
前言
Hello,大家好,我是
GISer Liu😁,一名热爱AI技术的GIS开发者,本文参与活动是2024 DataWhale AI夏令营;😲
在本文中作者将通过:
-
Gradio、Streamlit和LlamaIndex介绍
-
LlamaIndex 构建RAG应用
-
LlamaIndex 结合 Streamlit 构建RAG Web应用
这三个章节,冲LLM开发的理论基础知识开始学习,尝试软件框架的使用方法,最后通过RAG实践案例帮助读者入门本次AI夏令营的LLM应用开发;一起加油!!!😍😍😍
一、前端框架介绍
1.Gradio

Gradio 是一个开源的 Python 库,用于快速构建机器学习和数据科学演示应用。它允许开发者通过几行代码创建一个简单、可调整的用户界面,用于展示机器学习模型或数据科学工作流程。Gradio 支持多种输入输出组件,如文本、图片、视频、音频等,并且可以轻松地在互联网上分享和在局域网内分享应用。
整理一下其特点:

-
快速开发:Gradio 提供了丰富的预构建组件,可以快速搭建用户界面。 -
多种输入输出类型:支持文本、图片、视频、音频等多种输入输出类型。 -
易于分享:可以轻松地将应用分享到互联网或局域网。 -
集成方便:可以与各种机器学习框架(如 TensorFlow、PyTorch)无缝集成。
Gradio其拥有的功能:
-
用户界面构建:通过简单的 API 调用创建复杂的用户界面。 -
实时交互:支持实时交互,用户可以即时看到模型的输出。 -
组件定制:可以自定义组件的样式和行为。 -
事件处理:支持按钮点击、输入框变化等事件的处理。
Gradio 提供了多种组件,包括但不限于,下面的案例代码中我会展示细节:
- 文本框 (Textbox):用于输入和显示文本。
- 聊天框 (Chatbot):用于显示对话历史。
- 按钮 (Button):用于触发事件。
- 图像 (Image):用于输入和显示图像。
- 滑块 (Slider):用于输入数值。
安装方法:
pip install gradio
应用案例:
import gradio as gr
def greet(name, is_morning, temperature, image, audio, file, dropdown, checkbox, slider, number):
salutation = "早上好" if is_morning else "晚上好"
greeting = f"{salutation} {name}。今天气温是 {temperature} 度。"
return greeting, image, audio, file, dropdown, checkbox, slider, number
iface = gr.Interface(
fn=greet, # 定义处理函数
inputs=[
gr.inputs.Textbox(lines=2, placeholder="在这里输入你的名字..."), # 文本框
gr.inputs.Checkbox(label="现在是早上吗?"), # 复选框
gr.inputs.Number(label="气温"), # 数字输入框
gr.inputs.Image(type="pil"), # 图像上传
gr.inputs.Audio(source="microphone"), # 音频录制
gr.inputs.File(label="上传文件"), # 文件上传
gr.inputs.Dropdown(choices=["选项1", "选项2", "选项3"], label="选择一个选项"), # 下拉菜单
gr.inputs.CheckboxGroup(choices=["A", "B", "C"], label="选择选项"), # 复选框组
gr.inputs.Slider(minimum=0, maximum=100, default=50, label="选择一个值"), # 滑动条
gr.inputs.Number(label="输入一个数字") # 数字输入框
],
outputs=[
gr.outputs.Textbox(label="问候语"), # 文本框
gr.outputs.Image(label="上传的图像"), # 图像
gr.outputs.Audio(label="录制的音频"), # 音频
gr.outputs.File(label="上传的文件"), # 文件
gr.outputs.Textbox(label="选择的选项"), # 文本框
gr.outputs.Textbox(label="选择的复选框"), # 文本框
gr.outputs.Textbox(label="选择的滑动条值"), # 文本框
gr.outputs.Textbox(label="输入的数字") # 文本框
],
title="Gradio 多组件演示", # 页面标题
description="这是一个包含多种输入和输出组件的 Gradio 界面演示。" # 页面描述
)
iface.launch() # 启动界面
然后我们可以在终端中顺利运行Gradio窗口,我这里的gradio版本是3.10.1:
python3 test.py

