百万QPS下热点数据的收集方案
在高并发场景下,如京东、淘宝的秒杀活动开始时候,会有很多的用户同时抢购秒杀商品,由于同一个场次成百上千种商品参与秒杀活动,但是热点的商品往往就只有那么几十个左右,此时系统的90%的流量都是来自于这几十个热点商品,极端情况下因为这几十个热度商品导致服务器宕机,因此针对热点商品需要做一些应对的措施。常见的应对措施有缓存热点商品数据、热点数据和非热点数据做隔离等等。
如何在高并发下识别热点商品数据呢?下面我们将通过OpenResty+Lua+Kafka+ES方案实现热点数据收集的方案。
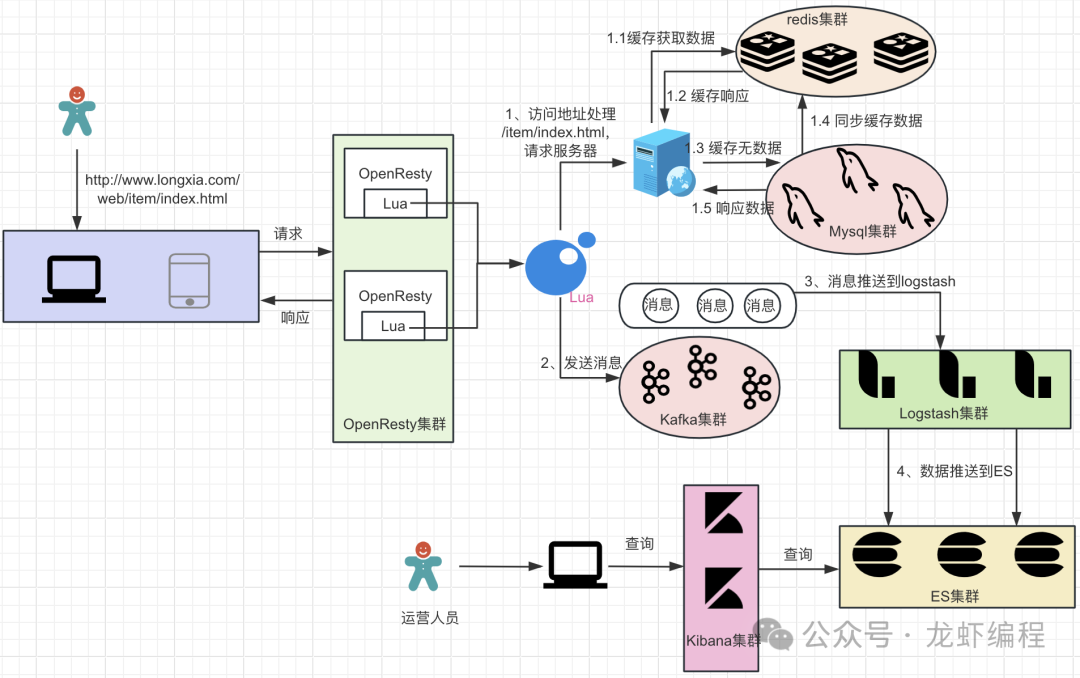
1、方案的实现流程
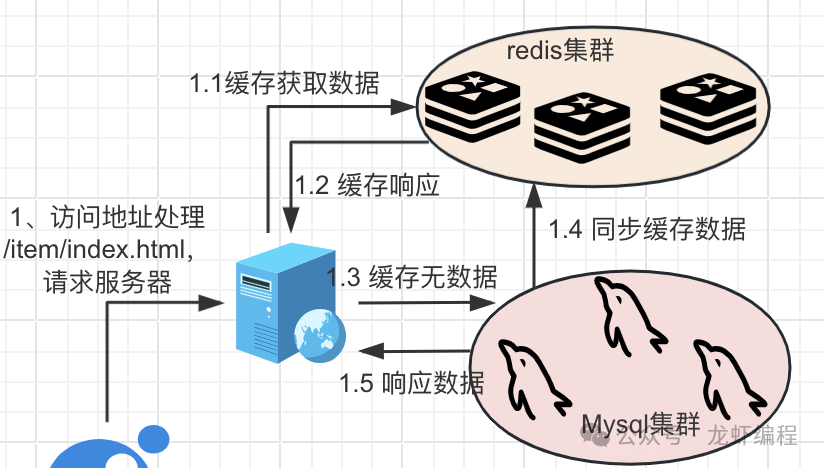
(1)当用户访问(如http://www.longxia.com/web/item/index.html)的时候,请求进入到OpenResty中。
(2)OpenResty中的Nginx上location拦截到请求,它会做去掉请求地址上的特定部分(如/web/item/index.html ----> /item/index.html),然后访问真实的服务获取数据。
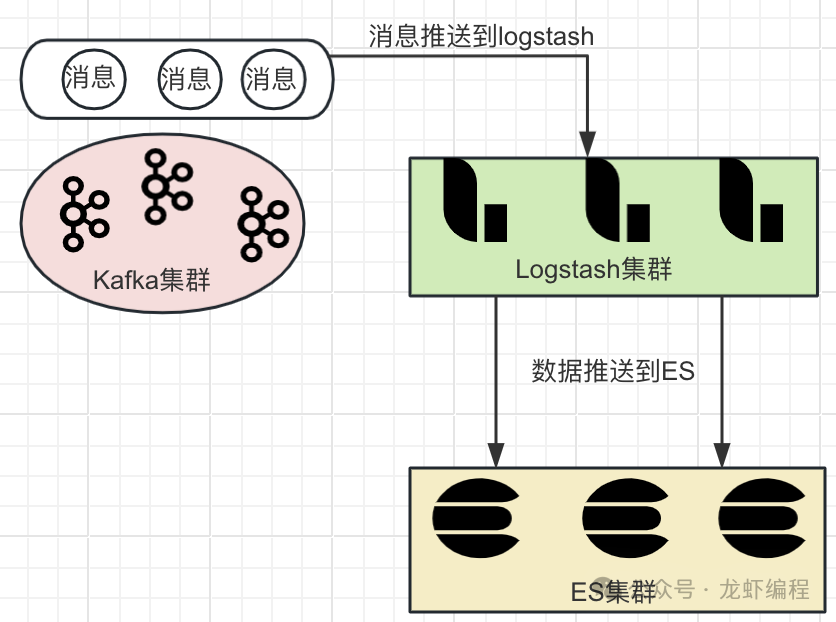
(3)Lua组装用户访问的数据(如商品信息)发送消息到Kafka中,Kafka随后将数据推送到Logstash中,Logstash会把数据推送到ES中存储起来。
2、核心的实现过程
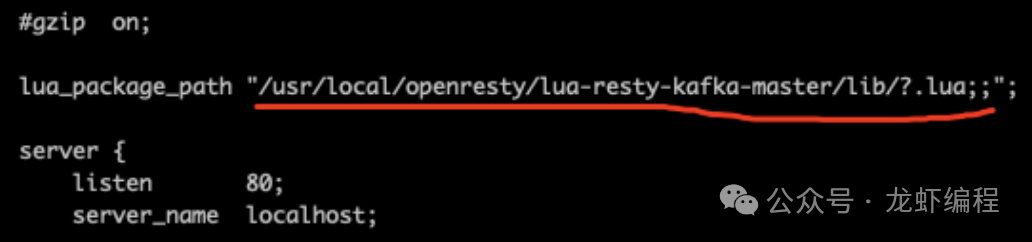
(1)配置lua-resty-kafka
地址:https://github.com/doujiang24/lua-resty-kafka
插件配置到Nginx模块上
(2)编写lua脚本
--依赖导入local cjson = require "cjson"local client = require "resty.kafka.client"local producer = require "resty.kafka.producer"--配置kafka的服务地址local broker_list = {{ host = "192.168.203.237",port = 9092}}--创建kafka的生产者local bp = producer:new(broker_list, { producer_type = "async" })--先获取用户的请求头 然后获取IP的信息local headers=ngx.req.get_headers()local ip=headers["X-REAL_IP"] or headers["X_FORWARDED_FCR"] or ngx.var.remote_addr or "0.0.0.0"--创建消息local message={}message["uri"]=ngx.var.urimessage["ip"]=ipmessage["token"]="987654"message["actime"]=os.date("%y-%M-%d %H:%m:%S")--发送消息local ok, err = bp:send("collection_hot_item",nil, cjson.encode(message))--把请求中的/web去掉local uri = ngx.var.uriuri = string.gsub(uri,"/web","")--将去掉的路径再次执行转发查找静态页ngx.exec(uri)
(3)页面的请求被Nginx拦截的配置
#拦截/web/item的请求 然后交给lua文件处理location /web/item/ {content_by_lua_file /usr/local/openresty/nginx/lua/item-access.lua;}location /item/ {root /usr/local/web;}
(4)kafka消息推送到Logstash
input {kafka {bootstrap_servers => "192.168.203.237:9092" # Kafka 服务器地址和端口topics => ["collection_hot_item"] # 需要消费的 Kafka 话题group_id => "logstash_group" # Kafka 消费者组IDconsumer_threads => 3 # 消费者线程数codec =>json}}filter {}output {#数据推送到eselasticsearch {hosts => ["http://192.168.203.238:9200"]index => "hot_item"}}
总结:运营人员通过Kibana可以查询到热点商品数据,定位到热点的商品数据后可以有针对性地做一些应对措施。本文是通过ES存储热点数据,也可以使用Druid来实现,Druid有更好的数据处理分析能力。
MyBatis 的多级缓存机制
一级缓存
1)MyBatis 的一级缓存默认开启,且默认作用范围为 SESSION,即一级缓存在一个会话中生效,也可以通过配置将作用范围设置为 STATEMENT,让一级缓存仅针对当前执行的 SQL 语句生效。
2)在同一个会话中,执行增,删,改操作会使本会话中的一级缓存失效。
3)不同会话持有不同的一级缓存,本会话内的操作不会影响其它会话内的一级缓存。
Session 针对浏览器会话,不同会话的同一个 SQL 语句,自然是不会走一级缓存。同一个浏览器会话,但是查询条件不同,比如 Where 条件不同,依然不会走一级缓存,或者同一个浏览器在两个相同的查询条件下,中间执行了一次增、删、改的操作,一级缓存依然失效。
特别注意:一级缓存针对的范围是什么?以及一级缓存失效的场景,当然一般我们都会在 yml 配置中去开启日志,通过查看日志可以看到缓存是否被使用!
二级缓存
1) MyBatis 中的二级缓存默认开启,可以在 MyBatis 配置文件中的<settings>中添加<setting name="cacheEnabled" value="false"/>将二级缓存关闭;
2)MyBatis 中的二级缓存作用范围是同一命名空间下的多个会话共享,这里的命名空间就是映射文件的 namespace,即不同会话使用同一映射文件中的 SQL 语句对数据库执行操作并提交事务后,均会影响这个映射文件持有的二级缓存;
3)MyBatis 中执行查询操作后,需要提交事务才能将查询结果缓存到二级缓存中;
4)MyBatis 中执行增,删或改操作并提交事务后,会清空对应的二级缓存;
5)MyBatis 中需要在映射文件中添加<cache>标签来为映射文件配置二级缓存,也可以在映射文件中添加<cache-ref>标签来引用其它映射文件的二级缓存以达到多个映射文件持有同一份二级缓存的效果。
二级缓存配置项
在 Mapper 配置文件中添加的 Cache 标签中可以设置相关属性。
1)Eviction 属性:缓存回收策略(LRU、FIFO、SOFT、WEAK)
2)FlushInterval属性:刷新间隔,单位毫秒,默认没有刷新间隔,语句被调用时缓存会刷新。
3)Size:引用的数目,缓存存储的对象数量,考虑到内存溢出问题。
4)ReadOnly:只读,是否是只读缓存,如果为 true,所有调用者返回缓存对象的相同实例。如果为 false,会返回缓存对象的拷贝(序列化对象),性能慢,但安全性高,默认为 false。
是否需要三级缓存?
