文章目录
- 什么是Spark
- Spark学习路线
- Spark入门指南
什么是Spark
Apache Spark 是一个开源集群运算框架,最初是由加州大学伯克利分校 AMP 实验室所开发。相对于 Hadoop 的 MapReduce 会在运行完工作后将中间数据存放到磁盘中,Spark 使用了存储器内存运算技术,能在数据尚未写入硬盘时即在存储器内分析运算。
Spark 特点:
- 运行速度快:Spark 的中文意思是“电光火石”,Spark 确实如此!官方提供的数据表明,如果数据由磁盘读取,速度是 Hadoop MapReduce 的 10 倍以上,如果数据从内存中读取,速度可以高达 100 多倍。
- 易用性好:Spark 不仅支持 Scala 编写应用程序,而且支持 Java、Python 和 R 等语言进行编写。Scala 是一种高效、可拓展的语言,能够用简洁的代码处理较为复杂的处理工作。
- 通用性强:Spark 生态圈即 BDAS(伯克利数据分析栈)所包含的组件:Spark Core 提供内存计算框架、Spark Streaming 的实时处理应用、Spark SQL 的即时查询、MLlib 的机器学习和 GraphX 的图处理,它们都是由 AMP 实验室提供,能够无缝地集成,并提供一站式解决平台。
- 随处运行:Spark 具有很强的适应性,能够读取 HDFS、Cassandra、HBase、S3 和 Tachyon,为持久层读写原生数据,能够以 Mesos、YARN 和自身携带的 Standalone 作为资源管理器调度作业来完成 Spark 应用程序的计算;此外,Spark 集群可扩展至超过8000个结点。
Spark学习路线
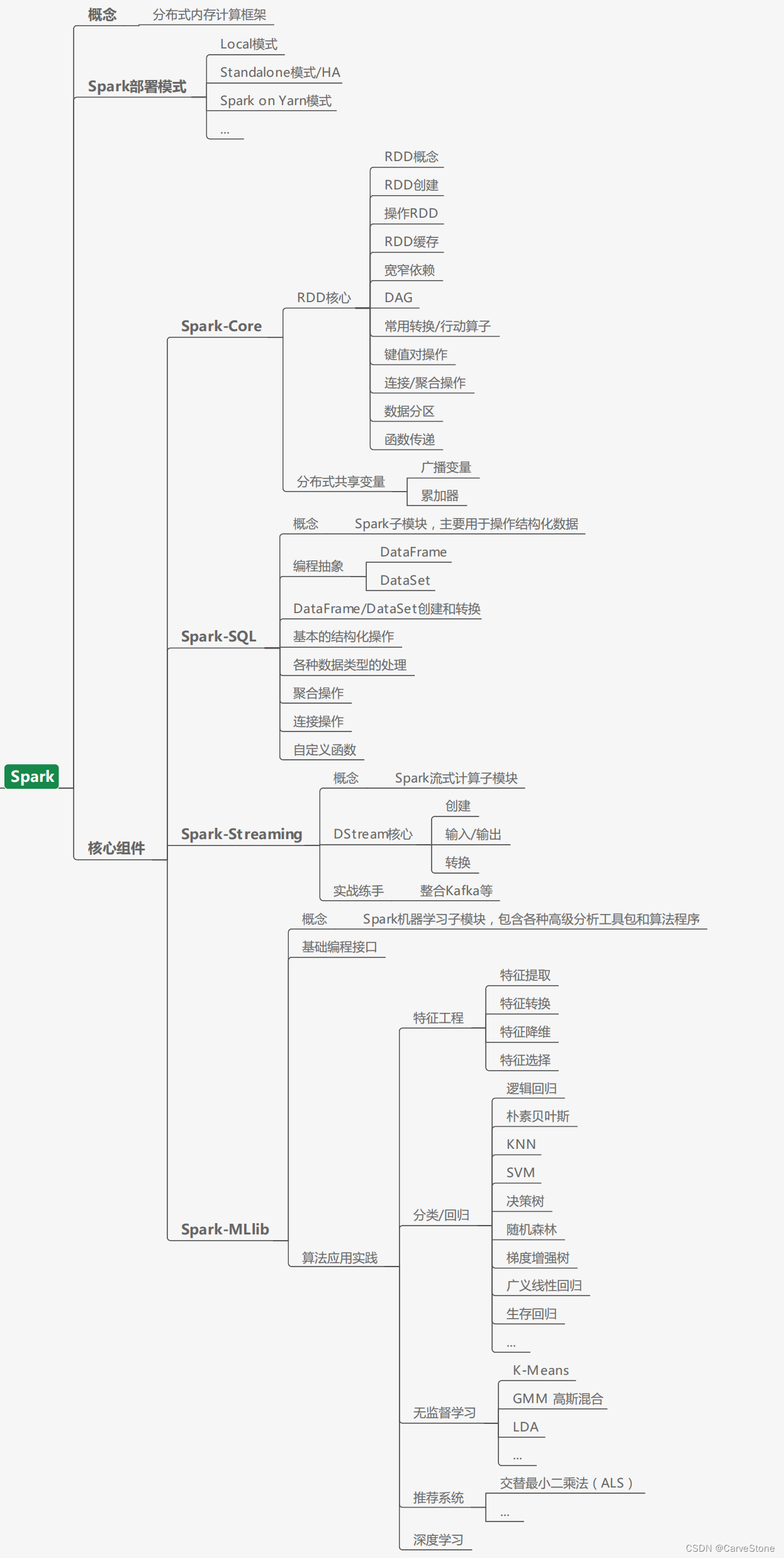
Spark入门指南
- idea配置Spark运行环境:https://blog.csdn.net/weixin_44018458/article/details/128831642
- Spark提交运行:https://blog.csdn.net/weixin_44018458/article/details/128831938
- RDD编程:https://blog.csdn.net/weixin_44018458/article/details/128769676
- 转换操作:https://blog.csdn.net/weixin_44018458/article/details/128774747
- 行动操作:https://blog.csdn.net/weixin_44018458/article/details/128774891
- DataSet:https://blog.csdn.net/weixin_44018458/article/details/128785412
- SparkSQL函数:https://blog.csdn.net/weixin_44018458/article/details/128848301
- SparkSQL编程基础:https://blog.csdn.net/weixin_44018458/article/details/128785488
- Spark_SQL的UDF使用:https://blog.csdn.net/weixin_44018458/article/details/128800313
- JDBC操作MySQL:https://blog.csdn.net/weixin_44018458/article/details/128800342
- Spark_SQL性能调优:https://blog.csdn.net/weixin_44018458/article/details/128818324
- 网站日志分析实例:https://blog.csdn.net/weixin_44018458/article/details/128819305