Zookeeper入门篇,了解ZK存储特点
- 前言
- 一、为什么要用 Zookeeper?
- 二、Zookeeper存储特色
- 1. 树状结构
- 2. 节点类型
- 三、存储位置
- 1. 内存存储
- 1. DataTree
- 2. DataNode
- 2. 硬盘存储
- 1. 事务日志
- 2. 快照
前言

继上次说完 Zookeeper 的安装后,已经过去半年多了,一直没有后续,本次得空就更新一下入门篇,给同学们介绍一下 Zookeeper ,并着重说一下其存储原理
📕作者简介:战斧,从事金融IT行业,有着多年一线开发、架构经验;爱好广泛,乐于分享,致力于创作更多高质量内容
📗本文收录于 Zookeeper 专栏,有需要者,可直接订阅专栏实时获取更新
📘高质量专栏 云原生、RabbitMQ、Spring全家桶 等仍在更新,欢迎指导
📙 mysql Redis dubbo docker netty等诸多框架,以及架构与分布式专题即将上线,敬请期待
一、为什么要用 Zookeeper?
我们先看 Zookeeper 官方自己的定义
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. All of these kinds of services are used in some form or another by distributed applications. Each time they are implemented there is a lot of work that goes into fixing the bugs and race conditions that are inevitable. Because of the difficulty of implementing these kinds of services, applications initially usually skimp on them, which make them brittle in the presence of change and difficult to manage. Even when done correctly, different implementations of these services lead to management complexity when the applications are deployed.
ZooKeeper是一个集中的服务,用于维护配置信息、命名、提供分布式同步、提供组服务。分布式应用程序以某种形式使用所有这些类型的服务。每次实现它们时,都有大量的工作要做,以修复不可避免的错误和竞争条件。由于实现这类服务的困难,应用程序最初通常会忽略它们,这使得它们在出现变化时变得脆弱,并且难以管理。即使正确地完成了这些服务,在部署应用程序时,这些服务的不同实现也会导致管理复杂性。
说人话,就是人如其名,ZooKeeper 就是动物园管理者,而各个组件和应用则是动物园里的动物。我们每引入一个组件,就可以把组件的配置信息,以及组件提供的服务信息等内容存储在ZK里。
如果仅仅是保存信息,那么很多组件都有这个能力,凭什么要有这么个ZooKepper?主要是ZooKepper有一些特性比较好用,比如:高可用、高性能、一致性 等
当然最实用的肯定是其提供了 监听与心跳 的功能:心跳可以用来检测节点的存活状态。节点在启动时会向ZK服务器发送心跳消息,如果一段时间内没有收到节点的心跳消息,ZK服务器会认为该节点不可用,而监听则可以让应用程序在ZK节点发生变化时收到通知,当节点发生变化(如节点创建、删除、数据变更)时,ZK会将变化事件通知到注册的监听器上。这样,应用程序可以及时响应节点变化,进行相应的处理。
二、Zookeeper存储特色
1. 树状结构
首先,让我们了解 Zookeeper 存储的基本原理。Zookeeper 使用一种层次化的命名空间进行数据存储,类似于一个树形结构。每个节点都是一个 znode,可以包含数据和子节点。Zookeeper 的数据存储是基于内存的,这意味着可以快速访问和更新数据。同时,Zookeeper 还使用了一种类似于文件系统的节点路径来唯一标识每个 znode,可以方便地对数据进行读写和查询,如下:

2. 节点类型
上面我们说了,ZK是以树状节点的样式来管理存储信息的。同时ZK也提供了四种节点类型:
-
持久节点(Persistent Node):创建后将一直存在,直到主动删除。当客户端与ZK断开连接后,持久节点的数据依然保留。 -
临时节点(Ephemeral Node):只在创建它的客户端与ZK保持连接期间存在,一旦客户端断开连接,临时节点将被自动删除。 -
持久顺序节点(Persistent Sequential Node):创建后将一直存在,直到主动删除。与持久节点类似,但ZK会为每个创建的节点自动分配一个递增的序列号。 -
临时顺序节点(Ephemeral Sequential Node):只在创建它的客户端与ZK保持连接期间存在,一旦客户端断开连接,临时节点将被自动删除。与临时节点类似,但ZK会为每个创建的节点自动分配一个递增的序列号。
Zooke
说是四种节点,其实主要是两个属性:① 是否临时、② 是否排序。这种设计使得我们在很多场景都能利用上ZK。
比如临时节点通常用于表示临时的状态信息、临时的工作单元等。当一个临时节点的客户端与ZooKeeper会话断开连接时,该节点的信息就能被自动删除
排序节点就是节点路径后会由ZK附加一个自增的序列号,当大家都想创建同一个节点时,就能利用这个序号进行排序了,利用这种性质,能做成分布式锁。
三、存储位置
因为ZK需要快速读取和处理各种状态信息,并且需要提供低延迟的响应,所以 ZK的数据是存储在内存中的。然而,虽然数据存储在内存中,ZK也会将数据持久化到硬盘上,以确保数据的持久性和可靠性,所以我们说ZK同时有内存存储 和 硬盘存储
1. 内存存储
ZK的数据在内存中,其结构主要依赖两个类,一个是节点类 DataNode,一个是树结构类DataTree。
1. DataTree
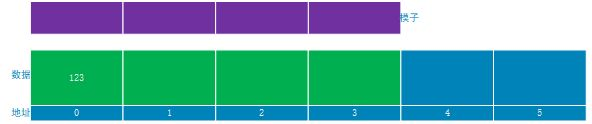
DataTree 维护两个并行的数据结构:一个从完整路径映射到datanode的散列表和一个由datanode组成的树。所有对路径的访问都要通过哈希表。只有在序列化到磁盘时才遍历树