概念:三级缓存通常指的是在分布式系统中,跨应用实例的缓存层,如使用 Redis 或 Memcached 作为缓存存储。
作用:三级缓存可以进一步减少对数据库的访问,提高系统的扩展性和性能。
考虑因素:是否需要三级缓存取决于应用的规模、架构和性能需求。如果应用部署在多个服务器上,且需要共享数据,可能需要考虑引入三级缓存。
实现:三级缓存通常不是由 MyBatis 直接提供,而是通过集成外部缓存系统来实现。
应用规模:对于大型应用或分布式系统,三级缓存可以提供更好的性能和扩展性。
性能需求:如果应用对性能有较高要求,尤其是在高并发场景下,三级缓存可以显著减少数据库的压力。
数据一致性:引入三级缓存需要考虑数据一致性问题,确保缓存与数据库之间的数据同步。
复杂性:实现三级缓存可能会增加系统的复杂性,需要权衡实现成本和性能收益。
其他补充
https://www.yucongming.com/
一级缓存示例
一级缓存是自动启用的,不需要额外配置。它通常在 SqlSession 的生命周期内有效。
// 获取 SqlSession
SqlSession session = sqlSessionFactory.openSession();
try {
// 查询用户,一级缓存会自动存储这个查询结果
User user1 = session.selectOne("com.example.mapper.User.selectById", 1L);
// 再次查询相同的用户,这次将从一级缓存中获取结果
User user2 = session.selectOne("com.example.mapper.User.selectById", 1L);
// 检验缓存是否失效:在一级缓存中,可以通过比较 user1 和 user2 是否相同来检验
if (user1 == user2) {
System.out.println("一级缓存有效");
} else {
System.out.println("一级缓存失效");
}
} finally {
session.close(); // 关闭 SqlSession,结束一级缓存的生命周期
}
二级缓存示例
二级缓存需要在 MyBatis 配置文件中配置,并在 Mapper 接口上使用 @CacheNamespace 注解。
<!-- mybatis-config.xml -->
<configuration>
<settings>
<!-- 启用二级缓存 -->
<setting name="cacheEnabled" value="true"/>
</settings>
<!-- 配置二级缓存的类型,这里使用 MyBatis 内置的 PerpetualCache -->
<cache type="org.apache.ibatis.cache.impl.PerpetualCache">
<!-- 二级缓存的大小限制 -->
<property name="size" value="1024"/>
</cache>
</configuration>
// 在 Mapper 接口上使用 @CacheNamespace 注解
@CacheNamespace
public interface UserMapper {
User selectById(Long id);
}
// 使用二级缓存的示例
SqlSession session = sqlSessionFactory.openSession();
try {
// 查询用户,结果将被存储在二级缓存中
User user1 = session.getMapper(UserMapper.class).selectById(1L);
// 关闭当前会话,然后重新打开一个新的会话
session.close();
session = sqlSessionFactory.openSession();
// 在新的会话中再次查询相同的用户,这次将从二级缓存中获取结果
User user2 = session.getMapper(UserMapper.class).selectById(1L);
// 检验缓存是否失效:在二级缓存中,可以通过比较 user1 和 user2 是否相同来检验
if (user1 == user2) {
System.out.println("二级缓存有效");
} else {
System.out.println("二级缓存失效");
}
} finally {
session.close(); // 关闭 SqlSession
}
检验缓存是否失效
-
一级缓存:由于一级缓存仅在
SqlSession的生命周期内有效,通常不需要手动检验缓存是否失效。当SqlSession关闭时,一级缓存自动失效。 -
二级缓存:可以通过比较两次查询返回的对象引用是否相同来检验缓存是否失效。如果相同,说明缓存有效;如果不同,说明缓存可能已经失效。
InheritableThreadLocal 实现父子线程局部变量的传递
线程间局部变量的传递问题,ThreadLocal,线程内部就是通过 inheritableThreadLocals 实现了父子线程间局部变量的传递。
一、父子线程间局部变量参数传递的方式 ThreadLocal
首先我们写看一段代码。
public class ThreadLocalTest implements Runnable{
private static final InheritableThreadLocal<String> MAIN_THREAD_LOCAL = new InheritableThreadLocal<>();
@SneakyThrows
@Override
public void run() {
System.out.println("threadlocal 默认值:"+ThreadLocalTest.MAIN_THREAD_LOCAL.get());
MAIN_THREAD_LOCAL.set("child thread value :"+Thread.currentThread().getName());
System.out.println("threadlocal 设置子线程值之后:"+ThreadLocalTest.MAIN_THREAD_LOCAL.get());
}
public String get(){
return MAIN_THREAD_LOCAL.get();
}
public void clean(){
MAIN_THREAD_LOCAL.remove();
}
public static void main(String[] args) {
ThreadLocalTest threadLocalTest = new ThreadLocalTest();
MAIN_THREAD_LOCAL.set("父线程的值 set 111");
System.out.println("启动:"+threadLocalTest.get());
for (int i = 0; i < 3; i++) {
new Thread(threadLocalTest).start();
// ThreadUtil.execAsync(threadLocalTest);
}
System.out.println("结束:"+threadLocalTest.get());
}
}在上面的这段代码中,我们就做了三个事情。
-
设置父线程中定义
ThreadLocal的值。 -
在子线程中打印父线程中
ThreadLocal的值。 -
启动多个子线程
二、子线程可以继承父线程局部变量的值吗
首先我们先说下答案,是可以继承的。上面代码的执行结果如下。
启动:父线程的值 set 111结束:父线程的值 set 111threadlocal 默认值:父线程的值 set 111threadlocal 设置子线程值之后:child thread value :Thread-1threadlocal 默认值:父线程的值 set 111threadlocal 默认值:父线程的值 set 111threadlocal 设置子线程值之后:child thread value :Thread-2threadlocal 设置子线程值之后:child thread value :Thread-0
在上面的代码中,我们的子线程优先打印了父线程中ThreadLocal的值,然后重新设置该值,再次读取。得出结论就是子线程可以通过ThreadLocal继承父线程的值,并且子线程自己内容再次重新设置不影响父线程的值。
三、父子线程局部变量传值的原理
3.1、new thread
在上面代码中,启动子线程的方式是new Thread(threadLocalTest).start();,所以秘密一定就在这一行代码里面。源码之下无秘密,我们一起来看下。
首先进入new Thread()的内部。
public Thread(Runnable target) {init(null, target, "Thread-" + nextThreadNum(), 0);}private void init(ThreadGroup g, Runnable target, String name,long stackSize) {init(g, target, name, stackSize, null, true);}
通过上面两个方法调用,最终进入到下面这个方法中。
private void init(ThreadGroup g, Runnable target, String name,long stackSize, AccessControlContext acc,boolean inheritThreadLocals) {}
init方法有个参数inheritThreadLocals,boolean类型的,如果为true,且可继承的线程局部变量不为空就继承。
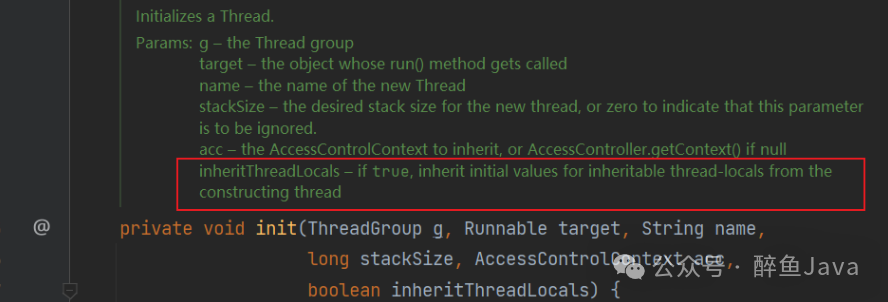

可以看到是直接对当前线程的inheritableThreadLocals直接进行的赋值操作,而值是通过ThreadLocal.createInheritedMap获取的,下面我们看下这个createInheritedMap方法做了哪些操作?

createInheritedMap方法是ThredLocal内部的方法,接收传递父线程的ThreadLocalMap为参数,该方法只做了一个事情,就是new了一个新的ThreadLocalMap。
跟进到new ThreadLocalMap(parentMap)方法内部,其实是把传进的值,一个个的遍历进行赋值到当前线程中。
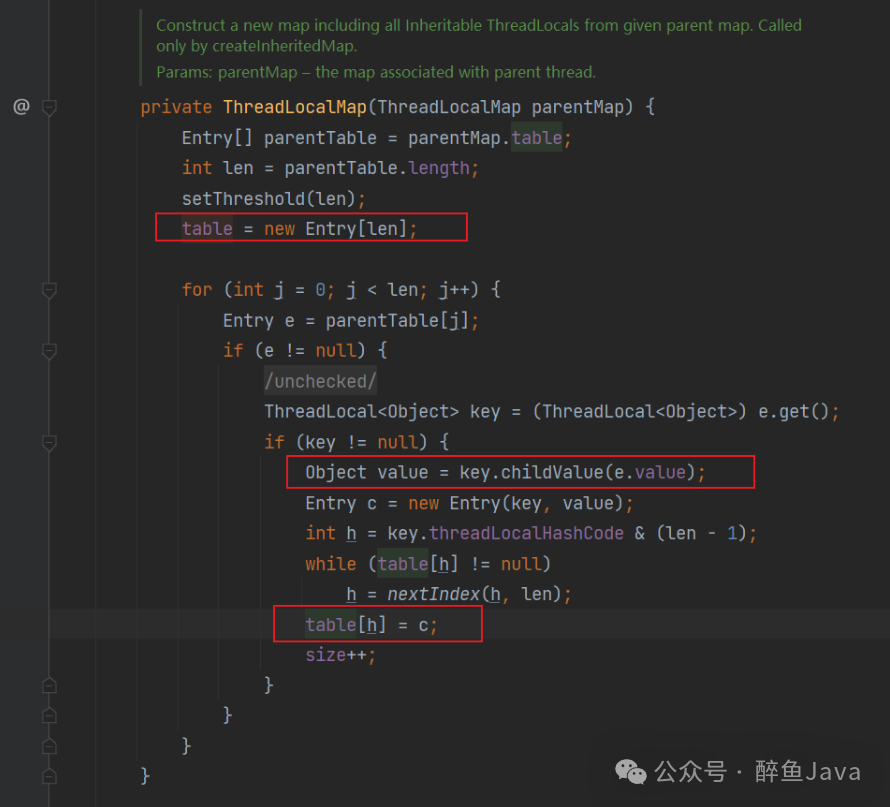
对于图中标记的第二个地方,childValue调用的是InheritableThreadLocal#childValue,该方法内也只做了一件事,就是返回传进来的值。
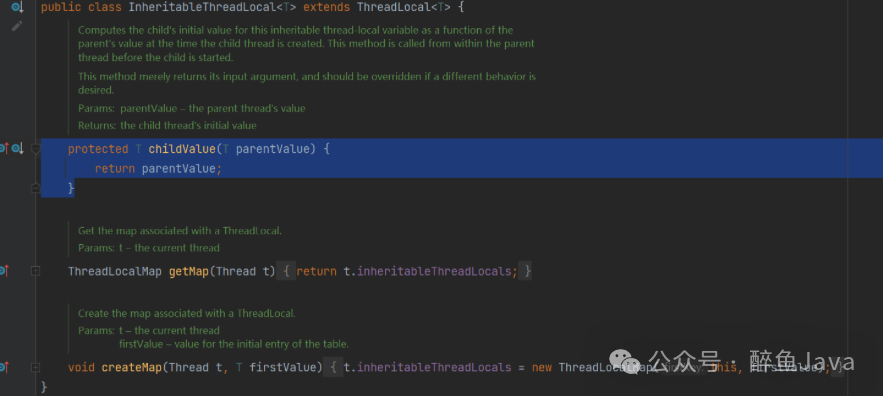
小结
父子线程之所以能传参,是因为我们使用了InheritableThreadLocal,这样在new Thread()时,就会进入到给子线程赋值父线程inheritableThreadLocals的逻辑中去。
扩展
用 ThreadLocal.withInitial创建的,怎么走到线程的if (inheritThreadLocals && parent.inheritableThreadLocals != null)?