2. Streamlit

Streamlit 是一个开源的 Python 库,专门用于快速构建数据科学和机器学习应用的 Web 界面。它允许开发者通过简单的 Python 脚本创建交互式的 Web 应用,无需深入了解 Web 开发技术。Streamlit 提供了丰富的组件和功能,使得数据可视化和模型展示变得简单快捷。
整理一下其特点:
-
快速开发:Streamlit 提供了简洁的 API,可以快速搭建 Web 界面。 -
代码驱动:完全基于 Python 脚本,无需 HTML 或 JavaScript。 -
实时更新:应用会根据代码的更改实时更新。 -
易于分享:可以轻松地将应用部署到云端或本地服务器。 -
集成方便:可以与各种数据科学和机器学习框架(如 Pandas、Matplotlib、TensorFlow)无缝集成。

Streamlit 拥有的功能:
-
数据展示:支持表格、图表、地图等多种数据展示方式。 -
用户交互:支持按钮、滑块、下拉菜单等交互组件。 -
组件定制:可以自定义组件的样式和行为。 -
缓存机制:支持缓存数据和计算结果,提高应用性能。
Streamlit 提供了多种组件,包括但不限于:
- 文本框 (Text Input):用于输入和显示文本。
- 按钮 (Button):用于触发事件。
- 图像 (Image):用于显示图像。
- 滑块 (Slider):用于输入数值。
- 下拉菜单 (Selectbox):用于选择选项。
安装方法:
pip install streamlit
应用案例:
import streamlit as st
import pandas as pd
import numpy as np
def main():
st.title("Streamlit 多组件演示")
st.write("这是一个包含多种输入和输出组件的 Streamlit 界面演示。")
name = st.text_input("输入你的名字", "在这里输入你的名字...")
is_morning = st.checkbox("现在是早上吗?")
temperature = st.number_input("输入气温", min_value=0, max_value=100, value=20)
image = st.file_uploader("上传图像", type=["png", "jpg", "jpeg"])
audio_file = st.file_uploader("上传音频", type=["wav", "mp3"])
file = st.file_uploader("上传文件")
dropdown = st.selectbox("选择一个选项", ["选项1", "选项2", "选项3"])
checkbox = st.multiselect("选择选项", ["A", "B", "C"])
slider = st.slider("选择一个值", 0, 100, 50)
number = st.number_input("输入一个数字")
if st.button("提交"):
salutation = "早上好" if is_morning else "晚上好"
greeting = f"{salutation} {name}。今天气温是 {temperature} 度。"
st.write(greeting)
if image:
st.image(image)
if audio_file:
st.audio(audio_file)
if file:
st.write("上传的文件:", file)
st.write("选择的选项:", dropdown)
st.write("选择的复选框:", checkbox)
st.write("选择的滑动条值:", slider)
st.write("输入的数字:", number)
if __name__ == "__main__":
main()
然后我们可以在终端中顺利运行 Streamlit 应用:
streamlit run app.py

通过以上案例,你可以看到 Streamlit 和 Gradio 都是非常强大的工具,用于快速构建和部署数据科学和机器学习应用的 Web 界面。选择哪一个取决于你的具体需求和偏好。
3.检索增强生成(RAG)

这里作者引用一下LangChain的RAG流程图,并详细解释一下其思路:
为了让LLM可以获取真实实时的信息,来自其他数据库、用户输入、互联网爬取的文本图像数据会通过Embedding模型向量化被存储到向量数据库中,然后每次模型调用时都会先去检索向量数据库,将向量(余弦)相似度最高的检索结果反馈,通过提示词工程包装,输入给LLM,得到较为精准的回答,从而实现长期的记忆 ;下面是典型RAG的重要组成:
- 索引:用于从源引入数据并对其进行索引的管道。这通常发生在离线状态。
- 检索和生成:实际的 RAG 链,它在运行时接受用户查询并从索引中检索相关数据,然后将其传递给模型。与问题组合为一个新的提示词,输入给LLM;
索引