这种双结构的存储方式,redis中也是一样的。这样会让我们在查询单个节点的时候,走的是 HashMap,时间复杂度为O(1),所以非常快。
2. DataNode
而所谓树状结构是怎么建立起来的呢?我们看一下 DataNode 的定义其实就清楚了,它其实是靠一个Set集合维护着子节点的。这样
public class DataNode {
/** the data for this datanode */
byte[] data;
/**
* 该节点的子节点列表。注意,子字符串列表不包含父路径——只包含路径的最后一部分。
* 对于该集合的变动和查询都必须要使用 synchronized ,除了反序列化(为了加速问题)之外。
*/
private Set<String> children = null;
}
得益于这样节点内 synchronized 的设计,使得我们在某个节点下增、减、查子节点时,都要先获取同步锁。这是ZK能作为分布式锁给其他组件使用的重要基础。
2. 硬盘存储
除了内存用来存储数据外,ZK还具有硬盘存储的机制,这种落盘机制的作用是确保ZK的数据在服务器故障或重启后能够重新加载并保持一致性。
1. 事务日志
ZK的事务日志是指将每个写操作都记录在一个磁盘上的事务日志文件中。当客户端请求对ZK进行写操作时,ZK首先将该操作追加到日志文件中,然后向客户端返回成功响应。日志文件是顺序写入的,这样可以提高写入的效率。通过记录每个写操作,ZK可以保证它的数据是具有顺序一致性的。这份文件的主要格式,我们能在源码的 FileTxnLog 类中看到
FileTxnLog 类实现了TxnLog接口。它提供api来访问txnlogs并向其中添加条目。
事务日志文件的格式如下由三部分构成:
// 文件头 事务列表 文件末尾的填充0
FileHeader TxnList ZeroPad
// 文件头构成:
FileHeader: {
magic 4bytes (ZKLG)
version 4字节
dbid 8个字节
}
// 事务列表由一个或多个事务记录构成
TxnList:
Txn || Txn TxnList
// 事务记录构成:
checksum Txnlen TxnHeader Record 0x42
checksum: 8字节,使用的Adler32算法的校验和
Txnlen: 4字节
TxnHeader: {
sessionid 8个字节
cxid 4字节
zxid 8个字节
time 8个字节
type 4个字节
}
关于事务这部分的详细情况,我们会在后面讲ZK集群的一致性时着重说明,现在我们只要知道ZK有事务日志功能即可
2. 快照
除了事务日志,ZK还使用快照来进行数据的持久化。快照是指ZK的内存数据结构在某个时刻的一份副本。ZK定期将内存中的数据转存到磁盘上,形成一个快照文件。快照文件是一个压缩文件,包含了ZK服务器的所有数据
// SyncRequestProcessor.java
代码步骤解释:
1. 获取当前日志数量 logCount 和日志大小 logSize 。
2. 判断条件:如果日志数量大于(快照计数设定值 snapCount 的一半加上随机数 randRoll ),
或者如果快照大小( snapSizeInBytes )大于0且日志大小大于(快照大小设定值 的一半加上随机大小 randSize )
private boolean shouldSnapshot() {
int logCount = zks.getZKDatabase().getTxnCount();
long logSize = zks.getZKDatabase().getTxnSize();
return (logCount > (snapCount / 2 + randRoll))
|| (snapSizeInBytes > 0 && logSize > (snapSizeInBytes / 2 + randSize));
}
通过事务日志的方式,ZK可以在发生故障时,通过回放日志文件来恢复数据。而通过快照文件,可以加快数据恢复的速度。因此,落盘机制是非常重要的,它保证了ZK的数据的持久性和可靠性。
![设计模式学习[2]---策略模式+简单工厂回顾](https://i-blog.csdnimg.cn/direct/3963db9ce0ab410e9278f2caf127ff11.png)