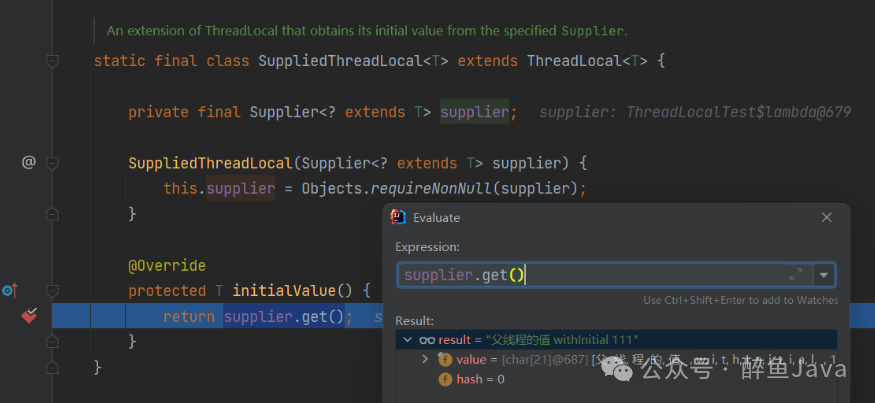
public static ThreadLocal<String> MAIN_THREAD_LOCAL = ThreadLocal.withInitial(() -> "父线程的值 withInitial 111");在上面的代码中,进行了ThreadLocal的初始化赋值,然后看下withInitial方法。

所以是当调用get方法时,才会触发赋值的操作,那么我们看下get方法。
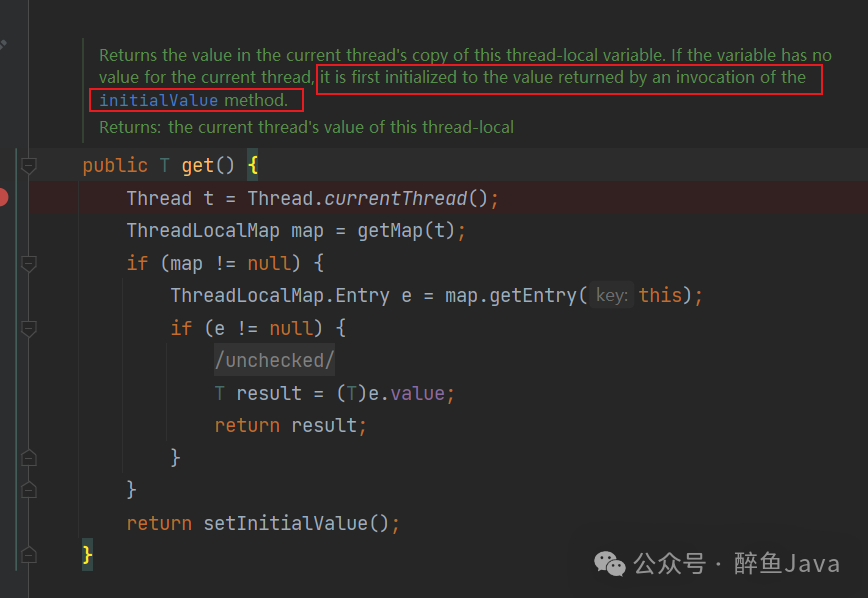
如果当前线程的局部变量没有值,返回初始化方法初始的值。
所以对于我们来说就是SuppliedThreadLocal#initialValue返回的值。
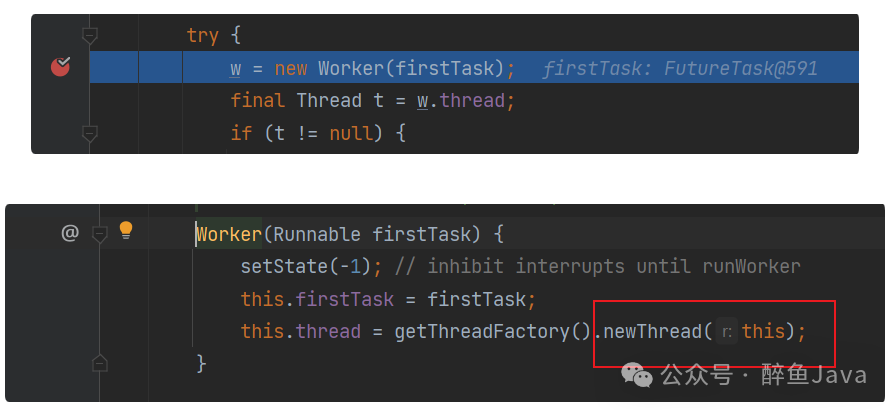
3.2、线程池
当使用线程池时,底层原理还是线程池中放入任务的逻辑,当放入线程池之后,会在AbstractExecutorService#submit()方法中执行execute方法,最终执行在ThreadPoolExecutor#execute(),在这里,就是把任务丢入线程池工作的逻辑,其中有个方法addWorker,该方法中有一行new Worker(),而在该Worker方法的内部,其实就是new Thread(),到了这,就与上面所说的一样了,到了判断inheritableThreadLocals的时候了。
四、如何解决内存泄漏
使用ThreadLocal的应用场景有很多,父子线程传参数的场景也有不少,但是有一个很关键的点内存溢出是需要重视的。解决ThreadLocal内存溢出的方式也很简单,就是在使用完成之后调用一下remove。
对于上面的代码示例,就是调用我们的clean方法。
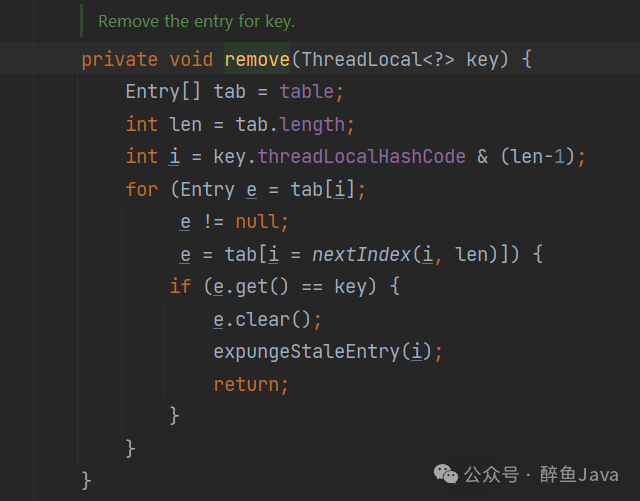
remove的代码如下,取值不为null时,执行删除逻辑。
五、总结
父子线程间可以通过ThreadLocal进行传递,测试了不同方式初始化ThreadLocal,并对比了new Thread()与线程池启动的区别。
线程池最后调用的还是Thread里面的方法。唯一需要注意的就是通过ThreadLocal.withInitial初始化是在get时赋值的。
1、SQL中为什么不要使用1=1
2、Redis中大Key与热Key的解决方案
3、面试官:对于MQ中的消息丢失你是如何理解的?
4、面试官:对于MQ中的消息堆积你是怎么理解的?
5、不掌握BigDecimal的四大坑你敢用吗?
6、线程池中线程异常后:销毁还是复用?
7、MySQL与Redis缓存一致性的实现与挑战
8、聊一下Redis实现分布式锁的8大坑
9、工作中用Redis最多的10种场景
10、Docker 国内镜像站全部失效,还有能用的吗?
聊聊系统设计思路
第1步: 明确需求
不管是系统设计还是业务开发,都必须先弄清楚需求,这好比是回答别人的提问,如果连对方的问题都没有弄清楚,后面所有的回答都可能是答非所问。
因此,系统设计的第一步是彻底理解需求,从实际工作经验来看,需求主要包括 2种类型:功能性需求和非功能性需求。
功能性需求
功能性需求是指系统需要执行的功能和行为,也就是系统实实在在要完成的功能,主要包含以下几个点:
-
系统应支持哪些核心功能?
-
是否有任何特定功能比其他功能更重要?
-
谁将使用这个系统(客户、技术团队、客服等)?
-
用户应该能够在系统上执行哪些特定操作?
-
用户将如何与系统交互(Web、移动应用程序、API 等)?
-
系统是否需要支持多语言?
-
系统必须处理哪些关键数据类型(文本、图像、结构化数据等)?
-
系统是否需要集成外部系统或三方服务?
非功能性需求
非功能性需求是指系统的质量属性和性能,主要包含以下几个点:
-
系统的预期规模是多少?
-
系统预计要处理多少数据量?
-
系统的输入和输出是什么?
-
预期的读写比是多少?
-
系统是否可以停机,或者是否需要高可用性?
-
是否有任何特定的延迟要求?
-
数据一致性有多重要?为了可用性,是否可以容忍一些最终的一致性?
-
是否有任何特定的非功能性需求(性能、可伸缩性、可靠性)我们应该关注?
需求是整个系统设计的风向标,因此,明确需求是整个系统设计的第一步,尽早地弄清楚需求,可以帮助我们更好的把握系统走向。
第2步: 系统容量预估
在明确了需求之后,第二步要完成的事情就是评估系统的容量,只有知道了系统的容量,才能更好的预算开发周期、人力投入、服务器投入以及其他的投入,帮助我们更好地做好后期决策。
系统容量预估,一般需要评估以下几个指标:
-
用户数:预估系统需要支撑的总用户数以及高峰时段的活跃用户数和最大并发用户数。
-
流量:计算日常TPS/QPS,以及峰值时的TPS/QPS。
-
存储:需要存储的数据类型(结构化、非结构化等),以及所需的存储总量(及其增长率)。
-
内存:估计系统可能消耗的内存总量。
-
网络:根据估计的流量和数据传输大小估算带宽需求。
另外,系统设计还需要做未来增长和可伸缩性要求考虑,比如支持数据几倍的增长以及支撑几年的数据增长,以确保系统能够处理随时间推移而增加的负载。
第3步: 架构设计
在做完需求分析和容量评估这些准备工作之后,我们就可以进入真正的设计阶段,系统设计(High-Level Design,HLD)是软件开发生命周期中最重要也是最难的一个阶段。
架构设计是一个宏观上的考虑,旨在定义系统的总体结构和高层次的架构,在这个阶段需要完成系统整体设计的蓝图,帮助开发团队理解和规划系统的各个组件及其相互关系,下图是 Google的一张系统设计蓝图:
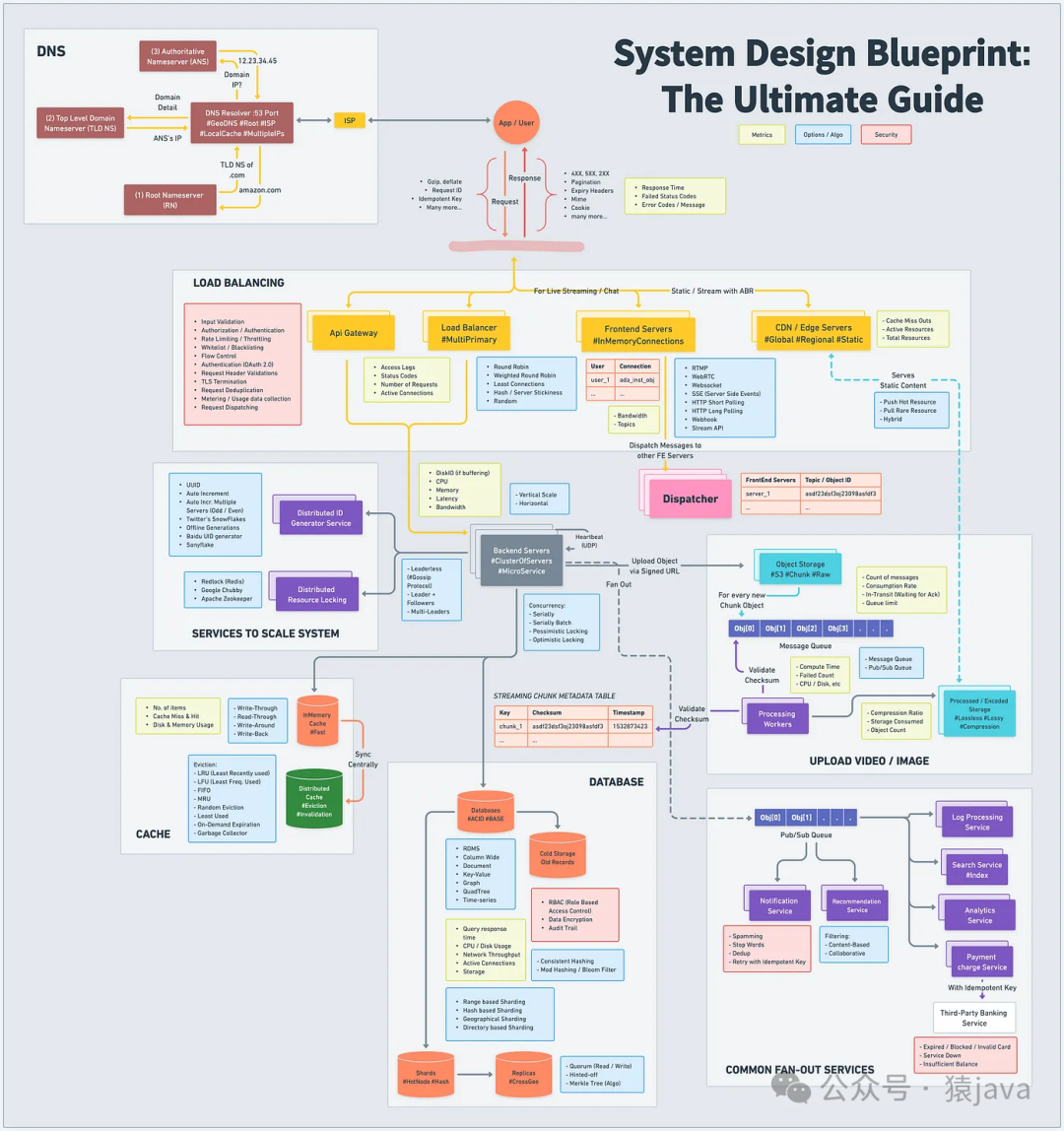
通过上述的蓝图可以看出:系统设计蓝图中包含以下主要组件:
-
DNS:DNS是一种分布式系统,由许多域名服务器和域名解析器组成,提供名称解析服务,将域名转换成IP。
-
客户端应用程序:表明用户将如何与系统(Web 浏览器、移动应用程序、桌面应用程序等)进行交互。
-
Web服务器:处理和响应客户端请求的服务器。
-
负载均衡器:用于将流量均匀地分配到服务器以处理大量流量。
-
应用程序服务:实现系统核心功能的后端逻辑层。
-
数据库:指定数据库类型:SQL 与 NoSQL,并简要说明原因。
-
缓存层:指定缓存(例如。Redis, Memcached),用于减少数据库的负载。
-
消息队列:如果系统需要使用异步通信。
-
外部服务:如果系统依赖于第三方 API(例如支付网关),请将其包括在内。
对于每个组件,一定要考虑权衡取舍,并说明为什么选择特定的技术或架构,关于设计图的绘制时,不要过度考虑小细节,而是更多站在宏观的角度。小细节可以在每个组件的设计中去推敲。
第4步: 数据库设计
绝大多数系统是需要和数据打交道的,因此数据库的设计也就显得至关重要,数据库设计通常包括数据库选型、数据建模、数据库结构设计等。
数据库选型
数据库选型通常是根据业务场景以确定最合适的数据库类型,主要包含以下几个考虑因素:
-
选择何种数据库,关系型数据库、NoSQL、ES等?还是多种数据库的组合?