-
数据加载:首先我们要从不同的数据格式中读取数据到向量数据库,在
langchain中,这通过DocumentLoaders实现; -
数据拆分:从不同文件中读取的数据会被拆分为数据块;因为向量数据库会分别计算不同数据块与用户输入的向量相似度,如果数据块拆分过大或者一整块(不拆分),则导致很多不相关的信息也会被检索到,如果数据块拆分的太细,则会导致我们读取到的信息不全,也不合适;因此数据拆分时一定要考虑到实际情况,具体问题具体分析,这样计算向量相似度才有意义;
-
数据存储:我们说我们读取的文本数据会被
Embedding模型经过向量化,转化为向量格式,然后存储到向量数据库中;这样我们才能进行后续的向量相似度计算;本文中篇幅有限,就不描述具体的数学原理了;
检索和生成
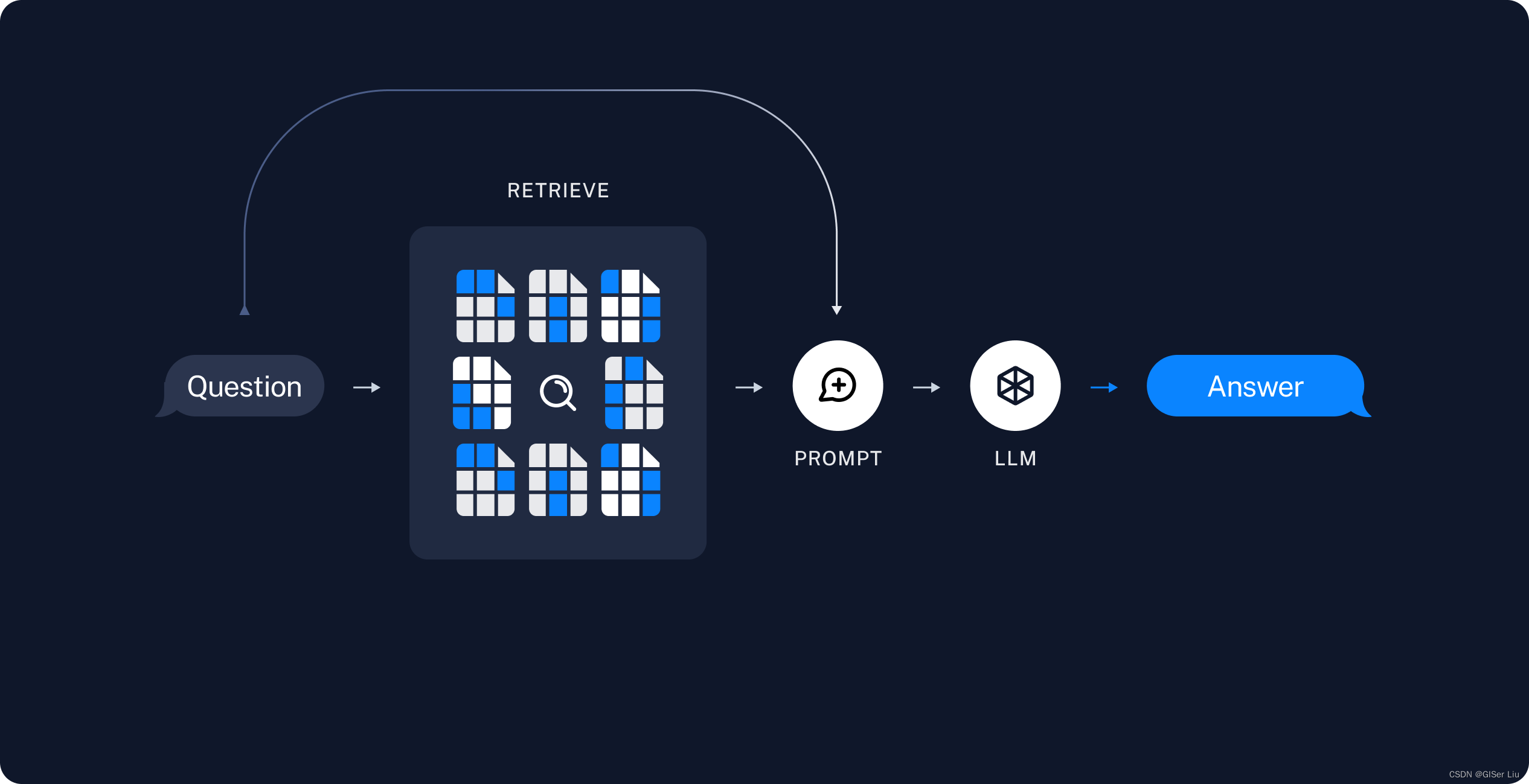
- 内容检索:根据用户的输入,使用Retriever从向量数据库中检索相关拆分的结果;
- 内容生成:ChatModel/LLM使用包含问题和检索信息的提示来生成答案;
RAG应用是LLM应用中除了聊天机器人外最有可能落地的应用了!
应用示例:
- 医学咨询:RAG系统先检索相关医学文献,再由LLM生成基于最新研究的回复,提供专业且可靠的医学建议。
- 法律咨询:在法律咨询中,RAG系统可以检索法律条文和案例,生成详细且准确的法律建议。
- 简历挑选:在企业招聘过程中,HR通过使用基于企业内网知识库的RAG系统可以从海量简历中自动检索出符合公司业务需求的面试者,并提供的薪资和面试建议。
- 个人学习:对于个人学习者,可以基于本地化部署的知识库和LLM API和Ollama构建个人知识库RAG系统,更好的检索知识,提高学习效率,避免遗忘;并可以实时接收AI 安排的计划,进行针对性的学习;
二、LlamaIndex 概念及应用
我们知道基于大模型实现RAG系统的方法很多。接下来我们就用一款新的工具来构建属于我们自己的RAG系统。
1.LlamaIndex

