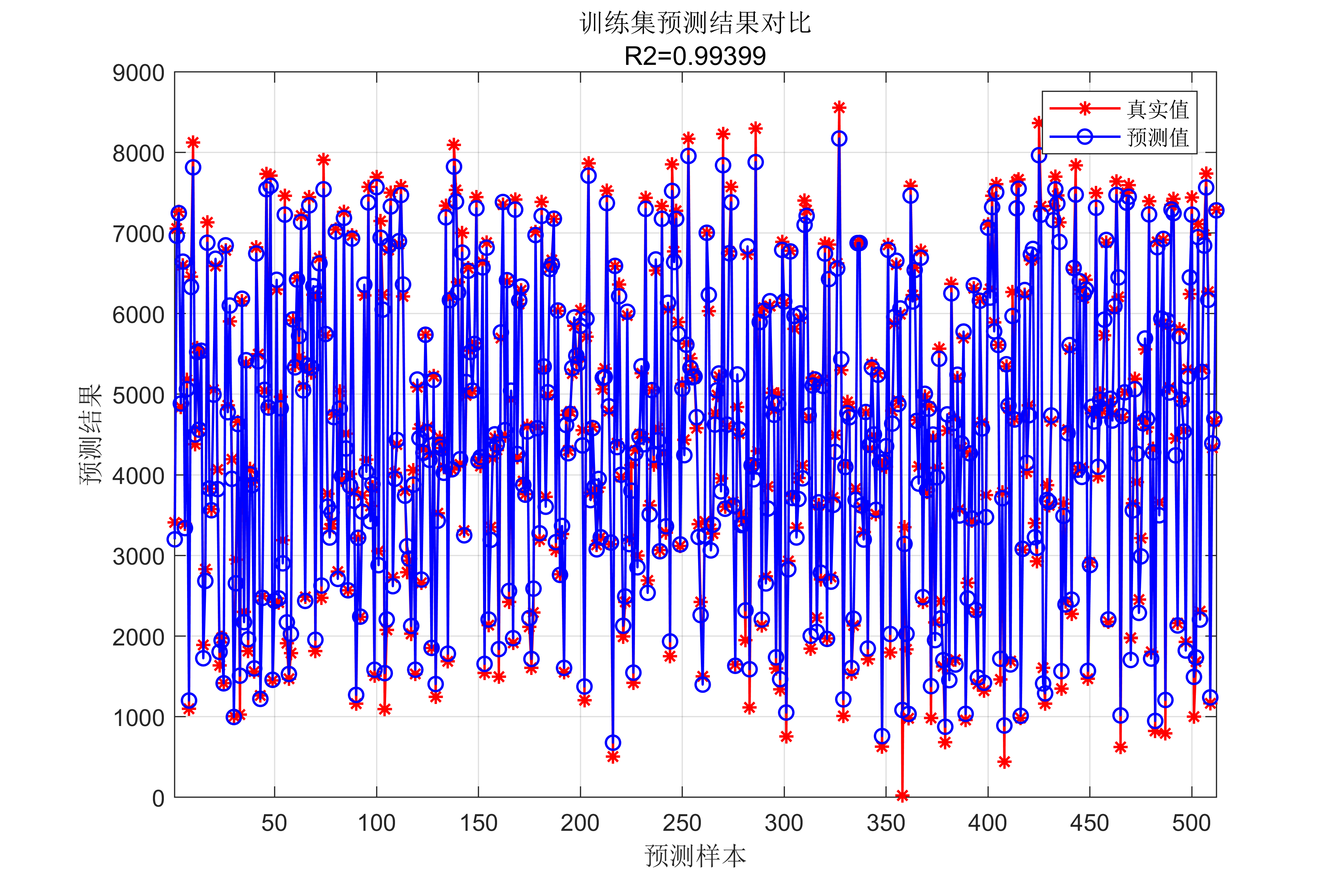
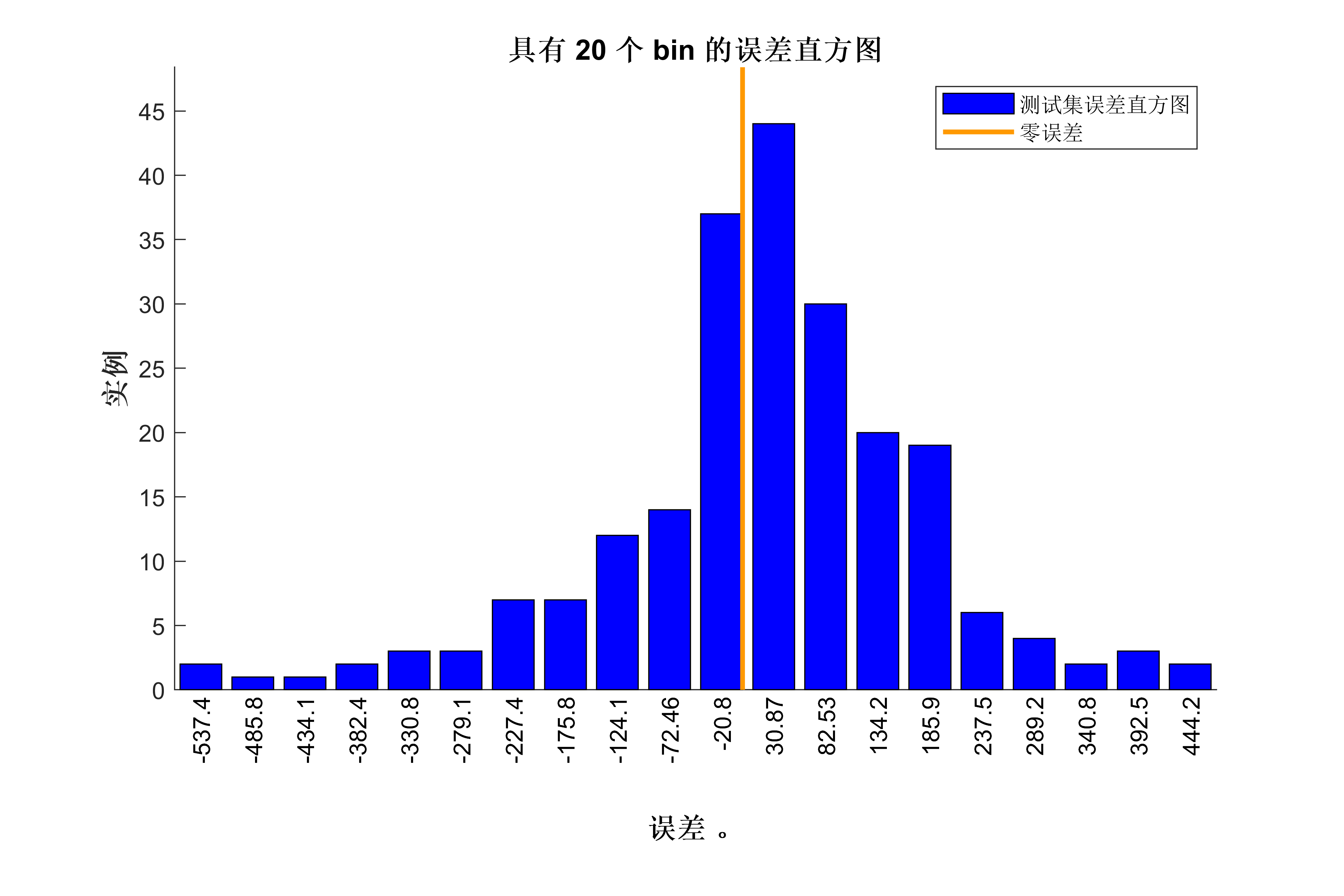
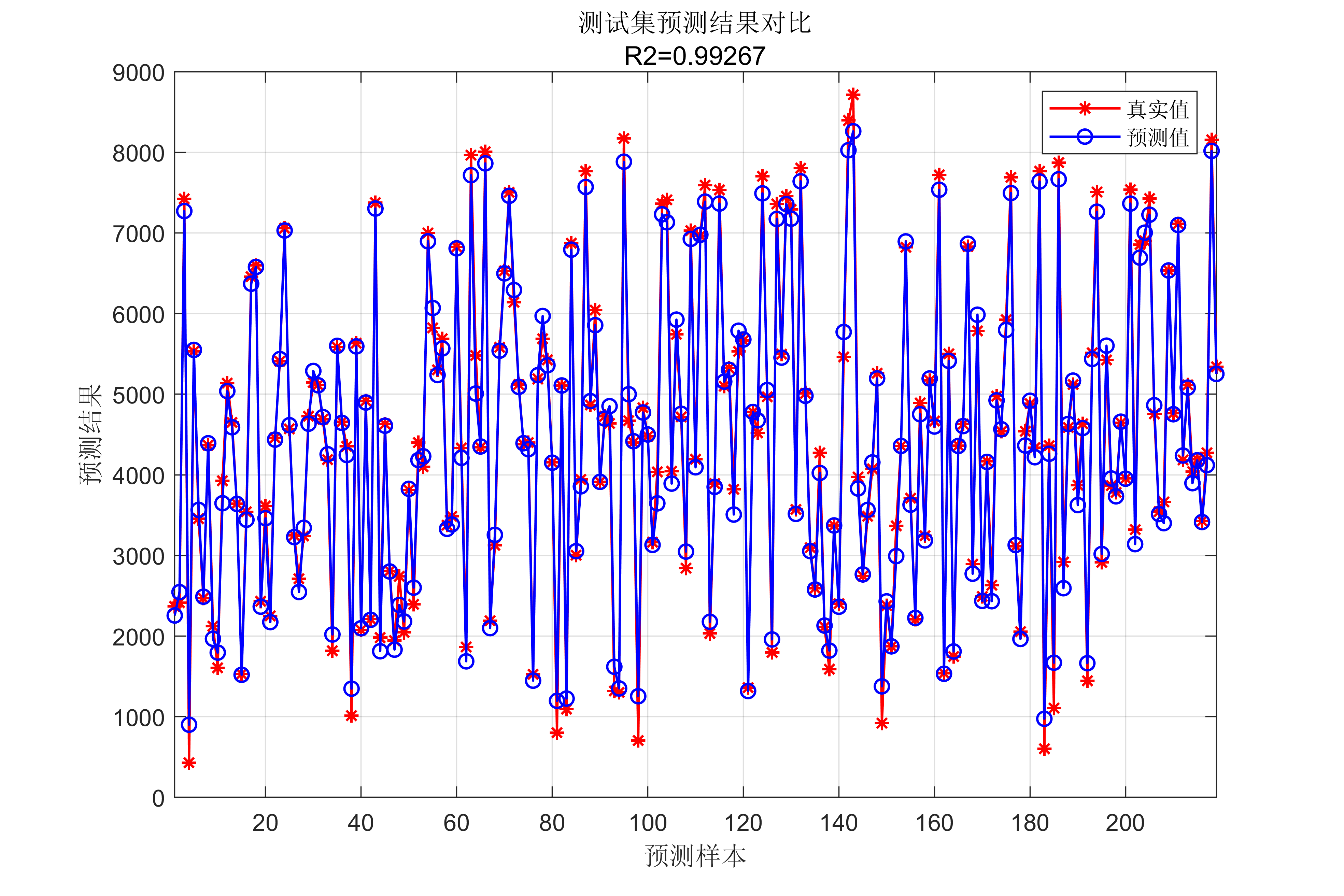