-
是否需要考虑数据结构、可伸缩性、性能、一致性和查询模式等因素?
-
关系数据库(例如,MySQL、PostgreSQL)适用于具有复杂关系和 ACID属性的结构化数据。
-
NoSQL数据库(例如 MongoDB、Cassandra)适用于非结构化或半结构化数据、高可扩展性和最终一致性。
数据建模
数据建模通常会考虑以下因素:
-
确定系统需要存储和管理的主要数据实体或对象(例如,用户、产品、订单)。
-
考虑实体之间的关系以及它们之间的交互方式。
-
确定与每个实体关联的属性或属性(例如,用户具有电子邮件、姓名、地址)。
-
标识每个实体的任何唯一标识符或主键。
-
考虑规范化技术,以确保数据完整性并最大程度地减少冗余。
数据库结构设计
数据库结构设计也就是真实的表结构设计,主要需要考虑以下因素:
-
根据所选的数据库类型定义表、列、数据类型和关系。
-
设计主键、外键等。
-
设置合理的索引以优化查询性能。
另外,在更宏观的角度上,还需要考虑分库分表,多活,灾备等问题。
第5步: API 设计和通信协议
API和通信协议,它定义了系统内不同的组件间该如何交互以及外部客户端如何访问系统的功能,通常会考虑以下因素:
明确 API 要求
-
确定系统需要通过 API 公开的主要功能和服务。
-
考虑与 API 交互的客户端类型(例如,Web、移动、第三方服务)。
-
确定每个 API 的数据输入、输出和其他要求。
选择 API 类型
-
根据系统要求和客户需求选择合适的 API类型。
-
RESTful API通常用于基于 Web 的系统,并为资源操作提供统一的接口。
-
GraphQL API为客户端查询和检索特定数据字段提供了一种灵活高效的方法。
-
RPC(远程过程调用)API适用于具有明确定义的过程或功能的系统。
定义API 协议
-
根据系统的功能和数据模型设计清晰直观的 API URL。
-
为API选择适当的 HTTP方法(例如,GET、POST、PUT、DELETE)。
第6步:细化组件设计
在第3步中,我们分析了架构设计,但是它从宏观上的一个把握,而不会过分的关注细节,因此在此步骤中,我们需要对第3步中的一些核心组件进行更详细的设计,这里以 Java后端为例:
作为 Java后端,你需要了解自己业务的领域,比如金融,电商,财务,出行等,因为不同的领域会有一定的差异性。下面是组件细化的一些考虑点:
-
三高系统:是否是高可用,高性能,高扩展性的系统?如何保证三高?
-
微服务:是否采用微服务,微服务的框架是什么,SpringCloud还是 Dubbo?
-
架构:是否需要使用DDD架构?
-
数据库:是否需要分库分表?是否需要多活?是否需要定时备份?
-
负载均衡器:使用哪些负载均衡技术和算法?
-
缓存:使用什么缓存?缓存放在哪里?如何处理缓存失效?
-
单点故障:是否有单点问题?如何解决单点问题?
-
身份验证/授权:如何安全地管理用户访问和权限?
-
速率限制:如何防止过度使用或滥用 API?
-
安全问题:如何保证系统安全和API安全?
以下都是在后端组件中需要考虑的问题,当然,我们需要根据自己所处的角色和领域,灵活的设计。
第7步: 解决关键问题
系统设计中难免会遇到一些技术难点以及核心挑战,这些挑战主要包括可扩展性和性能,以及可靠性、安全性和成本问题。为了更好的解决这些问题,下面也给出了具体的思路:
解决可扩展性和性能问题
-
增加节点进行水平扩展(横向扩展)。
-
增加单个资源(例如 CPU、内存、存储)的容量进行垂直扩展(纵向扩展)。
-
增加缓存以减少数据库压力并缩短响应时间。
-
优化数据结构和算法。
-
优化数据库查询和索引。
-
数据库分区和分库分片可提高查询性能。
-
增加CDN,加速静态资源访问。
-
利用异步编程模型高效处理并发请求。
解决可靠性问题
可靠性是指系统即使在出现故障或错误的情况下也能正确和一致地运行的能力。以下是系统在可靠性上的一些关键考虑因素:
-
识别系统架构中的单点问题,通过集群等方式消除单点故障。
-
服务或者数据做多活,以防止区域故障或灾难。
-
数据备份,确保数据可用性和持久性。
-
限流和降级机制,以防止级联故障并保护系统免受过载影响。
-
加强监控和警报,以及时检测故障、性能问题和异常情况。
总结
最后,我们再总结下系统设计的 7个步骤:
-
第1步: 明确需求
-
第2步: 系统容量预估
-
第3步: 架构设计
-
第4步: 数据库设计
-
第5步: API设计和通信协议
-
第6步: 细化组件设计
-
第7步: 解决关键问题
有了上述 7个步骤,在做系统设计时就有一个清晰的思路,最终方案如何实施还需要结合实际的业务以及最终的权衡来定。另外,上述 7个步骤也可以帮助我们轻松的应对面试中的各种系统设计问题。
5种编程范式
编程范式是指一种编程风格或者编程思想,它不是指特定的语言,而是用一种相对高级的方式来构建和概念化计算机程序的实现。
在很多编程语言中,它们的实现都需要遵循这些范式,一种编程语言可以支持一种或多种范式。
编程范式类型
从整体上看,编程范式有两种:命令式编程范式和声明式编程范式。
命令式编程范式
命令式编程范式(imperative paradigm)是一种计算机编程范式,它要求开发者以一系列计算步骤的形式来表达他们的代码逻辑。具体来说,命令式编程需要开发者详细指定每一个程序执行的具体操作,以及这些操作的执行顺序。此范式的核心是变量、赋值语句以及控制流语句,如循环和条件语句
命令式编程范式可以细分为 2种:
-
面向过程编程(procedural paradigm)
-
面向对象编程(object-oriented paradigm)
声明式编程范式
声明式编程范式(declarative program)是一种编程范式,与命令式编程相对立。它描述目标的性质,让计算机明白目标,而非流程。声明式编程不用告诉计算机问题领域,从而避免随之而来的副作用。而命令式编程则需要用算法来明确的指出每一步该怎么做。
声明式编程范式可以细分为 3种:
-
函数式编程(functional paradigm)
-
逻辑编程(logic paradigm)
-
响应式编程(reactive paradigm)
编程范式详解
面向过程编程
面向过程编程(Procedural Programming)是一种基于过程(或函数)的编程范式,在这种范式中,程序被视为一系列顺序执行的指令,通过调用过程来完成任务。
面向过程编程强调模块化和代码重用,将复杂的问题分解为若干子问题,并通过过程调用的方式逐步解决。
优点
-
逻辑清晰,易于理解和实现。
-
适合小型项目和简单算法的实现。
-
代码执行效率较高。
缺点
-
难以管理大型项目,代码可读性和维护性较差。
-
缺乏抽象,数据和操作紧耦合,难以重用和扩展。
举例说明
在面向过程编程范式中,步骤的顺序至关重要,因为在执行步骤时,给定步骤将根据变量的当前值产生不同的后果。c语言是典型的面向过程编程语言,因此,下面给出一个 c语言的示例代码,打印0,1,2:
#include <stdio.h>
int main()
{
int a = 0;
printf("a is: %d\n", a); //prints-> a is 0
b = 1;
printf("b is: %d\n", b); //prints-> b is 1
c = 2;
printf("c is: %d\n", c); //prints-> c is 2
return 0;
}
在上面的例子中,我们通过命令让计算机一行一行地计算,最后将结果值打印出来。
面向对象编程
面向对象编程(Object-Oriented Programming)是一种基于对象和类的编程范式。在这种范式中,程序被视为一组对象的集合,对象通过方法进行交互。面向对象编程强调数据封装、继承和多态,旨在提高代码的重用性和扩展性。
-
数据封装:将数据和操作封装在对象内部,通过方法来访问和修改数据。
-
继承:通过继承机制实现代码的重用和扩展,子类继承父类的属性和方法。
-
多态:通过多态机制实现同一方法在不同对象上的不同表现。
优点
-
模块化强,代码重用性高。
-
适合大型项目的管理和维护。
-
提供更高的抽象级别,易于建模复杂系统。
缺点
-
学习曲线较陡,理解和实现较为复杂。
-
执行效率较低,尤其是在多态机制的实现上。
-
可能导致过度设计,增加系统的复杂性。
举例说明
Java语言是一种典型的面向对象编程语言,从 Java 8 开始又引入了函数式编程,下面给出一个 Java面向对象的示例:
// 定义一个父类
class Animal {
private String name;
private String color;
public void call() { }
public void eat() { }
}
// 定义一个子类
class Dog extends Animal {
@Override
public void call() {
System.out.println("Woof woof...");
}
}
public class Main {
public static void main(String[] args) {
Animal dog = new Dog();
dog.call(); // 输出: Woof woof...
dog.eat();
}
}
在上面的示例中,我们把 Animal 看作一个对象,因此可以定义一个 Animal 类,它具有名字和颜色属性,并且具有 call()和 eat()方法用来表示叫和吃东西等行为。在 main() 方法中,我们创建了一个 Animal 对象 dog,并调用了其方法来叫和吃东西。
这个示例展示了面向对象编程的特点,即通过定义类和创建对象来实现程序的设计和开发。具体步骤如下:
-
定义一个 Animal 类,它具有名字和颜色属性,并且定义了 call()和 eat()方法;
-
在 main() 方法中,通过 new 关键字创建一个 Animal 对象 dog;
-
调用 dog 对象的 call()和 eat() 方法来表示叫和吃东西;
函数式编程
函数式编程(Functional Programming)是一种基于数学函数的编程范式,在这种范式中,程序被视为一组函数的组合,通过函数调用和组合来完成任务。
函数式编程强调函数的纯粹性(无副作用)、不可变性和高阶函数,旨在提高代码的简洁性和可测试性,且具备以下特点:
-
纯函数:在相同输入下总是产生相同输出,没有副作用。
-
不可变性:数据不可变,通过函数返回新的数据。
-
高阶函数:可以接受函数作为参数或返回函数。
优点
-
代码简洁,可读性和可测试性强。
-
易于并发和并行编程。
-
强调不可变性,减少了状态的变化和副作用。
缺点
-
学习曲线较陡,理解和实现较为复杂。
-
在某些场景下可能导致性能问题。
-
对于状态变化频繁的应用,可能不太适合。
举例说明
python 语言就是一种函数式编程语言,下面给出一个 python版本的示例:
# 定义一个纯函数
def add(a, b):
return a + b
# 定义一个高阶函数
def apply_func(func, x, y):
return func(x, y)
result = apply_func(add, 10, 5)
print(f"Result: {result}") # 输出: Result: 15
逻辑编程
逻辑编程(Logic Programming)是一种基于形式逻辑的编程范式。在这种范式中,程序被视为一组逻辑规则和事实,通过逻辑推理来解决问题。逻辑编程强调声明式编程,即描述“是什么”而非“怎么做”,常用于人工智能和知识表示领域。
规则:描述条件和结论的逻辑关系。
事实:描述已知的信息。
查询:通过逻辑推理得到结论。
优点
适合解决复杂的推理和搜索问题。提供高层次的抽象,易于表示知识和规则。
缺点
执行效率较低,尤其在大规模数据集上。难以表示状态变化和动态行为。学习曲线较陡,理解和实现较为复杂。
举例说明
逻辑编程最著名的代表是 Prolog 语言。下面是一个使用 Prolog 语言的简单示例,展示了逻辑编程的特点:
% 定义事实
parent(tom, bob).
parent(bob, alice).