概念
LlamaIndex是一个用于将私有数据与公共数据集成到大型语言模型(LLM)中的 AI 框架。它简化了数据导入-索引-查询的过程,为生成式 AI 需求提供了可靠的解决方案。
安装
首先,我们需要安装LlamaIndex的依赖环境:
pip install llama-index
pip install llama-index-embeddings-huggingface
pip install llama-index-embeddings-instructor
pip install llama-index-llms-ollama
组成
-
数据连接器:连接现有数据源和数据格式(如 API、PDF 等),并将这些数据转换为
LlamaIndex可用的格式。

-
数据索引:帮助结构化数据,以便无论是问答还是摘要等需求,都可以使用索引来检索相关信息。
-
查询接口:用于输入查询并从 LLM 中获取增强的知识输出。
高层次抽象结构

1. Indexing
Indexing 是一种数据结构,用于快速检索相关上下文。可以将其简单理解为对 “node” 的抽象组织方式。在 LlamaIndex 中存在多种组织 node 的方式。Indexing 将数据存储在 Node 对象(代表原始文档的 chunk )中,并支持额外配置和自动化的 Retriever 接口。

2. Vector Stores
Vector Stores 负责存储 chunk 的嵌入向量。默认情况下,LlamaIndex 使用一个简单的内存向量存储,非常适合快速实验。这些向量存储可以通过 vector_store.persist() 进行持久化。LlamaIndex 支持多种向量数据库输入。

3. Query Engine
Query Engine 是一个通用接口,允许用户对数据提出问题。Query Engine 接收自然语言查询,并通常通过检索器建立在一个或多个 indexing 上。用户可以组合多个 Query Engine 来实现更高级的功能。
功能
- 数据连接器:从原生数据源和格式中获取数据,例如API、PDF、SQL等。
- 数据索引:将数据结构化成LLM易于使用的中间表示。
- 引擎:
- 查询引擎:用于问答(例如RAG管道)。
- 聊天引擎:用于多轮交互。
- 代理:增强型知识工作者,利用简单的助手功能到API集成等工具。
- 可观测性/评估集成:进行实验、评估和监控。
与 LangChain 的 RAG 链的区别
LlamaIndex与LangChain的RAG链相比,具有以下特点:
- 模块化:
LlamaIndex提供了更高的模块化设计,允许用户更灵活地组合和扩展各个组件。 - 数据连接器:LlamaIndex提供了丰富的数据连接器,支持多种数据源和格式。
- 可观测性和评估:LlamaIndex内置了完善的可观测性和评估工具,方便用户进行实验和监控。
应用场景
LlamaIndex适用于各种上下文增强应用,包括但不限于:
- 问答系统(RAG)
- 聊天机器人
- 文档理解和数据提取
- 自主代理
- 多模态应用
- 数据微调模型
下面是一个使用 LlamaIndex 实现 RAG 系统的案例:
假设有如下的文件组织:
├── starter.py
└── data
└── *.pdf