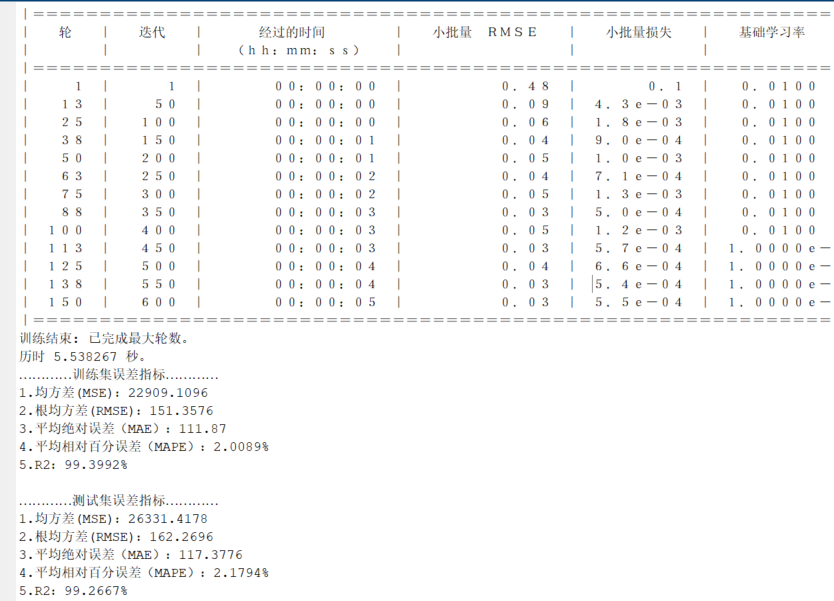
lgraph0 = connectLayers(lgraph0,'fold/miniBatchSize','unfold/miniBatchSize');代码效果图

获取代码请关注MATLAB科研小白的个人公众号(即文章下方二维码),并回复数据回归预测本公众号致力于解决找代码难,写代码怵。各位有什么急需的代码,欢迎后台留言~不定时更新科研技巧类推文,可以一起探讨科研,写作,文献,代码等诸多学术问题,我们一起进步。