% 定义规则
grandparent(X, Y) :- parent(X, Z), parent(Z, Y).
% 查询祖父母关系
?- grandparent(tom, alice).
% 输出: true
在上面的示例中,我们定义了一些逻辑规则和事实,包括父母关系和祖先关系。具体步骤如下:
-
定义了 parent 谓词,表示父母关系,例如 tom 是 bob 的父亲;
-
定义了 grandparent 规则,使用递归的方式判断某人是否是某人的祖先。如果某人直接是某人的父母,则是其祖先;如果某人是某人的父母的祖先,则也是其祖先;
-
使用?-查询符号,查询 tom 是否是 alice 的祖先;
并发编程
并发编程(Concurrent Programming)是一种旨在同时执行多个计算任务的编程范式。在这种范式中,程序通过多个独立的线程或进程并发执行,以提高系统的性能和响应能力。并发编程强调任务的并发执行和同步,适用于多核处理器和分布式系统。
并发编程具备以下特征:
-
线程:轻量级的并发执行单元,多个线程共享同一进程的资源。
-
进程:独立的并发执行单元,进程之间相互隔离。
-
同步:控制并发任务之间的协调和通信,避免竞争条件和死锁。
优点
-
提高系统的性能和响应能力。
-
适用于多核处理器和分布式系统。
-
能够处理并发任务,如网络请求和IO操作。
缺点
-
编程复杂度高,容易出现竞争条件和死锁。
-
调试和测试困难,难以重现并发问题。
-
资源开销较大,尤其在进程间通信上。
举例说明
下面为一个 python的并发编程的示例代码:
import threading
# 定义一个函数作为线程的任务
def print_numbers():
for i in range(5):
print(i)
# 创建并启动多个线程
threads = []
for _ in range(3):
t = threading.Thread(target=print_numbers)
threads.append(t)
t.start()
# 等待所有线程结束
for t in threads:
t.join()
总结
不同的编程范式提供了不同的思维方式和解决问题的方法。面向过程编程适合简单的算法和小型项目,面向对象编程适合大型项目和复杂系统,函数式编程适合并发和并行计算,逻辑编程适合推理和知识表示,并发编程适合处理并发任务。
SOLID
在 架构整洁之道 这本经典的书籍中有一套关于软件设计的SOLID原则,SOLID 实际上是五个设计原则首字母的缩写,它们分别是:
-
单一职责原则(Single responsibility principle, SRP)
-
开放封闭原则(Open–closed principle, OCP)
-
Liskov 替换原则(Liskov substitution principle, LSP)
-
接口隔离原则(Interface segregation principle, ISP)
-
依赖倒置原则(Dependency inversion principle, DIP)
单一职责原则:任何一个软件模块都应该只对某一类行为者负责
开放封闭原则:软件实体应该对扩展开放,对修改关闭
Liskov替换原则:子类型必须能够替换其父类型
接口隔离原则:不应强迫客户依赖他们不使用的接口
依赖倒置原则:高层模块不应该依赖低层模块;抽象不应该依赖于细节
里氏替换原则
什么是里式替换原则?
里式替换原则,Liskov substitution principle(简称LSP),它是以作者 Barbara Liskov(一位美国女性计算机科学家,对编程语言和分布式计算做出了开创性的贡献,于2008年获得图灵奖)的名字命名的,Barbara Liskov 曾在1987年的会议主题演讲“数据抽象”中描述了子类型:
Let Φ(x) be a property provable about objects x of type T. Then Φ(y) should be true for objects y of type S where S is a subtype of T.
Liskov替换原则的核心:设Φ(x)是关于 T类型对象 x的可证明性质。那么对于 S类型的对象 y,Φ(y)应该为真,其中 S是 T的子类型。这种科学的定义是不是过于抽象,太烧脑了?因此,在实际软件开发中的 Liskov替换原则可以这样:
The principle defines that objects of a superclass shall be replaceable with objects of its subclasses without breaking the application.
That requires the objects of your subclasses to behave in the same way as the objects of your superclass.
该原则定义了在不破坏应用程序的前提下,超类的对象应该可以被其子类的对象替换,这就要求子类对象的行为方式与您的超类对象相同。Robert C. Martin 对SLP的描述更加直接:
Subtypes must be substitutable for their base types.
子类型必须可以替代它们的基本类型。
通过上面几个描述,我们可以把 LSP通俗的表达成:子类型必须能够替换其父类。
如何实现Liskov替换原则?
说起 Liskov替换原则的实现,就不得不先看一个著名的违反 LSP设计案例:正方形/长方形问题。尽管这个 case已经有点老掉牙,但是为了帮助理解,我们还是炒一次剩饭。
数学知识告诉我们:正方形是一种特殊的长方形,因此用 java代码分别定义 Rectangle(长方形) 和 Square(正方形)两个类,并且 Square继承 Rectangle,代码如下:
// Rectangle(长方形)
public class Rectangle {
private int length;
private int width;
public void setLength(double length) {
this.length = length;
}
public void setWidth(double width) {
this.width = width;
}
}
// Square(正方形)
public class Square extends Rectangle {
// 设置边长
@Override
public void setLength(double length) {
super.setLength(length);
super.setWidth(length);
}
@Override
public void setWidth(double width) {
super.setLength(width);
super.setWidth(width);
}
}
假设现在的需求是计算几何图形的面积,因此面积计算代码会如下实现:
// 计算面积
public int area(){
Rectangle r = new Square();
// 设置长度
r.setLength(3);
// 设置宽度
r.setWidth(4);
r.getLength * r.getWidth = 3 * 4 = 12;
// 正方形
Rectangle r = new Rectangle();
// 设置长度
r.setLength(3); // Length=3, Width=3
// 设置宽度
r.setWidth(4); // Length=4, Width=4
r.getLength * r.getWidth = 4 * 4 = 16;
}
在这个例子中,Square类重写了 setLength和 setWidth方法,以确保正方形的长度和宽度总是相等的。因此:假设 length=3,width=4
-
对于长方形,面积 = length * width= 3 * 4 = 12,符合预期;
-
然而,用 Square对象替换 Rectangle对象时,程序的行为发生了变化,本期望矩形的面积为12(3 * 4),但实际输出为 4*4=16,违反了里氏替换原则。
如何解决这个 bad case呢?
可以定义一个几何图形的接口,设定一个计算面积的方法,然后长方形、正方形都实现这个接口,实现各自的面积计算逻辑,整体思路如下:
// 基类
public interface Geometry{
int area();
}
public class Rectangle implements Geometry{
private int length;
private int width;
public int area(){
return length * width;
}
}
public class Square implements Geometry{
private int side;
public int area(){
return side * side;
}
}
我们再来看一个 LSP使用的例子:
假设有一个股票交易的场景,而且需要支持债券、股票和期权等不同证券类型的多种交易类型,我们就可以考虑使用 LSP来解决这个问题。
首先,我们定义一个交易的基类,并且在基类中定义买入和卖出两个方法实现,代码如下:
// 定义一个交易类
public class Transaction{
// 买进操作
public void buy(String stock, int quantity, float price){
}
// 卖出操作
public void sell(String stock, int quantity, float price){
}
}
接着,定义一个子类:股票交易,它和基类具有相同的买入和卖出行为,因此,在股票交易子类中需要重写基类的方法,代码如下:
// 定义股票交易子类,定义股票特定的买卖动作逻辑
public class StockTransaction extends Transaction{
@Override
public void buy(String stock, int quantity, float price){
}
@Override
public void sell(String stock, int quantity, float price){
}
}
同样,定义一个子类:基金交易,它和基类具有相同的买入和卖出行为,因此,在基金交易子类中需要重写基类的方法,代码如下:
// 定义基金交易子类,定义基金特定的买卖动作逻辑
public class FundTransaction extends Transaction{
@Override
public void buy(String stock, int quantity, float price){
}
@Override
public void sell(String stock, int quantity, float price){
}
}
同样,我们还可以定义了债券交易子类,债券交易和交易基类具有相同的行为:买入和卖出。所以只需要重写基类的方法,实现子类特定的实现就ok了。
// 定义债券交易子类,定义债券特定的买卖动作逻辑
public class BondTransaction extends Transaction{
@Override
public void buy(String stock, int quantity, float price){
}
@Override
public void sell(String stock, int quantity, float price){
}
}
上述交易的案例,股票交易和基金交易子类替换基类之后,并没有破坏基类的买入卖出行为,更具体地说,替换的子类实例仍提供 buy()和 sell(),可以以相同方式调用的功能。这个符合LSP。
经过我们的抽象、分离和改造之后,Stock.updateStock()类就稳定下来了,再也不需要增加一个事件然后增加一个else if分支处理。这种抽象带来的好处也是很明显的:每次有新的库存变更事件,只需要增加一个实现类,其他的逻辑都不需要更改,当库存事件无效时只需要把实现类删除即可。
总结
Liskov替换原则扩展了OCP开闭原则,它描述的子类型必须能够替换其父类型,而不会破坏应用程序。因此,子类需要遵循以下规则:
-
不要对输入参数实施比父类实施更严格的验证规则。
-
至少对父类应用的所有输出参数应用相同的规则。
Liskov替换原则相对前面的单一职责和开闭原则稍微晦涩一些,因此在开发中容易误用,因此我们特别要注意类之间是否存在继承关系。
LSP不仅可以用在类关系上,也可以应用在接口设计中。
单一职责原则
关于单一职责,这里归纳最常见的三个版本:
-
版本一:一个类只有一个引起变化的原因
-
版本二:一个类都应该只负责一项职责
-
版本三:一个类只能干一件事情
单一职责原则,英文是:Single responsibility principle(SRP),是 Robert C. Martin提出的 SOLID原则中的一种,所以,我们先看看 作者对单一职责原则的描述,这里摘取了作者关于单一职责的原文:
The Single Responsibility Principle (SRP) states that
each software module should have one and only one reason to change.
原文翻译为:单一职责原则指出,任何一个软件模块都应该有一个且只有一个修改的理由。
定义看起来很严谨,但似乎和现实是相冲突的,因为软件设计本身就是一门关注长期变化的学问,变化是软件中最常见不过的问题,在现实环境中,软件系统为了满足用户和所有者的要求,势必会作出各种修改,而系统的用户或者所有者就是该设计原则所指的"被修改的原因"。
于是乎,作者又重新把单一职责描述为:
The single responsibility principle states that every module
or class should have responsibility over a single part of
the functionality provided by the software, and that
responsibility should be entirely encapsulated by the class.
原文翻译为:单一职责原则指出,每个模块或类应该只负责软件所提供功能的一部分,并且这个职责应该完全被该类封装。
在这个定义中,每个模块或者类只负责软件的一部分功能,那这一部分是多少呢?这部分功能是否可以包含不同类型的行为呢?比如,电商中的订单和物流都可以叫做电商的一部分功能,但是他们在业务意义上显然是不同的领域,因此,该定义缺乏了定性。
于是乎,作者再次修改了单一职责的定义:
Each module should only be responsible to one actor.