核心代码为:
# 导入需要的模块和类
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.ollama import Ollama
# 1. 使用 SimpleDirectoryReader 加载数据
# SimpleDirectoryReader 是一个简单的目录读取器,能从指定目录中读取所有文件的数据
documents = SimpleDirectoryReader("data").load_data()
# 2. 设置嵌入模型为 bge-base
# HuggingFaceEmbedding 是一个嵌入模型类,用于将文本转换为向量表示
# 这里我们使用的是 "BAAI/bge-base-en-v1.5" 模型
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-base-en-v1.5")
# 3. 使用 Ollama 快速接入大语言模型
# Ollama 是一个模型的快速调用框架
# 这里我们指定使用 "llama3" 模型,并设置请求超时时间为 360 秒
Settings.llm = Ollama(model="llama3", request_timeout=360.0)
# 4. 创建一个向量存储索引
# VectorStoreIndex 是一个用于存储和查询向量的索引类
# from_documents 方法是从文档数据创建索引
index = VectorStoreIndex.from_documents(documents)
# 5. 将索引转换为查询引擎
# as_query_engine 方法将现有的向量存储索引转换为一个查询引擎
# 查询引擎是一个通用接口,允许您对数据提出问题。
query_engine = index.as_query_engine()
# 6. 使用查询引擎进行查询
# query 方法接受一个查询字符串,并返回一个响应对象
# 这里我们查询 "作者小时候做了什么?"
response = query_engine.query("What did the author do growing up?")
# 7. 打印查询结果
# 打印从查询引擎返回的响应
print(response)
结果输入如下:

相关链接
三、构建LlamaIndex RAG Web应用
这里我们使用IpexLLMEmbedding作为向量嵌入模型,ollama为本地模型,streamlit为前端页面,实现完全本地化;
要使用 IpexLLMEmbedding 作为本地 CPU 模型,请确保安装了 llama-index-embeddings-ipex-llm:
pip install llama-index-embeddings-ipex-llm
- 基于
Streamlit构建全本地RAG应用
# test.py
import streamlit as st
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.ipex_llm import IpexLLMEmbedding
from llama_index.llms.ollama import Ollama
import os
# 配置文件上传路径
UPLOAD_DIR = "uploaded_files"
os.makedirs(UPLOAD_DIR, exist_ok=True)
# Streamlit 应用标题
st.title("RAG 应用")
# 文件上传
uploaded_files = st.file_uploader("上传文件", accept_multiple_files=True)
if uploaded_files:
for uploaded_file in uploaded_files:
file_path = os.path.join(UPLOAD_DIR, uploaded_file.name)
with open(file_path, "wb") as f:
f.write(uploaded_file.getbuffer())
st.success("文件上传成功!")
# 输入查询
query = st.text_input("输入查询")
# 加载数据并设置嵌入模型和语言模型
if st.button("执行查询"):
# 1. 使用 SimpleDirectoryReader 加载数据
documents = SimpleDirectoryReader(UPLOAD_DIR).load_data()
# 2. 设置嵌入模型为 IpexLLMEmbedding
Settings.embed_model = IpexLLMEmbedding(model_name="BAAI/bge-large-en-v1.5")
# 3. 使用 Ollama 快速接入大语言模型
Settings.llm = Ollama(model="llama3", request_timeout=360.0)
# 4. 创建一个向量存储索引
index = VectorStoreIndex.from_documents(documents)
# 5. 将索引转换为查询引擎
query_engine = index.as_query_engine()
# 6. 使用查询引擎进行查询
response = query_engine.query(query)
# 7. 打印查询结果
st.write("查询结果:")
st.write(response)
保存代码后,运行以下命令启动 Streamlit 应用:
streamlit run test.py
这将启动一个本地服务器,并在浏览器中打开应用程序界面,各位读者可以尝试在其中上传文件、输入查询并查看结果。这样,我们就使用了
IpexLLMEmbedding作为本地 CPU 模型来处理文本嵌入。
输入你的问题,点击提交按钮,你会看到一个基于LlamaIndex和Gradio的RAG系统生成的回答。
总结
在本教程中,我们介绍了如何使用Gradio、Streamlit和LlamaIndex构建RAG系统。希望这篇文章能帮助你更好地理解和使用这些工具,构建出属于自己的强大AI应用。如果你有任何问题或建议,欢迎留言讨论!
文章参考
- Streamlit官方文档
- Gradio官方文档
- DeepSeek官方文档
- LlamaIndex官方文档
项目地址
- 拓展阅读
- 专栏文章

如果觉得我的文章对您有帮助,三连+关注便是对我创作的最大鼓励!或者一个star🌟也可以😂.

