原文翻译为:任何一个软件模块都应该只对某一类行为者负责
这个定义,只要是能归结成一类的行为,都可以属于某个模块的功能,这样定义看起来更符合现实业务的语意。
软件模块是什么?
在上述单一职责几个定义中都提到了软件模块,那么,软件模块到底是什么呢?
软件模块(Software Module)是指软件系统中的一个独立单元,它包含一组相关的功能和数据,这些模块是通过封装数据和功能来实现的,以便实现更高的代码复用性、可维护性和可扩展性。通常具有以下特点:
-
独立性:模块是相对独立的代码单元,可以单独开发、测试和部署。模块的独立性提高了系统的灵活性,使得各个模块可以独立演化和更新,而不影响其他模块。
-
封装性:模块内部的数据和实现细节对外界隐藏,只通过公开的接口与其他模块进行交互。封装性提高了代码的安全性和可维护性。
-
职责单一:每个模块通常只负责一组相关的功能,这有助于遵循单一职责原则,使得模块更加易于理解和维护。
-
可重用性:模块设计得当,可以在不同的项目中重复使用,提高了开发效率和代码质量。
-
可替换性:模块通过标准化的接口与外界交互,可以在不影响其他部分的前提下替换或更新某个模块。
为了更好地说明软件模块,这里以一个电商系统为例,它可能包含以下几个模块:
-
用户管理模块:
-
功能:处理用户的注册、登录、个人信息管理等。
-
接口:提供用户注册、登录、信息更新等服务。
-
-
订单管理模块:
-
功能:处理订单的创建、更新、查询等。
-
接口:提供订单创建、订单状态更新、订单查询等服务。
-
-
支付处理模块:
-
功能:处理订单的支付、退款等。
-
接口:提供支付请求、支付状态查询、退款等服务。
-
-
库存管理模块:
-
功能:处理商品的库存查询、更新等。
-
接口:提供库存查询、库存更新等服务。
-
单一职责示例
为了更好的说明任何一个软件模块都应该只对某一类行为者负责这个定义,下面我们通过2个 Java反例来进行演示。
反例1
假设有一个 Employee员工类并且包含以下 3个方法:
public class Employee {
// calculatePay() 实现计算员工薪酬
public Money calculatePay();
// save() 将Employee对象管理的数据存储到企业数据库中
public void save();
// postEvent() 用于促销活动发布
public void postEvent();
}
刚看上去,这个类设计得还挺符合实际业务,员工有计算薪酬、保存数据、发布促销等行为,但是这 3个方法对应三类不同的行为者,计算薪酬属于财务的行为,保存数据属于数据管理员的行为,发布促销属于销售的行为。
因此,Employee类将三类行为耦合在一起,违反了单一职责原则。假如一个普通员工不小心调用了calculatePay()方法,把每个员工的薪酬计算成了实际工资的2位,那可想而知这是一个灾难性的问题。
如果增加新需求,要求员工能够导出报表,因此,需要在 Employee类中增加了一个新的方法,代码如下:
// 导出报表
void exportReport();
接着需求又一个一个增加,Employee类就得一次一次的变动,这会导致什么结果呢?
一方面,Employee类会不断地膨胀;另一方面,可能业务需求完全不同,却始终需要在同一个 Employee类上改动,合理吗?
联想一下你的日常开发,是否也有这样的设计?把很多不同的行为都耦合到同一个类中,然后随着业务的增加,该类急剧膨胀,最后无法维护。
该如何解决这种问题呢?
解决这个问题的方法有很多,特定的行为只能由特定的行为者来操作,因此,需要把 Employee类拆解成 3种行为者(财务、数据管理员、销售),Employee类拆分之后的代码如下:
// 财务行为
public class FinanceStaff {
public Money calculatePay();
}
// 数据管理员行为
public class TechnicalStaff {
public void save();
}
// 销售行为
public class OperatorStaff {
public String postEvent();
}
反例2
假设需要开发一个电商系统,其中有一个 Order订单类,负责处理订单的创建、订单的支付以及订单的通知,代码如下:
public class Order {
public void createOrder() {
// 订单创建逻辑
}
public void processPayment() {
// 支付处理逻辑
}
public void sendNotification() {
// 发送通知逻辑
}
}
在上述代码中,Order类同时承担了订单创建、支付处理和通知发送的职责,违反了单一职责原则,因为一个类有多个引起变化的原因。
为了遵循SRP,我们需要将不同的职责分离到不同的类中,因此可以创建三个类:Order类负责订单创建,PaymentProcessor类负责支付处理,NotificationService类负责通知发送,每个类都只承担一个职责,从而遵循了单一职责原则。代码如下:
public class Order {
public void createOrder() {
// 订单创建逻辑
}
}
public class PaymentProcessor {
public void processPayment(Order order) {
// 支付处理逻辑
}
}
public class NotificationService {
public void sendNotification(Order order) {
// 发送通知逻辑
}
}
上面2个示例代码的拆分都遵从了原则:因相同原因而发生变化的事物聚集在一起,因不同原因而改变的事物分开。这就是单一职责的真正体现,也是定义内聚和耦合的一种方式。
总结
从作者 Robert C. Martin对单一职责的 3次定义变更,我们可以看出:
-
单一职责原则本质上就是要理解分离关注点。
-
单一职责原则可以应用于不同的层次,小到一个函数,大到一个系统。
-
软件设计也不可能一成不变。
回归到实际的工作中,我们可以把一个系统模块看作一个单一职责的行为者,比如:订单系统只关注订单相关的行为,交易系统只关注交易相关的行为,我们也可以把类作为一个单一职责的行为者,比如:订单类,把订单相关的 CRUD聚合在一起,支付类,把支付相关的信息聚合在一起。
因此,任何一个软件模块都应该只对某一类行为者负责这个定义才更适合单一职责。
最后,单一职责原则是面向对象设计的重要原则之一,它可以提高代码的可维护性、可读性和可扩展性,在日常开发中,遵循 SRP可以有效地降低类之间的耦合度,提高系统的稳定性和灵活性,从而写出更高质量的代码。
开闭原则
开放封闭原则,英文是:Open–closed principle, 简称OCP,是该原则是 Bertrand Meyer 在1988年提出的,最后被 Robert C. Martin收录到 SOLID原则,开闭原则指出:
Software entities should be open for extension, but closed for modification.
软件实体应该对扩展开放,对修改关闭。
如何实现开闭原则?
"对扩展开放,对修改关闭",如何理解呢?我们先看一个案例,如下图,给出了电商领域库存系统库存变更的简易模型图,库存系统接收外部系统库存变更事件,然后对数据库中的库存进行修改。
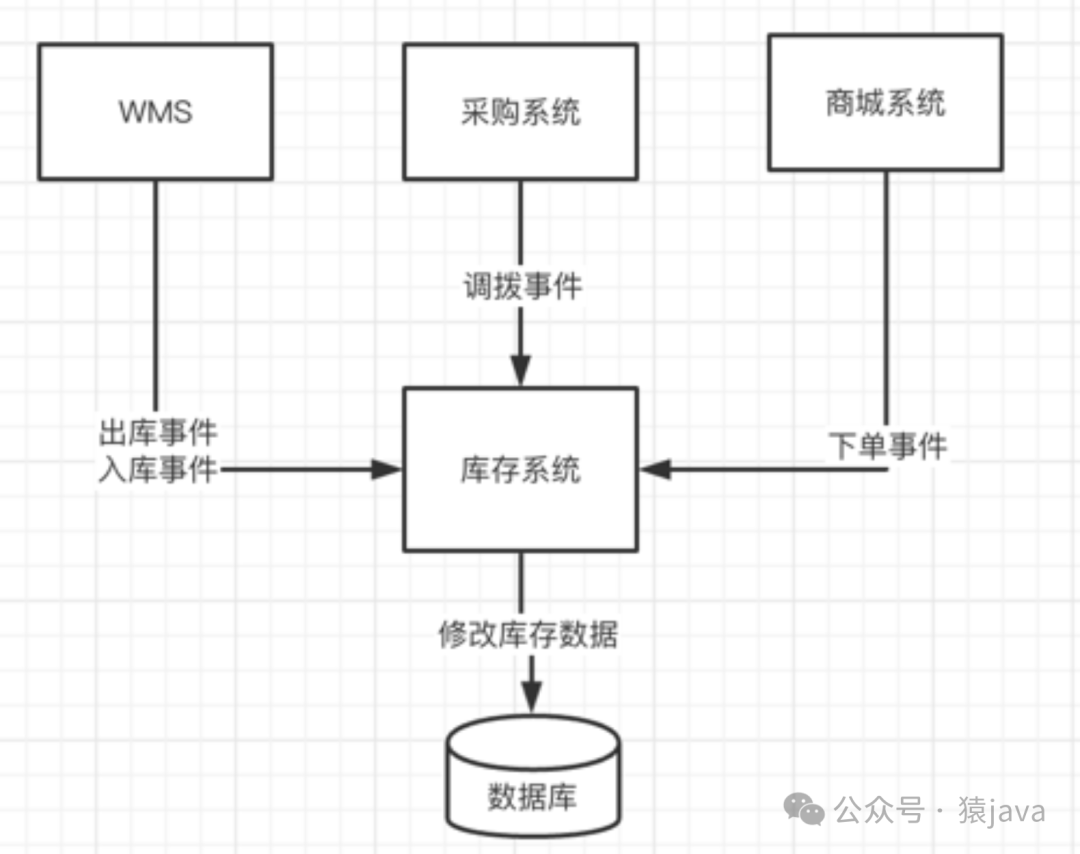
面对这个业务需求,很多人的代码会写出这样
public class Stock {
public void updateStock(String event){
if("outOfStock" == event){
// todo 出库事件 库存操作
}else if("warehousing" == event){
// todo 入库事件 库存操作
}
}
}
这时,新的需求来了:WMS仓储系统内部会产生盘点事件(盘盈/盘亏),这些事件会导致变更库存。于是,代码就会发展成下面这样
public class Stock {
public void updateStock(String event){
if("outOfStock" == event){
// todo 出库事件 库存操作
}else if("warehousing" == event){
// todo 入库事件 库存操作
}else if("panSurplus" == event){
// todo 盘盈事件 库存操作
}else if("loss" == event){
// todo 盘亏事件 库存操作
}
}
}
很显然,上述代码的实现,每来一个需求,就需要修改一次代码,在方法中增加一个 else if分支,因此 Stock类就一直处于变更中,不稳定。
有没有什么好的办法,可以使得这个代码不用被修改,但是又能够灵活的扩展,满足业务需求呢?
这个时候我们就要搬出 java的三大法宝:继承,实现,多态。
我们发现整个业务模型是:事件导致库存变更。所以,能不能把事件抽离出来?把它抽象成一个接口,代码如下:
public interface Event {
void updateStock(String event);
}
每种事件对应一种库存变更,抽象成一个具体的实现类,代码如下
入库事件
public class WarehousingEvent implements Event {
public void updateStock(String event){
// 业务逻辑
}
}
出库事件
public class OutOfStockEvent implements Event {
public void updateStock(String event){
// 业务逻辑
}
}
xxx事件
public class XXXEvent implements Event {
public void updateStock(String event){
// 业务逻辑
}
}
最后,Stock类中 updateStock()库存变更逻辑就可以抽象成下面这样:
public class Stock {
public void updateStock(String event){
// 根据事件类型获取真实的实现类
Event event = getEventInstance(event);
// 库存变更操作
event.updateStock();
}
}
经过抽象、分离和改造之后,Stock.updateStock()类就稳定下来了,再也不需要每增加一个事件就需要增加一个 else if分支处理,这种抽象带来的好处也是很明显的:每次有新的库存变更事件,只需要增加一个实现类,其他的逻辑都不需要更改,当库存事件无效时只需要把实现类删除即可。
开闭原则是常见方式
在Java编程中,遵循开闭原则的常见方式有:使用抽象类和接口、使用策略模式、使用装饰器模式等。
抽象类和接口
抽象类和接口是 Java中实现 开闭原则的基础,通过定义抽象类或接口,程序员可以在不修改已有代码的情况下,通过继承或实现来扩展新功能。因此,我们强烈建议:面向接口编程。
策略模式
策略模式是一种行为设计模式,允许在运行时选择算法的实现,策略模式通过定义一系列算法,并将每个算法封装在独立的类中,使得它们可以相互替换。
在上面的示例讲解中,其实使用的就是策略模式,当后期有其他的库存事件时,我们只需要添加扩展类,而无需修改现有的代码。
装饰器模式
装饰器模式是一种结构设计模式,允许向一个对象动态添加行为。装饰器模式通过创建一个装饰器类来包装原始类,从而增加新的功能。示例代码:
// 定义一个接口
public interface Coffee {
String getDescription();
double getCost();
}
// 实现接口的具体类
public class SimpleCoffee implements Coffee {
@Override
public String getDescription() {
return "Simple Coffee";
}
@Override
public double getCost() {
return 5.0;
}
}
// 创建装饰器抽象类
public abstract class CoffeeDecorator implements Coffee {
protected Coffee decoratedCoffee;
public CoffeeDecorator(Coffee coffee) {
this.decoratedCoffee = coffee;
}
@Override
public String getDescription() {
return decoratedCoffee.getDescription();
}
@Override
public double getCost() {
return decoratedCoffee.getCost();
}
}
// 实现具体的装饰器类
public class MilkDecorator extends CoffeeDecorator {
public MilkDecorator(Coffee coffee) {
super(coffee);
}
@Override
public String getDescription() {
return decoratedCoffee.getDescription() + ", Milk";
}
@Override
public double getCost() {
return decoratedCoffee.getCost() + 1.5;
}
}
public class SugarDecorator extends CoffeeDecorator {
public SugarDecorator(Coffee coffee) {
super(coffee);
}
@Override
public String getDescription() {
return decoratedCoffee.getDescription() + ", Sugar";
}
@Override
public double getCost() {
return decoratedCoffee.getCost() + 0.5;
}
}
// 客户端代码
public class CoffeeShop {
public static void main(String[] args) {
Coffee coffee = new SimpleCoffee();
System.out.println(coffee.getDescription() + " $" + coffee.getCost());
coffee = new MilkDecorator(coffee);
System.out.println(coffee.getDescription() + " $" + coffee.getCost());
coffee = new SugarDecorator(coffee);
System.out.println(coffee.getDescription() + " $" + coffee.getCost());
}
}
在这个示例中,Coffee接口定义了获取描述和成本的方法,SimpleCoffee类实现了这个接口。CoffeeDecorator类是一个抽象类,实现了 Coffee接口,并持有一个 Coffee对象。MilkDecorator和SugarDecorator类分别继承了CoffeeDecorator类,并扩展了其功能。如果我们需要增加新的装饰器,只需要继承 CoffeeDecorator类并实现其方法即可,而无需修改现有的代码。
总结
本文通过一个电商中库存实例,演示了开闭原则的整个抽象和实现过程,并给出了开闭原则最常用的 3种实现方式。
开闭原则的核心是对扩展开放,对修改关闭,因此,当业务需求一直需要修改同一段代码时,我们就得多思考代码修改的理由是什么?它们之间是不是有一定的共同性?能不能把这些变更点分离出来,通过扩展来实现而不是修改代码?
其实在业务开发中还有很多类似的场景,比如:电商系统中的会员系统,需要根据用户不同的等级计算不同的费用;机票系统,根据用户不同的等级(普通,白金用户,黄金用户...)提供不同的售票机制;网关系统中,根据不同的粒度(接口,ip,服务,集群)来实现限流;
SRP限制一个类的变化来源应该是单一的;OCP要求不要随意修改一个类;LSP则规范了类的继承关系。
接口隔离原则
接口隔离原则,Interface segregation principle(ISP),也是 Robert C. Martin提出的 SOLID原则中的一种,老规矩,还是先看看作者 Robert C. Martin 对接口隔离原则是如何定义的:
Clients should not be forced to depend upon interfaces that they do not use.
在作者对接口隔离原则的定义中强调:不应强迫客户依赖他们不使用的接口。
在 Java中,我们一直都强调要面向接口编程,足以看出接口在 Java中的重要性。其实, 与单一职责原则类似,接口隔离原则的目标是通过将软件拆分为多个独立的部分来减少所需更改的副作用和频率。
这里的"不应强迫"该如何理解?通常来讲"不应强迫" 有2种理解:
-
第一种理解是用户不能被强迫使用整个接口。
-
第二种理解是用户只使用接口中的部分方法,其余的方法不能被强迫使用。
显然,第二种理解比较合理,所以接口隔离原则可以更直白一点的表达成:在接口中,不要放置接口使用者不需要的方法。
如何实现接口隔离?
假如有一个业务场景,需要定义一个交通工具的 Transportation类,类中包含设置基本信息(价格,颜色),启停以及飞行等方法:
public interface Transportation{
void setPrice(double price);
void setColor(String color);
void start();
void stop();
void fly();
}
汽车属于一种交通工具,因此我们可以定义一个 Car类去实现 Transportation类,代码如下:
public class Car implements Transportation {
@Override
public void setPrice(double price) {
// 价格设置逻辑
}
@Override
public void setColor(String color) {
// 颜色设置逻辑
}
@Override
public void start(){
// 启动逻辑
}
@Override
public void stop(){
// 停止逻辑
}
@Override
public void fly(){
// 飞行逻辑
}
}
从上面的代码可以发现一个问题:Car不能飞行却要实现 fly()方法,为什么?显然 fly()这个方法是 Car这种交通工具不需要关注的,这就违反了接口隔离原则。
如何解决这个问题呢?
首先,我们将交通工具接口分成多个角色接口,每个角色接口用于特定的行为,在这里我们可以将 Transportation分成 BasicFeature、 Movable、Flyable 三类行为接口。
// 基本属性, 价格,颜色
public interface BasicFeature{
void setPrice(double price);
void setColor(String color);
}
// Movable 行为, 行驶和停止
public interface Movable {
void start();
void stop();
}
// 飞行 行为
public interface Flyable {
void fly();
}
而 Car只需要关注基本属性和 Movable行为,代码如下:
public class Car implements BasicFeature, Movable {
@Override
public void setPrice(double price) {
// 价格设置逻辑
}
@Override
public void setColor(String color) {
// 颜色设置逻辑
}
@Override
public void start(){
// 启动逻辑
}
@Override
public void stop(){
// 停止逻辑
}
}
Airplane飞机需要关注基本属性,Movable行为和飞行行为,代码如下:
public class Airplane implements BasicCFeature, Movable, Flyable {
@Override
public void setPrice(double price) {
// 价格设置逻辑
}
@Override
public void setColor(String color) {
// 颜色设置逻辑
}
@Override
public void start(){
// 启动逻辑
}
@Override
public void stop(){
// 停止逻辑
}
@Override
public void fly(){
// 飞行逻辑
}
}
通过上面的拆解,我们可以看到每种交通工具只需要关注自己需要的接口就好了,自己不需要的接口就不会被强迫关注,更加不会造成 Car能 fly()这样不常见的误区。
接口隔离和单一职责的比较
接口隔离原则和单一职责原则都是 SOLID设计原则中的重要组成部分,虽然它们有一些相似之处,但它们关注的重点和应用的范围有所不同,在实际开发中,很容易搞混淆,因此,这里对这两个原则做详细比较。
-
关注点不同
单一职责原则(SRP):关注类的职责划分,确保每个类只有为一类行为负责,它主要解决的是类内部职责过多导致的复杂性问题。接口隔离原则(ISP):关注接口的设计,确保客户端只依赖于它们实际需要的方法。它主要解决的是接口过于庞大导致的依赖问题。
-
作用范围不同
单一职责原则(SRP):作用于类的设计和实现层面,通过分离职责提高类的内聚性。接口隔离原则(ISP):作用于接口的设计层面,通过细化接口减少客户端的依赖,提高系统的灵活性。
-
实现方法不同
单一职责原则(SRP):通过将一个类的多种职责分离成多个独立的类来实现。接口隔离原则(ISP):通过将一个大接口分解为多个小接口,让不同的客户端依赖于不同的小接口来实现。
因此,接口隔离原则是在遵守单一职责原则的前提下,将接口更加细化。
总结
接口隔离可以提高代码的可读性、可维护性和灵活性,减少系统的耦合度,在实际开发中,合理应用接口隔离原则,可以帮助我们创建高质量的代码和系统。然而,在应用时需要注意适度细化和明确职责,避免过度设计和接口混乱。
当我们需要某个类A中使用到另外一个类B时,最直接的方式就是在A中直接依赖B,但是,今天我们要讲解的主角却是反其道而行之,它就是依赖倒置原则,那么,什么是依赖倒置原则?这种反向思维可以带来什么收益?
依赖倒置原则
依赖倒置原则,英文为:Dependency inversion principle(简称DIP),也是 Robert C. Martin提出的 SOLID原则中的一种,老规矩,还是先看看作者 Robert C. Martin 对接口依赖倒置原则是如何定义的:
The Dependency Inversion Principle (DIP) states that high-level
modules should not depend on low-level modules; both should
depend on abstractions. Abstractions should not depend on details.
Details should depend upon abstractions.
通过作者对依赖倒置的定义,可以总结出其核心思想是:高层模块不应该依赖低层模块,两者都应该依赖于抽象。抽象不应该依赖于细节,细节应该取决于抽象。
直接依赖的问题
对于上述依赖倒置的定义,如何理解呢?我们先来看下传统这种直接依赖会存在什么问题?如下为一张直接依赖的关系图:
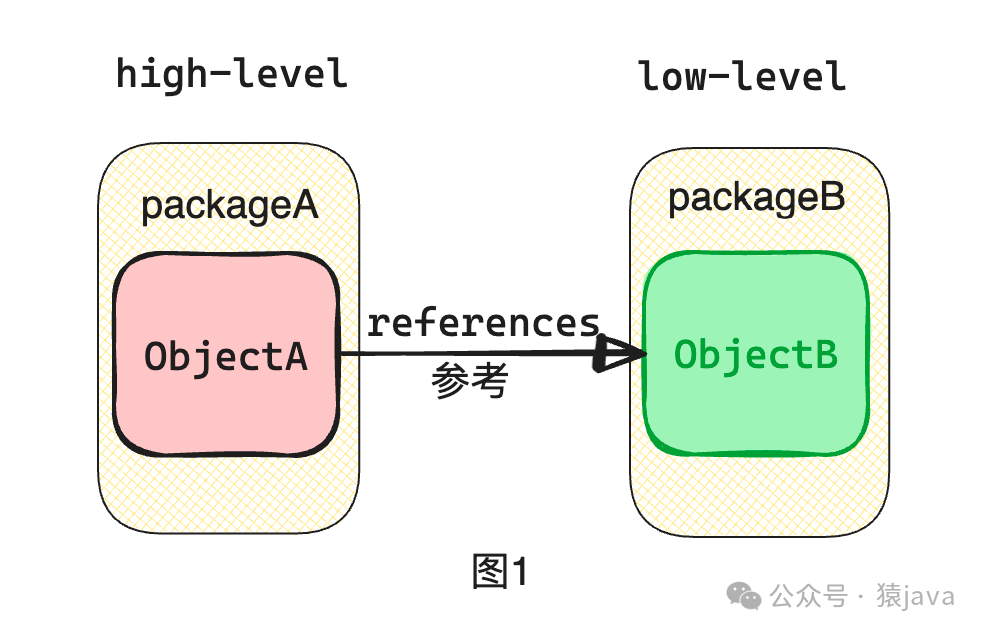
在上图中,高层组件 ObjectA直接依赖于低层组件 ObjectB,高层组件的重用机会受到限制,因为任何对低层组件的更改都会直接影响高层组件。
为了更好的说明直接依赖的问题,这里以一个真实的电商场景为例进行说明,其中有一个高层模块 OrderService用于处理订单,这个高层模块依赖于一个低层模块 OrderRepository来存储和检索订单数据。示例代码如下:
// 高层模块:OrderService
public class OrderService {
private MySQLOrderRepository mySQLRepository;
public OrderService(MySQLRepository mySQLRepository) {
this.mySQLRepository = mySQLRepository;
}
public void createOrder(Order order) {
// 一些业务逻辑
mySQLRepository.save(order);
}
}
// 低层模块:MySQLRepository
public class MySQLRepository {
public void save(Order order) {
// 使用 MySQL数据库保存订单
}
}
在上述例子中,OrderService直接依赖于 OrderRepository,这种设计存在几个缺点:
-
紧耦合:如果要把数据库从 MySQL切换到其他的数据库,我们需要修改 OrderService,因为它直接依赖于 OrderRepository。
-
难以测试:在进行单元测试时,我们无法轻松地对 OrderService 进行模拟,因为它直接依赖于具体实现 MySQLRepository。
-
重用性差:如果在另一个项目中我们需要使用 OrderService 但存储订单的方式不同,例如使用文件系统或远程服务,我们将无法直接重用 OrderService。
那么,对于这些缺点,该如何解决呢?接下来我们将重点讲解。
如何实现依赖倒置?
这里提供两种主流的解决方案。
方案一:引入抽象层
通过低级组件实现高级组件的接口,要求低级组件包依赖于高级组件进行编译,从而颠倒了传统的依赖关系,如下图:
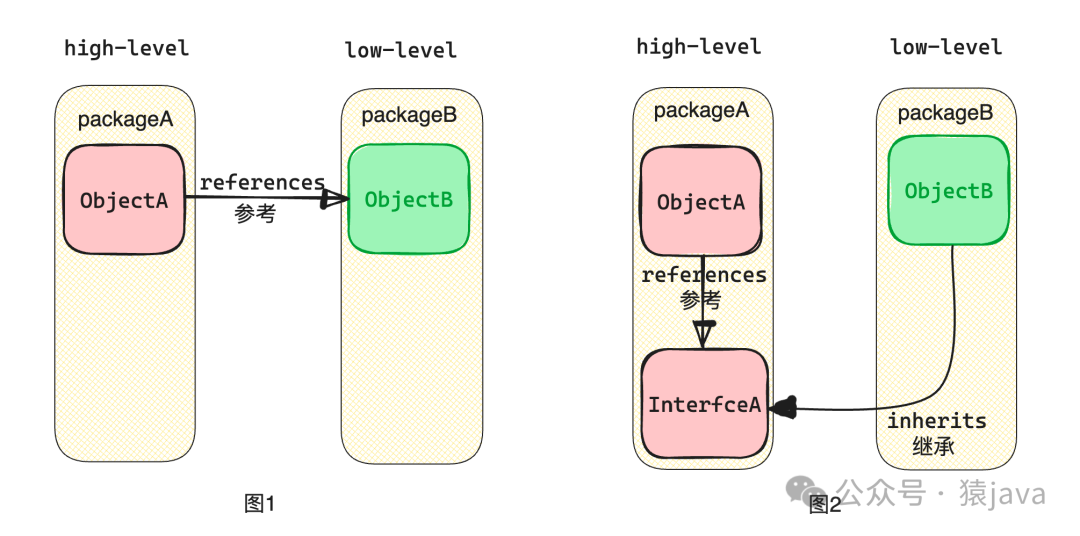
图1中,高层对象A依赖于底层对象B的实现;图2中,把高层对象A对底层对象的需求抽象为一个接口A,底层对象B实现了接口A,这就是依赖反转。
因此,上面的问题我们也可以通过引入一个抽象层 OrderRepository来解耦高层模块和低层模块,整个关系图如下:
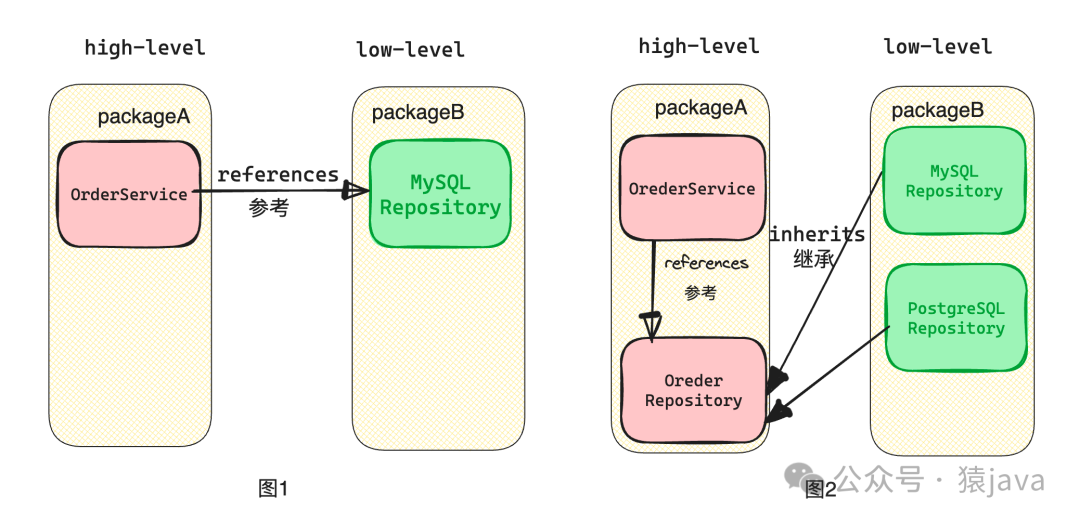
通过这种方式,OrderService依赖于 OrderRepository接口而不是具体实现 MySQLRepository。这样,我们可以轻松替换低层实现而无需修改高层模块,修改后的代码如下:
// 高层模块:OrderService
public class OrderService {
private OrderRepository orderRepository;
public OrderService(OrderRepository orderRepository) {
this.orderRepository = orderRepository;
}
public void placeOrder(Order order) {
// 一些业务逻辑
orderRepository.save(order);
}
}
// 抽象层:OrderRepository接口
public interface OrderRepository {
void save(Order order);
}
// 低层模块:MySQLRepository实现
public class MySQLRepository implements OrderRepository {
public void save(Order order) {
// 使用MySQL数据库保存订单
}
}
// 另一个低层模块:PostgreSQLRepository实现
public class PostgreSQLRepository implements OrderRepository {
public void save(Order order) {
// 使用PostgreSQL数据库保存订单
}
}
在应用程序中,我们可以灵活选择使用哪种具体实现,也可以把数据库的选择做成配置:
OrderRepository orderRepository = new MySQLRepository(); // 或 new PostgreSQLRepository();
OrderService orderService = new OrderService(orderRepository);
通过这种方式,OrderService变得更具重用性、可测试性更强,并且与具体的存储实现解耦,满足依赖倒置原则的要求。
方案二:引入抽象层升级版
尽管方式一也实现了依赖倒置,但是这种实现方式高层组件以及组件是封装在一个包中,对低层组件的重用会差一些,因此,另一种更灵活的解决方案是将抽象组件提取到一组独立的包/库中,如下图:
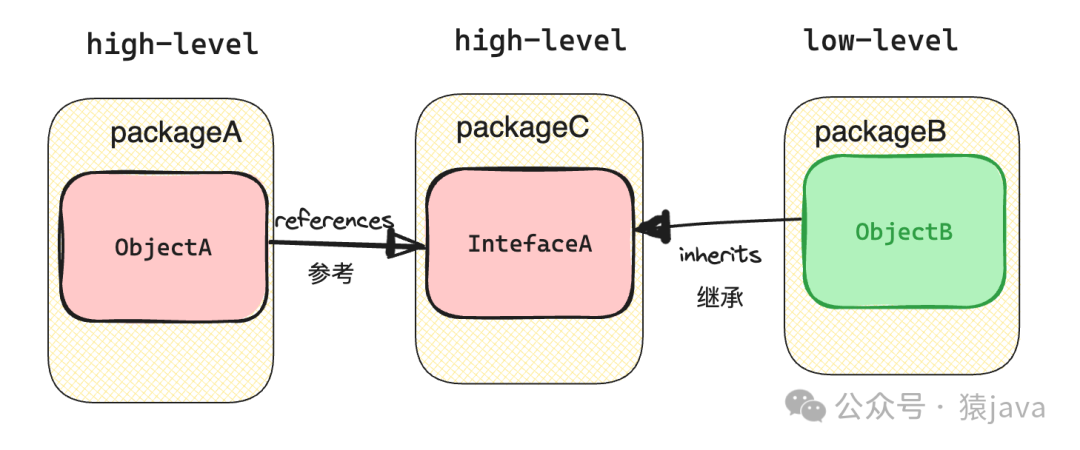
因此,上述电商示例的依赖关系会变成下图:
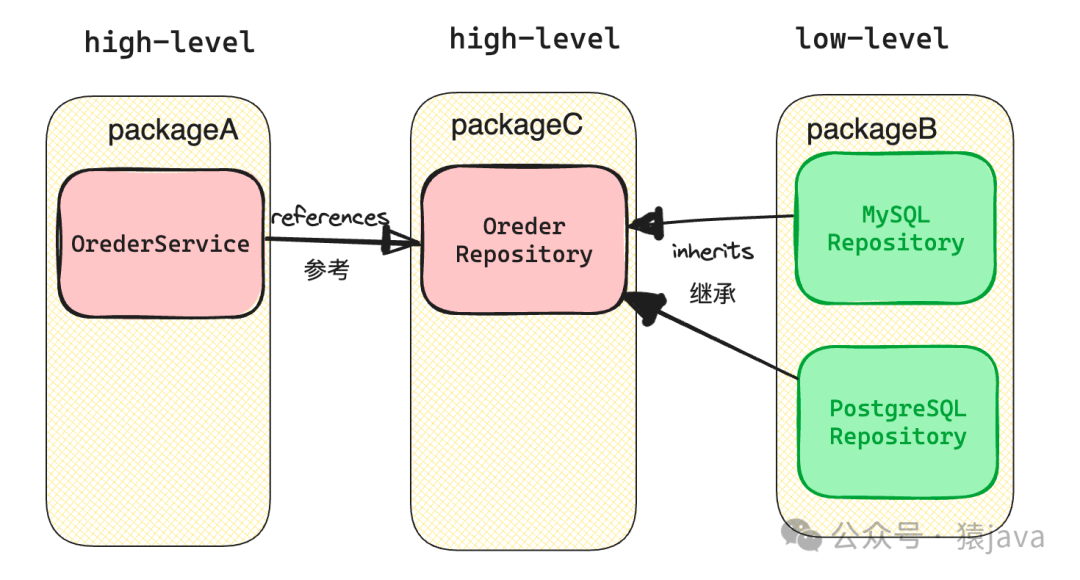
这种实现方式将每一层分离成自己的封装,鼓励任何层的再利用,提供稳健性和移动性。
两种方案的核心思想都是一样的,只是在灵活性和组件复用的考虑上略有差异。
依赖倒置的实例
在 Java语言中,使用依赖倒置原则的框架或者技术点有很多,这里列举2个比较较常用的例子:
Spring
Spring框架的核心之一是依赖注入(Dependency Injection, DI),这是依赖倒置原则的一个实现。通过Spring容器管理对象的创建和依赖关系,可以使得高层模块和低层模块都依赖于抽象。Spring支持构造器注入、setter注入和接口注入等多种方式。
Java SPI
Java SPI(Service Provider Interface)机制也体现了依赖倒置原则,SPI机制通过定义接口和服务提供者(Service Providers),使得高层模块(使用者)和低层模块(提供者)之间的依赖关系可以通过接口进行解耦。具体来说,高层模块依赖于抽象(接口),而不是具体的实现,从而实现了依赖倒置原则。
JDBC(Java Database Connectivity)就是使用 SPI机制来加载和注册数据库驱动程序,使得应用程序可以动态地使用不同的数据库而无需修改代码。
JDBC SPI的工作原理:
-
定义服务接口:JDBC API定义了一组接口,如 java.sql.Driver。
-
实现服务接口:每个数据库厂商实现这些接口,例如,MySQL的驱动实现了 java.sql.Driver接口。
-
声明服务提供者:数据库驱动的JAR包中包含一个文件,声明实现类。
-
加载服务提供者:通过 ServiceLoader或 JDBC API动态加载并实例化驱动实现。
总结
本文通过一个电商示例分析了什么是依赖倒置原则,并且提出了依赖倒置的两种实现风格,通过引入抽象层,可以降低系统的耦合度,提升系统的扩展性和可维护性。因此,在实际开发中,我们应当始终遵循依赖倒置原则,设计灵活、可扩展的系统架构,从而应对复杂多变的业务需求。







![【2024最新华为OD-C/D卷试题汇总】[支持在线评测] LYA的生日派对座位安排(200分) - 三语言AC题解(Python/Java/Cpp)](https://i-blog.csdnimg.cn/direct/5ec34571e93c408a97a960cb336ea0a5.png)








